
1.Shuffle机制
1.1 什么是shuffle机制
1.1.1 在hadoop中数据从map阶段传递给reduce阶段的过程就叫shuffle,shuffle机制是整个MapReduce框架中最核心的部分;
1.1.2 shuffle翻译成中文的意思为:洗牌,发牌(核心机制:数据分区,排序,缓存)
1.2 shuffle的作用范围
一般把数据从map阶段输出到reduce阶段的过程叫shuffle,所以shuffle的作用范围是map阶段数据输出到reduce阶段数据输入这一整个中间过程;
1.3 shuffle图解
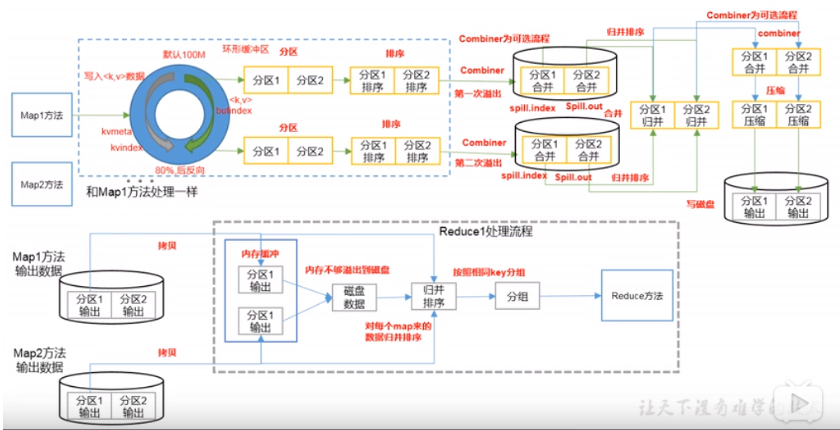
shuffle并不是hadoop的一个组件,只是map阶段产生数据输出到reduce阶段取得数据作为输入之前的一个过程;
1.4 shuffle的执行阶段流程
1.4.1 collect阶段:将mapTask的结果输出到默认大小为100的环形缓冲区,保存的是key/value序列化数据,partition分区信息等;
1.4.2 spill阶段:当内存中的数据量达到一定阈值的时候,就会将数据写入本地磁盘中,在将数据写磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序;
1.4.3 merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个mapTask最终值产生一个中间数据文件;
1.4.4 copy阶段:reducetask启动fetcher线程到已经完成mapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存缓冲区中,当内存的缓冲区达到一定阈值的时候,就会将数据写入磁盘中;
1.4.5 merge阶段:在reducetask远程复制数据的同时,会在后台开启两个线程(一个是内存到磁盘合并,一个是磁盘到磁盘合并)对内存到本地的数据文件进行合并操作;
1.4.6 sort阶段:在对数据进行合并的同时,会进行排序操作,由于mapTask阶段已经对数据进行了局部排序,reducetask只需保证copy的数据的最终整体有效性即可;
1.5 注意
shuffle中的缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘IO的次数越少,执行速度就越快,正是因为shuffle的过程中要不断的将文件从磁盘写入到内存,再从内存写入到磁盘,从而导致了hadoop中MapReduce执行效率相对于storm等一些实时计算来说比较低下的原因;
2.Partition分区
2.1 默认Partitioner分区
@Public
@Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public HashPartitioner() {
}
public void configure(JobConf job) {
}
public int getPartition(K2 key, V2 value, int numReduceTasks) {
// key的hashcode值与Integer的最大值 在和reduceTask数量求余
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
默认分区是根据key的hashCode值对ReduceTasks的个数取模得到的;用户没法控制哪个key存储到哪个分区中;
2.2 分区总结
(1)如果reduceTask的数量>getPartition的结果数,则会产生几个空的输出文件part-r-000xx;
(2)如果1<ReduceTask的数量<getPartition的结果数,则有一部分分区数据无处安放,会发生异常;
(3)如果ReduceTask的数量=1,则不管mapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就会产生一个结果文件part-r-00000;
(4)分区号必须从零开始,逐一累加;
3.Partition分区案例实操
3.1 Partitioner编写
package com.wn.partition;
import com.wn.flow.FlowwBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<Text, FlowwBean> {
@Override
public int getPartition(Text text, FlowwBean flowwBean, int i) {
String phone = text.toString();
switch (phone.substring(0,3)){
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
}
}
}
3.2 Driver编写
package com.wn.partition;
import com.wn.flow.FlowMapper;
import com.wn.flow.FlowReducer;
import com.wn.flow.FlowwBean;
import com.wn.wordcount.WcDriver;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class PartitionDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取一个Job实例
Job job = Job.getInstance(new Configuration());
//设置类路径
job.setJarByClass(PartitionDriver.class);
//设置mapper和reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//设置分区
job.setNumReduceTasks(5);
job.setPartitionerClass(MyPartitioner.class);
//设置mapper和reducer输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowwBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowwBean.class);
//设置输入的数据
FileInputFormat.setInputPaths(job,new Path("E:\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\output"));
//提交job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
4.WritableComparable排序
排序是MapReduce框架中最重要的操作之一;
mapTask和reducetask均会对数据按照key进行排序;该操作属于hadoop的默认行为;任何应用程序中的数据均会被排序,而不管逻辑上是否需要;
默认排序是按照字典顺序排序,且实现该排序的方法是快速排序;
对于mapTask,它会将处理的结果暂时存放到一个缓冲区,当缓冲区使用效率达到一定阈值后,在对缓冲区中的数据进行一次排序,并将这些数据写到磁盘中,而当数据处理完毕后,它会对磁盘所有文件进行一次,合并以将这些文件合并成一个大的有序的文件;
对于mapTask,它从每一个mapTask上远程拷贝响应的数据文件,如果文件大小超过阈值,则放在磁盘上,否则放到内存中;如果磁盘上文件数据达到阈值,则进行合并以生成一个更大的文件;如果内存中文件大小或者数目超过一定阈值,则进行一次合并后将数据写到磁盘上,当所有数据拷贝完毕后,reduceTask统一对内存和磁盘上的所有数据进行一次合并;
排序分类:
1.部分排序:MapReduce根据输入记录的键对数据排序,保证输出的每个文件内部排序;
2.全排序:首先创建一系列排好序的文件,其次,串联这些文件;最后,生成一个全局排序的文件;主要思路是使用一个分区来描述输出的全局排序;
3.辅助排序:MapReduce框架在记录到达reducer之前按键对记录排序,但键所响应的值并没有被牌排序;甚至在不同的执行轮次中,这些值的排序也不固定,因为他们来自不同的map任务且这些map任务在不同轮次中完成时间各不相同;一般来说,大多数MapReduce程序会避免让reducer函数依赖于值的排序;但是,有时也需要通过特定的方法对键进行排序和分组等以实现对值的排序;
4.二次排序:在自定义过程中,如果compareTo中的判断条件为两个即为二次排序;
5.WritableComparable排序案例实操(全排序)
根据上面序列化产生的结果再次对总流量进行排序;
5.1 FlowwBean类编写
package com.wn.writablecomparable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class FlowwBean implements WritableComparable<FlowwBean> {
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowwBean() {
}
@Override
public String toString() {
return "FlowwBean{" +
"upFlow=" + upFlow +
", downFlow=" + downFlow +
", sumFlow=" + sumFlow +
'}';
}
public void set(long upFlow, long downFlow){
this.upFlow=upFlow;
this.downFlow=downFlow;
this.sumFlow=upFlow+downFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
/*序列化方法
* dataOutput 框架给我们提供的数据出口
* */
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
dataOutput.writeLong(sumFlow);
}
/*顺序要完全一致*/
/*反序列化方法
* dataInput 框架提供的数据来源
* */
@Override
public void readFields(DataInput dataInput) throws IOException {
upFlow=dataInput.readLong();
downFlow=dataInput.readLong();
sumFlow=dataInput.readLong();
}
@Override
public int compareTo(FlowwBean o) {
return Long.compare(o.sumFlow,this.sumFlow);
}
}
5.2 mapper编写
package com.wn.writablecomparable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SortMapper extends Mapper<LongWritable, Text,FlowwBean,Text> {
private FlowwBean flow=new FlowwBean();
private Text phone=new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
phone.set(fields[0]);
flow.setUpFlow(Long.parseLong(fields[1]));
flow.setDownFlow(Long.parseLong(fields[2]));
flow.setSumFlow(Long.parseLong(fields[3]));
context.write(flow,phone);
}
}
5.3 reducer编写
package com.wn.writablecomparable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SortReducer extends Reducer<FlowwBean, Text,Text,FlowwBean> {
@Override
protected void reduce(FlowwBean key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text value:values){
context.write(value,key);
}
}
}
5.4 driver编写
package com.wn.writablecomparable;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SortDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(SortDriver.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(FlowwBean.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowwBean.class);
FileInputFormat.setInputPaths(job,new Path("E:\\北大青鸟\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\北大青鸟\\output2"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0: 1);
}
}
6.WritableComparable排序案例实操(区内排序)
要求每个省份手机号输出的文件中按照总流浪内部排序;
基于前一个需求,增加自定义分区类,分区按照省份手机号设置;
6.1 自定义partitioner编写
package com.wn.writablecomparable2;
import com.wn.writablecomparable.FlowwBean;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner2 extends Partitioner<FlowwBean, Text> {
@Override
public int getPartition(FlowwBean flowwBean, Text text, int i) {
switch (text.toString().substring(0,3)){
case "136":
return 0;
case "137":
return 1;
case "138":
return 2;
case "139":
return 3;
default:
return 4;
}
}
}
6.2 driver编写
package com.wn.writablecomparable2;
import com.wn.writablecomparable.FlowwBean;
import com.wn.writablecomparable.SortMapper;
import com.wn.writablecomparable.SortReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SortDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(SortDriver.class);
job.setMapperClass(SortMapper.class);
job.setReducerClass(SortReducer.class);
job.setMapOutputKeyClass(FlowwBean.class);
job.setMapOutputValueClass(Text.class);
//分區
job.setNumReduceTasks(5);
job.setPartitionerClass(MyPartitioner2.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowwBean.class);
FileInputFormat.setInputPaths(job,new Path("E:\\北大青鸟\\input"));
FileOutputFormat.setOutputPath(job,new Path("E:\\北大青鸟\\output2"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0: 1);
}
}
7.Combiner合并
7.1Combiner是MR程序中mapper和reducer之外的一种组件;
7.2 Combiner组件的父类就是reducer;
7.3 Combiner和reducer的区别在于运行的位置
Combiner是在每一个mapTask所在的节点运行;
reducer是接收全局所有mapper的输出结果;
7.4 Combiner的意义就是对每一个mapTask的输出进行局部总汇,以减小网络传输量;
7.5 Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出KV应该跟reducer的数据KV类型要对应起来;
8.Combiner合并案例实操
8.1 mapper编写
package com.wn.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.junit.Test;
import java.io.IOException;
public class WcMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text word=new Text();
private IntWritable one=new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到这一行数据
String line = value.toString();
//按照空格切分数据
String[] words = line.split(" ");
//遍历数组
for (String word:words){
this.word.set(word);
context.write(this.word,this.one);
}
}
}
8.2 reducer编写
(其实combiner代码和reducer代码一样,因为 Combiner组件的父类就是reducer)
package com.wn.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WcReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable total=new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//做累加
int sum=0;
for (IntWritable value : values) {
sum+=value.get();
}
//包装结果并输出
total.set(sum);
context.write(key,total);
}
}
8.3 driver编写
package com.wn.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WcDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//获取一个Job实例
Job job = Job.getInstance(new Configuration());
//设置类路径
job.setJarByClass(WcDriver.class);
//设置mapper和reducer
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
//合并
job.setCombinerClass(WcReducer.class);
//设置mapper和reducer输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//设置输入的数据
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//提交job
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
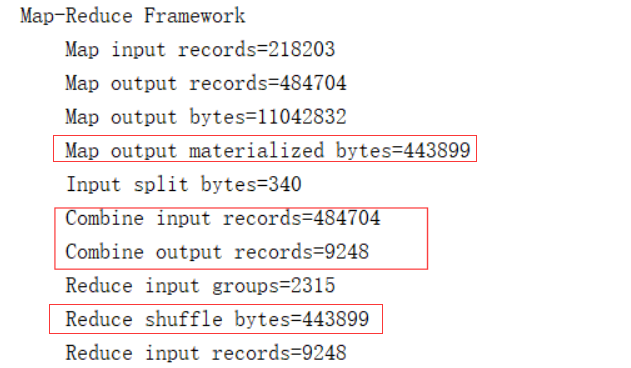
通过日志信息可以看出是否实现了,如果不写combiner,Combine input records和Combiner output records这里的值都是0;如果写了combiner,records的值不是0,并且bytes的值会变小;
9.GroupingComparator分组(辅助排序)
对reducer阶段的数据根据某一个或几个字段进行分组;
需求:
要求每一个订单中最贵的上商品;
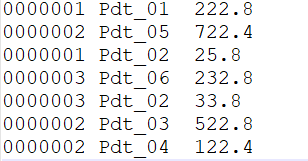
分析:
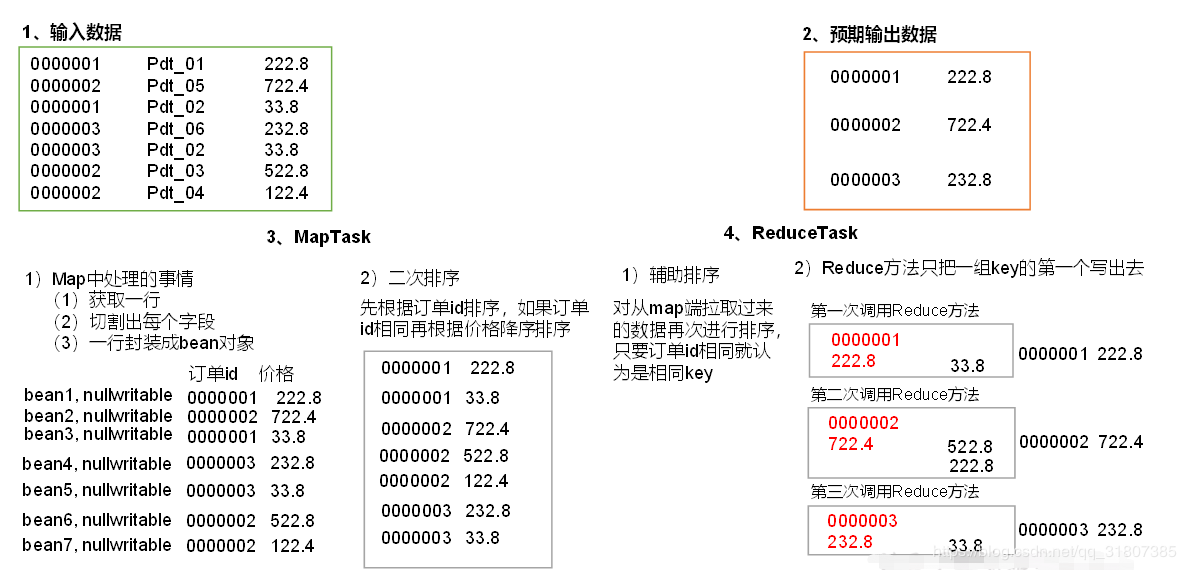
10.GroupingComparator分组案例实操
10.1 OrderBean编写
package com.wn.groupingcomparator;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class OrderBean implements WritableComparable<OrderBean> {
//订单ID
private String orderId;
//商品ID
private String productId;
//价格
private double price;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getProductId() {
return productId;
}
public void setProductId(String productId) {
this.productId = productId;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
@Override
public String toString() {
return "OrderBean{" +
"orderId='" + orderId + '\'' +
", productId='" + productId + '\'' +
", price=" + price +
'}';
}
@Override
public int compareTo(OrderBean o) {
int compare = this.orderId.compareTo(o.orderId);
if (compare==0){
return Double.compare(o.price,this.price);
}else{
return compare;
}
}
//序列化
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(orderId);
dataOutput.writeUTF(productId);
dataOutput.writeDouble(price);
}
//反序列化
@Override
public void readFields(DataInput dataInput) throws IOException {
this.orderId=dataInput.readUTF();
this.productId=dataInput.readUTF();
this.price=dataInput.readDouble();
}
}
10.2 mapper编写
package com.wn.groupingcomparator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OrderMapper extends Mapper<LongWritable, Text,OrderBean, NullWritable> {
private OrderBean orderBean=new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split("\t");
orderBean.setOrderId(fields[0]);
orderBean.setProductId(fields[1]);
orderBean.setPrice(Double.parseDouble(fields[2]));
context.write(orderBean,NullWritable.get());
}
}
10.3 Comparator编写
package com.wn.groupingcomparator;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class OrderComparator extends WritableComparator {
protected OrderComparator(){
super(OrderBean.class,true);
}
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean oa= (OrderBean) a;
OrderBean ob= (OrderBean) b;
return oa.getOrderId().compareTo(ob.getOrderId());
}
}
10.4 reducer编写
package com.wn.groupingcomparator;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import javax.xml.soap.Text;
import java.io.IOException;
public class OrderReducer extends Reducer<OrderBean, NullWritable,OrderBean,NullWritable> {
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
10.5 driver编写
package com.wn.groupingcomparator;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OrderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
job.setJarByClass(OrderDriver.class);
job.setMapperClass(OrderMapper.class);
job.setReducerClass(OrderReducer.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setGroupingComparatorClass(OrderComparator.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path("E:\\GroupingComparator"));
FileOutputFormat.setOutputPath(job,new Path("E:\\output"));
boolean b = job.waitForCompletion(true);
System.exit(b ? 0 : 1);
}
}
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号