


mysql中#和$的区别,1 #会自带双引号,$不会;2 ${}变量替换发生在动态sql解析阶段,而#{}在动态解析阶段只有个占位符?
3一般表名、或者不经常改变的字段,如排序就使用$。 重点是理解2,3,然后说说就行。
说一下Springmvc。 springmvc的主要组件dispatcherservlet,HandlerMapping,HandlerAdapter,Handler,ViewResolver,View。
jvm https://www.jianshu.com/p/76959115d486, 面试https://www.cnblogs.com/lfs2640666960/p/9297176.html
java虚拟机管理的内存将分为下面五大区域。
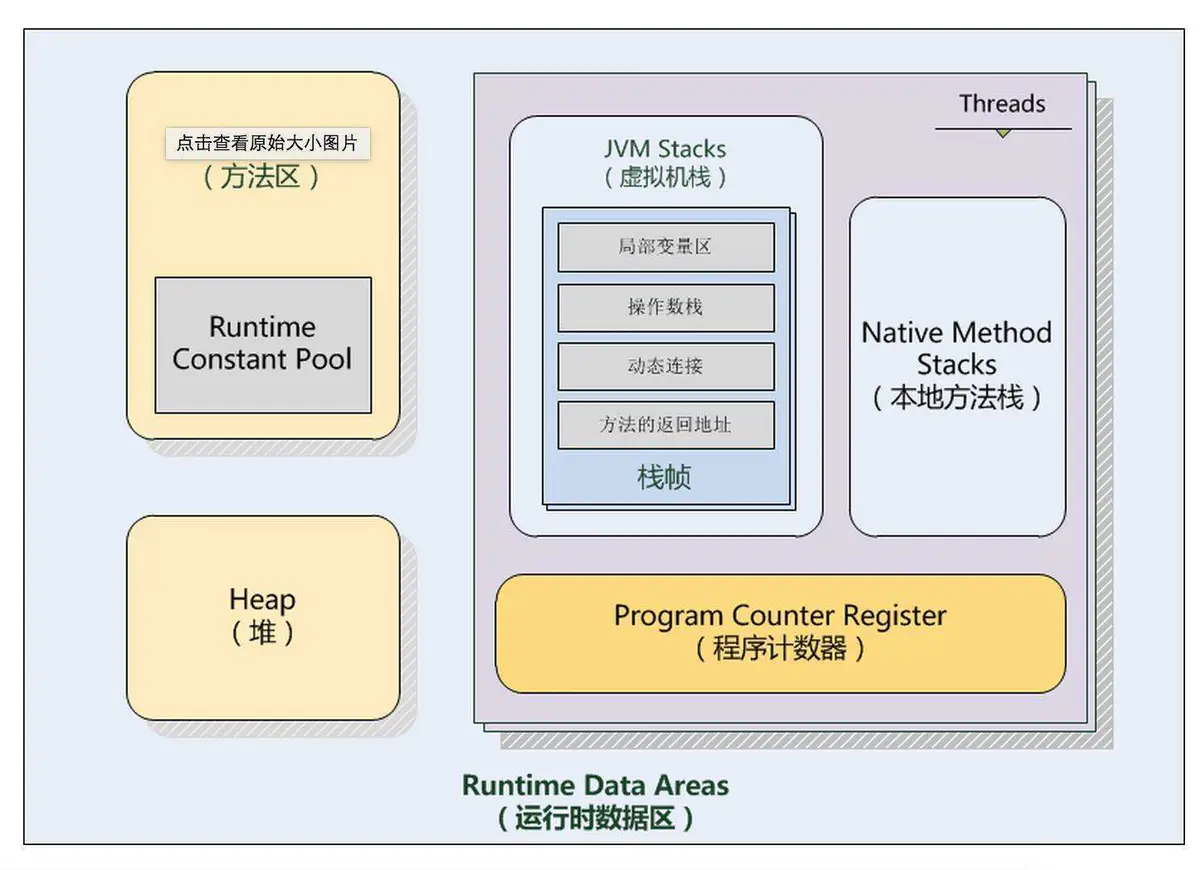
程序计数器
程序计数器是一块很小的内存空间,它是线程私有的,可以认作为当前线程的行号指示器。Java栈(虚拟机栈)
栈描述的是Java方法执行的内存模型。每个方法被执行的时候都会创建一个栈帧用于存储局部变量表,操作栈,动态链接,方法出口等信息。每一个方法被调用的过程就对应一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表:一片连续的内存空间,用来存放方法参数,以及方法内定义的局部变量,存放着编译期间已知的数据类型(八大基本类型和对象引用(reference类型),returnAddress类型。它的最小的局部变量表空间单位为Slot,虚拟机没有指明Slot的大小,但在jvm中,long和double类型数据明确规定为64位,这两个类型占2个Slot,其它基本类型固定占用1个Slot。
reference类型:与基本类型不同的是它不等同本身,即使是String,内部也是char数组组成,它可能是指向一个对象起始位置指针,也可能指向一个代表对象的句柄或其他与该对象有关的位置。
本地方法栈
堆
堆是java虚拟机管理内存最大的一块内存区域,因为堆存放的对象是线程共享的,所以多线程的时候也需要同步机制
方法区
用于存储已被虚拟机加载的类信息、常量、静态变量,如static修饰的变量加载类的时候就被加载到方法区中
dubbo
拦截器,过滤器https://www.jianshu.com/p/cbe0bc8780da ,依赖servlet,发生的时间不同,发生的原理不同
dubbo,服务,消费,注册,监控。nio,tcp,future。https://www.cnblogs.com/shan1393/p/9338530.html。重试机制,怎么配置。
长连接和短连接的区别 https://blog.csdn.net/castletower/article/details/104048920?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase 其实就是tcp连接保持和不保持的区别,加个心跳探测。
future在dubbo中的使用
http和https的区别 https://blog.csdn.net/qq_38289815/article/details/80969419
网络的七层和4层,https://www.cnblogs.com/sunsky303/p/10647255.html,http应用层,TCP传输层。
linux 常见命令操作 https://blog.csdn.net/shenaisi/article/details/81488187
①.判断键值对数组table[i]是否为空或为null,否则执行resize()进行扩容;
②.根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加,转向⑥,如果table[i]不为空,转向③;
③.判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
④.判断table[i] 是否为treeNode,即table[i] 是否是红黑树,如果是红黑树,则直接在树中插入键值对,否则转向⑤;
⑤.遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
⑥.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
1、交换机的名称
* 2、交换机的类型
* fanout:对应的rabbitmq的工作模式是 publish/subscribe
* direct:对应的Routing 工作模式
* topic:对应的Topics工作模式
* headers: 对应的headers工作模式
Work quenes :
多个消费者共同监听一个队列,消息不能被重复消费,rabbitMQ采用轮询的方式将消息平均发送给消费者。有一个默认的交换机
应用场景:对于复杂的运算,可以采用多个消费者进行消费
一个生产者发生产,多个消费者依次接受
发布订阅模式
运行原理:
1、一个生产者将消息发给交换机
2、与交换机绑定的有多个队列,每个消费者监听自己的队列
3、生产者将消息发给交换机,由交换机将消息转发到绑定此交换机的每个队列,每个绑定交换机的队列都将接受到消息。
相比工作模式,可以一个消息多个消费者接收
使用场景:转账成功了,需要通知方式短信,邮件等
路由模式
1、一个交换机绑定多个队列,每个队列设置routingkey,并且一个队列可以设置多个routingkey
2、每个消费者监听自己的队列
3、生产者将消息发给交换机,发送消息时需要制定routingKey,交换机来判断该routingkey的值和那个队列的routingKey相等,如果相等则将消息转发给该队列
通配符有两种:
*号 和#号
#号:匹配一个或者多个词,比如inform,inform.sms,inform.email,inform.email.sms等
号:只能匹配一个词,比如inform.,可以匹配inform.sms,inform.email,inform.email.sms不可以
代码修改只需要在队列修改
Header模式
header模式与routing不同的地方在于,header模式取消routingkey,使用header中的key/value(键值对)匹配队列。
RPC即客户端远程调用服务端的方法 ,使用MQ可以实现RPC的异步调用,基于Direct交换机实现,流程如下:
1、客户端即是生产者就是消费者,向RPC请求队列发送RPC调用消息,同时监听RPC响应队列。
2、服务端监听RPC请求队列的消息,收到消息后执行服务端的方法,得到方法返回的结果
3、服务端将RPC方法 的结果发送到RPC响应队列
4、客户端(RPC调用方)监听RPC响应队列,接收到RPC调用结果。
mysql的优化,能用左联就不要用in
唯一索引 组合索引的区别
接口和抽象类 https://blog.csdn.net/cillyb/article/details/81611090
springboot项目里面端口号的配置
set里为什么是唯一的 https://www.cnblogs.com/lyhc/p/10470702.html
父类的private属性子类能访问吗 https://blog.csdn.net/shadow_zed/article/details/82182087?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase 不能直接访问,可以通过super访问
controller和restcontroller的区别https://www.cnblogs.com/shuaifing/p/8119664.html
@RestController注解,相当于@Controller+@ResponseBody两个注解的结合,返回json数据不需要在方法前面加@ResponseBody注解了,但使用@RestController这个注解,就不能返回jsp,html页面,视图解析器无法解析jsp,html页面
rabbitmq如何处理消息丢失问题 https://www.cnblogs.com/756623607-zhang/p/10507267.html https://blog.csdn.net/u013256816/article/details/55515234/
实现线程的方式
创建线程池的方式 https://blog.csdn.net/qq_36381855/article/details/79942555
线程的5种状态 https://blog.csdn.net/xingjing1226/article/details/81977129
有没有对线程池里面的队列做过缓存,
给以一个执行很慢的sql,怎么排查这个sql哪里执行的慢,怎么优化
https://blog.csdn.net/qq_32603969/article/details/102819830
https://www.cnblogs.com/knowledgesea/p/3686105.html
- 内连接结果集大小取决于左右表满足条件的数量
- 左连接取决与左表大小,右相反。
- 完全连接和交叉连接取决与左右两个表的数据总数量
- distinct在查询一个字段或者很少字段的情况下使用,会避免重复数据的出现,给查询带来优化效果
- 菜鸟https://www.runoob.com/sql/sql-having.html
- having SELECT Websites.name, Websites.url, SUM(access_log.count) AS nums FROM (access_log INNER JOIN Websites ON access_log.site_id=Websites.id) GROUP BY Websites.name HAVING SUM(access_log.count) > 200;
- inner join SELECT Websites.name, access_log.count, access_log.date
FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count;
事物有哪几种传播机制
数据库的acid
stream和fileter的区别https://blog.csdn.net/qq_43045259/article/details/105789620
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
filter顾名思义过滤器,它是stream的一个方法
list.stream().filter(s -> !pids.contains(s)).forEach(i -> System.out.println(i));
线程的状态分析https://blog.csdn.net/qq_43322057/article/details/105884484
https://www.cnblogs.com/fuck1/p/5373616.html
几种阻塞的区别
wait,sleep,join,
wait sleep的区别,https://blog.csdn.net/qiuchaoxi/article/details/79837568
sleep()是使线程暂停执行一段时间的方法。wait()也是一种使线程暂停执行的方法。例如,当线程执行wait()方法时候,会释放当前的锁,然后让出CPU,进入等待状态。并且可以调用notify()方法或者notifyAll()方法通知正在等待的其他线程。notify()方法仅唤醒一个线程(等待队列中的第一个线程)并允许他去获得锁。notifyAll()方法唤醒所有等待这个对象的线程并允许他们去竞争获得锁。具体区别如下:
1) 原理不同。sleep()方法是Thread类的静态方法,是线程用来控制自身流程的,他会使此线程暂停执行一段时间,而把执行机会让给其他线程,等到计时时间一到,此线程会自动苏醒。例如,当线程执行报时功能时,每一秒钟打印出一个时间,那么此时就需要在打印方法前面加一个sleep()方法,以便让自己每隔一秒执行一次,该过程如同闹钟一样。而wait()方法是object类的方法,用于线程间通信,这个方法会使当前拥有该对象锁的进程等待,直到其他线程调用notify()方法或者notifyAll()时才醒来,不过开发人员也可以给他指定一个时间,自动醒来。
2) 对锁的 处理机制不同。由于sleep()方法的主要作用是让线程暂停执行一段时间,时间一到则自动恢复,不涉及线程间的通信,因此,调用sleep()方法并不会释放锁。而wait()方法则不同,当调用wait()方法后,线程会释放掉他所占用的锁,从而使线程所在对象中的其他synchronized数据可以被其他线程使用。
3) 使用区域不同。wait()方法必须放在同步控制方法和同步代码块中使用,sleep()方法则可以放在任何地方使用。sleep()方法必须捕获异常,而wait()、notify()、notifyAll()不需要捕获异常。在sleep的过程中,有可能被其他对象调用他的interrupt(),产生InterruptedException。由于sleep不会释放锁标志,容易导致死锁问题的发生,因此一般情况下,推荐使用wait()方法。
Thread.sleep(0)是让系统重新做一次cpu竞争,
https://blog.csdn.net/wm5920/article/details/89067205 sleep和wait,线程状态
https://www.cnblogs.com/hoobey/p/6915638.html
linkedblockqueue 实现锁的通过锁分离的方式实现的
从队列中取出并添加元素的方法有:put,add,poll
put: 若向队尾添加元素的时候发现队列已经满了会发生阻塞一直等待空间,以加入元素。
notFull.await();
add:若超出了度列的长度会直接抛出异常。
if (offer(e))
return true;
else
throw new IllegalStateException("Queue full");
offer:若队列已满,返回false。
if (count.get() == capacity)
return false;
--------------------
从队列中取出并移除元素的方法有:poll,remove,take
poll: 若队列为空,返回null。
if (count.get() == 0)
return null;
remove:若队列为空,
if (o == null) return false;
take:若队列为空,发生阻塞,等待有元素。
while (count.get() == 0) {
notEmpty.await();
}
aop 什么是切面https://blog.csdn.net/u013782203/article/details/51799427
https://www.cnblogs.com/handsomeye/p/5999362.html
https://blog.csdn.net/u010842515/article/details/67634813
https://blog.csdn.net/qq_32099833/article/details/103149102 实现锁的方式。
threadlocal使用时需要注意以下几点:
- 线程之间的threadLocal变量是互不影响的,
- 使用private final static进行修饰,防止多实例时内存的泄露问题
- 线程池环境下使用后将threadLocal变量remove掉或设置成一个初始值
大佬的研究https://blog.csdn.net/zzg1229059735/article/details/82715741 ,跟着学习。
ThreadLocal和Thread的关系
ThreadLocalMap,Entry两个静态内部内

