

softmax
写在前面
以下是个人在学习过程中的记录,如有侵权联系删除。
参考:
https://zhuanlan.zhihu.com/p/21102293?refer=intelligentunit
https://cs231n.github.io/linear-classify/
https://blog.csdn.net/SongGu1996/article/details/99056721
引
SVM将输出作为每个分类的评分,svm分类时输出每个分类的得分,这个分数不太好解释
softmax中函数映射保持不变,但将这些评分值视为每个分类的未归一化的对数概率
但是softmax的输出值时归一化的,可以用概率加以解释,也就是每个分类的概率,越接近1的概率就越高
svm中损失是折叶损失,而softmax的是交叉熵损失
何为交叉熵
交叉熵:用于度量两个概率分布间的差异性信息。交叉熵可在神经网络(机器学习)中作为损失函数,
p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。
按照真实分布p来衡量
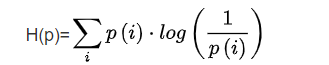
p(X) 是随机变量X的分布, q(X) 是随机变量的近似分布。两者之间有差异
如果采用错误的分布q来表示来自真实分布p

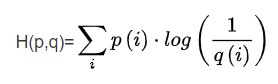
softmax的交叉熵损失
等价于
相当于信息论交叉熵的一个个体
softmax函数
被称作softmax 函数:其输入值是一个向量,向量中元素为任意实数的评分值(
中的),
函数对其进行压缩,输出一个向量,其中每个元素值在0到1之间,且所有元素之和为1。 (也就是返回的也是一个向量?)
Softmax分类器所做的就是最小化在估计分类概率和“真实”分布之间的交叉熵
概率论解释
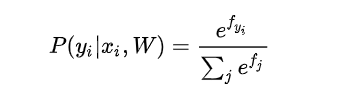
可以解释为是给定图像数据,以
为参数,分配给正确分类标签
的归一化概率。
Softmax分类器将输出向量中的评分值解释为没有归一化的对数概率。
那么以这些数值做指数函数的幂就得到了没有归一化的概率,而除法操作则对数据进行了归一化处理
由于上式是指数函数,所以会非常大,可能会产生溢出,所以一般会给分子分母乘以一个系数C
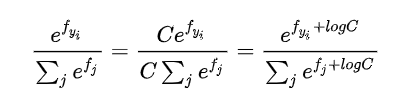
通过使用这个技巧可以提高计算中的数值稳定性。通常将设为
import numpy as np f = np.array([123, 456, 789]) p = np.exp(f) / np.sum(np.exp(f)) # 如果单单这么计算,会产生数值爆炸 # 添加一个系数C, 根据本例f 得logC = - 789 f -= np.max(f) # f中每个元素减去中的最大值 p = np.exp(f) / np.sum(np.exp(f))
说明:softmax函数是一个归一函数与交叉熵没有任何关系,只是用于称呼这个分类器
SVM同Softmax的比较
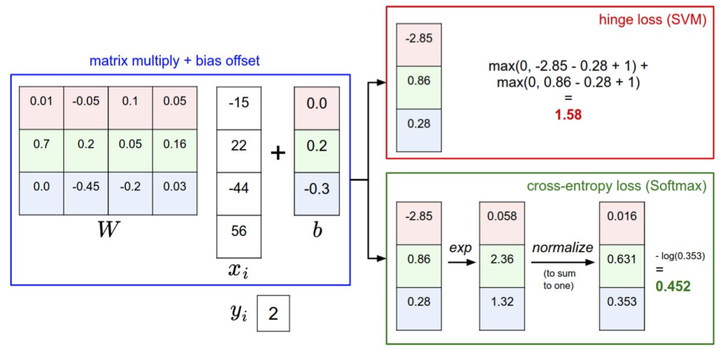
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
Softmax分类器为每个分类提供了“可能性”:SVM的计算是无标定的,而且难以针对所有分类的评分值给出直观解释。Softmax分类器则不同,它允许我们计算出对于所有分类标签的可能性。举个例子,针对给出的图像,SVM分类器可能给你的是一个[12.5, 0.6, -23.0]对应分类“猫”,“狗”,“船”。而softmax分类器可以计算出这三个标签的”可能性“是[0.9, 0.09, 0.01],这就让你能看出对于不同分类准确性的把握。为什么我们要在”可能性“上面打引号呢?这是因为可能性分布的集中或离散程度是由正则化参数λ直接决定的,λ是你能直接控制的一个输入参数。举个例子,假设3个分类的原始分数是[1, -2, 0],那么softmax函数就会计算:
现在,如果正则化参数λ更大,那么权重W就会被惩罚的更多,然后他的权重数值就会更小。这样算出来的分数也会更小,假设小了一半吧[0.5, -1, 0],那么softmax函数的计算就是:
现在看起来,概率的分布就更加分散了。还有,随着正则化参数λ不断增强,权重数值会越来越小,最后输出的概率会接近于均匀分布。这就是说,softmax分类器算出来的概率最好是看成一种对于分类正确性的自信。和SVM一样,数字间相互比较得出的大小顺序是可以解释的,但其绝对值则难以直观解释。
在实际使用中,SVM和Softmax经常是相似的:通常说来,两种分类器的表现差别很小,不同的人对于哪个分类器更好有不同的看法。相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。考虑一个评分是[10, -2, 3]的数据,其中第一个分类是正确的。那么一个SVM()会看到正确分类相较于不正确分类,已经得到了比边界值还要高的分数,它就会认为损失值是0。SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。
代码实现
from builtins import range import numpy as np from random import shuffle from past.builtins import xrange def softmax_loss_naive(W, X, y, reg): """ Softmax loss function, naive implementation (with loops) Inputs have dimension D, there are C classes, and we operate on minibatches of N examples. Inputs: - W: A numpy array of shape (D, C) containing weights. - X: A numpy array of shape (N, D) containing a minibatch of data. - y: A numpy array of shape (N,) containing training labels; y[i] = c means that X[i] has label c, where 0 <= c < C. - reg: (float) regularization strength Returns a tuple of: - loss as single float - gradient with respect to weights W; an array of same shape as W """ # Initialize the loss and gradient to zero. loss = 0.0 dW = np.zeros_like(W) ############################################################################# # TODO: Compute the softmax loss and its gradient using explicit loops. # # Store the loss in loss and the gradient in dW. If you are not careful # # here, it is easy to run into numeric instability. Don't forget the # # regularization! # ############################################################################# # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** for i in range(X.shape[0]): scores = X[i].dot(W) scores -= np.max(scores) p = np.exp(scores) / np.sum(np.exp(scores)) for j in range(W.shape[1]): if j == y[i]: dW[:, j] += (p[j] - 1) * X[i] else: dW[:, j] += p[j] * X[i] loss += -np.log(p[y[i]]) loss /= X.shape[0] loss += reg * np.sum(W ** 2) dW /= X.shape[0] dW += 2.0 * reg * W # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** return loss, dW def softmax_loss_vectorized(W, X, y, reg): """ Softmax loss function, vectorized version. Inputs and outputs are the same as softmax_loss_naive. """ # Initialize the loss and gradient to zero. loss = 0.0 dW = np.zeros_like(W) ############################################################################# # TODO: Compute the softmax loss and its gradient using no explicit loops. # # Store the loss in loss and the gradient in dW. If you are not careful # # here, it is easy to run into numeric instability. Don't forget the # # regularization! # ############################################################################# # *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** scores = X.dot(W) scores -= np.max(scores, axis=1, keepdims=True) p = np.exp(scores) / np.sum(np.exp(scores), axis=1, keepdims=True) loss = np.sum(-np.log(p[np.arange(X.shape[0]), y])) / X.shape[0] p[np.arange(X.shape[0]), y] = p[np.arange(X.shape[0]), y] - 1 dW = np.dot(X.T, p) loss += reg * np.sum(W ** 2) dW = dW / X.shape[0] + 2.0 * reg * W # *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)***** return loss, dW


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 提示词工程——AI应用必不可少的技术
· 地球OL攻略 —— 某应届生求职总结
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界