

感谢:原文地址: http://blog.csdn.net/zhangerqing/article/details/8193118 ;
Java集合类是一个非常重要的知识,HashMap,HashTable、ConcurrentHashMap是集合中的重点
第一个问题:hashMap Vs hashTable 区别:
1.HashMap是非安全的,HashTable是线程安全的;
2.HashMap的键值允许null值,Hashtable 中不允许出现null
3.HashMap 线程不安全不,运行的速度比hashTable快。
第二个问题:Java中的另一个线程安全与HashMap 很类似的类是什么?同样是线程安全,它与HashTable在线程同步上有什么不同?
1.理解HashMap 的内部数据存储结构:
1).java中数据的存储方式最底层两种数据结构,一种是数组,另外一种是链表;
数组特点:连续的空间寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢;
链表:空间不联系但是在删除和添加元素时候快,查询缓慢,增删快。
哈希表综合两种的优点: 具有较强的查询速度和较快的增删速度,所以适合海量的数据处理,构建哈希表有两种方式 开放地址法和分离链表的方法。
一般实现哈希表采用的分离链表的方法,哈希函数借用Honer法则:对于其中TableSize的选取:TableSize=取接近N最小的素数,让随机数散列较为均匀
当capacity> initialcapacity capacity<<1 将容量扩大两倍,在开放地址方法有具体的体现,Java只是对这种方法进行封装
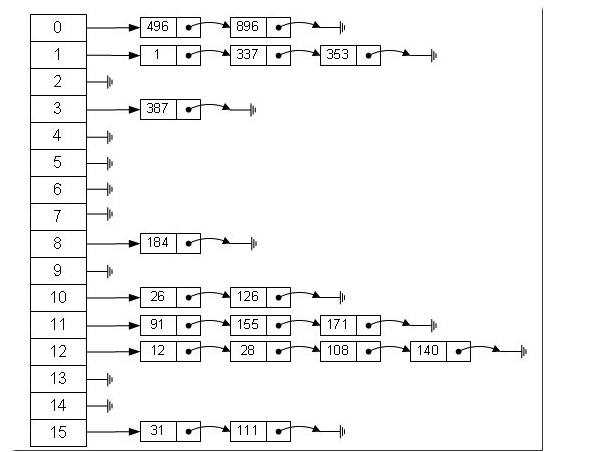
从上图中,我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。它的内部其实是用一个Entity数组来实现的,属性有key、value、next。接下来我会从初始化阶段详细的讲解HashMap的内部结构。
二、HashTable的内部存储结构
HashTable和HashMap采用相同的存储机制,二者的实现基本一致,不同的是:
1、HashMap是非线程安全的,HashTable是线程安全的,内部的方法基本都是synchronized。
2、HashTable不允许有null值的存在。
在HashTable中调用put方法时,如果key为null,直接抛出NullPointerException。其它细微的差别还有,比如初始化Entry数组的大小等等,但基本思想和HashMap一样。
三.对开头的问题的回答:
ConcurrentHashMap是线程安全的 基于HashMap实现的 Hashtable 的同步是通过加关键字synchronized关键字,其实加的对象锁,锁住对象的本体,采用的是阻塞的方式,ConcurrenthashMap 的同步加的lock锁,采用CAS原子操作方式,lock锁非阻塞的情况,关于CAS操作:
注意:HashMap中排序按照 值进行排序,所以保证有不同的关键字
1.集合框架:
Java中集合框架有两大根接口 Map 和collection 类
|------ Collection
|----Queue集合
|---PriorityQueen优先队列的方法,堆的方式
|-----List(有序的collection接口保存重复的对象)
|-----ArrayList、LinkedList 、Vector 主要实现类ArrayList 和LinkedList; Vector类古老的集合类主stack类
|----Set(集合中元素不能重复,自定义类中判断相同的对象必须重写自定类的equals方法和hashcode方法)
HashSet +LinkedhashSet+TreeSet 主要实现类HashSet ;
HashSet底层基于散列实现的有Set集合特性对于自定义的类重写其中的equals方法和hashCode方法(属性值一样hashCode一样Set首先通过HashCode计算对象位置,比较对象中equals方法)
TreeSet的底层基于红黑树的数据结构实现实现的SortSet的接口,只能装入同一类的对象分为自然排序(自定类实现Comparable接口)+定制排序(自定类实现Comparator接口匿名内部类方法)。
LinkedHashSet 特性如何通过链表进行地址链接 遍历输出顺序按照元素添加顺序输出。
|-----Map (键-value存在的映射)
|----HashMap(主要实现类)--类同于HashSet----线程不安全的 ,
|-----Hashtable 线程安全的操作
|----proprtties
|----TreeMap---类同于Set集合下TreeSet 有自然排序和定制排序实现SortMap接口
2. 理解概念:无序 指的是元素底存储的位置是无序的并不想数组一样开辟地址连续的地址块。
HashSet(HashMap)有Set集合的特定,总结 Java首先通过hashCode 判断对象存储位置,最后比较对象位置上的equals方法。
3.HashMap Vs Hashtable:
HashMap与Hashtable实现的Map集合接口,Map集合接口 键值与value 之间的映射,Key实现Set的接口因此Key不能够进行重复,value可以进行重复,遍历采样迭代器方法 map.EntrrSet()的方法,记住在遍历同时不能删除或者增加元素,这样导致抛出 Java.util.concurrentModifycationException()。
区别:
1.HashMap线程不安全 hashtable线程安全底层都使用sychronized关键字进行封装,因此运算速度HashMap>Hashtable,实际多线程中使用concurrentHashMap(线程通信CAS技术)不采用collections工具箱Collections.synchronizedMap(new hashMap())进行封装。
2.hashMap的key 有null 但是hashtable key不能有NULL值
3.HashMap去掉Hashtable的contains方法,增加了conatinsValue和containsKey方法
4.HashMap默认数组长度16,扩大是2的指数,Hashtable默认数组长度11 增加方式old*2+1.
concurrentHashMap Vs hashtable
两者都是线程安全的操作 最大区别是两者之间 锁的粒度和锁方式。
hashtable 用的synchronized关键字 使用一种悲观锁的概念,多个线程不能进入到临界区在临界区的外部进行等待锁的释放,concuurentHashMap采用Lock关键积极锁概念 多个线程进入临界区里面 在CAS竞争的方式获取锁(无锁的方法)。
hashtable锁住整张的hash表,concurentHashMap 字段锁(hash表分为16个字段)在读操作JDK1.5 并发进行,只是锁住的写操作使用重置锁。
4.hashCode 方法和equals方法:

