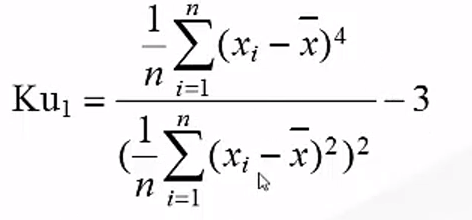SPSS Modeler1_数据读取和数据的统计描述
一、数据读取:左上角“文件 -->打开流 --> 选择文件所在位置导入即可”
二、数据的身份:下方“字段选项 -- >类型"节点(处理数据类型)、下方“字段选项 -- >过滤”节点(删除不需要的字段属性)
三、数据的集成:合并(横向合并,涉及内链接、外连接等)和追加(纵向合并)
四、描述性统计指标:下方的“输入-->数据审核”节点就可以算出所有虽需要的描述性统计指标
1、集中趋势:
平均数:非常容易受到异常点的影响,会影响对整体数量的集中分析,比如收入指标
中位数:不会收到异常点的影响,但中位数只是利用了部分信息,对整体数据的信息利用不充分
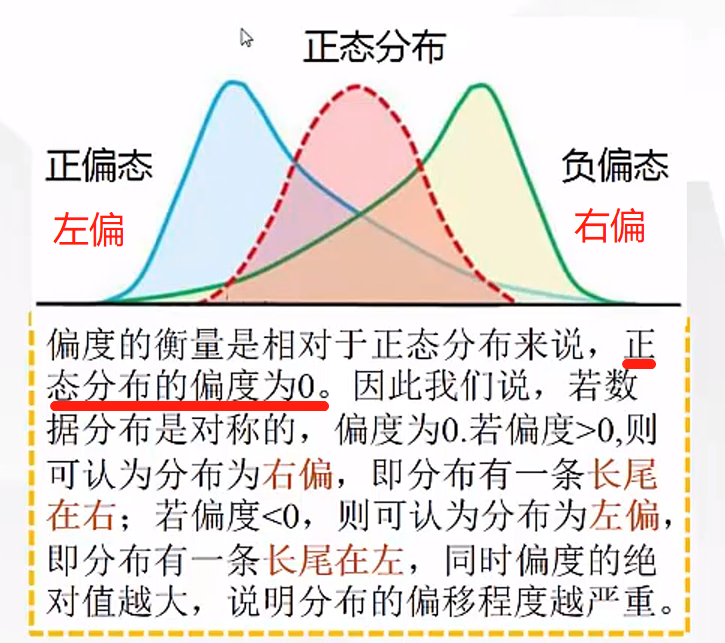
## 一般时平均数和中位数一起结合使用,看看数据分布是否左偏还是右偏
## 实际生活中,为了解决这些缺点,会提出几个最大值和最小值,然后再对剩下的数据求平均
众数:一般用在分类变量中,连续性变量用这个指标相对较少
2、离散趋势:
极差:一组数据中最大值减去最小值的差;极差利用整体数据的信息不充分
离差、平均差、方差、标准差:
3、分布趋势:
偏度:研究数据分布对称的统计量,通过对偏度系数的测量,我门可以判定数据分布的不对称程度以及方向,尾巴在哪就是那偏
偏度的公式:
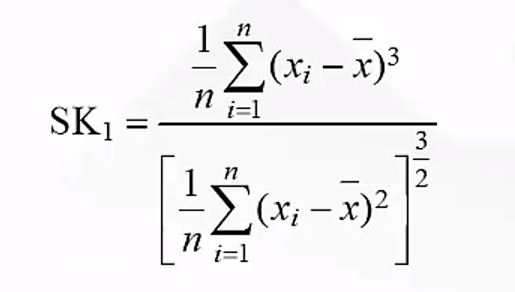
峰度:时研究数据分布陡峭或者平滑的统计量,通过对锋度系数的测量,我么能够判定数据分布相对于正太分布而言时更陡峭还是平滑
峰度的公式:当峰度等于0时,则该数据的分布形态是服从正态分布