HDFS简介及相关概念
HDFS简介:
HDFS在设计时就充分考虑了实际应用环境的特点,即硬件出错在普通服务集群中是一种常态,而不是异常。
因此HDFS主要实现了以下目标:
| 兼容廉价的硬件设备 | HDFS设计了快速检测硬件故障和进行自动恢复的机制,可以实现持续监视,错误检查,容错处理和自动回复,从而使得在硬件出错的情况下也能实现数据的完 整性 |
| 流数据读写 | 普通文件系统主要用于随机读写以及与用户进行交互,HDFS则是为了满足批量数据处理。因此其可以以流式方式来访问文件数据。 |
| 大数据集 | HDFS中的文件通常可以达到GB甚至TB级别 |
| 简答的文件模型 | HDFS采用了“一次写入,多次读取”的简单文件模型,文件一旦完成写入,关闭后就无法再次写入,只能被读取 |
| 强大的跨平台兼容性 | 由于HDFS使用java语言实现的,具有很好的跨平台兼容性 |
HDFS的局限:
| 不适合低延迟数据的访问 | HDFS不适合用在需要较低延迟(如数十毫秒)的应用场合,对于低延迟要求的应用程序而言,HBase是一个更好的选择 |
| 无法高效存储大量小文件 | 小文件是指文件大小小于一个块的文件 |
| 不支持多用户写入及任意修改文件 | HDFS只允许一个文件有一个写入者,且只允许对文件执行追加操作,不能执行随机写操作(即:不能改变文件中的数据,只能在文件后增加) |
HDFS的相关概念:
块:在传统的文件系统中,为了提高磁盘读写效率,一般以数据块为单位,而不是以次节为单位。查找数据的存储位置时,通过查询一块块的数据块,找到数据在磁盘中的存储位置,然后进行读写。HDFS也同样采用了块的概念,默认一个块的大小是64MB,这样做得目的是为了最小化寻址开销。通常,MapReduce中的Map任务一次只处理一个块中的数据。HDFS采用抽象的块概念的好处:
| 支持大规模文件存储 | 文件在存储时别拆分为一定量的块,分发到不同的节点上,因此一个文件的大小不会受到单个节点的存储容量限制 |
| 简化系统设计 | 大大简化了存储管理,因为一个文件块的大小是固定的,这样就可以计算出一个节点可以存储多少文件块,且方便了元数据的管理 |
| 适合数据备份 | 每个文件块都可以冗余存储到多个节点上,大大提高了系统的容错性和可用性 |
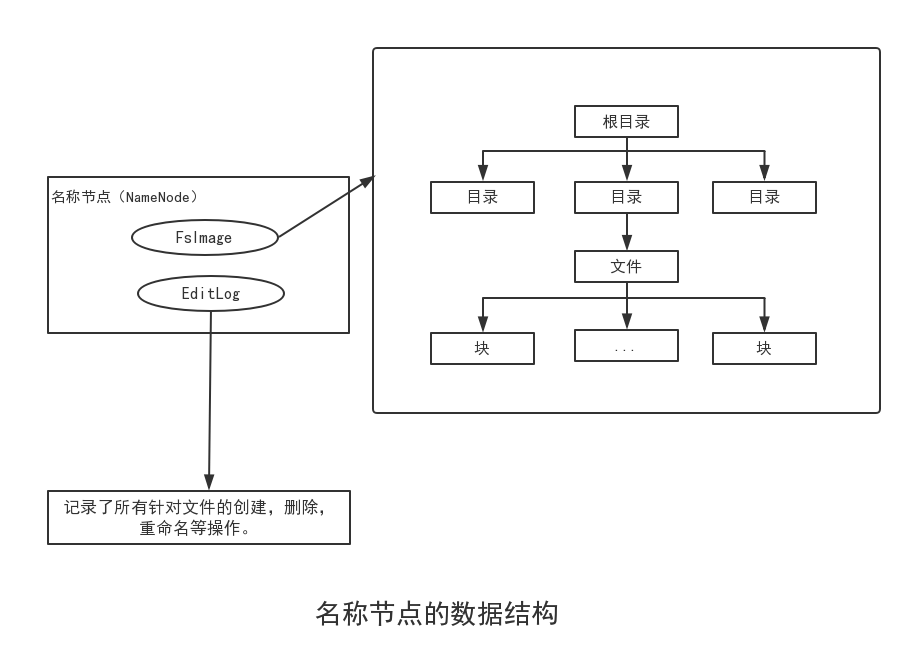
名称节点和数据节点:在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage和EditLog。FsImage用于维护文件系统树以及文件数中所有的文件和文件夹的元数据。操作日志文件EditLog中记录了所有针对文件的创建,删除,重命名等操作。名称节点记录了每个文件中各个块所在的数据节点的位置信息,但是并不持久化存储这些信息,而是在每次系统启动时扫描所有的数据节点重构得到这些信息。
名称节点在启动时,会将FsImage的内容加载到内存中,然后执行EditLog文件中的各项操作,舍得内从中的元数据保持最新。操作完成后,就会创建一个新的FsImage文件和一个空的EditLog文件。名称节点启动成功并进入正常运行状态后,HDFS中的更新操作都会被写入EditLog中,而不是直接写入FsImage中。名称节点在启动的过程中处于“安全模式”,只能对外提供读操作而无法提供写操作。启动过程结束后,系统就会退出安全模式,进入正常运行状态,对外提供读写操作。
数据节点(DataNode)负责数据的存储和读取。每个数据节点的数据会被保存在各自节点的本地Linux文件系统中。
第二名称节点:在名称节点运行期间,HDFS会不断发生更新操作,这些更新操作都是直接被写入EditLog文件,因此EditLog文件也会逐渐变大,虽然EditLog不会对系统性能产生显著影响,但是当名称节点重启是,需要将FsImage加载到内存中,然后逐条执行EditLog中的记录,使得FsImage保持更新,可想而知,如果EditLog很大,就会导致整个过程变得非常缓慢,使得名称节点在启动过程中长期处于“安全模式”,无法正常对外提供写操作,影响了用户的使用。
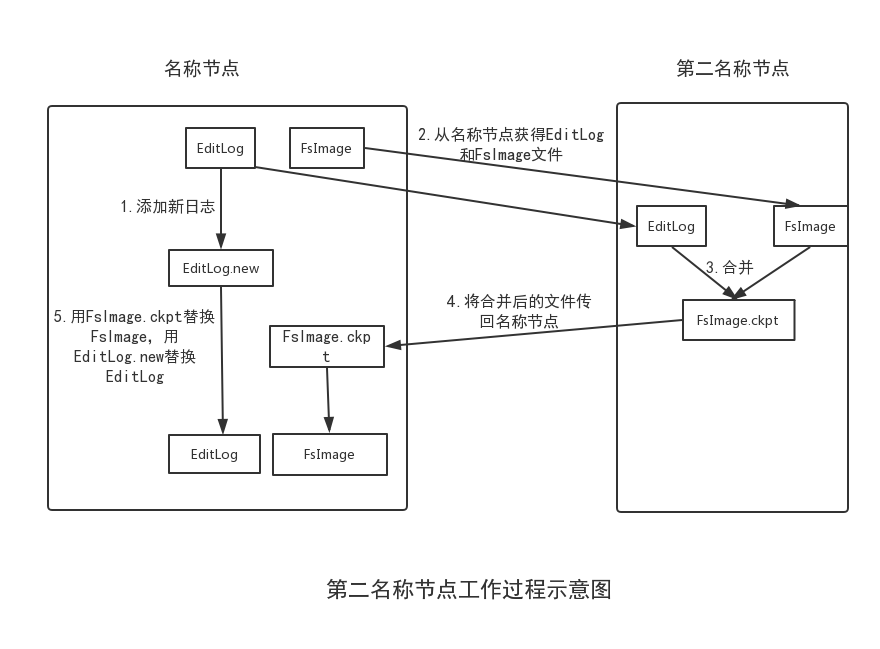
为了解决这个问题,HDFS采用了第二名称节点。它具有两个方面的功能:
一是进行EditLog和FsImage的合并操作,每隔一段时间(假设为t1),第二名称节点会和名称节点通信,请求其停止使用EditLog文件,暂时将新到达的写操作添加到一个新的文件EditLog.new中。然后,第二名称节点把名称节点中的FsImage和EditLog文件拉回本地,再加载到内存中,对两者执行合并操作,即在内存中逐条执行EditLog中的操作,使得FsImage保持最新。合并结束后,第二名称节点会把合并得到的最新FsImage文件发送到名称节点。名称节点收到后,会用最新的FsImage文件去替换旧的FsImage文件,同时用EditLog.new文件去替换EditLog文件(假设这段时间为t2),从而减小了EditLog文件的大小。
二是作为名称节点的“检查节点”。从上面的合并过程中可以看出,第二名称节点会定期和名称节点通信,从名称节点获取FsImage和EditLog文件。这相当于第二名称节点是名称节点的“检查节点”,周期性地备份名称节点中的元数据信息,当名称节点发生故障时,就可以用第二名称节点对其进行恢复。但是,第二名称节点上合并操作得到的新的FsImage文件是合并操作发生时(即t1时刻)HDFS记录的元数据信息,并没有包含t1时刻和t2时刻期间发生的更新操作,如果名称节点在这段时间内发生故障,系统就会丢失部分元数据。在HDFS的设计中,也并支持把系统直接切换到第二名称节点。因此第二名称节点相当于系统的“冷备份”。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号