
多进程和多线程
进程的概念
进程:一个正在执行的程序
- 计算机程序是存储在磁盘上的可执行二进制(或其他类型)文件,只有把它们加载到内存中,并被操作系统调用,它们才会拥有其自己的生命周期。
- 进程是表示的一个正在执行的程序。
- 每个进程都拥有自己的地址空间、内存、数据栈以及其他用于跟踪执行的辅助数据。
- 操作系统负责其上所有进程的执行,并为这些进程合理地分配执行时间。
- 进程之间是独立的,不能共享彼此的数据。
并行与并发
并行:同时进行多个任务
并发:短时间内,运行多个任务
并发:单CPU,多进程并发
无论是并行还是并发,在用户看来都是'同时'运行的,不管是进程还是线程,都只是一个任务而已,真实干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务
一 并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发)
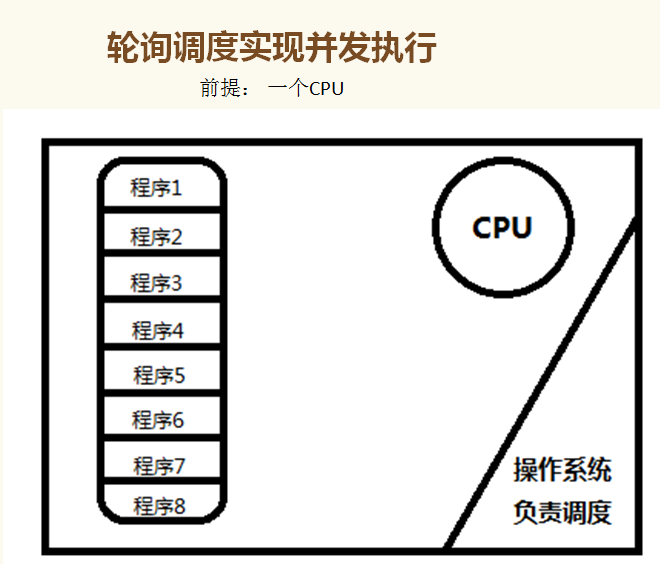
并行:多CPU(同时运行,只有具有多个cpu才能实现并行)
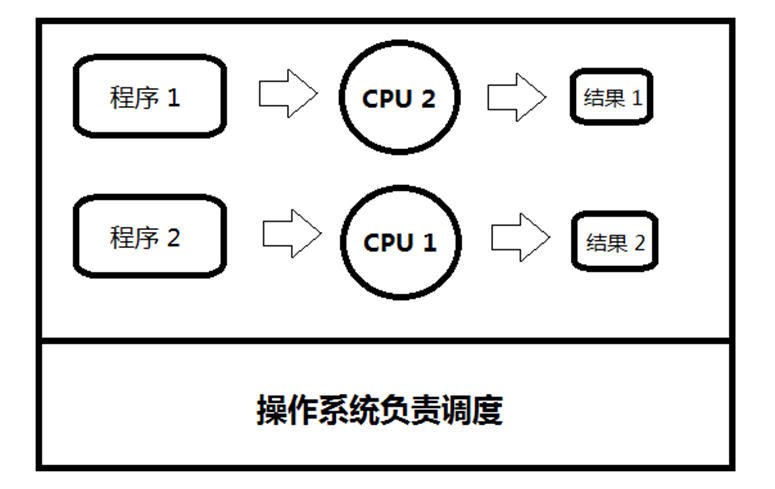
并行满足的条件是总进程数量不多于 CPU核心数量!因此,现在PC运行的程序大部分都是轮询调度产生的并行假象
举例:比如PC有四个核,六个任务,这样同一时间有四个任务被执行,假设分别被分配给了cpu1,cpu2,cpu3,cpu4,
一旦任务2遇到I/O就被迫中断执行,此时任务5就拿到cpu1的时间片去执行,这就是单核下的多道技术
而一旦任务2的I/O结束了,操作系统会重新调用它(需知进程的调度、分配给哪个cpu运行,由操作系统说了算),可能被分配给四个cpu中的任意一个去执行
所以,现代计算机经常会在同一时间做很多件事,一个用户的PC(无论是单cpu还是多cpu),都可以同时运行多个任务(一个任务可以理解为一个进程)。
多道技术:内存中同时存入多道(多个)程序,cpu从一个进程快速切换到另外一个,使每个进程各自运行几十或几百毫秒,这样,虽然在某一个瞬间,一个cpu只能执行一个任务,但在1秒内,cpu却可以运行多个进程,这就给人产生了并行的错觉,即伪并发,以此来区分多处理器操作系统的真正硬件并行(多个cpu共享同一个物理内存)
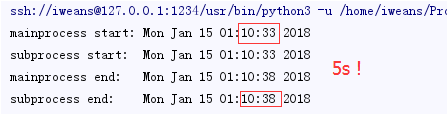
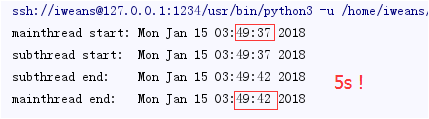
例子:在python中执行耗时操作

结果:
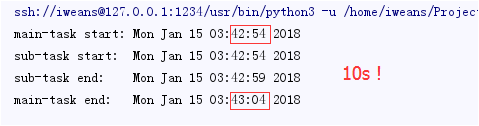
用进程来分担耗时任务后:

python进程使用流程
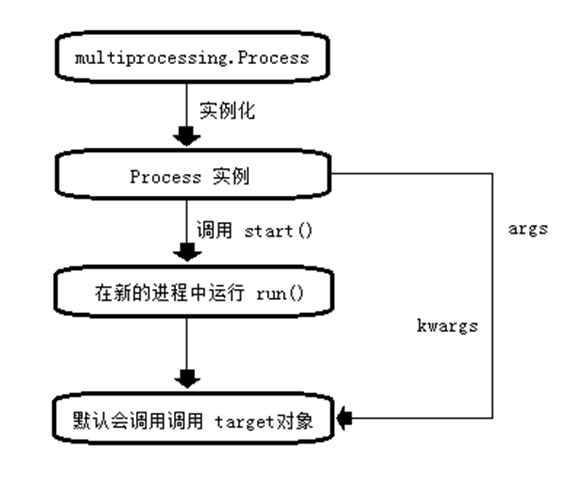
线程的概念
- 线程被称作轻量级进程。
- 与进程类似,不过它们是在同一个进程下执行的。
- 并且它们会共享相同的上下文。
- 当其他线程运行时,它可以被抢占(中断)和临时挂起(也称为睡眠)
- 线程的轮训调度机制类似于进程的轮询调度,只不过这个调度不是由操作系统来负责,而是由Python解释器来负责。
GIL锁
Python在设计的时候,还没有多核处理器的概念。因此,为了设计方便与线程安全,直接设计了一个锁。这个锁要求,任何进程中,一次只能有一个线程在执行。
因此,并不能为多个线程分配多个CPU。所以Python中的线程只能实现并发,而不能实现真正的并行。但是Python3中的GIL锁有一个很棒的设计,在遇到阻塞(不是耗时)的时候,会自动切换线程。
Scrapy、Django、Flask、Web2py ...等框架 都是使用多线程来完成
GIL锁带给我们的新认知,遇到阻塞就自动切换。因此我们可以利用这种机制来有效的避开阻塞 ,充分利用CPU
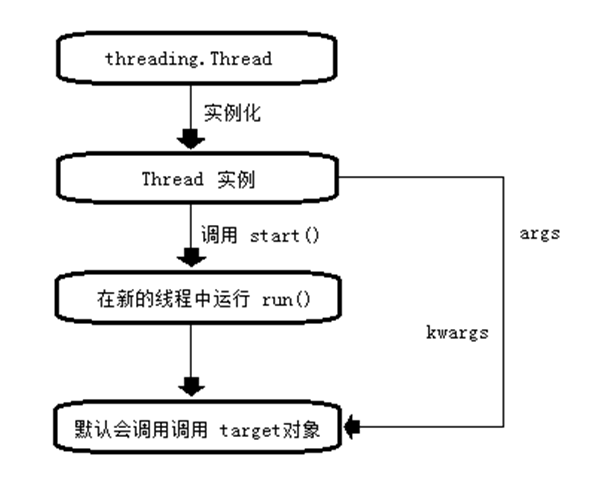
例子:使用线程来避开阻塞任务

python线程使用流程
计算密集型和IO密集型
IO密集型遇到等待时,不消耗CPU,CPU会调度其他程序执行,使用多线程可以有效的进行并发(爬虫的请求是IO密集型),线程在系统中所占资源较少。
计算密集型:CPU会一直计算,此时使用多线程,反而会耗时更多,此时使用多进程(CPU越多,性能越好)。
使用多进程/多线程实现并发服务器:
import socket from multiprocessing import Process from threading import Thread def read(conn,addr): while True: data = conn.recv(1024) if data: print('客户端{}的消息:{}'.format(addr,data.decode())) conn.send(data) else: conn.close() print('客户端{}断开连接'.format(addr)) break if __name__ == '__main__': server = socket.socket() server.bind(('', 9998)) # 注意这些代码要写在if...main...判断下面,因为在Windows中,使用进程的模式类似导入,在判断外面的代码会在子进程执行 server.listen(5) while True: print('等待客户端连接') conn,addr = server.accept() # 有客户端连接,就往下进行 print('客户端{}已连接'.format(addr)) # p = Process(target=read,args=(conn,addr)) # 使用多进程,每来一个客户端连接,就分出一个进程去和它一对一处理 # p.start() t = Thread(target=read,args=(conn,addr)) # 使用多线程,每来一个客户端连接,就分出一个线程去和它一对一处理 t.start()
补充
fork介绍
Unix/Linux操作系统提供了一个fork()系统调用,它非常特殊。普通的函数调用,调用一次,返回一次,但是fork()调用一次,返回两次,因为操作系统自动把当前进程(称为父进程)复制了一份(称为子进程),然后,分别在父进程和子进程内返回。
子进程永远返回0,而父进程返回子进程的ID。这样做的理由是,一个父进程可以fork出很多子进程,所以,父进程要记下每个子进程的ID,而子进程只需要调用getppid()就可以拿到父进程的ID。
import os if __name__ == '__main__': print('进程 (%s) start...' % os.getpid()) pid = os.fork() # time.sleep(10) if pid == 0: # 若fork()返回0为子进程 print("子进程{},父进程{}".format(os.getpid(), os.getppid())) #getpid()获取当前进程的pid,getppid()获取父进程的pid else: # 父进程fork返回子进程的id print("父进程{},子进程{}".format(os.getpid(), pid)) >> 进程 (3130) start... 父进程3130,子进程3131 子进程3131,父进程3130
multiprocessing模块介绍
python中的多线程无法利用CPU资源,在python中大部分计算密集型任务使用多进程。如果想要充分地使用多核CPU的资源(os.cpu_count()查看)
python中提供了非常好的多进程包multiprocessing。
multiprocessing模块用来开启子进程,并在子进程中执行功能(函数),该模块与多线程模块threading的编程接口类似。
multiprocessing的功能众多:支持子进程、通信和共享数据、执行不同形式的同步,提供了Process、Queue、Pipe、Lock等组件。
计算密集型任务:如金融分析,科学计算
multiprocessing.current_process() :在任何一个进程中搞清楚自己是谁,在线程中也有类似方法

Process类的介绍
1.创建进程的类
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) 强调: 1. 需要使用关键字的方式来指定参数 2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
2.参数介绍
group参数未使用,值始终为None target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元组,args=(1,2,'al',) kwargs表示调用对象的字典,kwargs={'name':'al','age':18} name为子进程的名称
3.方法介绍
p.start():启动进程,并调用该子进程中的p.run()
p.run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。
如果p还保存了一个锁那么也将不会被释放,进而导致死锁,线程中无此方法
p.is_alive():如果p仍然运行,返回True
p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)再往下运行。timeout是可选的超时时间,
需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
4.属性介绍
p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置
p.name:进程的名称
p.pid:进程的pid,线程中是t.ident 注意只有进程或线程已经启动才会分配pid或ident
p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可)
p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,
这类连接只有在具有相同的身份验证键时才能成功(了解即可)
以用面向对象的形式使用进程与线程
关键点:
- 继承Process或Thread类
- 重写__init__方法
- 重写run方法
from multiprocessing import Process import time import random import os
class pro(Process): #继承Process类 def __init__(self,name): super().__init__() # 重写__init__方法 这里是直接调用父类的初始化方法 self.name = name
def run(self): # 重写run方法 print('%s is working,父进程%s,当前进程%s'%(self.name,os.getppid(),os.getpid())) time.sleep(1) print('%s end'%self.name)
if __name__ =='__main__': p1 = pro('a') p2 = pro('b') p3 = pro('c') p1.start() p2.start() p3.start() print('主进程',os.getpid()) >> 主进程 9116 b is working,父进程9116,当前进程4316 a is working,父进程9116,当前进程6664 c is working,父进程9116,当前进程10132 b end a end c end
总结:
Windows用的导入(所以if...main...判断外面的代码,在子进程仍会执行) 方法: p = Process(target=func,name='p1',daemon=True) #实例的时候可以指定方法、名字、是否守护进程 p.current_process() 获取当前进程对象 p.is_alive() 判断进程实例是否在运行 是返回True 否返回False p.terminate() 结束进程 线程无此方法 p.name 获取进程名字 p.join() 等待子进程结束再往下执行 p.daemon = True 把进程设为守护进程 (父进程结束,守护进程也结束) 注意:如果设置了join() 那么terminate和daemon 就不管用啦 p.pid 获取当前进程的pid 线程是t.ident 注意:只有进程(或线程)启动之后,操作系统(或python解释器)才会分配pid(或ident) 默认在子进程当中,会关闭标准输入 import sys import os sys.stdin = os.fdopen(0) #加上这行代码,子进程才能使用标准输入 多线程的方法与属性 t.setDaemon(True) t.setName('p1') t.getName()

