KVM原理及使用
Qemu 和 Qemu-kvm
Qemu: http://qemu-project.org/Download
Qemu-kvm:https://sourceforge.net/projects/kvm/files/qemu-kvm/
自2012年低时,Qemu1.3.0版本发布后,qemu-kvm中针对KVM的修改已全部加入到普通的Qemu代码库中,
从此之后可完全使用纯qemu来与kvm配合使用(命令行仅需添加-enable-kvm参数),而无需专门使用
qemu-kvm代码库了,并且qemu-kvm的更新自2012年9月已经停止更新,到2016年5月30日,最新的QEMU稳定版
已经到2.6.0版了。
另外Qemu的漏洞也需要多加关注,截止16年5月已经发现的Qemu 漏洞已经有149个:
http://www.cnnvd.org.cn/vulnerability/index/vulcode2/qemu/vulcode/qemu/cnnvdid/fbsjs/p/2/
KVM简介
KVM (名称来自英语: Kernel-basedVirtual Machine 的缩写,即基于内核的虚拟机),是一种用于Linux
内核中的虚拟化基础设施,可以将Linux内核转化为一个hypervisor。KVM诞生于以色列的一家创业公司Qumranet
员工Avi Kivity等人手中,于2006年8月完成开源并推向Linux内核社区,当年10月被Linux社区接受.2007年2月发布的
Linux2.6.20是第一个包含KVM模块的内核版本.2008年9月Redhat收购Qumranet公司,并开始投入较多资源开发
KVM虚拟化.2011年11月Redhat发布RHEL6中将原先RHEL5的默认企业级虚拟化Xen彻底去掉改用KVM.
KVM要求CPU必须支持HVM(硬件虚拟化)即:Intel的CPU要支持VT-x或AMD的CPU必须支持AMD-V的功能;
若硬件支持内存的虚拟化,如EPT/NPT及I/O设备的虚拟化,如:VT-d/SR-IOV的支持则会对KVM的虚拟化效率有
很大的提高。KVM也被移植到S/390,PowerPC与IA-64平台上。在Linux内核3.9版中,加入ARM架构的支持。
目前KVM的开源社区也非常活跃,其Redhat的工程师在KVM、QEMU、libvirt等开源社区中成为核心开发成员.
除Redhat外,还有IBM、Intel、Novell、AMD、Siemens、华为以及一些小公司 和 个人独立开发者活跃在
KVM开源社区,为KVM开发代码或者做测试工作。
在硬件方面的虚拟化支持和软件方面的功能开发、性能优化的共同作用下,目前KVM虚拟化技术已经拥有
非常丰富的功能和非常优秀的性能。且KVM的上层管理工具如:libvirt、Ovirt、Virt-Manager、OpenStack
(云计算平台)等也在日渐成熟, KVM将逐渐成为虚拟化开源领域的主力。
KVM由两部分组成: 内核模块和管理接口
内核模块
ls -1 /lib/modules/`uname -r`/kernel/arch/x86/kvm/
kvm-amd.ko #KVM对AMD CPU所提供的虚拟化驱动
kvm-intel.ko #KVM对Intel CPU所提供的虚拟化驱动
kvm.ko #KVM的核心模块
管理接口
yum install qeum-kvm #此为KVM为用户提供的管理VM的接口。
#它是针对KVM的需要定制的Qemu软件.
KVM模块载入后的系统运行模式:
内核模式:GuestOS执行I/O类操作,或其它的特殊指令的操作.
用户模式:代表GuestOS请求I/O类操作;
来宾模式:GuestOS的非I/O类操作;事实上,它被称作虚拟机的用户模式更贴切.
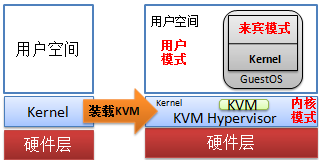
KVM的两类组件:
/dev/kvm: 它是一个字符设备,工作于Hypervisor(Linux Kernel)层,在用户空间可通过ioctl()
系统调用来完成VM创建、启动等管理功能.【注:当装载了kvm.ko 和 kvm-intel或amd.ko后,才会有此设备.】
具体职责:
创建VM、为VM分配内存、读写VCPU寄存器、向VCPU注入中断、调度GuestOS-APP到VCPU上运行等.
qemu进程:工作于用户空间, 主要用于实现模拟PC机的IO设备;
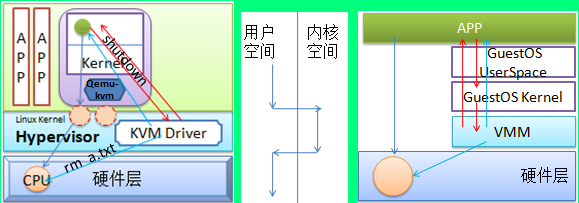
下图是KVM虚拟机中APP运行方式图:
在非虚拟化的环境中,APP(应用程序)运行时,它实际是直接运行在CPU上的,仅当它需要调用特权指令时,
如:访问I/O设备、关机等特权指令时,它会发起系统调用,然后,APP被调入内存等待,内核中的一段代码将被
调度到CPU执行,完成操作后,内核代码会唤醒APP继续运行. 那么在虚拟化的环境中,GuestOS中的APP运行时
是否会被调度到CPU执行?当然,答案是肯定的,KVM在进行CPU虚拟化时,会为GuestOS模拟一颗或多颗CPU,
这些CPU实际是绑定在某个物理核心上的线程,当GuestOS的APP运行时,它被调度到虚拟CPU上,而这些虚拟CPU
实际是映射到某个物理核心上的,因此实际上GuestOS的APP是运行在CPU上的.
下面三幅图要说的是同一个问题, 当GuestOS中的APP运行时,因为虚拟架构和物理架构是相同的,因此
GuestOS中的APP是可以直接运行在物理CPU上的,若虚拟架构与物理架构不同,则GuestOS的APP是无法直接
运行在物理CPU上的,因为,物理CPU根本就无法理解GuestOS的APP所调用的CPU环3上的普通指令,所以肯定
是无法执行的,因此需要VMM来作为中间的翻译代GuestOS的APP执行它所需要物理CPU执行的代码.
另外GuestOS中APP执行时,当执行非特权指令时它是直接运行于物理CPU上,但若执行特权指令时,一定
是由VMM(虚拟机监视器)代为执行,此时的执行流程是GuestOS的APP先向GuestOS的kernel发起系统调用
GuestOS的Kernel再向VMM请求,最终VMM根据GuestOS-APP的请求,来决定如何处理,如它所发出的特权指令
是访问物理I/O设备,则VMM将代为向物理CPU发起请求,若该特权指令是关机、重启则VMM将直接返回告诉
GuestOS-APP已经完成操作,然后,VMM再切断该GuestOS的电源,而非物理机的电源.
KVM的特性:
内存管理:
(1) 将分配给VM的内存交换至SWAP;
(2) 支持使用Huge Page(大内存页),故而可实现更高性能的内存分配.
(3) 支持使用Intel 的EPT(扩展页表) 或 AMD的RVI(快速虚拟索引:也叫NPT(嵌套页表))技术完成内存地址映射。
此映射指: 直接从VM中APP的虚拟线性地址空间直接映射为宿主机的物理内存地址空间.
同时EPT和RVI都实现了tagging-TLB,即对虚拟线性地址与物理地址转换结果的缓存标记功能.
简单说: tagging-TLB:
VM标签 | VM虚拟线性地址 | Host物理内存地址
VM-A | 0x0000001 | 0x0101FF011
VM-B | 0x0000001 | 0x01FFF2982
若没有EPT或RVI则VM中APP访问宿主机的物理内存就必须借助影子页表来实现.
即: GuestOS-APP的虚拟线性地址--->
GuestOS-Kernel的虚拟物理地址--->
Shadow Page Table将GuestOS的虚拟物理地址转为Host的物理内存地址--->
宿主机的物理内存地址.
(4) 支持KSM(Kernel Same-page Merging:相同内存页合并) :它可以将相同内存块进行合并以便节省内存空间
当一个被合并的块需要修改时,KSM会启动CoW(写时复制)的机制来创建一个内存块的副本,以完成修改.
KVM对硬件的支持:
KVM对硬件的支持取决于Linux Kernel对硬件的支持.因为KVM实际上是一个内核模块,它一旦被Kernel装载,则
Linux Kernel将即刻变成Hypervisor,来向VM提供CPU、内存、及I/O设备的虚拟化支持。
KVM的存储支持:
(1) 支持本地存储: IDE、SATA、SCSI、CDROM等
(2) 支持网络附加存储:NFS/Samba,iSCSI
(3) 支持存储区域网络:FCoE
(4) 支持分布式存储:GlusterFS等
KVM支持实现迁移:
KVM支持的GuestOS:
Linux, Windows(KVM还通过了微软的虚拟化应用认证,即:KVM环境中的Windows出现问题,若系统是正版的,微软还会提供技术支持),
OpenBSD, FreeBSD, OpenSolaris等.
KVM的设备驱动:
IO设备的完全虚拟化:
硬件模拟,这些模拟的硬件是运行在KVM宿主机的用户空间中的线程.
IO设备的半虚拟化:
在GuestOS中安装驱动:virtio; virtio是Redhat和IBM联合研发的开源虚拟化IO驱动。它已经支持
virtio-blk,virtio-net,virtio-pci,virtio-console,virtio-balloon(内存动态大小调整)。
KVM的局限性:
一般局限性:
CPU overcommit(过载):
即KVM在给VM分配资源时,尽量避免超过宿主机的物理CPU的资源数,如:物理CPU
有6颗,那么分配给VM的VCPU的总和应该为6,若超过,则这些VCPU将会在物理CPU间调度以
实现获得CPU资源,但这将对性能造成一定影响。
时间记录难以精确:
这是因为操作系统在启动时,会读取一次硬件时钟,作为系统启动时的系统时钟,随后,
OS将通过CPU的频率来计时,如CPU的主频为2GHz,则OS会检测CPU的晶振次数若到达2G次,
则认为已经过了1秒,以此来更新时钟.但在虚拟化环境中,GuestOS是不可独占CPU的,因此它统计
的CPU晶振次数是不精确的,这也导致GuestOS的时钟不可能非常精确.它必须依赖与时钟服务器来同步时间.
MAC地址:
VM数量特别多时,存在冲突的可能。
实时迁移:
(1) GuestOS的磁盘映像文件必须放在共享存储上,并且源和目标KVM挂载共享的位置必须一致.
(2) 迁移的目标KVM的版本必须相互兼容。
(3) CPU必须是相同的.
(4) I/O透传将不支持迁移,因为:若A端使用一个磁盘分区做为GuestOS的系统分区,就无法迁移到B端.
(5) 两端的时间必须同步。
(6) 两端的网络配置必须一样,如: A端GuestOS桥接在br0上,但B端没有br0就会出现错误。
性能局限性:【注:都是相对于物理硬件而言】
(1) 完全虚拟化中CPU的MMU的性能仅7%
半虚拟化中CPU支持EPT或RVI则性能可达97%
(2) 磁盘I/O的虚拟化性能
模拟磁盘: 40%
I/O半虚拟化: 85%
I/O透传技术:95%
(3) 显卡完全虚拟化的性能: 45%,它不支持半虚拟化.
(4) 完全虚拟化的时间:快或慢5%, 半虚拟化可以做到精确,因为有辅助模块的支持。
KVM的工具栈:
qemu:
qemu-kvm: 此为qemu专为KVM而设计的虚拟机管理工具,qemu本身也是一个虚拟化工具,不过它是模拟器,
支持物理硬件和虚拟硬件不同,但在虚拟环境和物理环境相同时,qemu会与KVM结合来提供虚拟化.
qemu-img: 此工具是专门用来创建虚拟磁盘映像文件的.
libvirt:
GUI: virt-manager(一个图形管理虚拟机的工具)、virt-viewer(它仅是一个查看虚拟机的监视器)
CLI: virt-install(仅用来创建、删除VM等), virsh(可用来管理VM的整个生命周期,但创建VM需要提供xml文件,不是很方便.)
libvirt工具在使用时,必须启动一个进程libvirtd,这使得virt-manager、virt-install、virsh都可以支持远程管理VM.
QEMU主要提供了以下几个部分:
(1) 处理器 模拟
(2) 仿真I/O设备
(3) 关联模拟的设备至真实设备
(4) 调试器
(5) 与模拟器交互的用户接口
使用KVM的条件
(1) 确保CPU支持硬件虚拟化: grep --color -E 'svm|vmx' /proc/cpuinfo #svm: AMD的AMD-v,vmx: Intel的VT-x
(2)只要内核装载了 kvm 、kvm-intel(intel CPU需要加载) 则当前Linux的kernel就即刻变成KVM Hypervisor了。
接着就只需要验证下 ls /dev/kvm 若存在,则说明KVM Hypervisor已经成功寄宿到Kernel了。
注: 若是AMD的CPU则需要装载: kvm-amd
IO半虚拟化驱动:virtio
下载地址:
https://fedorapeople.org/groups/virt
I/O半虚拟化:
前端驱动(Virtio前半段):virtio-blk,virtio-net,virtio-balloon,virtio-console
Linux:CentOS4.8及以后版本/5.3及以后版本/6全系列及以上版本都支持Virtio前端驱动
virtio:虚拟队列,通过virt-ring实现
transport:负责从前端队列中取出请求,交由后端处理程序进行处理。
后端处理程序(virt backend drivers):它在QEMU中实现。
virtio-balloon:
ballooning:让VM中运行的GuestOS的内存可在开机状态下动态套装内存大小。
基本过程为:
(1) 增加GuestOS内存:从A向外扩,从B向外收,来增加GuestOS内存。
(2) 减少GuestOS内存:从B向内扩,从A向内收, 挤出GuestOS内存,回收给Host。
qemu-kvm -balloon virtio
手动在QEMU-monitor中查看balloon使用情况
info balloon
balloon MemSize #动态调整KVM虚拟机内存的大小,默认单位:MB
#注: VM源分配内存512MB, 调小100M,则MemSize=412
virtio-net :
qemu-kvm -net nic,model=?
qemu-kvm -net nic,model=virtio
#查看KVM虚拟机是否使用了virtio
ethtool -i eth1
Host中关闭网卡的GSO,TSO,可能提高网卡性能。
ethtool -K $IF gso off
ethtool -K $IF tso off
ethtool -k $IF
注:TSO(TCP Segmentation Offload TCP分片):
网卡支持TSO则 系统会延迟大数据段的在TCP层分段,而是将大数据段交给网卡来进行分段,
然后在调用IP层根据MTU来分片,减轻CPU负荷。(注:此时分片中只有第一个分片包有TCP头,
后续只有IP头,这使得第一个分片丢失,则整个报文必须重传!)【注:这是TSO和GSO最大的区别】
UFO(UDP Fragmentation Offload UDP分片):
UDP不支持分片,它需要在IP层进行分片。
GSO(Generic Segmentation Offload 通用分片):
它支持多种协议,它的设计思想是尽可能在发往硬件驱动前延迟数据分片尽可能让网卡硬件
来调用Linux内核做分片工作,减轻CPU负担,在使用中GSO会先判断网卡是否支持TSO,支持则
GSO会控制着TCP层分段前将数据发给网卡驱动由网卡芯片来执行分段,随后再调用IP层分片,
不需要CPU参与(注:此时分片中只有第一个分片包有TCP/UDP头,后续只有IP头,这使得第一个
分片丢失,则整个报文必须重传!)。
若不支持TSO,则Linux内核来调用GSO,由它来调用TCP/UDP的回调函数来分段,接着
发给下层IP层,注意TCP分段的大小是按照MSS(Max Segment Size:最大段大小) 来分段的,
因此到IP层后,若分段加上IP头部后超过MTU(Max Transmission Unit:最大传输单元),则
IP层还要在进行分片,最后交给网卡发出。 (注:这里是每个包都有TCP/UDP头和IP头)
收数据
LRO(Large Receive Offload:)
它是接收TSO发出的分片数据包,并将多个TCP分段聚合成一个skb结构,当合并多个skb后,
一次发给网络栈,减小上层协议栈的skb开销。
它使用发送方IP,目的地IP,IP封包ID,L4协议四者来区分段,这会导致从同一个LAN里面的两台
PC要往同一目的IP发包时,到达对端的包若被分片了,在将分片包组合为完整包时,要区分那些
分片报文是一组时,可能会出现三者都一样的问题,因为LAN中的两台PC访问的目的IP和
发送者IP都一样(SNAT后,LAN中PC的LAN IP被换成了互联网IP), 而IP封包ID又非全局分配,可能一样,
L4协议可能都是TCP。这就可能出现"卷绕"的BUG。
GRO(Generic Receive Offloading) :
它接收GSO发出的分段报文。并使用发送方和目的方IP,源/目的端口,L4协议三者来区分分段报文,
完成分段报文的拼接,最后一股脑全部将拼接后的报文送到网络栈。对于现在来说基本都使用GRO
而不使用LRO来接收分段数据。
性能影响
GuestOS和HostOS都打开GSO/TSO/UFO > GuestOS打开,HostOS关闭 > GuestOS,HostOS都关闭
对TCP来说:CPU资源充足时, TSO/GSO开不开意义不大。
CPU资源不足时, TSO/GSO带来的性能提升会较明显。
对UDP来说:改进效果一般,性能提升不超过20%
但在VxLAN隧道中,其实是可以关闭GSO,从而避免它带来一些潜在问题。
潜在问题
1.网络传输延迟,因为包大小增加,会增大driver queue的容量(capacity)。这会导致一些交互式应用发的
小包和等待分片的大包在driver queue队列中等待排队发出,造成交互式应用出现无法忍受的网络延时。
所以若网络出现一些莫名其妙的问题时可以尝试关闭offloading技术。
GSO和TSO封包说明:
1.系统先判断网卡是否支持GSO(注:Guest中的Virtio NIC是支持的),支持并且启用了GSO则Guest会直接将
没有分段的GSO大帧传递给Virtio-net驱动.
2.当Virtio-net驱动会通过Virtio-ring将GSO大帧传给Host上的Virtio backend dirver.
3.Host上的tap和bridge都会原封不动的转发这个GSO大帧(注:包结构为:Payload,inner-tcp,inner-ip,inner-ethernet)
4.Host上的VxLAN driver在原GSO大帧上添加VxLAN帧头,则包结构变为:Payload,inner-tcp,inner-ip,inner-ethernet,vxlan
5.若Host上不支持GSO,则Host的IP层将直接对UDP层分片(注:只有第一个分片有UDP头,其余只有IP头)
分片1包结构:Payload,inner-tcp,inner-ip,inner-ethernet,vxlan,outer-udp,outer-ip
分片2包结构:Payload,inner-tcp,inner-ip,inner-ethernet,vxlan,outer-ip
6.若Host支持GSO,再看物理网卡,若支持TSO,则直接将大帧(即:Payload,inner-tcp,inner-ip,inner-ethernet,vxlan)
转发给物理网卡的TSO去硬件分片。若不支持TSO,则Linux系统将调用GSO软件执行分片,而GSO由于会调用
UDP的回调函数,但没有VxLAN的回调函数,所以这里的GSO分片应该每一个都有UDP头,但只有第一个有VxLAN头。
分片1包结构:Payload,inner-tcp,inner-ip,inner-ethernet,vxlan,outer-udp,outer-ip
分片2包结构:Payload,inner-tcp,inner-ip,inner-ethernet,outer-udp,outer-ip
7.但Host的物理网卡是根据MSS(最大段大小)来确定即发给远端的包大小是由Guest的MSS值设定,而非MTU值.
Host上打开GSO后,又增加了outer-udp,会造成包大小大于MSS值,从而继续在outer-ip时进行IP分片。
【注:所以Redhat的最佳实践是关闭host上的GSO特性】
从Host到GuestOS的包流向
以OpenStack的网络节点为例:
Internet--->eth0--->br-ex--->qg-XXX--->qr-XXX--->br-int(OVS-bridge)--->ovs-patch-ports--->
br-tun(for STT Tunnel)--->eth1--->OpenStack的管理网络
注:若eth0,eth1的MTU=9000,则Host的GRO打开,则eth0收到的数据会分段重组为一个大GRO帧。
路由器:
数据包在通过Router时,conntrack需要将分片重组后,使用防火墙规则检查,避免攻击,但Router有一个特性,
就是它对重组的包有一个重组定时器,若超时依然没有重组完成,则Router将丢弃并清理该分段数据包,这就会
导致丢包,网络不通的情况出现。
若将Linux配置为一台路由器的话,要查看Router分段重组超时的设置,以及分段重组所能使用的最大内存量:
cat /proc/sys/net/ipv4/ipfrag_low_thresh #这是分段重组最少可以使用的内存量
cat /proc/sys/net/ipv4/ipfrag_high_threst #可用的最大内存量
cat /proc/sys/net/ipv4/ipfrag_time #分段重组超时的默认值
LinuxBridge上关闭防火墙功能:
net.bridge.bridge-nf-call-arptables = 0
net.bridge.bridge-nf-call-iptables = 0
net.bridge.bridge-nf-call-ip6tables = 0
1.若Host上的GRO打开,则Host上的物理网卡要先将分片重组为一个大GRO包。
2.若br-ex是LinuxBridge,且防火墙开启了,则netfilter conntrack为了做二层的防欺骗检查,需重组分片,检测通过后,
再重新分片(注:此时分片采用出去的网络接口上的MTU进行分片, 这和Guest向Host发包时用Guest的TCP/UDP
协议栈上的MSS不同。),重新分片时将使用qg-xxx的MTU来分片,一般MTU值为1500,这是标准默认值。
3.即使br-ex不是LinuxBridge,eth0在重组分片后,做完防火墙检查后,再使用9000重新分片,再传到后面MTU为1500
的虚拟设备又会先分片再重组,所以若MTU设置不当,还不如将Host上的TSO/GSO/GRO关闭更好。
4.最后virtio会将大帧传入Guest。
VMware STT隧道
STT:它是加了伪装TCP头,通过网卡的TSO特性,让网卡硬件来对数据包做分片以便加速CPU性能的技术。
注: OVS(OpenVSwitch) bridge支持STT,但LinuxBridge不支持。
NSX Bridge:它是用OVS实现的,它不具有LinuxBridge的bridge-nf-call-iptables的特性。但它和OpenStack的neutron
集成时依然可以这样用:
tap--->qbr--->qvr--->br-int--->ovs-patch-port--->phy-br-eth0
这里的qbr和phy-br-eth0均有可能是LinuxBridge。
OpenStack的问题:
创建Windows实例成功,但RDP连接总被取消或关闭。尝试过关闭NIC中的TSO/GSO/GRO没能解决,
修改了WindowsNIC校验和也没有解决。
可参看以下解决方法:
1.若用隧道,则Guest中需要修改MTU
2.关闭LinuxBridge的防火墙功能
3.若需要使用conntract特性没有关闭LinuxBridge防火墙功能,则关闭Host上的GSO/TSO/GRO。
4.重点关注Host上物理网卡与LinuxBridge上的MTU,其它虚拟网卡的MTU默认即可。
5.也可尝试关闭Offload的rx和tx特性。(ethtool --offload eth0 rx off tx off sgo off tso off)
注:当Tx和Rx打开时,Chksum是在硬件网卡处做的。
Virtio:
在Virtio中Guest的Virtio的前端驱动要访问后端驱动的流程:
virtio-net/virtio-pci---->virtio-queue--->发送notify的trap中断给Hypervisor---->Hypervisor调用
Host中面向Guest的前端驱动API接口----->由API接口访问后端驱动----->后端驱动再访问到物理设备。
注:
Guest内核中的tx0和rx0两个队列与Host中的rx和tx两个队列是通过共享内存交换数据的。
VxLAN实现:
从Guest出来的TCP数据段到达Host的VxLAN设备时,它会给该数据段计算TOS,TTL,df,src_port,dst_port,md,Flags等,
并设置GSO参数后,传到给UDP Tunnel协议栈继续处理,然后再送入IP层处理。
【不是很确定,仅做参考】
此时若网卡硬件支持TSO和UFO,则由网卡芯片来做UDP 分片,然后由硬件做IP分片,最后送到网卡。
若网卡不支持,则送入Device Driver Queue(设备驱动队列)时,由Linux内核调用UDP GSO分片,再IP分片,再到网卡。
注:
Guest上TCP协议栈设置的TCP MSS是始终保持不变的,网卡硬件对UDP所做的UDP GSO分片数据报的大小还是根据
TCP MSS来定的。所以VxLAN协议有一个问题就是Host的IP分片是根据Guest中TCP连接的MSS来进行的。简单说
就是传入到IP层的数据报文大小只要超过物理网卡的MTU,就必须进行IP分片。
vhost-net :
区别:
》virtio-net:工作于用户空间的Qemu进程,来模拟后端驱动.
》vhost-net:工作于内核空间的内核模块,来模拟后端驱动。
优劣:
》virtio-net: 不存在VM处理网络流量的快慢问题,因为Virtio-ring是virtio实现的收发缓冲器,
它是像一个环,发送或接收数据会先放到环中的一个槽位中,等待发送或处理,并且
后端驱动是在用户空间模拟,它是可以直接访问物理网卡的,并受Linux控制。
》vhost-net:它运行于内核空间,处理速度非常快,并且当vnet_hdr标识打开后,该标识会允许
对数据包的校验和仅做部分检查,这将允许大数据包发送,并且也变相提高了吞吐量。
而VM在处理网络流量时,若无法跟上vhost-net的速度,就会出现VM正在处理接收的数据,
但vhost-net已经发完了需要发送的数据,并且也已经接收完了返回的数据,导致宿主机的
接收缓冲区快速被占满; TCP还好,它的窗口滑动机制可逐渐控制发送速度变慢,并且还有
丢包重传机制保护; 但UDP就不行了,它一旦丢了就丢了.而缓冲区满后,后来的UDP可能
将全部丢掉,这将大大降低整体性能。
#启动vhost-net的方法。
# vnet_hdr: on强制启用vnet的hdr标识,不启用可能会出错。
# HDR标识:它是TAP/TUN虚拟设备的“IFF_VNET_HDR”标识,它打开后,
# 将允许发送或接受大数据包时仅做部分校验和检查,从而变相提高网络吞吐量。
# vhostforce=[on|off] 设置是否强制使用vhost作为非MSI-X中断方式的virtio客户机的后端处理程序.
注: MSI-X: PCIe总线引出MSI-X机制的主要目的是为了扩展PCIe设备使用中断向量的个数,
同时解决MSI中断机制要求使用中断向量号连续所带来的问题。
MSI-X Capability中断机制与MSI Capability的中断机制类似。
https://www.cnblogs.com/helloworldspace/p/6760718.html
#
-net tap[,vnet_hdr=on|off [,vhost=on|off]]
示例:
qemu-kvm -name rhel64-03 -m 512 -smp 2 -hda /images/kvm/rhel6.4.img \
-net nic,model=virtio,macaddr=52:54:... \
-net tap,vnet_hdr=on,vhost=on,script=/etc/kvm/if-up,downscript=no \
-vnc :5
注:
#在使用libvirt创建VM时,若不想使用vhost,则修改VM的xml配置文件:
<interface type="network">
....
<model type="virtio"/>
<driver name="qemu"> #若使用vhost-net,则修改qemu为vhost。
</interface>
virtio-blk:
kvm_clock: 半虚拟化时钟
# VM的时钟不同步对于Web应用中Cookie或Session有效期计算、VM迁移,
# 等依赖时间戳的应用都会造成影响。
# Constant TSC(Constant Time Stamp Counter:不变的时钟计数器),它是一个恒定
# 不变的CPU频率计算器,无论CPU核心是否因省电策略改变频率,它都始终保持不变,
# 此功能在较新的CPU中得到了支持,这是对VM精确计时提供的硬件支持.
#查看本机是否支持kvm_clock:
grep 'constant_tsc' /proc/cpuinfo
#查看CPU是否支持Censtant TSC
# 注:"TSC deadline"模式是通过软件设定"deadline(最后期限)"的阈值,当CPU的时间戳计数器
# 大于或等于deadline阙值,则本地高级可编程中断控制器(Local APIC)就会产生一个时钟中断请求
# (IRQ),来保障VM时间的精确。
# 另注:
# KVM在Linux3.6以后才对TSC Deadline Timer提供支持。
# qemu-kvm是从0.12版开始支持, qemu-kvm -cpu host 来向VM输入TSC Deadline Timer特性.
grep 'tsc_deadline_timer' /proc/cpuinfo
#查看Linux内核是否编译了对kvm_clock的支持
grep -iE 'paravirt|KVM_CLOCK' /boot/config-*
CONFIG_PARAVIRT_CLOCK=y #y:编译进内核
#默认KVM已经让kvm_clock成为时间源,所以无需显示指定加载。
demsg |grep -i --color 'kvm-clock' #在VM中使用此命令即可看到kvm-clock已经加载.
Intel和AMD的I/O虚拟化技术规范
Intel VT-d(Virtualization Technology for Directed I/O) 和 AMD Vi(也叫IOMMU) :
PCI硬件设备对VT-d技术的支持与否,决定了VM是否可独占使用该物理设备.并且这种使用
几乎是不需要Hypervisor参与的。但是要真正实现VM直接使用物理设备,还需要中断重映射
(Interrupt Remapping) 和 DMAR(DMA虚拟化,其核心芯片为IOMMU)的支持。
#检查VT-d在宿主机上是否启用:
dmesg |grep -i 'DMAR' #Intel VT-d搜此关键字
dmesg |grep -i 'IOMMU' #AMD Vi搜此关键字
#注: GRUB的Kernel默认没有启用IOMMU,可grub.conf的kernel项后追加"intel_iommu=on"来启用.
#若要将物理设备分配给VM独占使用,还需要将该设备在宿主机中隐藏,
#使其他VM和宿主机不能再使用该设备.
#pci_stub可实现隐藏宿主机中的物理设备,以便VM独占使用.
modprobe pci_stub
grep -i 'pci_stub' /boot/config-*
CONFIG_PCI_STUB=y #这表示PCI_STUB已经编译到内核了。
#若该模块以经编译到Kernel中了,则检查以下目录是否存在,则说明pci_stub已经编译到内核中了.
ls /sys/bus/pci/drivers/pci-stub
#绑定PCI设备的方法:
(1) 查看PCI设备的vendor ID(厂商ID) 和 device ID(设备ID)
lspci |grep -i 'eth' #注:假设是绑定网卡,用此命令找出该网卡的BDF(Bus:Device.Function)信息.
02:01.0 Ethernet controller: Intel Corporation 82545EM Gigabit Ethernet Controller (Copper) (rev 01)
02:05.0 Ethernet controller: Intel Corporation 82545EM Gigabit Ethernet Controller (Copper) (rev 01)
[root@node2 ~]# ethtool -i eth1
driver: e1000
version: 7.3.21-k8-NAPI
firmware-version:
bus-info: 0000:02:05.0
lspci -Dn -s 02:05.0 #假设08:00.0是该网卡的PCI总线地址(BDF信息).
0000:02:05.0 0200: 8086:100f (rev 01)
注:8086即为vendor ID, 100f就是device ID.
0000:表示PCI设备的域,一般为0,当有多个Host PCI Bridge时,其值范围为:0~0xffff。
08: bus
00: slot
0: function
(2) 绑定设备到pci_stub驱动.
echo -n "8086 100f" > /sys/bus/pci/drivers/pci-stub/new_id
#注:下面两个是一样的,1是一个软连接,2是真实路径
1.echo '0000:02:05.0' > /sys/bus/pci/devices/0000\:02\:05.0/driver/unbind
2. echo '0000:02:05.0' > /sys/bus/pci/drivers/e1000/0000\:02\:05.0/driver/unbind
echo '0000:02:05.0' > /sys/bus/pci/drivers/pci-stub/bind
#查看绑定后的效果
lspci -k -s 02:05 .0 #查看kernel当前使用此PCI设备的驱动和Kernel中可支持该设备的模块.
....
Kernel driver in use: pci-stub #Kernel当前使用的网卡驱动已经改成pci-stub了.
Kernel modules:e1000 #[注:这里我还不是很明白,内核使用了pci-stub做网卡驱动,这与隔离网卡有什么关系.]
(3) qemu-kvm命令创建VM时,绑定物理设备给VM.
qemu-kvm -device ? #查看qemu-kvm支持的设备驱动.
qemu-kvm -device pci-assign,? #查看pci-assign驱动的属性值.
# 注:id:为Qemu Monitor中info pci输出信息时的标识, addr:为该设备的在VM中的PCI slot编号.
qemu-kvm -device pci-assign,host=02:05.0,id=myEth0,addr=0x6
(4) 解除绑定物理网卡的绑定
echo -n "8086 100f" > /sys/bus/pci/drivers/e1000/new_id
echo '0000:02:05.0' > /sys/bus/pci/devices/pci-stub/0000\:02\:05.0/driver/unbind
echo '0000:02:05.0' > /sys/bus/pci/drivers/e1000/bind
#========================================================#
#分配物理磁盘
ls -l /dev/disk/by-path/pci-0000\:16\:00.0-sas-0x.....
lspci -Dn -s 16:00.0
echo -n "VendorID DericeID" > /sys/bus/pci/drivers/pci-stub/new_id
echo "0000:16:00.0" > /sys/bus/pci/devices/0000:16:00.0/driver/unbind
echo "0000:16:00.0" > /sys/bus/pci/drivers/pci-stub/bind
qemu-kvm -device pci-assign,host=00:16.0,addr=0x6 ...
#将宿主机的整个USB控制器分配给VM
# 通过U盘来确定将宿主机的那个USB控制器设备分配给VM
ls -l /dev/disk/by-path/pci-0000:00:ld.0-usb-0\:1.2\:1.0-scsi...
# 隔离USB控制的方法与物理磁盘一样.
#分配
qemu-kvm -device pci-assign,host=00:ld.0,addr=0x5 ...
#分配单独USB设备给VM
# 首先也是先隔离该USB设备.
#分配给VM
lsusb
Bus 001 Device 002 : ID 0781:5567 SanDisk Corp. Cruzer Blade
qemu-kvm -usbdevice host:0781:5567 ...
或
qemu-kvm -usbdevice host:001.002 ....
SR-IOV虚拟化前端后端思想的硬件实现
SR-IOV(Single Root I/O Virtualization and Sharing)概况:
VT-d使VM可直接独占使用物理硬件,VM性能提升了,但成本也升高了; SR-IOV是在这种
机会之下催生的产物,它是PCI-SIG组织发布的规范,它实现了将支持SR-IOV技术的物理硬件
划分为管理器(PF:Physical Function)和虚拟功能(VF:Virtual Function)两部分, 管理器将物理
硬件中的数据传送和处理功能虚拟成多份,就类似与CPU按时间片被虚拟化为多个vCPU. 然后,
将这种虚拟功能输出给VM,实现PCI物理设备的复用。
安照前端后端来说, VM中使用的虚拟功能就是前端驱动,物理设备就是后端驱动.
支持SR-IOV技术的PCI硬件多是网卡,如:Intel 82576(igb驱动)、X540(ixgbe驱动)等.
支持SR-IOV的虚拟化软件: Qemu/kvm(2009年发布)、Xen、VMware、Hyper-V等.
SR-IOV的基本原理:
SR-IOV为VM使用虚拟功能提供了独立的内存空间、中断、DMA(直接内存访问)流,无需
Hypervisor的软件交换机的介入传输.
一个有SR-IOV功能的设备 在其PCI配置空间中可被配置为多种功能包括一个PF和多个VF,
每个VF都有自己独立的配置空间和完整的BAR(Base Address Register:基址寄存器),Hypervisor
将VF的配置空间映射给VM,使VM可以看到设备的配置空间,来实现将一个或多个VF分配给一个VM.
另外Intel VT-x和VT-d等硬件辅助虚拟化技术提供的内存转换技术,使DMA可直接将数据发送到VM
的内存空间,也允许VM直接将数据通过DMA传送到宿主机的内存空间.
一个VF同一时间仅能分配给一个VM,在VM中看到的VF就是一个普通的完整的设备。
SR-IOV的优劣:
优:实现了一个物理设备被多VM共享复用,降本提性.
劣:无法动态迁移,支持SR-IOV技术的设备有限,设备依赖性高.
#查看本机是否有支持SR-IOV的设备
lspci |grep 'SR-IOV'
#Intel支持SR-IOV设备的驱动:igb, ixgbe的示例
# 查看igb 或 ixgbe启用VF功能的参数
modinfo igb |grep 'parm'
modprobe -r igb #若当前没有启动VF功能可先卸载.
modprobe igb max_vfs=7 #igb最大支持7个VF.
lspci |grep 'Eth' #启动后,将可看到物理网卡被虚拟为7个VF网卡.
# 假如上面加载网卡的PCI总线地址为: '0000:0d:00.0'
#查看该网卡为VF设备分配的PCI总线地址.假设为"0000:0e:10.0"
ls -l /sys/bus/pci/devices/0000\:0d\:00.0/virtfn*
ls -l /sys/bus/pci/devices/0000\:0e\:10.0/phsfn #查看PF的PCI总线地址.
# 让系统开机后,自动加载igb驱动,并启用VF功能.
cat /etc/modprobe.d/igb.conf
option igb max_vfs=7
# 将VF绑定给VM的方法
(1) 先隔离其中的一个VF,在使用 qemu-kvm -device pci-assign,host=0e:10.0 .. 即可.
KVM工具的使用
qemu-kvm是最核心的工具.它是libvirt工具栈底层调用的工具。
yum install qemu-kvm
ln -sv /usr/libexec/qemu-kvm /bin
qemu-kvm 命令行选项:
标准选项:
-M :指定模拟的主机架构【qemu-kvm-1.5.3-160.el7_6.2, 没有找到此项】
-cpu :指定CPU的架构,如: Intel, AMD
-smp :指定CPU颗数、核心数、线程数、插槽数
n,[maxcpus=cups] :指定cpu颗数,最大多少颗
cores=n :指定核心数
threads=n: 指定线程数
sockets=n: 指定有几个CPU插座
-name: 指定VM的名称
-m : 指定内存的大小
-boot:指定启动选项
order: 指定启动顺序:a(软盘), c(磁盘), d(CDROM), n(网络)
once: 仅设置时使用一次,a, c, d, n
menu=[on |off] :可在启动VM时,提示按F12显示启动菜单.

-drive option[,option[,option[,....]]]
file=/path/to/somefile :磁盘映像文件路径
if=interface :指定磁盘设备所连接的接口类型,即控制器类型,如: IDE/SCSI/SD/MTD/Floppy/Pflsh/virtio等
index=index: 设定同一种控制器类型中不同设备的索引号、即标识号,如:sda,sda1,sda2....;
media=[disk | cdrom] : 定义介质类型为硬盘或光盘.
snapshot=[on|off] :指定当前磁盘设备是否支持快照功能.
#注: 启用snapshot后,Qemu不会将磁盘数据的更改写回镜像文件中,而是写入临时文件,
# 当按Ctrl+ALT+1进入Qemu的monitor模式后,使用commit命令时,可强制将更改写回后端磁盘镜像。
cache=[none|writeback|unsafe|writethrough] :定义如何使用物理机缓存来访问块数据.
unsafe:不安全的缓存(性能最好) > writeback: 回写缓存(性能较好) > writethrough:通写缓存(安全性高,性能次之)
writeback:仅将数据写入磁盘缓存就返回完成,缓存中的数据在即将被换出时,才写入磁盘.
writethrough: 将数据写入磁盘缓存的同时也写入磁盘,都完成后返回完成。
none:读写都不使用缓存,而writeback 和 writethrough默认都优先使用缓存。
format=FMT :指定映像文件的格式.
aio=[threads | native] :设置使用异步IO的方式.
# threads : 默认值, 即让一个线程池来处理异步IO.
# native :仅在cache=none时可用,它使用Linux原生的AIO来处理异步IO.
readonly=[ on | off] :设定驱动器是否可读。
serial=SERIAL_# #指定分配给设备的序列号。
addr=ADDR #分配给驱动器控制器的PCI地址, 仅适用于virtio接口。
id=ID_Name #在Qemu Monitor模式下查看info blk时,显示的磁盘id标识。
-iscsi [user=USER][,password=PASSWD]\
[,header-digest=CRC32C|CR32C-NONE|NONE-CRC32C|NONE]\
[,initiator-name=iqn]
示例:
qemu-kvm -iscsi initiator-name=iqn.2000-11.com.example:my-initiator \
-cdrom iscsi://192.168.100.1/iqn.2012-11.com.example/2 \
-drive file=iscsi://192.168.100.1/iqn.2012-11.com.example/1
-mtdblock /path/to/file #将指定文件做为VM的Flash存储器(即:U盘)
-sd /path/to/file #将指定文件做为VM的SD卡(Secure Digital Card)
-pflash /path/to/file #并行Flash存储器
启动VM:
qemu-kvm -m 128 -name cirros-001 -smp 2 -hda /image/kvm/cirros-*.img
补充:
关闭cirros-0.3.4的检查更新的过程,但还需要注意Cirros还有三次等待DHCP分配地址的延时,
若有DHCP这很快就过去了:
# cat /etc/cirros-init/ds-ec2
MAX_TRIES=0
SLEEP_TIME=0
BURL="http://169.254.169.254/2009-04-04"
使用-drive指定磁盘映像文件:
qemu-kvm -m 128 -name cirros-002 -smp 2 \
-drive file=/images/kvm/cirros-0.3.4-i386-disk.img,if=virtio,\
media=disk,cache=writeback,format=qcow2
通过cdrom启动winxp的安装:
qemu-kvm -name WinXP-001 -smp 4,sockets=1,cores=2,threads=2 -m 512 \
-drive file=/images/kvm/winxp.img,if=ide,media=disk,cache=writeback,format=qcow2 \
-drive file=/root/winxp_ghost.iso,media=cdrom
设置使用VNC显示VM的图形界面
qemu-kvm -m 128 -name cirros-004 -smp 2 \
-drive file=/images/kvm/cirros.img,if=virtio,media=disk,cache=writeback,format=qcow2 \
-vnc :3 \ #启动vnc,默认监听所有接口,端口: 5900 + 3
-monitor stdio #启动后直接在当前shell进入VM的监控控制台
-vnc :3,passwd -monitor stdio #VNC :3,passwd 是指定VNC连接需要密码.
# 这样就会启动一个qemu的monitor界面,在monitor模式里可以设置VNC的密码。
(qemu) change vnc passwd #这在Qemu的monitor模式中指定为VNC修改密码的方式.
查看VM启动情况:
ps aux |grep qemu-kvm
qeum-kvm的显示选项:
-usbdevice tablet #此选项用于VNC连接后,鼠标轨迹与实际轨迹保持同步.
#默认Qemu使用SDL来显示VGA输出,此选项可禁用图形接口,此时,qemu将为其仿真串口设备将被重定向到控制台.
-nographic:
-curses: 禁止图形接口,并使用curses/ncurses作为字符交互终端接口;
-alt-grab: 使用Ctrl+Alt+shift组合键释 放鼠标;
-ctrl-grab: 使用右Ctrl键释放鼠标;
-sdl: 启用SDL;
注: SDL(Simple DirectMedia Layer:简单直接介质层) :它采用C语言开发,跨平台且开源的多媒体程序库文件,用于简单图形
图像声音等多媒体信息输出呈现的库, 它被广泛应用与各种操作系统,如:游戏开发/多媒体播放器/且被多种模拟器用来打开窗口等
-spice option[,option[,...]]: 启用spice远程桌面协议; 其有许多子选项.
-vga type: 指定要仿真的VGA接口类型,常见类型有:
cirrus: Cirrus Logic GD5446显示卡;
std: 带有Bochs VBI扩展的标准VGA显卡
vmware: VMWare SVGA-II兼容的显示适配器
qxl: QXL虚拟化显示卡;与VGA兼容,在Guest中安装QXL驱动后能以很好的方式工作,当使用spice协议时推荐使用.
none: 禁用VGA卡
-vnc display[,option[,....]] : 默认情况下,qemu使用SDL显示VGA输出,使用-vnc选项,可让qemu监听在VNC上,并将VGA输出
重定向至VNC会话; 此选项必须使用-k选项指定键盘布局类型.
注:
VNC(Virtual Network Computing:远程网络计算),它使用RFB(Remote FrameBuffer:远程帧缓存)协议远程控制另外的主机。
display:
(1) host:N #1.1.1.1:2, 监听于1.1.1.1主机的5900+2的端口上.
(2) unix:/path/to/socket_file
(3)none
opetions:[新版本中已经废弃]
(1) password: 连接VNC的密码
(2) reverse: "反向"连接至某个处于监听状态的vncview上。
-monitor stdio :表示在标准输入输出上显示monitor界面.
-nographic 选项执行以下快捷键:
ctrl+a 松开快速再按 c :在console和mointor间切换.
ctrl+a 松开快速再按 h :显示帮助信息.
网络属性相关选项:
-net nic[,vlan=n][,macaddr=MAC][,model=Type][,name=Name][,addr=Addr][,vectors=V]:
创建一个新的网卡设备,并连接到VLAN n中,PC架构上默认NIC为e1000;
qemu可模拟多种类型的网卡,如:virtio, i82551, i82557b, i82559er,
ne2k_isa, pcnet, rtl8139,e1000,smc91c111,lance及mcf_fec等;
不过不同平台架构上,其支持的类型可能只包含前述列表中的一部分,
可使用"qemu-kvm -net nic,model=?" 来获取当前平台支持的类型;
-net tap[,vlan=n][,name=Name][,fd=h][,ifname=Name][,script=Sfile][,downscript=Dfile] :
通过物理机的TAP网络(虚拟二层网络设备)接口连接至VLAN n中,使用script=Sfile指定脚本
(默认为/etc/qemu-ifup)来配置当前网络接口,并使用downscript=Dfile指定脚本
(默认为/etc/qemu-ifdown)来撤销接口配置; 使用script=no和downscript=no可分别用来禁止直行脚本.
name:指定qemu monitor模式中显示虚拟二层网络设备的接口名
ifname:指定在宿主机上显示虚拟二层网络设备的接口名
注:
通常nic 和 tap需要联合使用,nic用来创建VM的网卡,并为网卡配置IP,MAC,网卡芯片等;
而TAP用来指定VM如何连入虚拟网络中,tap提供网络的前半段和后半段.前半段在VM中,
与网卡关联,后半段在宿主机上,并需要使用scirpt来指定一个脚本完成后半段接口
桥接到那个网桥上.以便完成复杂的网络模型创建。
qemu-kvm会调用script指定的脚本,并将后半段网卡作为参数传给该脚本,以便完成后半段加入指定网桥.
-net user[,option][,option][,...]:
在用户模式配置网络栈,其不依赖于管理权限,这得益于qemu-kvm实现了一个自有的tcp/ip协议栈
它可以不使用Kernel所提供的tcp/ip协议栈;它功能与tap类似,也是指定VM如何连入虚拟网络,
所不同的是tap需要管理员权限. 有效选项有:
vlan=n : 连接至VLAN n, 默认n=0;
name=Name: 指定接口显示名称, 常用于监控模式中;
net=addr[/mask]: 设定GuestOS可见的IP网络, 掩码可选, 默认为:10.0.2.0/8
host=addr : 指定GuestOS中的本机IP,默认为net指定网段中的第二个IP,即:x.x.x.2
dhcpstart=addr: 指定DHCP服务的地址池中16个地址的起始IP,默认为x.x.x.16~x.x.x.31.
dns=addr : 指定GuestOS的DNS地址.默认为GuestOS所在网段中的第三个IP,即:x.x.x.3
tftp=dir: 激活内置的tftp服务器,并使用指定目录作为tftp服务器的默认根目录。
bootfile=file: BOOTP文件名, 用于PXE引导GuestOS. 如:
qemu-kvm -hda /kvm/linux.img -boot n -net user,tftp=/tftpserver/pub,bootfile=/pxelinux.0
-soundhw #开启声卡硬件支持
#如: qemu-kvm -soundhw ?
Qemu Monitor中实现物理设备的热插拔
(1) CPU
#对CPU和内存的热插拔技术,在RHEL6.3中已经得到支持.
qemu-kvm -smp 2,maxvcpus=8 ... #启动时使用两颗vCPU,最大可动态增加8个.
#按Ctrl+Alt+2切换到Qemu Monitor:
cpu_set 3 online #动态添加
cpu_set 3 offline #动态移除
#若动态添加后, vCPU在VM中没有上线工作,可手动激活下:
echo 1 > /sys/devices/system/cpu/cpu3/online
(2) 内存
#Qemu-kvm的内存的热插拔还没有提供支持。
#目前仅可使用virtio-balloon技术来增大或减少内存。
qemu-kvm -balloon virtio ...
#手动在QEMU-monitor中查看balloon使用情况
#按Ctrl+Alt+2切换到Qemu Monitor:
info balloon
balloon MemSize #动态调整KVM虚拟机内存的大小
(3) SATA硬盘
#首先,还是需要先在宿主机中将物理设备隔离,在再Qemu Monitor中添加.
#按Ctrl+Alt+2切换到Qemu Monitor:
device_add pci-assign,host=00:1f.2,id=mysata,addr=0x06
info pci
device_del mystat
(4) USB
#假如在宿主机中查看lsusb为:
lsusb
Bus 001 Device 002 : ID 0781:5567 SanDisk Corp. Cruzer Blade
#按Ctrl+Alt+2切换到Qemu Monitor:
方法1: usb_add host:001.002 或 usb_add host:0781:5567
info usb
Device 0.2, Port 1, ...
usb_del 0.2
方法2: device_add pci-assign,host=00:1d.0,id=myusb
device_del myusb
(5) 网卡
#先在宿主机中隔离一个物理网卡 或 VF网卡.
#按Ctrl+Alt+2切换到Qemu Monitor:
device_add pci-assign,host=06:10.1,id=myNIC
device_del myNIC
VM Mirgration(迁移):
static migration
live migration
整体迁移时间
服务器停机时间
对服务的性能的影响
#迁移注意事项:
(1) 使用Samba、NFS等共享方式存放VM的磁盘映像文件,并在源和目的宿主机上挂载到相同目录;
(2) 源和目的宿主机的软件配置要尽量相同,如: 源和目的都有相同的网桥等。
(3) VM迁移到目的宿主机后,要保证VM的名称在目的宿主机上唯一。
(4) 64位---迁移---64位; 32位----迁移----32位或64位
(5) Intel平台---迁移---Intel平台,AMD平台---迁移---AMD平台.
不建议:Intel平台---迁移---AMD平台,虽然有时不会出错.
(6) 动态迁移的源和目的宿主机对NX位(Never eXecute)的设置是相同的.源和目的只能是同关闭或同打开.
cat /proc/cpuinfo |grep nx ,查看CPU是否支持NX.
补充:
NX bit(Never eXecute):
NX位是CPU特性的一种,它可让OS将指定内存区域标记为不可执行,这样CPU将不会执行该区域的
任何代码。NX技术理论上可防止“缓冲区溢出(buffer overflow)”类型的黑客攻击。
NX技术在不同的CPU上的称呼:
Intel CPU:XD bit(eXecute Disable)
AMD CPU: EVP(Enhanced Virus Protection)
ARM CPU:XN(eXecute Never)
#Qemu-kvm来迁移VM,必须在Qemu Monitor中操作.
#在源VM上, 按Ctrl+Alt+2切换到Qemu Monitor:
# 迁移命令格式:
# migrate [-d] [-i] [-b] 目的主机的URI
# -d : 执行migrate命令后,不占用前台,即Qemu Monitor界面下依然可输入命令.
# -i : 同时传输增量的磁盘映像文件到目的宿主机
# -b : 同时传输整个VM的磁盘映像文件到目的宿主机.
#
# 与迁移相关的命令:
# migrate_cancel :取消迁移.
# migrate_set_speed ?[B|K|G|T] #指定迁移占用多大的网络带宽,越大速度越快.
# migrate_set_downtime 1 #当KVM迁移到最后时,估算剩余完成时间 <= 1秒,则关闭源VM.
#
#(1) 源和目的宿主机都挂载了存放迁移VM磁盘映像的共享存储.
源宿主机:
mount -t nfs 1.1.1.1:/kvm/image /kvm/images
qemu-kvm -name RHEL6-01 -m 512 -smp 2 -hda /kvm/images/rhel6.4.img -net nic
目的宿主机:
mount -t nfs 1.1.1.1:/kvm/image /kvm/images
#注:tcp:本地监听地址:监听端口, 0:监听所有接口.
qemu-kvm -name RHEL6-01 -m 512 -smp 2 -hda /kvm/images/rhel6.4.img -net nic -incoming tcp:0:6666
#(2) 在源宿主机上操作迁移:
# 在源VM上, 按Ctrl+Alt+2切换到Qemu Monitor:
migrate -d tcp:DestiantionIP:6666
#(1) 同时迁移源VM的增量磁盘映像文件.
源宿主机:
# 注意: 通过后端文件创建的增量img文件,指定的大小似乎不起作用.增量img文件的容量是
# 后端img文件创建时的大小。
qemu-img create -f qcow2 -o backing_file=/kvm/image/rhel6.4.img,size=20G /tmp/rhel6u4.img
qemu-kvm -name RHEL6-01 -m 512 -smp 2 -hda /tmp/rhel6u4.img -net nic
目的宿主机:
qemu-img create -f qcow2 -o backing_file=/kvm/image/rhel6.4.img,size=20G /tmp/rhel6u4.img
qemu-kvm -name RHEL6-01 -m 512 -smp 2 -hda /tmp/rhel6u4.img -net nic -incoming tcp:0:6666
#(2) 在源宿主机上,按Ctrl+Alt+2切换到Qemu Monitor:
migrate -i tcp:DestinationIP:6666 #仅迁移增量的rhel6u4.img磁盘映像文件.
migrate -b tcp:DestIP:6666 #迁移整个rhel6.4.img磁盘.
附件1:
SMP(Symmetric Multi-Processor: 对称多处理器):
在SMP系统中,多个进程可真正实现并行执行,且单个进程下的多个线程也可得到并行执行,
这极大地提高了计算机系统并行处理能力和整体性能。
SMP在硬件方面,早期的计算机系统多采用在一块主板上集成多个物理CPU插槽来实现SMP系统;
后来随着多核、超线程(Hyper-Threading)技术的出现,SMP逐渐采用多个物理CPU、多核或超线程等
技术中的一个或多个来实现。
SMP在操作系统(OS)方面,目前多数现代OS都已提供了对SMP系统的支持,如:主流的Linux(2.6及
以上Kernel对SMP支持更完善)、微软的WinNT、Mac OS、BSD、HP-UX、IBM的AIX等。
在Linux中查询是否支持超线程的方式:
#若物理CPU的核心数 大于 逻辑CPU的个数,则说明超线程是支持并启用的。
# cat /proc/cpuinfo |grep 'core id' #物理CPU的核心个数.
core id : 0 #这表明CPU共4个核心,编号为0-3
core id : 1
core id : 2
core id : 3
# cat /proc/cpuinfo |grep 'siblings' #显示每个物理CPU中逻辑CPU(可能是core、thread或两者)的个数
siblings : 4
siblings : 4
siblings : 4
siblings : 4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号