从零开始实现一个玩具版浏览器渲染引擎
前言
浏览器渲染原理作为前端必须要了解的知识点之一,在面试中经常会被问到。在一些前端书籍或者培训课程里也会经常被提及,比如 MDN 文档中就有渲染原理的相关描述。
作为一名工作多年的前端,我对于渲染原理自然也是了解的,但是对于它的理解只停留在理论知识层面。所以我决定自己动手实现一个玩具版的渲染引擎。
渲染引擎是浏览器的一部分,它负责将网页内容(HTML、CSS、JavaScript 等)转化为用户可阅读、观看、听到的形式。但是要独自实现一个完整的渲染引擎工作量实在太大了,而且也很困难。于是我决定退一步,打算实现一个玩具版的渲染引擎。刚好 Github 上有一个开源的用 Rust 写的玩具版渲染引擎 robinson,于是决定模仿其源码自己用 JavaScript 实现一遍,并且也在 Github 上开源了 从零开始实现一个玩具版浏览器渲染引擎。
这个玩具版的渲染引擎一共分为五个阶段:
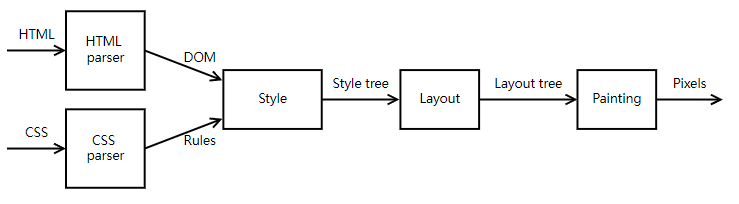
分别是:
- 解析 HTML,生成 DOM 树
- 解析 CSS,生成 CSS 规则集合
- 生成 Style 树
- 生成布局树
- 绘制
每个阶段的代码我在仓库上都用一个分支来表示。由于直接看整个渲染引擎的代码可能会比较困难,所以我建议大家从第一个分支开始进行学习,从易到难,这样学习效果更好。
现在我们先看一下如何编写一个 HTML 解析器。
HTML 解析器
HTML 解析器的作用就是将一连串的 HTML 文本解析为 DOM 树。比如将这样的 HTML 文本:
<div class="lightblue test" id=" div " data-index="1">test!</div>
解析为一个 DOM 树:
{
"tagName": "div",
"attributes": {
"class": "lightblue test",
"id": "div",
"data-index": "1"
},
"children": [
{
"nodeValue": "test!",
"nodeType": 3
}
],
"nodeType": 1
}
写解析器需要懂一些编译原理的知识,比如词法分析、语法分析什么的。但是我们的玩具版解析器非常简单,即使不懂也没有关系,大家看源码就能明白了。
再回到上面的那段 HTML 文本,它的整个解析过程可以用下面的图来表示,每一段 HTML 文本都有对应的方法去解析。

为了让解析器实现起来简单一点,我们需要对 HTML 的功能进行约束:
- 标签必须要成对出现:
<div>...</div> - HTML 属性值必须要有引号包起来
<div class="test">...</div> - 不支持注释
- 尽量不做错误处理
- 只支持两种类型节点
Element和Text
对解析器的功能进行约束后,代码实现就变得简单多了,现在让我们继续吧。
节点类型
首先,为这两种节点 Element 和 Text 定一个适当的数据结构:
export enum NodeType {
Element = 1,
Text = 3,
}
export interface Element {
tagName: string
attributes: Record<string, string>
children: Node[]
nodeType: NodeType.Element
}
interface Text {
nodeValue: string
nodeType: NodeType.Text
}
export type Node = Element | Text
然后为这两种节点各写一个生成函数:
export function element(tagName: string) {
return {
tagName,
attributes: {},
children: [],
nodeType: NodeType.Element,
} as Element
}
export function text(data: string) {
return {
nodeValue: data,
nodeType: NodeType.Text,
} as Text
}
这两个函数在解析到元素节点或者文本节点时调用,调用后会返回对应的 DOM 节点。
HTML 解析器的执行过程
下面这张图就是整个 HTML 解析器的执行过程:

HTML 解析器的入口方法为 parse(),从这开始执行直到遍历完所有 HTML 文本为止:
- 判断当前字符是否为
<,如果是,则当作元素节点来解析,调用parseElement(),否则调用parseText() parseText()比较简单,一直往前遍历字符串,直至遇到<字符为止。然后将之前遍历过的所有字符当作Text节点的值。parseElement()则相对复杂一点,它首先要解析出当前的元素标签名称,这段文本用parseTag()来解析。- 然后再进入
parseAttrs()方法,判断是否有属性节点,如果该节点有class或者其他 HTML 属性,则会调用parseAttr()把 HTML 属性或者class解析出来。 - 至此,整个元素节点的前半段已经解析完了。接下来需要解析它的子节点。这时就会进入无限递归循环回到第一步,继续解析元素节点或文本节点。
- 当所有子节点解析完后,需要调用
parseTag(),看看结束标签名和元素节点的开始标签名是否相同,如果相同,则parseElement()或者parse()结束,否则报错。
HTML 解析器各个方法详解
入口方法 parse()
HTML 的入口方法是 parse(rawText)
parse(rawText: string) {
this.rawText = rawText.trim()
this.len = this.rawText.length
this.index = 0
this.stack = []
const root = element('root')
while (this.index < this.len) {
this.removeSpaces()
if (this.rawText[this.index].startsWith('<')) {
this.index++
this.parseElement(root)
} else {
this.parseText(root)
}
}
}
入口方法需要遍历所有文本,在一开始它需要判断当前字符是否是 <,如果是,则将它当作元素节点来解析,调用 parseElement(),否则将当前字符作为文本来解析,调用 parseText()。
解析元素节点 parseElement()
private parseElement(parent: Element) {
// 解析标签
const tag = this.parseTag()
// 生成元素节点
const ele = element(tag)
this.stack.push(tag)
parent.children.push(ele)
// 解析属性
this.parseAttrs(ele)
while (this.index < this.len) {
this.removeSpaces()
if (this.rawText[this.index].startsWith('<')) {
this.index++
this.removeSpaces()
// 判断是否是结束标签
if (this.rawText[this.index].startsWith('/')) {
this.index++
const startTag = this.stack[this.stack.length - 1]
// 结束标签
const endTag = this.parseTag()
if (startTag !== endTag) {
throw Error(`The end tagName ${endTag} does not match start tagName ${startTag}`)
}
this.stack.pop()
while (this.index < this.len && this.rawText[this.index] !== '>') {
this.index++
}
break
} else {
this.parseElement(ele)
}
} else {
this.parseText(ele)
}
}
this.index++
}
parseElement() 会依次调用 parseTag() parseAttrs() 解析标签和属性,然后再递归解析子节点,终止条件是遍历完所有的 HTML 文本。
解析文本节点 parseText()
private parseText(parent: Element) {
let str = ''
while (
this.index < this.len
&& !(this.rawText[this.index] === '<' && /\w|\//.test(this.rawText[this.index + 1]))
) {
str += this.rawText[this.index]
this.index++
}
this.sliceText()
parent.children.push(text(removeExtraSpaces(str)))
}
解析文本相对简单一点,它会一直往前遍历,直至遇到 < 为止。比如这段文本 <div>test!</div>,经过 parseText() 解析后拿到的文本是 test!。
解析标签 parseTag()
在进入 parseElement() 后,首先调用就是 parseTag(),它的作用是解析标签名:
private parseTag() {
let tag = ''
this.removeSpaces()
// get tag name
while (this.index < this.len && this.rawText[this.index] !== ' ' && this.rawText[this.index] !== '>') {
tag += this.rawText[this.index]
this.index++
}
this.sliceText()
return tag
}
比如这段文本 <div>test!</div>,经过 parseTag() 解析后拿到的标签名是 div。
解析属性节点 parseAttrs()
解析完标签名后,接着再解析属性节点:
// 解析元素节点的所有属性
private parseAttrs(ele: Element) {
// 一直遍历文本,直至遇到 '>' 字符为止,代表 <div ....> 这一段文本已经解析完了
while (this.index < this.len && this.rawText[this.index] !== '>') {
this.removeSpaces()
this.parseAttr(ele)
this.removeSpaces()
}
this.index++
}
// 解析单个属性,例如 class="foo bar"
private parseAttr(ele: Element) {
let attr = ''
let value = ''
while (this.index < this.len && this.rawText[this.index] !== '=' && this.rawText[this.index] !== '>') {
attr += this.rawText[this.index++]
}
this.sliceText()
attr = attr.trim()
if (!attr.trim()) return
this.index++
let startSymbol = ''
if (this.rawText[this.index] === "'" || this.rawText[this.index] === '"') {
startSymbol = this.rawText[this.index++]
}
while (this.index < this.len && this.rawText[this.index] !== startSymbol) {
value += this.rawText[this.index++]
}
this.index++
ele.attributes[attr] = value.trim()
this.sliceText()
}
parseAttr() 可以将这样的文本 class="test" 解析为一个对象 { class: "test" }。
其他辅助方法
有时不同的节点、属性之间有很多多余的空格,所以需要写一个方法将多余的空格清除掉。
protected removeSpaces() {
while (this.index < this.len && (this.rawText[this.index] === ' ' || this.rawText[this.index] === '\n')) {
this.index++
}
this.sliceText()
}
同时为了方便调试,开发者经常需要打断点看当前正在遍历的字符是什么。如果以前遍历过的字符串还在,那么是比较难调试的,因为开发者需要根据 index 的值自己去找当前遍历的字符是什么。所以所有解析完的 HTML 文本,都需要截取掉,确保当前的 HTML 文本都是没有被遍历:
protected sliceText() {
this.rawText = this.rawText.slice(this.index)
this.len = this.rawText.length
this.index = 0
}
sliceText() 方法的作用就是截取已经遍历过的 HTML 文本。用下图来做例子,假设当前要解析 div 这个标签名:

那么解析后需要对 HTML 文本进行截取,就像下图这样:

小结
至此,整个 HTML 解析器的逻辑已经讲完了,所有代码加起来 200 行左右,如果不算 TS 各种类型声明,代码只有 100 多行。
CSS 解析器
CSS 样式表是一系列的 CSS 规则集合,而 CSS 解析器的作用就是将 CSS 文本解析为 CSS 规则集合。
div, p {
font-size: 88px;
color: #000;
}
例如上面的 CSS 文本,经过解析器解析后,会生成下面的 CSS 规则集合:
[
{
"selectors": [
{
"id": "",
"class": "",
"tagName": "div"
},
{
"id": "",
"class": "",
"tagName": "p"
}
],
"declarations": [
{
"name": "font-size",
"value": "88px"
},
{
"name": "color",
"value": "#000"
}
]
}
]
每个规则都有一个 selector 和 declarations 属性,其中 selectors 表示 CSS 选择器,declarations 表示 CSS 的属性描述集合。
export interface Rule {
selectors: Selector[]
declarations: Declaration[]
}
export interface Selector {
tagName: string
id: string
class: string
}
export interface Declaration {
name: string
value: string | number
}

每一条 CSS 规则都可以包含多个选择器和多个 CSS 属性。
解析 CSS 规则 parseRule()
private parseRule() {
const rule: Rule = {
selectors: [],
declarations: [],
}
rule.selectors = this.parseSelectors()
rule.declarations = this.parseDeclarations()
return rule
}
在 parseRule() 里,它分别调用了 parseSelectors() 去解析 CSS 选择器,然后再对剩余的 CSS 文本执行 parseDeclarations() 去解析 CSS 属性。
解析选择器 parseSelector()
private parseSelector() {
const selector: Selector = {
id: '',
class: '',
tagName: '',
}
switch (this.rawText[this.index]) {
case '.':
this.index++
selector.class = this.parseIdentifier()
break
case '#':
this.index++
selector.id = this.parseIdentifier()
break
case '*':
this.index++
selector.tagName = '*'
break
default:
selector.tagName = this.parseIdentifier()
}
return selector
}
private parseIdentifier() {
let result = ''
while (this.index < this.len && this.identifierRE.test(this.rawText[this.index])) {
result += this.rawText[this.index++]
}
this.sliceText()
return result
}
选择器我们只支持标签名称、前缀为 # 的 ID 、前缀为任意数量的类名 . 或上述的某种组合。如果标签名称为 *,则表示它是一个通用选择器,可以匹配任何标签。
标准的 CSS 解析器在遇到无法识别的部分时,会将它丢掉,然后继续解析其余部分。主要是为了兼容旧浏览器和防止发生错误导致程序中断。我们的 CSS 解析器为了实现简单,没有做这方面的做错误处理。
解析 CSS 属性 parseDeclaration()
private parseDeclaration() {
const declaration: Declaration = { name: '', value: '' }
this.removeSpaces()
declaration.name = this.parseIdentifier()
this.removeSpaces()
while (this.index < this.len && this.rawText[this.index] !== ':') {
this.index++
}
this.index++ // clear :
this.removeSpaces()
declaration.value = this.parseValue()
this.removeSpaces()
return declaration
}
parseDeclaration() 会将 color: red; 解析为一个对象 { name: "color", value: "red" }。
小结
CSS 解析器相对来说简单多了,因为很多知识点在 HTML 解析器中已经讲到。整个 CSS 解析器的代码大概 100 多行,如果你阅读过 HTML 解析器的源码,相信看 CSS 解析器的源码会更轻松。
构建样式树
本阶段的目标是写一个样式构建器,输入 DOM 树和 CSS 规则集合,生成一棵样式树 Style tree。
样式树的每一个节点都包含了 CSS 属性值以及它对应的 DOM 节点引用:
interface AnyObject {
[key: string]: any
}
export interface StyleNode {
node: Node // DOM 节点
values: AnyObject // style 属性值
children: StyleNode[] // style 子节点
}
先来看一个简单的示例:
<div>test</div>
div {
font-size: 88px;
color: #000;
}
上述的 HTML、CSS 文本在经过样式树构建器处理后生成的样式树如下:
{
"node": { // DOM 节点
"tagName": "div",
"attributes": {},
"children": [
{
"nodeValue": "test",
"nodeType": 3
}
],
"nodeType": 1
},
"values": { // CSS 属性值
"font-size": "88px",
"color": "#000"
},
"children": [ // style tree 子节点
{
"node": {
"nodeValue": "test",
"nodeType": 3
},
"values": { // text 节点继承了父节点样式
"font-size": "88px",
"color": "#000"
},
"children": []
}
]
}
遍历 DOM 树
现在我们需要遍历 DOM 树。对于 DOM 树中的每个节点,我们都要在样式树中查找是否有匹配的 CSS 规则。
export function getStyleTree(eles: Node | Node[], cssRules: Rule[], parent?: StyleNode) {
if (Array.isArray(eles)) {
return eles.map((ele) => getStyleNode(ele, cssRules, parent))
}
return getStyleNode(eles, cssRules, parent)
}
匹配选择器
匹配选择器实现起来非常容易,因为我们的CSS 解析器仅支持简单的选择器。 只需要查看元素本身即可判断选择器是否与元素匹配。
/**
* css 选择器是否匹配元素
*/
function isMatch(ele: Element, selectors: Selector[]) {
return selectors.some((selector) => {
// 通配符
if (selector.tagName === '*') return true
if (selector.tagName === ele.tagName) return true
if (ele.attributes.id === selector.id) return true
if (ele.attributes.class) {
const classes = ele.attributes.class.split(' ').filter(Boolean)
const classes2 = selector.class.split(' ').filter(Boolean)
for (const name of classes) {
if (classes2.includes(name)) return true
}
}
return false
})
}
当查找到匹配的 DOM 节点后,再将 DOM 节点和它匹配的 CSS 属性组合在一起,生成样式树节点 styleNode:
function getStyleNode(ele: Node, cssRules: Rule[], parent?: StyleNode) {
const styleNode: StyleNode = {
node: ele,
values: getStyleValues(ele, cssRules, parent),
children: [],
}
if (ele.nodeType === NodeType.Element) {
// 合并内联样式
if (ele.attributes.style) {
styleNode.values = { ...styleNode.values, ...getInlineStyle(ele.attributes.style) }
}
styleNode.children = ele.children.map((e) => getStyleNode(e, cssRules, styleNode)) as unknown as StyleNode[]
}
return styleNode
}
function getStyleValues(ele: Node, cssRules: Rule[], parent?: StyleNode) {
const inheritableAttrValue = getInheritableAttrValues(parent)
// 文本节点继承父元素的可继承属性
if (ele.nodeType === NodeType.Text) return inheritableAttrValue
return cssRules.reduce((result: AnyObject, rule) => {
if (isMatch(ele as Element, rule.selectors)) {
result = { ...result, ...cssValueArrToObject(rule.declarations) }
}
return result
}, inheritableAttrValue)
}
在 CSS 选择器中,不同的选择器优先级是不同的,比如 id 选择器就比类选择器的优先级要高。但是我们这里没有实现选择器优先级,为了实现简单,所有的选择器优先级是一样的。
继承属性
文本节点无法匹配选择器,那它的样式从哪来?答案就是继承,它可以继承父节点的样式。
在 CSS 中存在很多继承属性,即使子元素没有声明这些属性,也可以从父节点里继承。比如字体颜色、字体家族等属性,都是可以被继承的。为了实现简单,这里只支持继承父节点的 color、font-size 属性。
// 子元素可继承的属性,这里只写了两个,实际上还有很多
const inheritableAttrs = ['color', 'font-size']
/**
* 获取父元素可继承的属性值
*/
function getInheritableAttrValues(parent?: StyleNode) {
if (!parent) return {}
const keys = Object.keys(parent.values)
return keys.reduce((result: AnyObject, key) => {
if (inheritableAttrs.includes(key)) {
result[key] = parent.values[key]
}
return result
}, {})
}
内联样式
在 CSS 中,内联样式的优先级是除了 !important 之外最高的。
<span style="color: red; background: yellow;">
我们可以在调用 getStyleValues() 函数获得当前 DOM 节点的 CSS 属性值后,再去取当前节点的内联样式值。并对当前 DOM 节点的 CSS 样式值进行覆盖。
styleNode.values = { ...styleNode.values, ...getInlineStyle(ele.attributes.style) }
function getInlineStyle(str: string) {
str = str.trim()
if (!str) return {}
const arr = str.split(';')
if (!arr.length) return {}
return arr.reduce((result: AnyObject, item: string) => {
const data = item.split(':')
if (data.length === 2) {
result[data[0].trim()] = data[1].trim()
}
return result
}, {})
}
布局树
第四阶段讲的是如何将样式树转化为布局树,也是整个渲染引擎相对比较复杂的部分。
CSS 盒子模型
在 CSS 中,所有的 DOM 节点都可以当作一个盒子。这个盒子模型包含了内容、内边距、边框、外边距以及在页面中的位置信息。
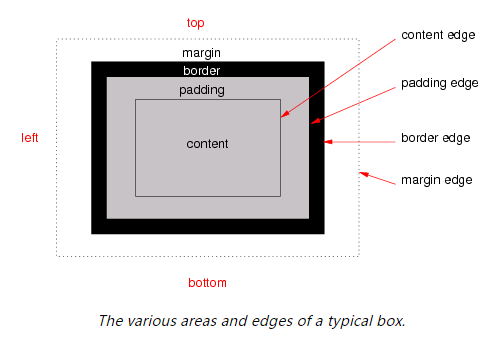
我们可以用以下的数据结构来表示盒子模型:
export default class Dimensions {
content: Rect
padding: EdgeSizes
border: EdgeSizes
margin: EdgeSizes
}
export default class Rect {
x: number
y: number
width: number
height: number
}
export interface EdgeSizes {
top: number
right: number
bottom: number
left: number
}
块布局和内联布局
CSS 的 display 属性决定了盒子在页面中的布局方式。display 的类型有很多种,例如 block、inline、flex 等等,但这里只支持 block 和 inline 两种布局方式,并且所有盒子的默认布局方式为 display: inline。
我会用伪 HTML 代码来描述它们之间的区别:
<container>
<a></a>
<b></b>
<c></c>
<d></d>
</container>
块布局会将盒子从上至下的垂直排列。
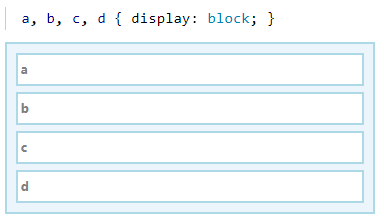
内联布局则会将盒子从左至右的水平排列。
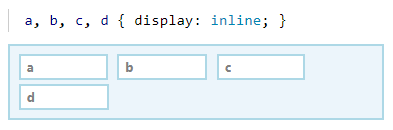
如果容器内同时存在块布局和内联布局,则会用一个匿名布局将内联布局包裹起来。
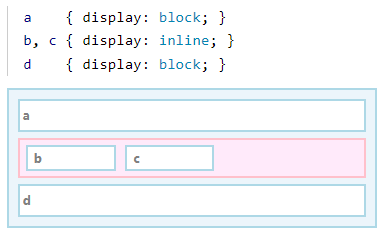
这样就能将内联布局的盒子和其他块布局的盒子区别开来。
通常情况下内容是垂直增长的。也就是说,在容器中添加子节点通常会使容器更高,而不是更宽。另一种说法是,默认情况下,子节点的宽度取决于其容器的宽度,而容器的高度取决于其子节点的高度。
布局树
布局树是所有盒子节点的集合。
export default class LayoutBox {
dimensions: Dimensions
boxType: BoxType
children: LayoutBox[]
styleNode: StyleNode
}
盒子节点的类型可以是 block、inilne 和 anonymous。
export enum BoxType {
BlockNode = 'BlockNode',
InlineNode = 'InlineNode',
AnonymousBlock = 'AnonymousBlock',
}
我们构建样式树时,需要根据每一个 DOM 节点的 display 属性来生成对应的盒子节点。
export function getDisplayValue(styleNode: StyleNode) {
return styleNode.values?.display ?? Display.Inline
}
如果 DOM 节点 display 属性的值为 none,则在构建布局树的过程中,无需将这个 DOM 节点添加到布局树上,直接忽略它就可以了。
如果一个块节点包含一个内联子节点,则需要创建一个匿名块(实际上就是块节点)来包含它。如果一行中有多个子节点,则将它们全部放在同一个匿名容器中。
function buildLayoutTree(styleNode: StyleNode) {
if (getDisplayValue(styleNode) === Display.None) {
throw new Error('Root node has display: none.')
}
const layoutBox = new LayoutBox(styleNode)
let anonymousBlock: LayoutBox | undefined
for (const child of styleNode.children) {
const childDisplay = getDisplayValue(child)
// 如果 DOM 节点 display 属性值为 none,直接跳过
if (childDisplay === Display.None) continue
if (childDisplay === Display.Block) {
anonymousBlock = undefined
layoutBox.children.push(buildLayoutTree(child))
} else {
// 创建一个匿名容器,用于容纳内联节点
if (!anonymousBlock) {
anonymousBlock = new LayoutBox()
layoutBox.children.push(anonymousBlock)
}
anonymousBlock.children.push(buildLayoutTree(child))
}
}
return layoutBox
}
遍历布局树
现在开始构建布局树,入口函数是 getLayoutTree():
export function getLayoutTree(styleNode: StyleNode, parentBlock: Dimensions) {
parentBlock.content.height = 0
const root = buildLayoutTree(styleNode)
root.layout(parentBlock)
return root
}
它将遍历样式树,利用样式树节点提供的相关信息,生成一个 LayoutBox 对象,然后调用 layout() 方法。计算每个盒子节点的位置、尺寸信息。
在本节内容的开头有提到过,盒子的宽度取决于其父节点,而高度取决于子节点。这意味着,我们的代码在计算宽度时需要自上而下遍历树,这样它就可以在知道父节点的宽度后设置子节点的宽度。然后自下而上遍历以计算高度,这样父节点的高度就可以在计算子节点的相关信息后进行计算。
layout(parentBlock: Dimensions) {
// 子节点的宽度依赖于父节点的宽度,所以要先计算当前节点的宽度,再遍历子节点
this.calculateBlockWidth(parentBlock)
// 计算盒子节点的位置
this.calculateBlockPosition(parentBlock)
// 遍历子节点并计算对位置、尺寸信息
this.layoutBlockChildren()
// 父节点的高度依赖于其子节点的高度,所以计算子节点的高度后,再计算自己的高度
this.calculateBlockHeight()
}
这个方法执行布局树的单次遍历,向下执行宽度计算,向上执行高度计算。一个真正的布局引擎可能会执行几次树遍历,有些是自上而下的,有些是自下而上的。
计算宽度
现在,我们先来计算盒子节点的宽度,这部分比较复杂,需要详细的讲解。
首先,我们要拿到当前节点的 width padding border margin 等信息:
calculateBlockWidth(parentBlock: Dimensions) {
// 初始值
const styleValues = this.styleNode?.values || {}
// 初始值为 auto
let width = styleValues.width ?? 'auto'
let marginLeft = styleValues['margin-left'] || styleValues.margin || 0
let marginRight = styleValues['margin-right'] || styleValues.margin || 0
let borderLeft = styleValues['border-left'] || styleValues.border || 0
let borderRight = styleValues['border-right'] || styleValues.border || 0
let paddingLeft = styleValues['padding-left'] || styleValues.padding || 0
let paddingRight = styleValues['padding-right'] || styleValues.padding || 0
// 拿到父节点的宽度,如果某个属性为 'auto',则将它设为 0
let totalWidth = sum(width, marginLeft, marginRight, borderLeft, borderRight, paddingLeft, paddingRight)
// ...
如果这些属性没有设置,就使用 0 作为默认值。拿到当前节点的总宽度后,还需要和父节点对比一下是否相等。如果宽度或边距设置为 auto,则可以对这两个属性进行适当展开或收缩以适应可用空间。所以现在需要对当前节点的宽度进行检查。
const isWidthAuto = width === 'auto'
const isMarginLeftAuto = marginLeft === 'auto'
const isMarginRightAuto = marginRight === 'auto'
// 当前块的宽度如果超过了父元素宽度,则将它的可扩展外边距设为 0
if (!isWidthAuto && totalWidth > parentWidth) {
if (isMarginLeftAuto) {
marginLeft = 0
}
if (isMarginRightAuto) {
marginRight = 0
}
}
// 根据父子元素宽度的差值,去调整当前元素的宽度
const underflow = parentWidth - totalWidth
// 如果三者都有值,则将差值填充到 marginRight
if (!isWidthAuto && !isMarginLeftAuto && !isMarginRightAuto) {
marginRight += underflow
} else if (!isWidthAuto && !isMarginLeftAuto && isMarginRightAuto) {
// 如果右边距是 auto,则将 marginRight 设为差值
marginRight = underflow
} else if (!isWidthAuto && isMarginLeftAuto && !isMarginRightAuto) {
// 如果左边距是 auto,则将 marginLeft 设为差值
marginLeft = underflow
} else if (isWidthAuto) {
// 如果只有 width 是 auto,则将另外两个值设为 0
if (isMarginLeftAuto) {
marginLeft = 0
}
if (isMarginRightAuto) {
marginRight = 0
}
if (underflow >= 0) {
// 展开宽度,填充剩余空间,原来的宽度是 auto,作为 0 来计算的
width = underflow
} else {
// 宽度不能为负数,所以需要调整 marginRight 来代替
width = 0
// underflow 为负数,相加实际上就是缩小当前节点的宽度
marginRight += underflow
}
} else if (!isWidthAuto && isMarginLeftAuto && isMarginRightAuto) {
// 如果只有 marginLeft 和 marginRight 是 auto,则将两者设为 underflow 的一半
marginLeft = underflow / 2
marginRight = underflow / 2
}
详细的计算过程请看上述代码,重要的地方都已经标上注释了。
通过对比当前节点和父节点的宽度,我们可以拿到一个差值:
// 根据父子元素宽度的差值,去调整当前元素的宽度
const underflow = parentWidth - totalWidth
如果这个差值为正数,说明子节点宽度小于父节点;如果差值为负数,说明子节点大于父节。上面这段代码逻辑其实就是根据 underflow width padding margin 等值对子节点的宽度、边距进行调整,以适应父节点的宽度。
定位
计算当前节点的位置相对来说简单一点。这个方法会根据当前节点的 margin border padding 样式以及父节点的位置信息对当前节点进行定位:
calculateBlockPosition(parentBlock: Dimensions) {
const styleValues = this.styleNode?.values || {}
const { x, y, height } = parentBlock.content
const dimensions = this.dimensions
dimensions.margin.top = transformValueSafe(styleValues['margin-top'] || styleValues.margin || 0)
dimensions.margin.bottom = transformValueSafe(styleValues['margin-bottom'] || styleValues.margin || 0)
dimensions.border.top = transformValueSafe(styleValues['border-top'] || styleValues.border || 0)
dimensions.border.bottom = transformValueSafe(styleValues['border-bottom'] || styleValues.border || 0)
dimensions.padding.top = transformValueSafe(styleValues['padding-top'] || styleValues.padding || 0)
dimensions.padding.bottom = transformValueSafe(styleValues['padding-bottom'] || styleValues.padding || 0)
dimensions.content.x = x + dimensions.margin.left + dimensions.border.left + dimensions.padding.left
dimensions.content.y = y + height + dimensions.margin.top + dimensions.border.top + dimensions.padding.top
}
function transformValueSafe(val: number | string) {
if (val === 'auto') return 0
return parseInt(String(val))
}
比如获取当前节点内容区域的 x 坐标,计算方式如下:
dimensions.content.x = x + dimensions.margin.left + dimensions.border.left + dimensions.padding.left
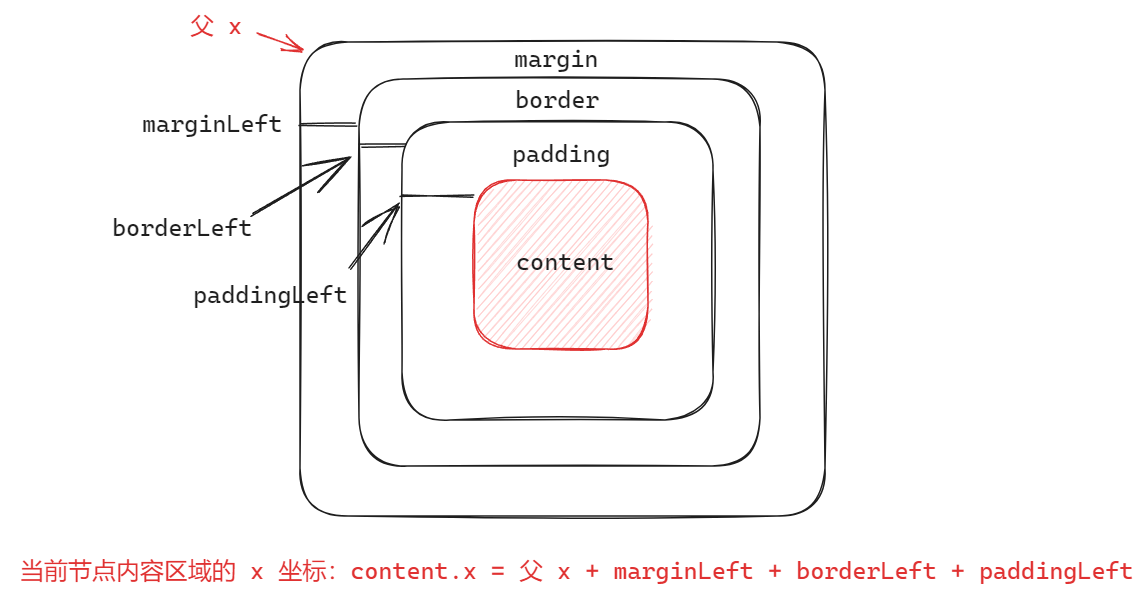
遍历子节点
在计算高度之前,需要先遍历子节点,因为父节点的高度需要根据它下面子节点的高度进行适配。
layoutBlockChildren() {
const { dimensions } = this
for (const child of this.children) {
child.layout(dimensions)
// 遍历子节点后,再计算父节点的高度
dimensions.content.height += child.dimensions.marginBox().height
}
}
每个节点的高度就是它上下两个外边距之间的差值,所以可以通过 marginBox() 获得高度:
export default class Dimensions {
content: Rect
padding: EdgeSizes
border: EdgeSizes
margin: EdgeSizes
constructor() {
const initValue = {
top: 0,
right: 0,
bottom: 0,
left: 0,
}
this.content = new Rect()
this.padding = { ...initValue }
this.border = { ...initValue }
this.margin = { ...initValue }
}
paddingBox() {
return this.content.expandedBy(this.padding)
}
borderBox() {
return this.paddingBox().expandedBy(this.border)
}
marginBox() {
return this.borderBox().expandedBy(this.margin)
}
}
export default class Rect {
x: number
y: number
width: number
height: number
constructor() {
this.x = 0
this.y = 0
this.width = 0
this.height = 0
}
expandedBy(edge: EdgeSizes) {
const rect = new Rect()
rect.x = this.x - edge.left
rect.y = this.y - edge.top
rect.width = this.width + edge.left + edge.right
rect.height = this.height + edge.top + edge.bottom
return rect
}
}
遍历子节点并执行完相关计算方法后,再将各个子节点的高度进行相加,得到父节点的高度。
height 属性
默认情况下,节点的高度等于其内容的高度。但如果手动设置了 height 属性,则需要将节点的高度设为指定的高度:
calculateBlockHeight() {
// 如果元素设置了 height,则使用 height,否则使用 layoutBlockChildren() 计算出来的高度
const height = this.styleNode?.values.height
if (height) {
this.dimensions.content.height = parseInt(height)
}
}
为了简单起见,我们不需要实现外边距折叠。
小结
布局树是渲染引擎最复杂的部分,这一阶段结束后,我们就了解了布局树中每个盒子节点在页面中的具体位置和尺寸信息。下一步,就是如何把布局树渲染到页面上了。
绘制
绘制阶段主要是根据布局树中各个节点的位置、尺寸信息将它们绘制到页面。目前大多数计算机使用光栅(raster,也称为位图)显示技术。将布局树各个节点绘制到页面的这个过程也被称为“光栅化”。
浏览器通常在图形API和库(如Skia、Cairo、Direct2D等)的帮助下实现光栅化。这些API提供绘制多边形、直线、曲线、渐变和文本的功能。
实际上绘制才是最难的部分,但是这一步我们有现成的 canvas 库可以用,不用自己实现一个光栅器,所以相对来说就变得简单了。在真正开始绘制阶段之前,我们先来学习一些关于计算机如何绘制图像、文本的基础知识,有助于我们理解光栅化的具体实现过程。
计算机如何绘制图像、文本
在计算机底层进行像素绘制属于硬件操作,它依赖于屏幕和显卡接口的具体细节。为了简单起点,我们可以用一段内存区域来表示屏幕,内存的一个 bit 就代表了屏幕中的一个像素。比如在屏幕中的 (x,y) 坐标绘制一个像素,可以用 memory[x + y * rowSize] = 1 来表示。从屏幕左上角开始,列是从左至右开始计数,行是从上至下开始计数。因此屏幕最左上角的坐标是 (0,0)。
为了简单起见,我们用 1 bit 来表示屏幕的一个像素,0 代表白色,1 代表黑色。屏幕每一行的长度用变量 rowSzie 表示,每一列的高度用 colSize 表示。

绘制线条
如果我们要在计算机上绘制一条直线,那么只要知道计算机的起点坐标 (x1,y1) 和终点坐标 (x2,y2) 就可以了。
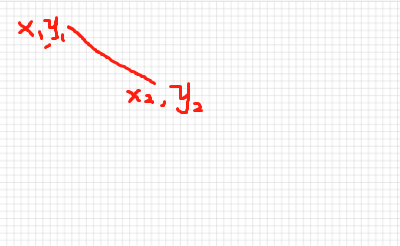
然后根据 memory[x + y * rowSize] = 1 公式,将 (x1,y1) 至 (x2,y2) 之间对应的内存区域置为 1,这样就画出来了一条直线。
绘制文本
为了在屏幕上显示文本,首先必须将物理上基于像素点的屏幕,在逻辑上以字符为单位划分成若干区域,每个区域能输出单个完整的字符。假设有一个 256 行 512 列的屏幕,如果为每个字符分配一个 11*8 像素的网格,那么屏幕上总共能显示 23 行,每行 64 个字符(还有 3 行像素没使用)。
有了这些前提条件后,我们现在打算在屏幕上画一个 A:

上图的 A 在内存区域中用 11*8 像素的网格表示。为了在内存区域中绘制它,我们可以用一个二维数组来表示它:
const charA = [
[0, 0, 1, 1, 0, 0, 0, 0], // 按从左至右的顺序来读取 bit,转换成十进制数字就是 12
[0, 1, 1, 1, 1, 0, 0, 0], // 30
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 1, 1, 1, 1, 0, 0], // 63
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[1, 1, 0, 0, 1, 1, 0, 0], // 51
[0, 0, 0, 0, 0, 0, 0, 0], // 0
[0, 0, 0, 0, 0, 0, 0, 0], // 0
]
上面二维数组的第一项,代表了第一行内存区域每个 bit 的取值。一共 11 行,画出了一个字母 A。
如果我们为 26 个字母都建一个映射表,按 ascii 的编码来排序,那么 charsMap[65] 就代表字符 A,当用户在键盘上按下 A 键时,就把 charsMap[65] 对应的数据输出到内存区域上,这样屏幕上就显示了一个字符 A。
绘制布局树
科普完关于绘制屏幕的基础知识后,我们现在正式开始绘制布局树(为了方便,我们使用 node-canvas 库)。
首先要遍历整个布局树,然后逐个节点进行绘制:
function renderLayoutBox(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D, parent?: LayoutBox) {
renderBackground(layoutBox, ctx)
renderBorder(layoutBox, ctx)
renderText(layoutBox, ctx, parent)
for (const child of layoutBox.children) {
renderLayoutBox(child, ctx, layoutBox)
}
}
这个函数对每个节点依次绘制背景色、边框、文本,然后再递归绘制所有子节点。
默认情况下,HTML 元素按照它们出现的顺序进行绘制。如果两个元素重叠,则后一个元素将绘制在前一个元素之上。这种排序反映在我们的布局树中,它将按照元素在 DOM 树中出现的顺序绘制元素。
绘制背景色
function renderBackground(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D) {
const { width, height, x, y } = layoutBox.dimensions.borderBox()
ctx.fillStyle = getStyleValue(layoutBox, 'background')
ctx.fillRect(x, y, width, height)
}
首先拿到布局节点的位置、尺寸信息,以 x,y 作为起点,绘制矩形区域。并且以 CSS 属性 background 的值作为背景色进行填充。
绘制边框
function renderBorder(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D) {
const { width, height, x, y } = layoutBox.dimensions.borderBox()
const { left, top, right, bottom } = layoutBox.dimensions.border
const borderColor = getStyleValue(layoutBox, 'border-color')
if (!borderColor) return
ctx.fillStyle = borderColor
// left
ctx.fillRect(x, y, left, height)
// top
ctx.fillRect(x, y, width, top)
// right
ctx.fillRect(x + width - right, y, right, height)
// bottom
ctx.fillRect(x, y + height - bottom, width, bottom)
}
绘制边框,其实我们绘制的是四个矩形,每一个矩形就是一条边框。
绘制文本
function renderText(layoutBox: LayoutBox, ctx: CanvasRenderingContext2D, parent?: LayoutBox) {
if (layoutBox.styleNode?.node.nodeType === NodeType.Text) {
// get AnonymousBlock x y
const { x = 0, y = 0, width } = parent?.dimensions.content || {}
const styles = layoutBox.styleNode?.values || {}
const fontSize = styles['font-size'] || '14px'
const fontFamily = styles['font-family'] || 'serif'
const fontWeight = styles['font-weight'] || 'normal'
const fontStyle = styles['font-style'] || 'normal'
ctx.fillStyle = styles.color
ctx.font = `${fontStyle} ${fontWeight} ${fontSize} ${fontFamily}`
ctx.fillText(layoutBox.styleNode?.node.nodeValue, x, y + parseInt(fontSize), width)
}
}
通过 canvas 的 fillText() 方法,我们可以很方便的绘制带有字体风格、大小、颜色的文本。
输出图片
绘制完成后,我们可以借助 canvas 的 API 输出图片。下面用一个简单的示例来演示一下:
<html>
<body id=" body " data-index="1" style="color: red; background: yellow;">
<div>
<div class="lightblue test">test1!</div>
<div class="lightblue test">
<div class="foo">foo</div>
</div>
</div>
</body>
</html>
* {
display: block;
}
div {
font-size: 14px;
width: 400px;
background: #fff;
margin-bottom: 20px;
display: block;
background: lightblue;
}
.lightblue {
font-size: 16px;
display: block;
width: 200px;
height: 200px;
background: blue;
border-color: green;
border: 10px;
}
.foo {
width: 100px;
height: 100px;
background: red;
color: yellow;
margin-left: 50px;
}
body {
display: block;
font-size: 88px;
color: #000;
}
上面这段 HTML、CSS 代码经过渲染引擎程序解析后生成的图片如下:

总结
至此,这个玩具版的渲染引擎就完成了。虽然这个玩具并没有什么用,但如果能通过实现它来了解真实的渲染引擎是如何运作的,从这个角度来看,它还是“有用”的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号