(转)Lampard--【Lua基础系列】协程
【Lua基础系列】协程
大家好,我是Lampard~~
欢迎来到Lua进阶系列的博客
前文再续,书接上一回。今天和大家讲解一下lua中的协程
(一) 什么是协程
Lua 协同程序(coroutine)与线程(这里的线程指的是操作系统的线程)比较类似:拥有独立的堆栈,独立的局部变量,独立的指令指针,同时又与其它协同程序共享全局变量和其它大部分东西。
一个多线程程序可以同时运行几个线程(并发执行、抢占),而协程却需要彼此协作地运行,并非真正的多线程,即一个多协程程序在同一时间只能运行一个协程,并且正在执行的协程只会在其显式地要求挂起(suspend)时,它的执行才会暂停(无抢占、无并发)。
协同程序有点类似同步的多线程,在等待同一个线程锁的几个线程有点类似协同程序。
协程的用法: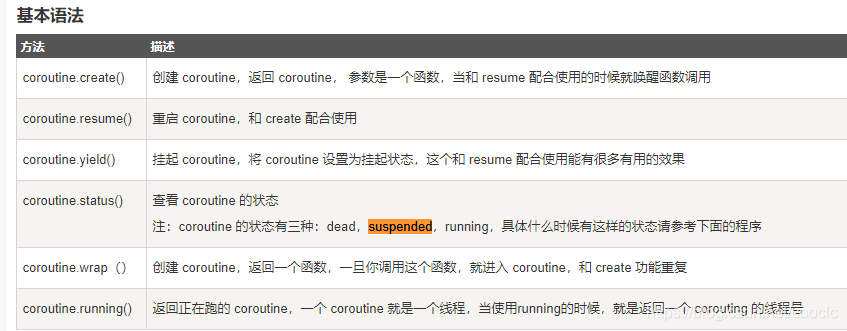
coroutine.running就可以看出来,coroutine在底层实现就是一个线程,当create一个coroutine的时候就是在新线程中注册了一个事件。
(二) resume和yeild
resume和yeildr的协作是Lua协程的核心
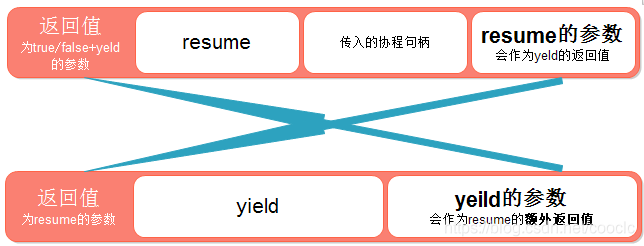
举一个经典生产者消费者例子:创建一个生产工厂,让它生产20件产品,每生产一件就把协程挂起,等待客户下一次提交需求的时候才重新resume唤醒
local newProductor function productor() local i = 0 while true do i = i + 1 send(i) -- 将生产的物品发送给消费者 end end function consumer() local i = receive() while i < 20 do print(i) i = receive() end end function receive() -- 唤醒程序 local status, value = coroutine.resume(newProductor) return value end function send(x) coroutine.yield(x) -- x表示需要发送的值,值返回以后,就挂起该协同程序 end -- 创建生产工厂 newProductor = coroutine.create(productor) consumer()
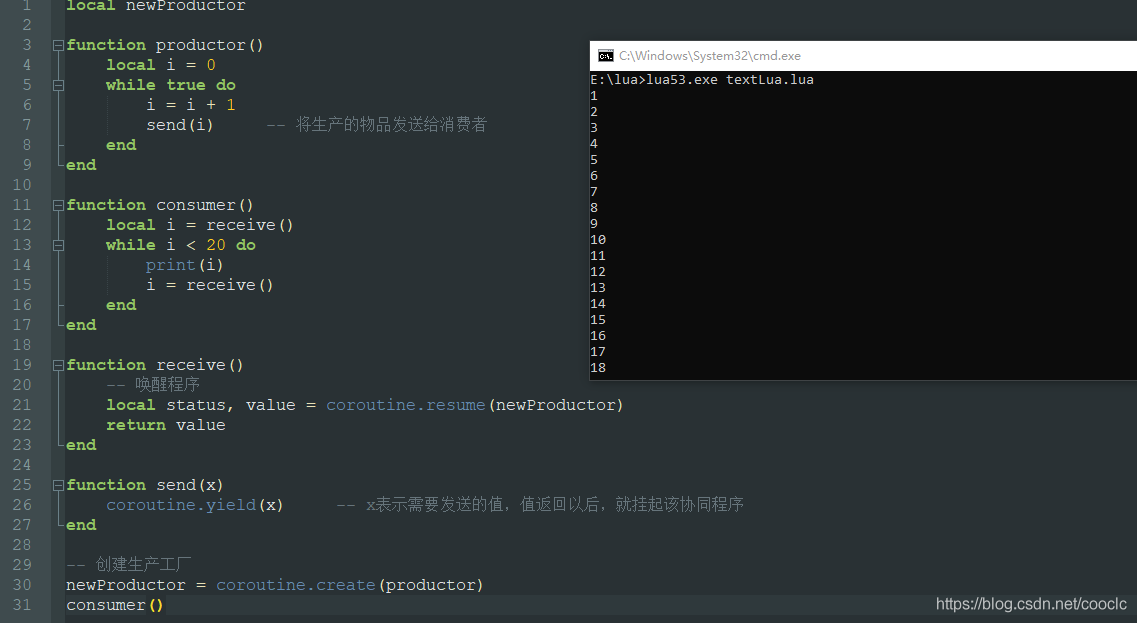
测试结果:
(三) 协程的作用:
我作为客户端,参与项目一年多,其实一直都是单线程开发的,对于多线程,协程这些为何存在一直不太理解,知道查阅了这篇博客稍微的了解一些:协程的好处是什么?
一开始大家想要同一时间执行那么三五个程序,大家能一块跑一跑。特别是UI什么的,别一上计算量比较大的玩意就跟死机一样。于是就有了并发,从程序员的角度可以看成是多个独立
的逻辑流。内部可以是多cpu并行,也可以是单cpu时间分片,能快速的切换逻辑流,看起来像是大家一块跑的就行。 但是一块跑就有问题了。我计算到一半,刚把多次方程解到最后一步,你突然插进来,我的中间状态咋办,我用来储存的内存被你覆盖了咋办?所以跑在一个cpu里面的并发都需要处理
上下文切换的问题。进程就是这样抽象出来个一个概念,搭配虚拟内存、进程表之类的东西,用来管理独立的程序运行、切换。 后来一电脑上有了好几个cpu,好咧,大家都别闲着,一人跑一进程。就是所谓的并行。 因为程序的使用涉及大量的计算机资源配置,把这活随意的交给用户程序,非常容易让整个系统分分钟被搞跪。所以核心的操作需要陷入内核(kernel),切换到操作系统,让老大帮你
来做。 有的时候碰着I/O访问,阻塞了后面所有的计算。空着也是空着,老大就直接把CPU切换到其他进程,让人家先用着。当然除了I\O阻塞,还有时钟阻塞等等。一开始大家都这样弄,后
来发现不成,太慢了。为啥呀,一切换进程得反复进入内核,置换掉一大堆状态。进程数一高,大部分系统资源就被进程切换给吃掉了。后来搞出线程的概念,大致意思就是,这个地方
阻塞了,但我还有其他地方的逻辑流可以计算,这些逻辑流是共享一个地址空间的,不用特别麻烦的切换页表、刷新TLB,只要把寄存器刷新一遍就行,能比切换进程开销少点。
比如在进程里面写一个逻辑流调度的东西,碰着i\o我就用非阻塞式的(比如在加载资源时,我们可以做一些初始化场景的逻辑)。那么我们即可以利用到并发优势,又可以避免反复系统调用,还有进程切换造成的开销,分分钟给你上几千个逻辑流不费力。这就是协程。
原文地址:https://blog.csdn.net/cooclc/article/details/112640610

 浙公网安备 33010602011771号
浙公网安备 33010602011771号