
最小生成树和次小生成树
最小生成树,就是图上边权和最小的生成树。
令
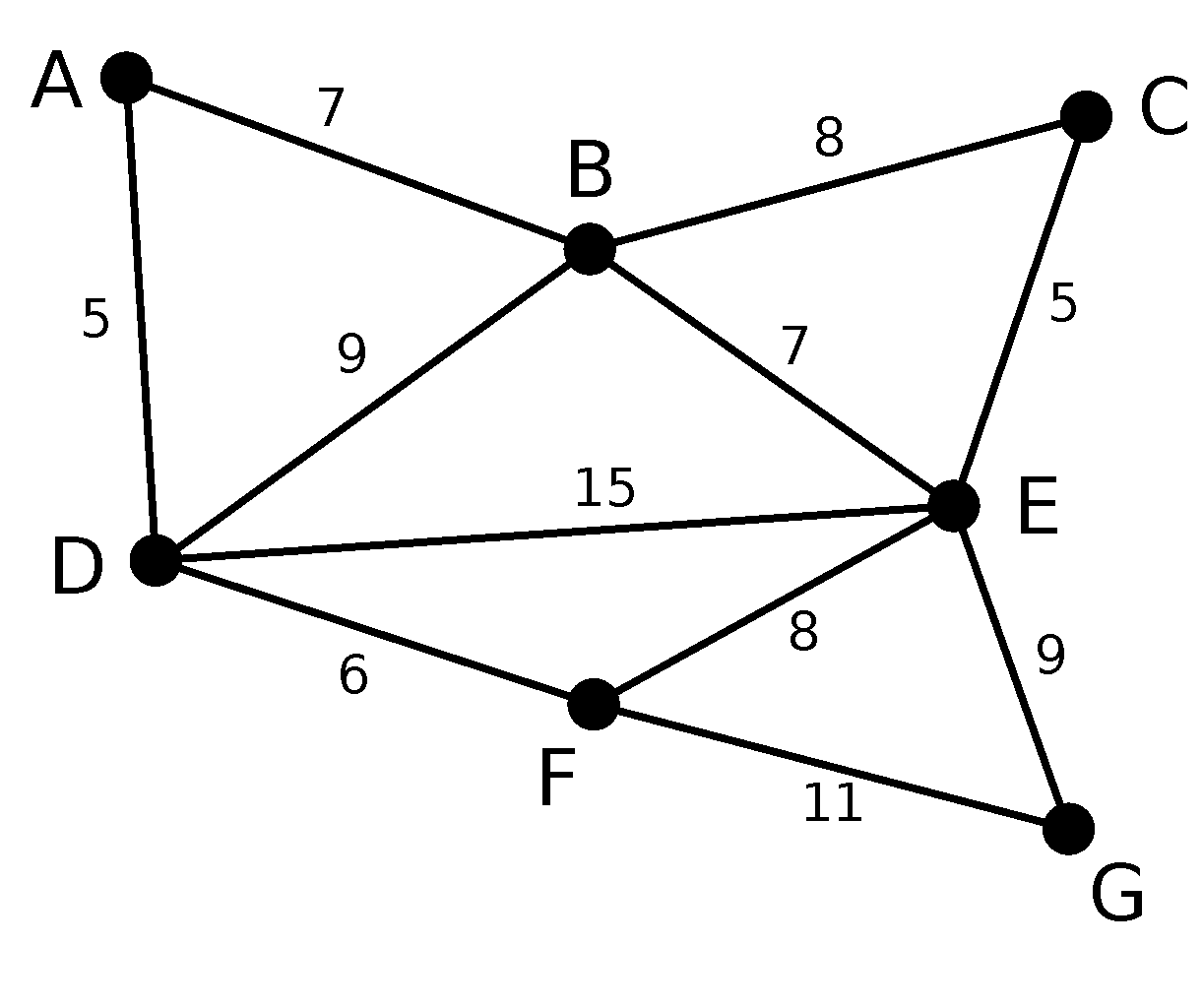
克鲁斯卡尔算法,一种常见且方便好写的最小生成树算法,利用贪心的思想+并查集维护。
贪心就是按边权从小到大排序,依次处理。如果当前边的两个端点处于同一棵树内,那么就不能加这条边(否则会形成环,不满足生成树的要求),否则将这条边连起来。
判断两点是否处于同一棵树内,这不就是并查集所维护的吗?
排序:
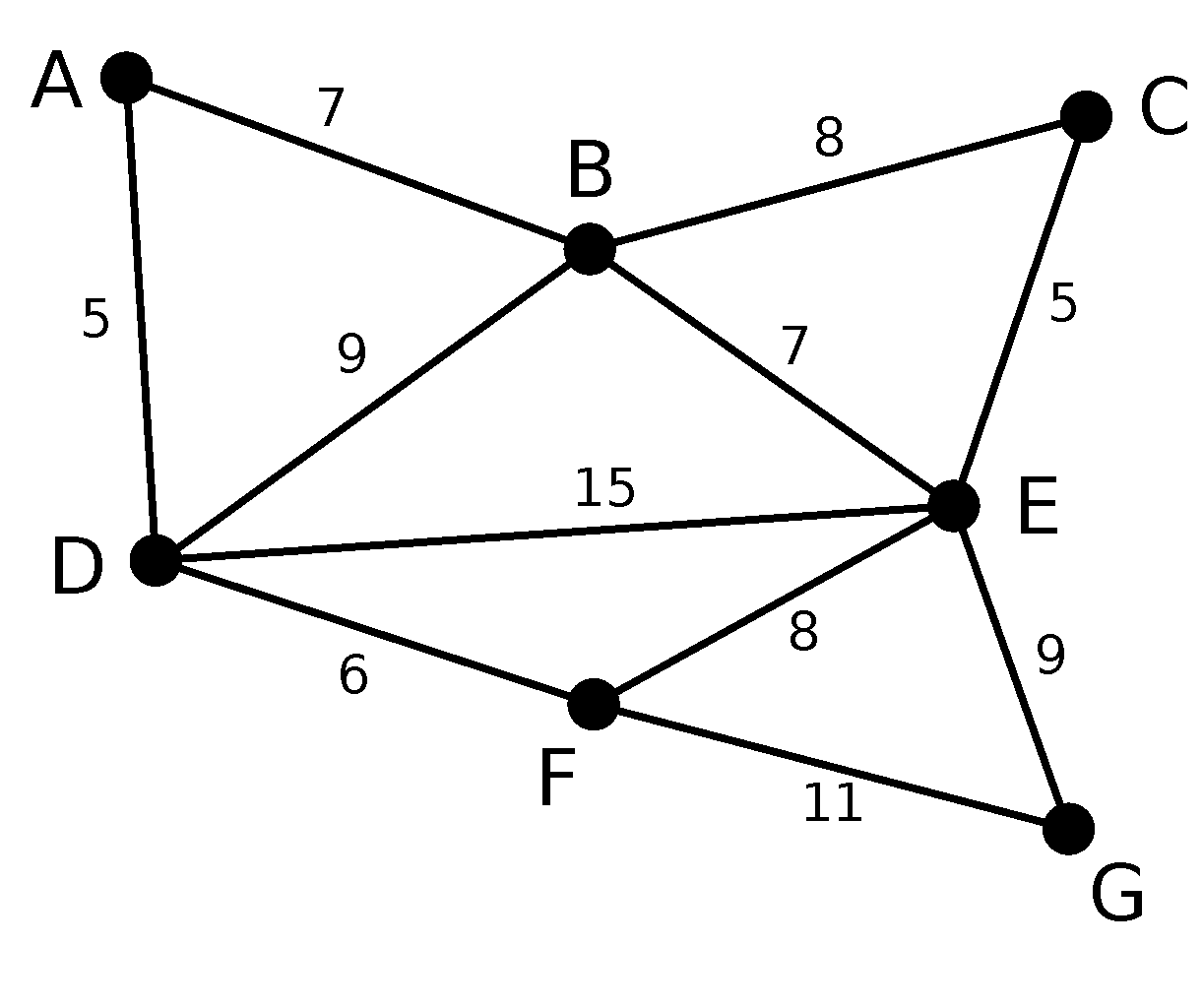
Prim 是另外一种常见且码量也不算很多的最小生成树算法,主要思想就是维护每个点到生成树内的点的最短距离,每次把距离最小的加入最小生成树。
加入距离最小的点,可以通过暴力查找,也可以用优先队列维护,但它复杂度并没有更优,常数也比 Kruskal 要大,所以一般非必要情况下不会写 Prim。
- 暴力の优势:
- 优化の优势:
次小生成树
非严格次小生成树
令图的最小生成树为
维护
严格次小生成树
观察原本的算法,为啥它是非严格的呢?因为可能这条路径上的最大值恰好等于
解决方法也很简单,只要在维护最大值时顺便维护一个严格次大值,当最大值等于
细节不少,D 了我至少一个小时。
struct MST { vector<pair<int, int>> g[N]; int fa[N][25], mx[N][25][2], h[N]; void Add (int x, int y, int z) { g[x].push_back({y, z}), g[y].push_back({x, z}); } void MkTe (int x) { h[x]++; for (auto i : g[x]) { if (i.first != fa[x][0]) { fa[i.first][0] = x, mx[i.first][0][0] = i.second, mx[i.first][0][1] = -1, h[i.first] = h[x], MkTe(i.first); } } } void FAT () { for (int i = 0; i <= 20; i++) { mx[0][i][0] = mx[0][i][1] = -1; } for (int i = 1; i <= 20; i++) { for (int j = 1; j <= n; j++) { fa[j][i] = fa[fa[j][i - 1]][i - 1], mx[j][i][0] = mx[j][i - 1][0], mx[j][i][1] = mx[j][i - 1][1]; if (mx[fa[j][i - 1]][i - 1][0] > mx[j][i][0]) { mx[j][i][1] = mx[j][i][0], mx[j][i][0] = mx[fa[j][i - 1]][i - 1][0]; } else if (mx[fa[j][i - 1]][i - 1][0] < mx[j][i][0] && mx[fa[j][i - 1]][i - 1][0] > mx[j][i][1]) { mx[j][i][1] = mx[fa[j][i - 1]][i - 1][0]; } if (mx[fa[j][i - 1]][i - 1][1] < mx[j][i][0] && mx[fa[j][i - 1]][i - 1][1] > mx[j][i][1]) { mx[j][i][1] = mx[fa[j][i - 1]][i - 1][1]; } } } } pair<int, int> lca (int x, int y) { if (h[x] > h[y]) { swap(x, y); } pair<int, int> xm = {-1, -1}; for (int i = 20; i >= 0; i--) { if ((h[y] - h[x]) >> i) { if (mx[y][i][0] > xm.first) { xm.second = xm.first, xm.first = mx[y][i][0]; } else if (mx[y][i][0] < xm.first && mx[y][i][0] > xm.second) { xm.second = mx[y][i][0]; } if (mx[y][i][1] < xm.first && mx[y][i][1] > xm.second) { xm.second = mx[y][i][1]; } y = fa[y][i]; } } if (x == y) { return xm; } for (int i = 20; i >= 0; i--) { if (fa[x][i] != fa[y][i]) { if (mx[y][i][0] > xm.first) { xm.second = xm.first, xm.first = mx[y][i][0]; } else if (mx[y][i][0] < xm.first && mx[y][i][0] > xm.second) { xm.second = mx[y][i][0]; } if (mx[y][i][1] < xm.first && mx[y][i][1] > xm.second) { xm.second = mx[y][i][1]; } if (mx[x][i][0] > xm.first) { xm.second = xm.first, xm.first = mx[x][i][0]; } else if (mx[x][i][0] < xm.first && mx[x][i][0] > xm.second) { xm.second = mx[x][i][0]; } if (mx[x][i][1] < xm.first && mx[x][i][1] > xm.second) { xm.second = mx[x][i][1]; } y = fa[y][i], x = fa[x][i]; } } if (mx[y][0][0] > xm.first) { xm.second = xm.first, xm.first = mx[y][0][0]; } else if (mx[y][0][0] < xm.first && mx[y][0][0] > xm.second) { xm.second = mx[y][0][0]; } if (mx[y][0][1] < xm.first && mx[y][0][1] > xm.second) { xm.second = mx[y][0][1]; } if (mx[x][0][0] > xm.first) { xm.second = xm.first, xm.first = mx[x][0][0]; } else if (mx[x][0][0] < xm.first && mx[x][0][0] > xm.second) { xm.second = mx[x][0][0]; } if (mx[x][0][1] < xm.first && mx[x][0][1] > xm.second) { xm.second = mx[x][0][1]; } return xm; } } mst;
本文作者:wnsyou の blog
本文链接:https://www.cnblogs.com/wnsyou-blog/p/spanning_tree.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步