
1.计数器应用
hadoop为每个作业维护若干个内置计数器,以描述多项指标;例如:某些计数器记录已处理的字节数和记录数,使用户可监控已经处理的输入数据量和已产生的输出数据量;
1.1 计数器API
1.1.1 采用枚举的方式统计计数
enumMyCounter(MALFORORMED,NORMAL)
1.1.2 采用计数器组,计数器名称的方式统计
context.getCount("countGroup","counter").increment(1);
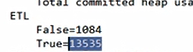
1.1.3 计数结果在程序运行后的控制台上查看;
2.数据清洗
在运行核心业务MapReduce程序之前,往往要先对数据进行清除,清理掉不符合用户要求的数据;清理的过程往往只需要运行mapper程序,不需要运行reduce程序;
3.数据清洗需求
3.1 需求
去除日志中字段长度小于等于11的日志;
(1)输入数据
(2)输出数据
每行字段长度大于11;
3.2 需求分析
需要在map阶段对输入的数据根据规则进行过滤清洗;
4.数据清洗案例--简单版
4.1 mapper编写
package com.wn.etl;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(" ");
if (fields.length>11){
context.write(value,NullWritable.get());
context.getCounter("ETL","True").increment(1);
}else{
context.getCounter("ETL","False").increment(1);
}
}
}
4.2 driver编写
package com.wn.etl;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class ETLDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(ETLDriver.class);
job.setMapperClass(ETLMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("E:\\北大青鸟\\大数据04\\hadoop\\ETL"));
FileOutputFormat.setOutputPath(job,new Path("E:\\北大青鸟\\大数据04\\hadoop\\outETL"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}

5.数据清理案例--复杂版
5.1 bean编写
package com.wn.etl2;
public class LogBean {
private String remote_addr; //记录客户端的ip地址
private String remote_user; //记录客户端用户名称
private String time_local; //记录访问时间与时区
private String request; //记录请求的url和http协议
private String status; //记录请求状态,成功是200
private String body_bytes_sent; //记录发送给客户端文件主题内容大小
private String http_referer; //用来记录从哪个页面链接访问过来的
private String http_user_agent; //记录客户浏览器的相关信息
private boolean valid=true; //判断数据是否合法
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
@Override
public String toString() {
StringBuilder sb=new StringBuilder();
sb.append("\001").append(this.remote_addr);
sb.append("\001").append(this.remote_user);
sb.append("\001").append(this.time_local);
sb.append("\001").append(this.request);
sb.append("\001").append(this.status);
sb.append("\001").append(this.body_bytes_sent);
sb.append("\001").append(this.http_referer);
sb.append("\001").append(this.http_user_agent);
return sb.toString();
}
}
5.2 mapper编写
package com.wn.etl2;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class LogMapper extends Mapper<LongWritable, Text,Text, NullWritable> {
private LogBean logBean=new LogBean();
private Text k=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
parseLog(line);
if (logBean.isValid()){
k.set(logBean.toString());
context.write(k,NullWritable.get());
context.getCounter("ETL","True").increment(1);
}else{
context.getCounter("ETL","False").increment(1);
}
}
private void parseLog(String line) {
String[] fields= line.split(" ");
if (fields.length>11){
//封装数据
logBean.setRemote_addr(fields[0]);
logBean.setRemote_user(fields[1]);
logBean.setTime_local(fields[3].substring(1));
logBean.setRequest(fields[6]);
logBean.setStatus(fields[8]);
logBean.setBody_bytes_sent(fields[9]);
logBean.setHttp_referer(fields[10]);
if (fields.length>12){
logBean.setHttp_user_agent(fields[11]+" "+fields[12]);
}else{
logBean.setHttp_user_agent(fields[11]);
}
//大于400,HTTP错误
if (Integer.parseInt(logBean.getStatus())>=400){
logBean.setValid(false);
}else{
logBean.setValid(true);
}
}else{
logBean.setValid(false);
}
}
}
5.3 driver编写
package com.wn.etl2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class LogDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(LogDriver.class);
job.setMapperClass(LogMapper.class);
job.setNumReduceTasks(0);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("E:\\北大青鸟\\大数据04\\hadoop\\ETL"));
FileOutputFormat.setOutputPath(job,new Path("E:\\北大青鸟\\大数据04\\hadoop\\outETL"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号