K8s容器资源限制
在K8s中定义Pod中运行容器有两个维度的限制:
1. 资源需求:即运行Pod的节点必须满足运行Pod的最基本需求才能运行Pod。
如: Pod运行至少需要2G内存,1核CPU
2. 资源限额:即运行Pod期间,可能内存使用量会增加,那最多能使用多少内存,这就是资源限额。
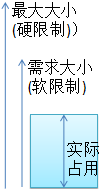
# kubectl describe node node1.zcf.com ....................... Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits #这里显示的就是 资源的需求 和 限额 -------- -------- ------ cpu 250m (12%) 0 (0%) memory 0 (0%) 0 (0%) ephemeral-storage 0 (0%) 0 (0%) Requests: 就是需求限制,也叫软限制 Limits:最大限制,也叫硬限制 通常来说:Limits >= Requests 并且requests 和 limits 通常要一起配置,若只配置了requests,而不配置limits,则很可能导致Pod会吃掉所有资源。
需要注意:
目前k8s在对资源限制方面还有欠缺,特别是Java应用,因为Pod运行起来后,它看到的资源是Node上全部的资源,虽然可通过requests和limits限制,但我们都知道JVM启动后,它要计算自己的堆内存中不同区域的大小,而这些大小通常是按比例划分的,假若JVM启动后,根据Node上实际的内存大小来计算堆内存中老年代,Eden,幸存区那肯定会出问题,因为,我们给它分片的内存肯定不够,所以这个要特别注意,而解决办法,只能是在启动Java应用前,配置JVM能使用的最大内存量。
在K8s的资源:
CPU:
我们知道2核2线程的CPU,可被系统识别为4个逻辑CPU,在K8s中对CPU的分配限制是对逻辑CPU做分片限制的。
也就是说分配给容器一个CPU,实际是分配一个逻辑CPU。
而且1个逻辑CPU还可被单独划分子单位,即 1个逻辑CPU,还可被划分为1000个millicore(毫核), 简单说就是1个逻辑CPU,继续逻辑分割为1000个豪核心。
豪核:可简单理解为将CPU的时间片做逻辑分割,每一段时间片就是一个豪核心。
所以:500m 就是500豪核心,即0.5个逻辑CPU.
内存:
K,M,G,T,P,E #通常这些单位是以1000为换算标准的。
Ki, Mi, Gi, Ti, Pi, Ei #这些通常是以1024为换算标准的。
K8s中资源限制对调度Pod的影响:
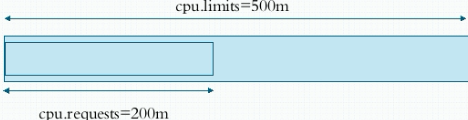
cpu.limits: 是我们设置Pod运行时,最大可使用500m个CPU,但要保障Pod能在Node上成功启动起来,就必需能提供cpu.requests个CPU.
当预选策略在选择备选Node时,会首先考虑当前Pod运行, 其所需资源是否足够, 来做为首要判断条件,假如某Node上已经运行了一些Pod,预选策略会获取当前所有Pod的cpu.requests ,ram.requests等,这里以cpu.requests来说明,比如说某Node上是2核2线程的CPU,所有容器的cpu.requests全部加起来假如已经3.9个CPU了,那么此Node在预选阶段就会被筛选掉。
资源限制配置:
kubectl explain pods.spec.containers.resorces
limits:<map[string]string>
requests:<map[string]string>
#以下压测时,若压测内存,可能导致登录容器都成问题,因此改为仅测试CPU。 apiVersion: v1 kind: Pod metadata: name: pod-cpu-limits labels: app: test tier: frontend spec: containers: - name: myapp image: ikubernetes/stress-ng command: ["/usr/bin/stress-ng","-c 1","--metrics-brief"] resources: requests: cpu: "500m" memory: "512Mi" limits: cpu: "500m" memory: "512Mi"
QoS类型:
Guranteed:
每个容器的CPU,RAM资源都设置了相同值的requests 和 limits属性。
简单说: cpu.limits = cpu.requests
memory.limits = memory.requests
这类Pod的运行优先级最高,但凡这样配置了cpu和内存的limits和requests,它会自动被归为此类。
Burstable:
每个容器至少定义了CPU,RAM的requests属性,这里说每个容器是指:一个Pod中可以运行多个容器。
那么这类容器就会被自动归为burstable,而此类就属于中等优先级。
BestEffort:
没有一个容器设置了requests 或 limits,则会归为此类,而此类别是最低优先级。
QoS类型的作用:
Node上会运行很多Pod,当运行一段时间后,发现Node上的资源紧张了,这时K8s就会根据QoS类别来选择Kill掉一部分Pod,那些会先被Kill掉?
当然就是优先级最低的,也就是BestEffort,若BestEffort被Kill完了,还是紧张,接下来就是Kill中等优先级的,即Burstable,依次类推。
这里有个问题,BestEffort因为没有设置requests和limits,可根据谁占用资源最多,就kill谁,但Burstable设置了requests和limits,它的kill标准是什么?
若按照谁占资源多kill谁,那遇到这样的问题,怎么选择?
PodA: 启动时设置了memory.request=512M , memory.limits=1G
PodB: 设置为: memory.requests=1G, memory.limits=2G
PodA: 运行了一段时间后,占用了500M了,它可能还有继续申请内存。
PodB: 它则占用了512M内存了,但它可能也还需要申请内存。
想想,现在Node资源紧张了,会先kill谁?
其实,会优先kill PodA , 为啥?
因为它启动时,说自己需要512M内存就够了,但你现在这么积极的申请内存,都快把你需求的内存吃完了,只能说明你太激进了,因此会先kill。
而PodB,启动时需要1G,但目前才用了1半,说明它比较温和,因此不会先kill它。
K8s中Pod监控的指标有以下几类:
1. Kubernetes系统指标
2. 容器指标,即:容器使用的CPU,内存,存储等资源的统计用量的
3. 应用指标,即业务应用的指标,如:接收了多少用户请求,正在处理的用户请求等等。
K8s中获取Node资源用量,Pod资源用量要如何实现?
其实早期K8s中kubelet内封装了一个组件叫cAdvisor,它启动后,会监听在14041端口上,来对外提供单节点上Node和Pod的资源统计用量,但是由于安全性问题,后期就将kubelet上的cAdvisor改为不监听,而是会通过配置HeapSter Pod的访问cAdvisor的地址,将自己的统计数据发送给它,由它来负责存储这些统计数据,但HeapSter它默认是将数据存储在缓存中,不能持久存储,因此它需要借助InfluxDB来实现数据的持久化,这些资源统计用量被发给HeapSter后,若通过命令行工具来获取指定Node上的资源使用统计,以及Pod的资源使用统计时,可以用kubectl top [node |pod] 来查看,但若想查看历史数据,就不能实现了,因为命令行工具只能从HeapSter来获取实时数据,而无法获取历史数据,若要获取历史数据,就必须借助另一个组件叫Grafana,它可以从InfluxDB中读取时序存储的数据,并通过图形界面来展示给用户。
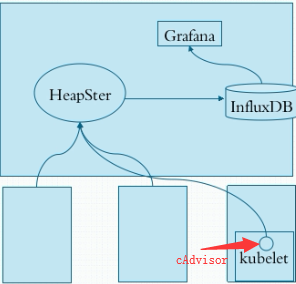
HeapSter 由于从Kubernetes1.11.1以后将被废弃,从11.2后将被彻底废弃。
它被废弃的原因是,因为它自身的设计架构上,会去整合很多第三方开发的后端存储组件,其中InfluxDB就是其中之一,由于是第三方组织研发的,所以这就导致了一个问题,若那天第三方对此不感兴趣了,就会放弃对这些后端存储组件的维护,导致无法继续支持K8s后期版本的。另一个原因是在HeapSter中这些第三方存储组件也是作为其核心代码的一部分存在的,因此它带来的问题是,HeapSter的代码会越来越臃肿,而且配置也会越来越复杂,因而K8s才决定放弃HeapSter。
下面部署中使用了这样的版本组合:
HeapSter-amd64:v1.5.4 + heapster-influxdb-amd64:v1.5 + heapster-grafana-amd64:v5.0.4
#测试发现,不能正常工作,查看日志一切正常,但是无法正常获取监控指标数据。
使用下面这个旧版本的组合,是可以正常工作的,这个需要注意:
HeapSter-amd64:v1.5.1 + heapster-influxdb-amd64:v1.3.3 + heapster-grafana-amd64:v4.4.3
#这个组合中,grafana配置NodePort后,从外部访问,Grafana没有Web图像接口,但从日志上可以看到外部访问记录,也没有报错,怀疑其可能没有图像界面。
#所以这个grafana组件可以不安装。另外,我测试将5.0.4的Grafana部署上,它可以连接到InfluxDB,应该是能获取数据,但因为没有默认面板,所以若想测试,需要自行到grafana官网去找一些模板测试。
构建上面三个组件的顺序:
1. 先部署InfluxDB,因为它被HeapSter所依赖
wget -c https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/influxdb.yaml
2. 接着就可以直接应用此清单
kubectl apply -f influxdb.yaml
若镜像下载失败,可尝试阿里云镜像的谷歌镜像仓库下载:
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/heapster-influxdb-amd64:v1.5.2
3. 验证
# kubectl get pod -n kube-system
#kubectl describe pod -n kube-system monitoring-influxdb-xxxxx
#从输出的信息中可以看到默认influxdb使用HTTP协议来对对外提供服务,你可以通过它的一些专用客户端工具来登入它,查看它所提供的服务。
4. 接下来创建HeapSter,但创建HeapSter前需要先创建它所有依赖的RBAC配置,因为默认使用kubeasz部署的K8s集群是启用了RBAC的,因此需要先创建HeapSter所需的RBAC配置.
wget -c https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/rbac/heapster-rbac.yaml
kubectl apply heapster-rbac.yaml
#创建完RBAC后,就可以创建heapster Pod了。
wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/heapster.yaml
#需要注意: apiVersion: v1 kind: ServiceAccount #heapSter需要使用一个服务帐户,因为它需要能从所有Node上获取Pod的资源统计信息,因此它必须被授权. metadata: name: heapster namespace: kube-system #在HeapSter容器定义部分可以看到它引用了上面创建的SA帐户 spec: serviceAccountName: heapster containers: - name: heapster image: k8s.gcr.io/heapster-amd64:v1.5.4 imagePullPolicy: IfNotPresent command: - /heapster - --source=kubernetes:https://kubernetes.default #这里是定义HeapSter从K8s内部访问APIServer的地址. - --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086 #这是指明HeapSter访问InfluxDB的地址,因为InfluxDB是Pod,不能直接访问Pod的IP,因此这里访问的是InfluxDB前端的SerivseIP。 #另外还有注意,HeapSter也需要Serivce apiVersion: v1 kind: Service ..... name: heapster namespace: kube-system spec: ports: - port: 80 #这里可以看到它在Node上暴露的端口是80 targetPort: 8082 #HeapSter在Pod内部启动的端口为8082 type: NodePort #若需要K8s外部访问HeapSter,可修改端口类型为NodePort selector: k8s-app: heapster
#接着执行应用此清单
kubectl apply -f heapster.yaml
#查看heapster的日志:
kubectl logs -n kube-system heapster-xxxxx
5. 最后来部署Grafana
wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/grafana.yaml
#另外还有需要注意: volumeMounts: - mountPath: /etc/ssl/certs #它会自动挂载Node上的/etc/ssl/certs目录到容器中,并自动生成证书,因为它使用的HTTPS. name: ca-certificates readOnly: true #Grafana启动时,会去连接数据源,默认是InfluxDB,这个配置是通过环境变量来传入的 env: - name: INFLUXDB_HOST value: monitoring-influxdb #这里可看到,它将InfluxDB的Service名传递给Grafana了。 - name: GF_SERVER_HTTP_PORT value: "3000" #默认Grafara在Pod内启动时,监听的端口也是通过环境变量传入的,默认是3000端口. #在一个是,我们需要配置Grafana可以被外部直接访问 ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana type: NodePort
部署完成后,可登录Dashboard查看资源状态统计信息

自定义资源:
在K8s中支持用户根据自己业务的特殊需求去自定义服务组件,来扩展K8s原始的Service,headless等,这种被称为 自制资源定义(CRD)。
另外在K8s中也可自己开发一个新的APIServer,它里面可提供自己所需要的API接口,然后在通过K8s 中的所谓的API聚合器将自己开发的APIServer和K8s自己的APIServer聚合在一起来使用它;在不然就是自己修改K8s源码,来新增需要的功能定义。
K8s从1.8开始引入资源指标API,它将资源的内容也当作API接口中的数据直接进行获取,而不像早期HeapSter,需要先部署HeapSter,然后从HeapSter中获取资源指标数据,这样带来的不便是,我们获取数据就需要通过两个地方获取,当获取API资源(Pod, Service,...)是通过APIServer获取,而获取监控资源指标时,就必须从HeapSter中获取,而在新版的K8s中,引入资源指标API就是想避免这种麻烦,让用户再来获取数据时,全部从APIServer来获取,而要实现这个功能,它引入了一个API聚合器,因为资源监控指标API是允许用户自定义开发的,而开发出来的资源指标API通过一个类似代理层的API聚合器 将这些用户开发的资源指标API 和 原始的APIServer联合起来,用户通过访问API聚合器,来获取自己需要的数据,而API聚合器会根据用户的请求,自动将请求转发给APIServer或资源指标API。
需要说明的是 资源指标API 分为两类,一类是核心指标,另一类是非核心指标,核心指标是metrics-server提供的,它也是一个Pod。
HPA:它是水平Pod自动伸缩器,它也是需要获取资源指标来判断,并作出一些预定义动作,如:判断CPU使用率已经80%了,则会自动增加一个Pod,若发现某个Pod的资源使用率很低,一直维持在比如说5%,它可以自动关闭几个该Pod,以便腾出资源供其它Pod使用等。
kubectl top .... 这个命令 和 HPA功能在早期都是需要依赖HeapSter来工作的,但是HeapSter有个很多的缺陷,它只能统计CPU,内存,磁盘等的资源用量,但无法获取其它更多资源指标,这就限制了我们想获取更多信息的途径,另外也使得HPA的功能受到了限制,例如有时候,Pod的CPU,内存等占有率不高,但其访问量却非常高,这时我们也希望能自动创建Pod来分担并发压力,但HeapSter就无法帮我们做的,因此才导致新的资源指标API的出现,以及后来又引入了自定义资源指标的模型。
Prometheus:它可以收集基本指标,同时还可以收集网络报文的收发速率,网络连接的数量,内存,包括进程的新建和回收的速率等等,而这些K8s早期是不支持的,它让我们可以使用这些功能来增强我们的HPA能力。它即作为监控组件使用,也作为一些特殊指标的资源提供者来提供,但这些不是内建的标准核心指标,这些我们统称为自定义指标。
需要注意Prometheus要想将它监控采集到的数据,转化为指标格式,需要一个特殊的组件,它叫 k8s-prometheus-adapter
K8s新一代监控指标架构由两部分组成:
- 核心指标流水线:由Kubelet资源评估器,metrics-server,以及由APIServer提供的API组成,它里面主要提供最核心的监控指标。主要是通过它让Kubernetes自身的组件来了解内部组件和核心使用程序的指标,目前主要包含,CPU(CPU的累积使用率),内存的实时使用率,Pod的资源占用率和容器的磁盘占用率。【累积使用率:指一个进程累积使用CPU的总时长比例】
- 监控流水线:用于从系统收集各种指标数据并提供给用户,存储,系统以及HPA来使用。 它包含核心指标,同时也包含许多非核心指标;非核心指标不一定能被K8s所理解,简单说:prometheus采集的数据,k8s可能不理解,因为这些数据定义只有在Prometheus的语境中才有定义,因此才需要一个中间组件叫 k8s-prometheus-adapter来将其转化为k8s能理解的监控指标定义。
metrics-server:
它主要用于提供监控指标API,但它通常是由用户提供的API服务,它本身不是k8s的核心组件,它仅是K8s上的一个Pod,因此为了能让用户无缝的使用metrics-server上提供的API,因此就必须使用kube-aggregator。当然kube-aggregator不仅仅可以聚合传统APIServer和metrics-server,它还可以聚合很多用户自定义的API服务。
/apps/metrics.k8s.io/v1beta1:
这个群组默认是不包含在创建API Server中的,因此你通过 kubectl api-versions 查看,是没有这个群组的,这个群组实际是由 metrics-server 来提供的,而我们需要做的是使用kube-aggregator将这个API群组合并到API Server中去,这样用户再去访问API Server时,就可以访问到此API群组了。
#需要修改两个文件: #第一个文件: metrics-server-deployment.yaml #此清单文件定义了metrics-server镜像和metrics-server-nanny容器启动的参数,这些参数有些需要修改 #metrics-server容器: command: - /metrics-server - --metric-resolution=30s #- --kubelet-insecure-tls #网上很多文章都说必须加上此参数, 此参数含义: #若不能做TLS加密认证,使用不安全的通信也可以.但我测试时,不加也能正常工作,仅做借鉴 # These are needed for GKE, which doesn't support secure communication yet. # Remove these lines for non-GKE clusters, and when GKE supports token-based auth. - --kubelet-port=10255 - --deprecated-kubelet-completely-insecure=true - --kubelet-preferred-address-types=InternalIP,Hostname,InternalDNS,ExternalDNS,ExternalIP #metrics-server-nanny容器: command: - /pod_nanny - --config-dir=/etc/config #下面这些{{....}} 这些若不替换,启动metrics-server-nanny容器时会报错,但从报错日志中可以到它们的简单说明 - --cpu={{ base_metrics_server_cpu }} #设置metrics-server基本运行可用CPU豪核数量,测试设置100m - --extra-cpu=0.5m - --memory={{ base_metrics_server_memory }} #分配给metrics-server基本运行的内存大小, 测试设置 150Mi - --extra-memory={{ metrics_server_memory_per_node }}Mi #每个节点上的metrics-server额外分配内存大小,测试50Mi - --threshold=5 - --deployment=metrics-server-v0.3.3 - --container=metrics-server - --poll-period=300000 - --estimator=exponential # Specifies the smallest cluster (defined in number of nodes) # resources will be scaled to. #- --minClusterSize={{ metrics_server_min_cluster_size }} #这里字面意思似乎是 设置启动几组Metrics-server,选项说明提示默认是16组. 但这我注释掉了。 #第二个文件:resource-reader.yaml rules: - apiGroups: - "" resources: - pods - nodes - nodes/stats #这里需要注意:默认是没有添加的,若只添加nodes,它是获取不到nodes/stats的状态信息的, # 因为nodes/stats和nodes是两个不同的资源. nodes/stats是获取节点监控数据的专用资源. - namespaces #以上两个文件修改好后,就可执行应用了 kubectl apply -f ./ #在应用使用,可查看kube-system名称空间中 metrics-server pod的创建 kubectl get pod -n kube-system -w #会发现metrics-server先创建一组,等第二组启动为running后,第一组就会自动终止。目前还没有弄明白是什么逻辑。 #上面修改好后,测试发现还是会报错,但已经不报参数无效的错误了 # kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE ................ metrics-server-v0.3.3-7d598d5c9d-qngp7 2/2 Running 0 49s # kubectl logs -n kube-system metrics-server-v0.3.3-7d598d5c9d-qngp7 -c metrics-server-nanny ERROR: logging before flag.Parse: I0729 13:06:42.923342 1 pod_nanny.go:65] Invoked by [/pod_nanny --config-dir=/etc/config --cpu=100m --extra-cpu=0.5m --memory=300Mi --extra-memory=50Mi --threshold=5 --deployment=metrics-server-v0.3.3 --container=metrics-server --poll-period=300000 --estimator=exponential] ERROR: logging before flag.Parse: I0729 13:06:42.923611 1 pod_nanny.go:81] Watching namespace: kube-system, pod: metrics-server-v0.3.3-7d598d5c9d-qngp7, container: metrics-server. ERROR: logging before flag.Parse: I0729 13:06:42.923642 1 pod_nanny.go:82] storage: MISSING, extra_storage: 0Gi ERROR: logging before flag.Parse: I0729 13:06:42.927214 1 pod_nanny.go:109] cpu: 100m, extra_cpu: 0.5m, memory: 300Mi, extra_memory: 50Mi ERROR: logging before flag.Parse: I0729 13:06:42.927362 1 pod_nanny.go:138] Resources: [{Base:{i:{value:100 scale:-3} d:{Dec:<nil>} s:100m Format:DecimalSI} ExtraPerNode:{i:{value:5 scale:-4} d:{Dec:<nil>} s: Format:DecimalSI} Name:cpu} {Base:{i:{value:314572800 scale:0} d:{Dec:<nil>} s:300Mi Format:BinarySI} ExtraPerNode:{i:{value:52428800 scale:0} d:{Dec:<nil>} s:50Mi Format:BinarySI} Name:memory}] #上面准备就绪后,就可做以下测试 1. 查看api-versions是否多出了一个 metrics.k8s.io/v1beta1 # kubectl api-versions ............. metrics.k8s.io/v1beta1 2. 若以上验证都通过了,则可做以下测试 kubectl proxy --ports=8080 3. 在另一个终端访问8080 curl http://localhost:8080/apis/metrics.k8s.io/v1beta1 { "kind": "APIResourceList", "apiVersion": "v1", "groupVersion": "metrics.k8s.io/v1beta1", "resources": [ { "name": "nodes", "singularName": "", "namespaced": false, "kind": "NodeMetrics", "verbs": [ "get", "list" ........................ } #查看收集到的Pods 和 node监控数据 curl http://localhost:8080/apis/metrics.k8s.io/v1beta1/node
#查看是否能获取Node 和 Pod的资源使用情况:
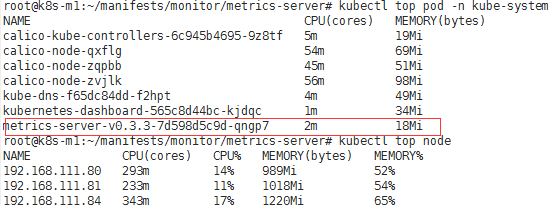
通过上面部署metrics-server,我们可以获取到核心资源信息了,但是若想获取更多监控资源数据,就必须借助另一个Addons组件来获取,而这个Addons就是prometheus
prometheus
它本身就是一个监控系统,它类似于Zabbix,它也需要在Node上安装Agent,而prometheus将自己的Agent称为node_exporter, 但这个node_exporter它仅是用于给Prometheus提供Node的系统级监控指标数据的,因此,若你想采集MySQL的监控数据,你还需要自己部署一个MySQL_exporter,才能采集mySQL的监控数据,而且Prometheus还有很多其它重量级的应用exporter,可在用到时自行学习。
我们需要知道,若你能获取一个node上的监控指标数据,那么去获取该node上运行的Pod的指标数据就非常容易了。因此Prometheus,就是通过metrics URL来获取node上的监控指标数据的,当然我们还可以通过在Pod上定义一些监控指标数据,然后,定义annotations中定义允许 Prometheus来抓取监控指标数据,它就可以直接获取Pod上的监控指标数据了。
PromQL:
这是Prometheus提供的一个RESTful风格的,强大的查询接口,这也是它对外提供的访问自己采集数据的接口。
但是Prometheus采集的数据接口与k8s API Server资源指标数据格式不兼容,因此API Server是不能直接使用Prometheus采集的数据的,需要借助一个第三方开发的k8s-prometheus-adapter来解析prometheus采集到的数据, 这个第三方插件就是通过PromQL接口,获取Prometheus采集的监控数据,然后,将其转化为API Server能识别的监控指标数据格式,但是我们要想通过kubectl来查看这些转化后的Prometheus监控数据,还需要将k8s-prometheus-adpater聚合到API Server中,才能实现直接通过kubectl获取数据 。
#接下来部署Prometheus的步骤大致为:
1. 部署Prometheus
2. 配置Prometheus能够获取Pod的监控指标数据
3. 在K8s上部署一个k8s-prometheus-adpater Pod
4. 此Pod部署成功后,还需要将其聚合到APIServer中
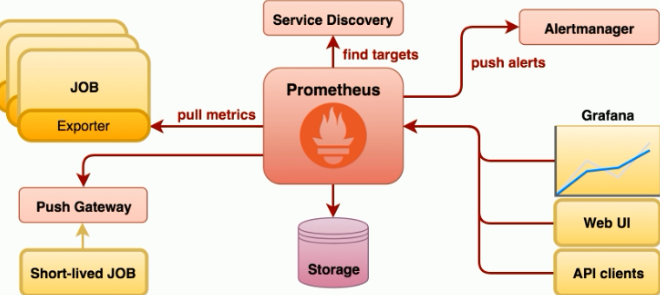
说明:
Prometheus它本身就是一个时序数据库,因为它内建了一个存储 所有eporter 或 主动上报监控指标数据给Prometheus的Push Gateway的数据 存储到自己的内建时序数据库中,因此它不需要想InfluxDB这种外部数据库来存数据。
Prometheus在K8s中通过Service Discovery来找到需要监控的目标主机,然后通过想Grafana来展示自己收集到的所有监控指标数据,另外它还可以通过Web UI 或 APIClients(PromQL)来获取其中的数据。
Prometheus自身没有提供报警功能,它会将自己的报警需求专给另一个组件Alertmanger来实现报警功能。
#在K8s上部署Prometheus需要注意,因为Prometheus本身是一个有状态数据集,因此建议使用statefulSet来部署并控制它,但是若你只打算部署一个副本,那么使用deployment和statefulSet就不重要了。但是你若需要后期进行纵向或横向扩展它,那你就只能使用StatefulSet来部署了。
部署K8s Prometheus
需要注意,这是马哥自己做的简版Prometheus,他没有使用PVC,若需要部署使用PVC的Prometheus,可使用kubernetes官方的Addons中的清单来创建。
官方地址:https://github.com/kubernetes/kubernetes/tree/master/cluster/addons/prometheus
马哥版的地址:https://github.com/iKubernetes/k8s-prom
下面以马哥版本来做说明: 1. 先部署名称空间: kubectl apply -f namespace.yaml --- apiVersion: v1 kind: Namespace metadata: name: prom #这里需要注意: 他是先创建了一个prom的名称空间,然后,将所有Prometheus的应用都放到这个名称空间了。 2. 先创建node_exporter: cd node_exporter #需要注意: apiVersion: apps/v1 kind: DaemonSet metadata: name: prometheus-node-exporter namespace: prom ....... spec: tolerations: #这里需要注意:你要保障此Pod运行起来后,它能容忍Master上的污点.这里仅容忍了默认Master的污点.这里需要根据实际情况做确认。 - effect: NoSchedule key: node-role.kubernetes.io/master containers: - image: prom/node-exporter:v0.15.2 #这里使用的node-exporter的镜像版本。 name: prometheus-node-exporter #应用这些清单 kubectl apply -f ./
#应用完成后,查看Pod

#接着进入Prometheus的清单目录 cd prometheus #prometheus-deploy.yaml 它需要的镜像文件可从hub.docker.com中下载,若网速慢的话。 #prometheus-rbac.yaml apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: [""] resources: - nodes - nodes/proxy - services - endpoints - pods verbs: ["get", "list", "watch"] - apiGroups: - extensions resources: - ingresses verbs: ["get", "list", "watch"] - nonResourceURLs: ["/metrics"] verbs: ["get"] #prometheus-deploy.yaml resources: #这里做了一个资源使用限制,需要确认你每个节点上要能满足2G的可用内存的需求,若你的Node上不能满足这个limits,就将这部分删除,然后做测试。 limits: memory: 2Gi #接着开始应用这些清单: kubectl apply -f ./
#应用完成后查看:
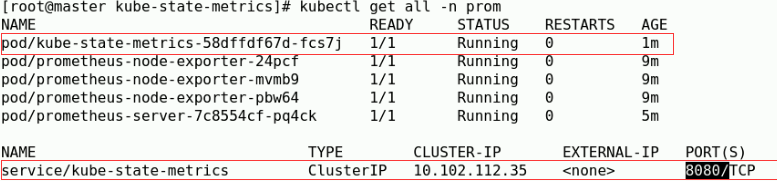
kubectl get all -n prom
#现在来部署,让K8s能获取Prometheus的监控数据 cd kube-state-metrics #此清单中的镜像若不能从google仓库中获取,可到hub.docker.com中搜索镜像名,下载其他人做的测试 #K8s需要通过kube-state-metrics这个组件来进行格式转化,实现将Prometheus的监控数据转换为K8s API Server能识别的格式。 #但是kube-state-metrics转化后,还是不能直接被K8s所使用,它还需要借助k8s-prometheus-adpater来将kube-state-metrics聚合到k8s的API Server里面,这样才能通过K8s API Server来访问这些资源数据。
#应用kube-state-metrics的清单文件 kubectl apply -f ./
#应用完成后,再次验证
#以上创建好以后,可先到k8s-prometheus-adapter的开发者github上下载最新的k8s-prometheus-adapter的清单文件 https://github.com/DirectXMan12/k8s-prometheus-adapter/tree/master/deploy/manifests #注意:
# !!!!!!!!!
# 使用上面新版本的k8s-prometheus-adapter的话,并且是和马哥版的metrics-server结合使用,需要修改清单文件中的名称空间为prom
# !!!!!!!!!!!!!!! # 但下面这个文件要特别注意: custom-metrics-apiserver-auth-reader-role-binding.yaml piVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: custom-metrics-auth-reader namespace: kube-system #这个custom-metrics-auth-reader必须创建在kube-system名称空间中,因为它要绑到这个名称空间中的Role上 roleRef: apiGroup: rbac.authorization.k8s.io kind: Role #此角色是用于外部APIServer认证读的角色 name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: custom-metrics-apiserver #这是我们自己创建的SA账号 namespace: prom #这些需要注意:要修改为prom #以上清单文件下载完成后,需要先修改这些清单文件中的namespace为prom,因为我们要部署的Prometheus都在prom这个名称空间中. 之后就可以正常直接应用了 kubectl apply -f ./
# 应用完成后,需要检查
kubectl get all -n prom #查看所有Pod都已经正常运行后。。
# 查看api-versions中是否已经包含了 custom.metrics.k8s.io/v1beta1, 若包含,则说明部署成功
kubectl api-versions
# 测试获取custom.metrics.k8s.io/v1beta1的监控数据
curl http://localhost:8080/custom.metrics.k8s.io/v1beta1/
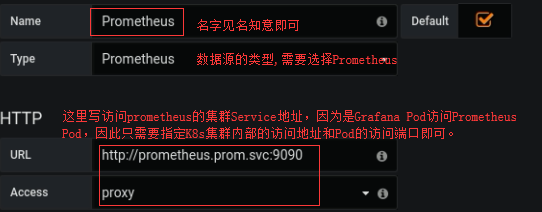
下面测试将Grafana部署起来,并且让Grafana从Prometheus中获取数据 #部署Grafana,这里部署方法和上面部署HeapSter一样,只是这里仅部署Grafana wget https://raw.githubusercontent.com/kubernetes-retired/heapster/master/deploy/kube-config/influxdb/grafana.yaml #此清单若需要修改apiVersion,也要向上面修改一样,配置其seletor。 #另外还有需要注意: volumeMounts: - mountPath: /etc/ssl/certs #它会自动挂载Node上的/etc/ssl/certs目录到容器中,并自动生成证书,因为它使用的HTTPS. name: ca-certificates readOnly: true #Grafana启动时,会去连接数据源,默认是InfluxDB,这个配置是通过环境变量来传入的 env: #- name: INFLUXDB_HOST # value: monitoring-influxdb #这里可看到,它将InfluxDB的Service名传递给Grafana了。 #需要特别注意:因为这里要将Grafana的数据源指定为Prometheus,所以这里需要将InfluxDB做为数据源给关闭,若你知道如何定义prometheus的配置, #也可直接修改,不修改也可以,那就直接注释掉,然后部署完成后,登录Grafana后,在修改它的数据源获取地址。 - name: GF_SERVER_HTTP_PORT value: "3000" #默认Grafara在Pod内启动时,监听的端口也是通过环境变量传入的,默认是3000端口. #在一个是,我们需要配置Grafana可以被外部直接访问 ports: - port: 80 targetPort: 3000 selector: k8s-app: grafana type: NodePort #配置完成后,进行apply kubectl apply -f grafana.yaml #然后查看service对集群外暴露的访问端口 kubectl get svc -n prom
#随后打开浏览器,做以下修改
#接着,你可以查找一个,如何导入第三方做好的模板,然后,从grafana官网下载一个模板,导入就可以获取一个漂亮的监控界面了。
#获取Prometheus的模板文件,可从这个网站获取
https://grafana.com/grafana/dashboards?search=kubernetes
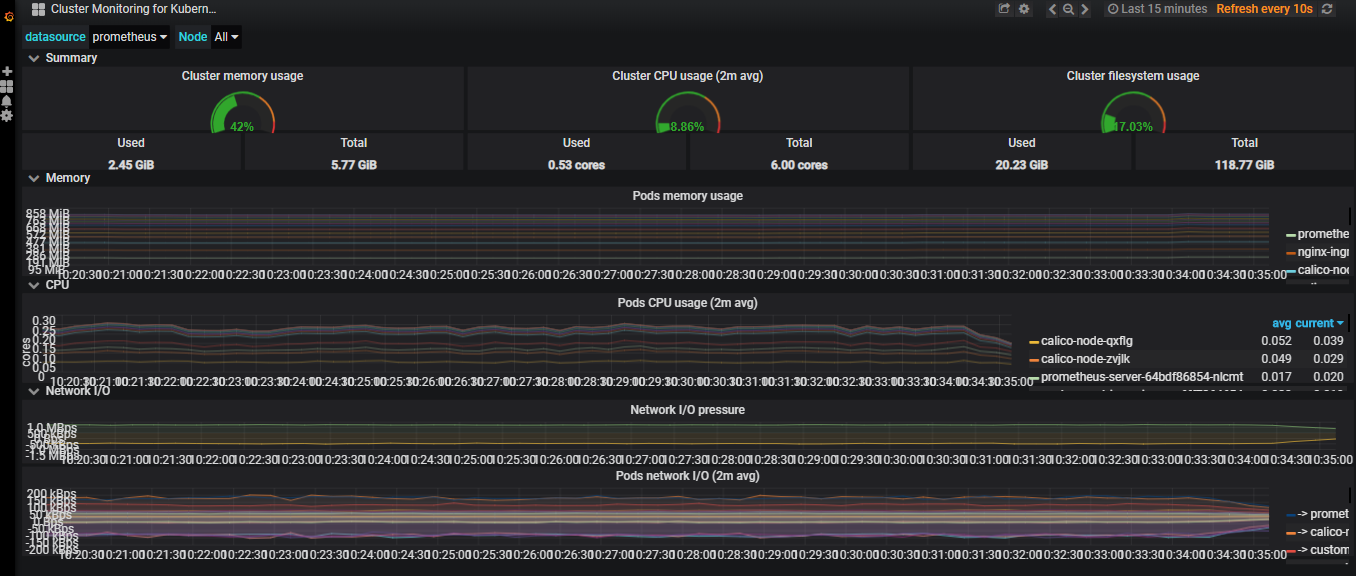
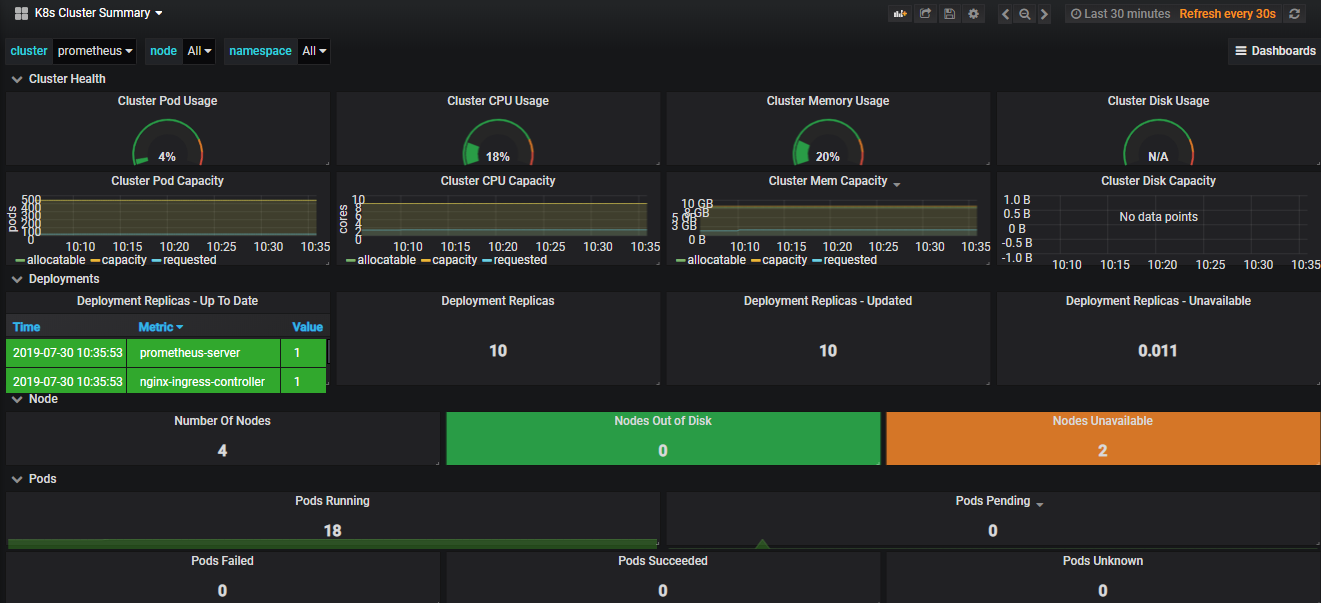
HPA功能:
正如前面所说,它可根据我们所设定的规则,监控当前Pod整体使用率是否超过我们设置的规则,若超过则设置的根据比例动态增加Pod数量。
举个简单的例子:
假如有3个Pod,我们规定其最大使用率不能高于60%,但现在三个Pod每个CPU使用率都到达90%了,那该增加几个Pod的?
HPA的计算方式是:
90% × 3 = 270% , 那在除以60,就是需要增加的Pod数量, 270 / 60 = 4.5 ,也就是5个Pod
#HPA示例:
kubectl run myapp --image=harbor.zcf.com/k8s/myapp:v1 --replicas=1 \
--requests='cpu=50m,memory=256Mi' --limits='cpu=50m,memory=256Mi' \
--labels='app=myapp' --expose --port=50
#修改myapp的svcPort类型为NodePort,让K8s集群外部可以访问myapp,这样方便压力测试,让Pod的CPU使用率上升,然后,查看HPA自动创建Pod.
kubectl patch svc myapp -p '{"spec":{"type":"NodePort"}}'
# kubectl get pods
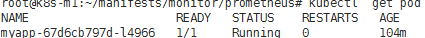
#这里目前只有一个Pod!!
kubectl describe pod myapp-xxxx #可查看到它当前的QoS类别为: Guranteed
#创建HPA,根据CPU利用率来自动伸缩Pod
kubectl autoscale deployment myapp --min=1 --max=8 --cpu-percent=40

#查看当前Pod是Service: # kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE .................. myapp NodePort 172.30.162.48 <none> 80:50113/TCP 103m #创建成功后,就可以通过ab等压测工具来测试自动伸缩 #apt-get install apache2-utils # # ab -c 1000 -n 3000 http://192.168.111.84:50113 #查看HPA自动伸缩情况 # kubectl describe hpa Name: myapp Namespace: default ............................ resource cpu on pods (as a percentage of request): 76% (38m) / 40% Min replicas: 1 Max replicas: 8 Deployment pods: 6 current / 8 desired #这里可看到现在已经启动6个Pod #创建一个HPA v2版本的自动伸缩其 #完整配置清单: vim hpa-pod-demo-v2.yaml apiVersion: v1 kind: Service metadata: labels: app: myapp name: myapp-v2 spec: clusterIP: 172.30.10.98 ports: - port: 80 protocol: TCP targetPort: 80 type: NodePort selector: app: myapp --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: myapp name: myapp-v2 spec: replicas: 1 selector: matchLabels: app: myapp strategy: {} template: metadata: labels: app: myapp spec: containers: - image: harbor.zcf.com/k8s/myapp:v1 name: myapp-v2 ports: - containerPort: 80 resources: limits: cpu: 50m memory: 256Mi requests: cpu: 50m memory: 256Mi --- apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: myapp-v2 spec: maxReplicas: 8 minReplicas: 1 scaleTargetRef: apiVersion: extensions/v1beta1 kind: Deployment name: myapp metrics: - type: Resource resource: name: cpu targetAverageUtilization: 55 - type: Resource resource: name: memory targetAverageValue: 50Mi
#压测方便和上面一样。这个配置清单中定义了CPU和内存的资源监控指标,V2是支持内存监控指标的,但V1是不支持的。

#若以后自己程序员开发的Pod,能通过Prometheus导出Pod的资源指标,比如:HTTP的访问量,连接数,我们就可以根据HTTP的访问量或者连接数来做自动伸缩。
在那个Pod上的那些指标可用,是取决于你的Prometheus能够从你的Pod的应用程序中获取到什么样的指标的,但是Prometheus能获取的指标是由一定语法要求的,开发要依据 Prometheus支持的RESTful风格的接口,去输出一些指标数据,这指标记录当前系统上Web应用程序所承载的最大访问数等一些指标数据,那我们就可基于这些输出的指标数据,来完成HPA自动伸缩的扩展。
#自定义资源指标来创建HPA,实现根据Pod中输出的最大连接数来自动扩缩容Pod
#下面是一个HPA的定义,你还需要创建一个能输出http_requests这个自定义资源指标的Pod,然后才能使用下面的HPA的清单。
下面清单是使用自定义资源监控指标 http_requests 来实现自动扩缩容:
docker pull ikubernetes/metrics-app #可从这里获取metrics-app镜像
vim hpa-http-requests.yaml apiVersion: v1 kind: Service metadata: labels: app: myapp name: myapp-hpa-http-requests spec: clusterIP: 172.30.10.99 #要根据实际情况修改为其集群IP ports: - port: 80 protocol: TCP targetPort: 80 type: NodePort #若需要集群外访问,可添加 selector: app: myapp --- apiVersion: apps/v1 kind: Deployment metadata: labels: app: myapp name: myapp-hpa-http-requests spec: replicas: 1 #这里指定Pod副本数量为1 selector: matchLabels: app: myapp strategy: {} template: metadata: labels: app: myapp annotations: #annotations一定要,并且要定义在容器中!! prometheus.io/scrape: "true" #这是允许Prometheus到容器中抓取监控指标数据 prometheus.io/port: "80" prometheus.io/path: "/metrics" #这是指定从那个URL路径中获取监控指标数据 spec: containers: - image: harbor.zcf.com/k8s/metrics-app #此镜像中包含了做好的,能输出符合Prometheus监控指标格式的数据定义。 name: myapp-metrics ports: - containerPort: 80 resources: limits: cpu: 50m memory: 256Mi requests: cpu: 50m memory: 256Mi --- apiVersion: autoscaling/v2beta1 kind: HorizontalPodAutoscaler metadata: name: myapp-hpa-http-requests spec: maxReplicas: 8 minReplicas: 1 scaleTargetRef: #这指定要伸缩那些类型的Pod。 apiVersion: extensions/v1beta1 kind: Deployment #这里指定对名为 myapp-hpa-http-requests这个 Deployment控制器 下的所有Pod做自动伸缩. name: myapp-hpa-http-requests metrics: - type: Pods #设置监控指标是从那种类型的资源上获取:它支持Resource,Object,Pods ; #resource:核心指标如:cpu,内存可指定此类型,若监控的资源指标是从Pod中获取,那类型就是Pods pods: metricName: http_requests #http_requests就是自定义的监控指标,它是Prometheus中Pod中获取的。 targetAverageValue: 800m #800m:是800个并发请求,因为一个并发请求,就需要一个CPU核心来处理,所以是800个豪核,就是800个并发请求。 # curl http://192.168.111.84:55066/metrics #注意:Prometheus抓取数据时,它要求获取资源指标的数据格式如下: # HELP http_requests_total The amount of requests in total #HELP:告诉Prometheus这个数据的描述信息 # TYPE http_requests_total counter #TYPE: 告诉Prometheus这个数据的类型 http_requests_total 1078 #告诉Prometheus这个数据的值是多少。 # HELP http_requests_per_second The amount of requests per second the latest ten seconds # TYPE http_requests_per_second gauge http_requests_per_second 0.1 # 测试方法: 1. 先在一个终端上执行: for i in `seq 10000`; do curl http://K8S_CLUSTER_NODE_IP:SERVER_NODE_PORT/ ; done 2. 查看hpa的状态 # kubectl describe hpa Name: myapp-hpa-http-requests Namespace: default ......... Reference: Deployment/myapp-hpa-http-requests Metrics: ( current / target ) "http_requests" on pods: 4366m / 800m Min replicas: 1 Max replicas: 8 Deployment pods: 8 current / 8 desired ........................ Events: Type Reason Age From Message ---- ------ ---- ---- ------- ..................... Normal SuccessfulRescale 51s horizontal-pod-autoscaler New size: 4; reason: pods metric http_requests above target Normal SuccessfulRescale 36s horizontal-pod-autoscaler New size: 8; reason: pods metric http_requests above target 3. 查看Pod # kubectl get pod NAME READY STATUS RESTARTS AGE myapp-hpa-http-requests-69c9968cdf-844lb 1/1 Running 0 24s myapp-hpa-http-requests-69c9968cdf-8hcjl 1/1 Running 0 24s myapp-hpa-http-requests-69c9968cdf-8lx9t 1/1 Running 0 39s myapp-hpa-http-requests-69c9968cdf-d4xdr 1/1 Running 0 24s myapp-hpa-http-requests-69c9968cdf-k4v6h 1/1 Running 0 114s myapp-hpa-http-requests-69c9968cdf-px2rl 1/1 Running 0 39s myapp-hpa-http-requests-69c9968cdf-t52xr 1/1 Running 0 39s myapp-hpa-http-requests-69c9968cdf-whjl6 1/1 Running 0 24s

 浙公网安备 33010602011771号
浙公网安备 33010602011771号