TC学习总结
带宽管理:
TC中规定描述带宽:
mbps = 1024 kbps = 1024 * 1024 bps => byte/s
mbit = 1024 kbit => kilo bit/s
mb = 1024 kb = 1024 * 1024 b =>byte
mbit = 1024kbit => kilo bit.
默认: 数字使用bps和 b方式存储.
无类队列规则: 它能够接受数据和重新编排、延时或丢弃数据包,默认使用pfifo_fast队列规则.
pfifo_fast:
特点: 对任何数据包都使用FIFO(先进先出)队列,来存放入队。但它有3个所谓的"频道",对
每一个频道都使用FIFO规则,内核会优先将TCP的TOS标志位(“最小延迟”)置位的数据包
放入0频道,其它的放入1和2频道中,当然这是默认行为. 三个频道按照0,1,2的顺序,依次
等待处理,即0频道有数据包等待发送,1频道的包就不会发送,若1频道有包等待发送,则
2频道的包将不会被发送。
txqueuelen
#关于网卡设备的缓冲队列长度,可通过ip 或 ifconfig来修改.
ifconfig eth0 txqueuelen 10
priomap:
内核对会根据数据包的优先权将其对应到不同的频道.
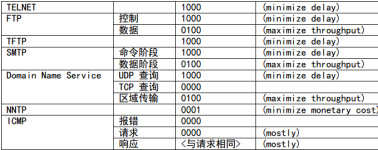
TCP报文中TOS字段如下:

TOS值的含义 和 其对应的频道:

对于以下服务推荐TOS设置:
TBF(令牌桶过滤器):
TBF是一个简单队列,它只允许数据包按照事先设定的速率通过,支持设置峰值流量,它很精确,
且对网络和处理器的影响较小,因此比较常用.
TBF的原理:
它实现了一个缓冲器(即令牌桶),在这个桶里面会不断以特定速率往里面填充“令牌",token rate
(令牌速率)是令牌桶比较重要的参数,它是桶的大小,也就是能存储令牌的数量.
如:
rate 200kbps: 它指 令牌桶最多存储200kbit个令牌,一个令牌1bit, 因为要通过1bit的数据,
就需要一个令牌,因此发送速率若为200k bit每秒,则桶里面始终会有令牌,若超过
则没有可用令牌,就会产生丢包,这也就是TBF对流量整型的过程; 若低于此速率
则令牌桶可能会被装满,多余的令牌将丢失。
另外它也隐含说明了,缓存队列的长度,即它最多能缓存多少bit的数据.
理解: 因为令牌的产生是按照系统的时间解析度来产生的,系统时间解析度指
多久为1个时间单位 或 多少HZ(赫兹)一个时间单位, 假如10ms为一个时间单位,
那就是每隔10毫秒系统会生产一个令牌放到令牌桶中。
假如在初始时 桶中当前只有1个令牌,按照200kbit/s的速率, 第一个bit进入,桶中
有令牌取走,该bit通过,接下来的bit,就要等10ms(一个时间单位)后,才能得到下一个
令牌,而第二个bit在等待时,第三个bit已经到了,依次类推,缓存队列最多能存200kbit
数据,若超过了,后续的数据就丢失了,若不超过设定速率,这个队列始终不会被填满.
TBF可用参数:
limit 和 latency:
limit: 允许最多有多少数据(字节数)在队列中等待可用令牌。
latency: 设定一个数据包在缓存队列中等待发送的最长等待时间,若设置它,就相当于
决定了桶的大小、速率和峰值速率,因为数据包大小范围:64~MTU kbit 。
burst/buffer/maxburst:
设置最多一次允许多少个令牌能被立即使用,即峰值速率。
buffer: 设置令牌桶的大小,通常是管理的带宽越大,buffer就需要的越大.
mpu: Minimum Packet Unit:最小分组单位, 它决定了令牌的最低消耗。
rate:设置速率(缺省不限速)
peakrate:设置峰值速率,即: 一个包通过后,下一个包要等多久才允许通过.
如: Unix的时间解析度是10ms(2004年左右的参考值), 若平均包长为10kbit,
则峰值速率最大为1Mbps,即 1秒=1000ms, 按10ms的解析度, 即100个
时间单位,每个时间单位发送10kbit,就是100 X 10kbit = 1Mbps.
mtu/minburst:
mtu: 峰值速率 = mtu X 时间解析度.
例:
tc qdisc add dev ppp0 root tbf rate 220kbit latency 50ms burst 1540
SFQ(Stochastic Fairness Queueing:随机公平队列):
SFQ的精确度不如上面的算法,但它确能以很小的计算量,实现较高的公平数据发送。
SFQ实现的公平是随机的, 因为它是针对一个TCP会话或UDP流,将它们通过散列的
方式平均分配到有限的几个FIFO队列中,所以它们实际上是共享发包机会的,但为了
让尽量公平,SFQ会每隔指定时间改变一次散列算法,以便让这种机制能让所有包都
在几秒内发送出去。
注:
SFQ仅在网卡确实已经被挤满时,才会生效, 来创建队列并散列TCP或UDP数据包到不同
队列中,进行公平调度。
SFQ可用参数:
perturb: 每隔多久改变一次散列算法,10秒是比较合适的值.
quantum: 设置一个流至少传输多少字节后,切换到下一个队列中发送其中的数据包。
建议使用默认值,即最大包长度(MTU). 此值不能设置数值小于MTU!!
例:
# tc qdisc add dev ppp0 root sfq perturb 10
# tc -s -d qdisc ls
qdisc sfq 800c: dev ppp0 quantum 1514b limit 128p flows 128/1024 perturb 10sec
Sent 4812 bytes 62 pkts (dropped 0, overlimits 0)
注:
“ 800c:”这个号码是系统自动分配的句柄号
“ limit”: 是这个队列中可以有 128 个数据包排队等待。
“flows 128/1024”: 一共可以有 1024 个散列目标可以用于速率审计,
而其中 128 个可以同时激活。
perturb 10: 每隔 10 秒散列算法更换一次。
以上队列何时使用最合适:
1. 仅想限速,使用令牌桶过滤器(TBF):调整桶的配置后可用于控制很高的带宽。
2. 若链路已被塞满, 使用SFQ,可避免某一会话独占出口带宽.
3. 若你仅想看看网卡是否有较高的负载,可使用pfifo,而非pfifo_fast,因为pfifo内部
频道可进行backlog统计。
4.最后记住: 技术不能解决一切问题,社交还是需要的!
TC的实现流量控制的大致框架流程如下:

注:
图中Ingress处就根据策略避免超过规定的数据包进入内核,这样可以
减少CPU处理时间。 若数据包顺利进入内核,若它是进入本地进程的,
就转给IP协议栈, 否则就交给egress分类器. 经过审查后,最终被放入
若干队列规定中进行排队,此过程叫入队。如不进行任何配置,默认
只有一个egress队列规定,即pfifo_fast. 当数据包入队后,等待内核处理
并通过某网卡发出,这过程叫出队。
队列规定: 即管理设备输入(ingress)或输出(egress)的算法.根据否能包含子类,
它被分为无类和分类两种:
无类队列规定: 一个内部不包含可配置子类的队列规定.
分类队列规定: 一个分类的队列规定内可包含更多class(类),其中每个子类又
进一步地包含一个分类 或 无类的队列规定。
整形(策略):在数据包被发送前,跟据设定进行适当延迟,避免超过设定的最大速率.
通常采用丢包来实现, 因为TCP的滑动窗口机制可以根据丢包来自动调整
其发送数据包的速率,而UDP只能通过丢包来限制其速率。
Work-Conserving: 对于work-conserving队列规定,若得到一个数据包,就立刻
发送。即:只要网卡(egress队列规定)允许,它就不会延迟数据包发送.
non-Work-Conserving: 有些队列,如TBF(令牌桶过滤器),可能需要暂时停止发包,
以实现限制带宽,也就是说它们有时即时有数据包需要处理,也可能拒绝发送.
过滤器: 对流量进行分类,如:网页流量,视频流量,游戏流量等进行过滤条件匹配,
匹配出来后,交给分类器处理。
分类器: 分类器可将不同的流量分发给 分类队列规定 中不同的子类来处理。
TC的队列规定家族:
root, 句柄(handle), 兄弟节点 和 父节点
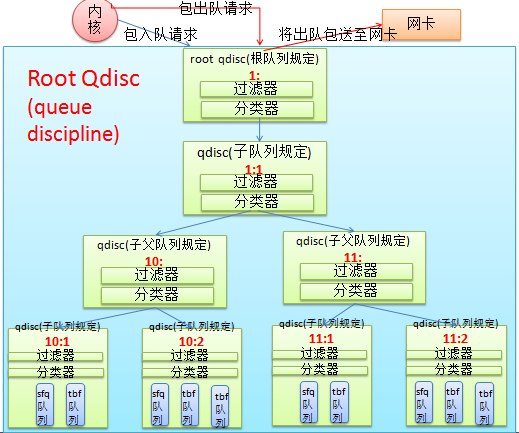
注:
句柄(handle): 节点引用标识,它的格式: MajorNumber:MinorNumber,其中父节点的次号码始终为0.
root节点的handle为1:0(可简写为:"1:"), 它有一个子节点 1:1
1:1这个子队列规定有两个父级的子队列规定分别是 10: 和 11:
内核 仅和root qdisc 进行通信, 与物理网卡的通信也是有root qdisc来完成的,它们对应整体
的队列规定家族是透明的,所有对外的接口只有root qdisc一个。
在队列规定内部(我的理解如下):
当内核发来入队请求时, root qdisc 会先调用过滤器来匹配数据包,若没有匹配就直接由分类器
将其下发至子队列规定,它也是先过滤器匹配,然后分类器分发,假如过滤器发现数据包为游戏流量
就将其送入11: 这个父级的子队列规定,接着11: 过滤器继续判断,发现是boos的游戏流量,就将其
分发到11:1,在继续到11:1的过滤器,然后是分类器,完后入队等待发送。
当内核发来出队请求时,root qdisc会向1:1发查询,1:1会分别向10: 和 11:发查询,接着10:会向
其下的10:1 和 10:2发查询,直到11:1发现了要出队的数据包,它将数据包出队发给root qdisc,接着
在内核的指引下,root qdisc将数据包发给网卡。【注: 出队要遍历全队列,所以队列不要太多哦~】
队列规定:
PRIO:它不对流量进行整形,它仅根据配置的过滤器将流量细分到不同的类中,若需要对流量进行整形处理,
可以在这些子类中包含相应的队列,由它们来做整形。默认PRIO队列规定包含3个类,每个类下面包含
一个FIFO队列。
PRIO可以参数:
bands : 指定创建的频道个数,一个频道就是一个类, 默认是3个频道.
priomap: 为PRIO队列规定绑定一个过滤器,默认:根据TOS字段来匹配分类规则与pfifo_fast根据TOS
字段分类一样。
例:
创建如下树:

命令:
#这个命令创建了三个类,1:1, 1:2, 1:3,因为默认bands为3.
tc qdisc add dev eth0 root handle 1: prio
#为第一个子类1:1创建了一个父级子类10:, 并制定内部队列为SFQ(随机公平队列)
tc qdisc add dev eth0 parent 1:1 handle 10: sfq
tc qdisc add dev eth0 parent 1:2 handle 20: tbf rate 20kbit buffer 1600 limit 3000
tc qdisc add dev eth0 parent 1:3 handle 30: sfq
tc -s qdisc ls dev eth0
qdisc sfq 30: quantum 1514b
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
qdisc tbf 20: rate 20Kbit burst 1599b lat 667.6ms
Sent 0 bytes 0 pkts (dropped 0, overlimits 0)
qdisc sfq 10: quantum 1514b
Sent 132 bytes 2 pkts (dropped 0, overlimits 0)
qdisc prio 1: bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 174 bytes 3 pkts (dropped 0, overlimits 0)
测试:
1. 尝试使用scp 复制文件到其它主机. 然后查看 队列统计信息。
2. 书中说 10: 它的优先权最高,交互流量会优先选它, 30:的优先权最低,大量数据流量会优先走它.
需要测试参考 TOS 标志位含义。
CBQ(Class Based Queueing:基于类的队列):
CBQ是根据链路平均空闲时间,来判断链路负载是否需要进行管制(即:整形),它有三种情况:
avgidle = 0 : 则说明当前连路负载最佳,数据包能够精确按照预计时间间隔到达.
avgidle < 0 : 则说明当前链路过载了, 若负值逐渐增大,则说明负载超限(Overlimit),
CBQ将启动整形,开始丢包以禁止发包,禁止发包时长为 超限前计算
出来的数据包平均发送间隔。
avgidle > 0 : 则说明当前链路太空闲了, 若空闲超过几个小时,若此时有流量过来,CBQ
将允许无限制的流量转发, 但这通常不是我期望的,因此需要设置maxidle,
来限制avgidle的值不能太大.
avgidle = 两个数据包平均发送间隔时长 减去 EWMA
EWMA:Exponential Weighted Moving Average:指数加权移动均值,此算法是根据最近
处理的数据包的权值比以前的数据包按指数增加。 【算法具体含义不清楚】
简单理解: 最近数据包权值 = 前一个数据包权值^n+1
另注: UNIX 的平均负载也是这样算出来的
CBQ整形的参数:
avpkt: 平均数据包大小,单位:字节. 它是计算maxidle的参数, maxidle从maxburst得出.
bandwidth: 物理网卡的带宽, 用于计算链路空闲时间.
cell: 它用于设置时间解析度(即:时间精度), 通常设为8,它必须是2的整数次幂。
maxburst: 最大突发数据包的个数(原文: 在avgidle=0前,可允许有maxburst个数据包突发传输出去。)
此值决定了maxidle计算使用的数据包个数【不是很理解】.
minburst: 它是设置超限后CBQ进入禁止发包延时状态后,根据之前计算的空闲时间延迟值,
结合系统调度处理程序离开CPU到下次调度它到CPU上执行的间隔,来适当设置禁止发包的
时长,当处理程序调度到CPU上执行时,一次突发传输 minburst 个数据包.
注: 大尺度时间上, minburst值越大,整形越精确;
从毫秒级时间尺度上,就会有更多突发传输.
禁止发包的等待时间叫: offtime
minidle: 当avgidle < 0,发送越限后,CBQ进入禁止发包的等待状态,但为了避免解禁后,再次
出现突发传输,导致avgidle超限更多,负值越大,导致更长的禁止状态,所以需要设置
一个 minidle 来限制负值无限增大.
注: minidle 10 : 表示avgidle被限制其越限最大值为 -10us (负10微秒)
mpu: 数据包的最小大小.用于CBQ精确计算链路空闲时间
rate: 预期想限制的最大传输速率.
CBQ在数据包分类方面的参数:
注: 这些参数是控制那些队列要参与计算,如:已知该队列中无数据包,就不让其参与调度计算,
及那些队列要被惩罚性的降低优先级等。
CBQ使用prio参数来设定每个类的优先级,值越小越优先; 数据包出队是按照WRR(Weighted
Round Robin:加权轮询) 对root qdisc下每个子类进行轮询,优先级高的子类先被调度,从
该子类中的队列中取数据,接着是次高的,直到全部子类遍历一遍,当然对于没有数据的
子类将自动跳过. 每次从子类中取多少数据是根据 allot * weight 来决定的。
WRR的相关参数:
prio: 设置类的优先级,值越小越优先.
allot: 设置一次发送多少数据量.
weight: 允许多发多少数据的权重数(注: 建议weight=rate/10);假如有如下图:
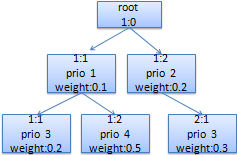
注:
对于这个图, 1:0这个根类下有两个子类1:1和1:2, 1:1的prio值更小,因此它
更优先被WRR调度;
一级子类1:1它的发送数据的权重=0.2+0.5
一级子类1:2它的发送数据的权重=0.3
而对于1:1的子类来说:
二级1:1发送数据的权重=0.2
二级1:2发送数据的权重=0.5
而2:1与此一样.
CBQ兄弟类之间是否可以互相借用带宽:
isolated / sharing:
isolated: 不会和兄弟类出借暂时多余的带宽。
sharing: 允许借用暂时多余的带宽.
bounded / borrow:
bounded: 不允许借
borrow: 允许借
例:
这个配置把 WEB 服务器的流量控制为 5Mbps、 SMTP 流量控制在 3Mbps , 而且
二者一共不得超过 6Mbps,互相之间允许借用带宽。我们的网卡是 100Mbps的。
# tc qdisc add dev eth0 root handle 1:0 cbq bandwidth 100Mbit avpkt 1000 cell 8
# tc class add dev eth0 parent 1:0 classid 1:1 cbq bandwidth 100Mbit \
rate 6Mbit weight 0.6Mbit prio 8 allot 1514 cell 8 maxburst 20 avpkt 1000 bounded
注:
子类1:1物理网卡的最大带宽为100Mbit,设置最大速率为6Mbit,允许发送数据量的权重为0.6Mbit.
一次发送数据量为1514(单位:不清楚),允许的最大突发20个数据包,平均包大小为1000字节,时间解析度为8,
不借出带宽给兄弟节点,本例子类1:1没有同级兄弟节点,因此设置或不设置一样.
# tc class add dev eth0 parent 1:1 classid 1:3 cbq bandwidth 100Mbit \
rate 5Mbit weight 0.5Mbit prio 5 allot 1514 cell 8 maxburst 20 avpkt 1000
# tc class add dev eth0 parent 1:1 classid 1:4 cbq bandwidth 100Mbit \
rate 3Mbit weight 0.3Mbit prio 5 allot 1514 cell 8 maxburst 20 avpkt 1000
注:
在子类1:1下有两个子类,它们是可以互相借用空闲带宽的,但他俩最大能使用的总带宽是6Mbit.
Web能占用的带宽 = 6 X (0.5/(0.5+0.3)) Mbps
SMTP能占用的带宽 = 6 X (0.3/(0.5+0.3)) Mbps
# tc qdisc add dev eth0 parent 1:3 handle 30: sfq
# tc qdisc add dev eth0 parent 1:4 handle 40: sfq
# tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip sport 80 0xffff flowid 1:3
# tc filter add dev eth0 parent 1:0 protocol ip prio 1 u32 match ip sport 25 0xffff flowid 1:4
注:
这是添加了两个过滤器,用于匹配Web和SMTP的流量,并将它们分别送入1:3和1:4中.
对于没有匹配到的流量,1:0 即root队列规定将直接处理,它采用FIFO队列,不限制直接转发.
注: 以上命令创建的结构如下图:
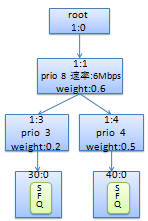
CBQ的过滤器选项:
split节点: 当你需要使用CBQ自带的过滤器 defmap时,定义defmap的类的父类就称为split节点.
defmap: 它是通过与TCP的TOS(服务类型标志位) 做或运算来匹配特定TOS置位的数据包,并将
这些数据包接入到匹配类中. 0:表示不匹配.
例:
# 1:1就是split节点
# tc qdisc add dev eth1 root handle 1: cbq bandwidth 10Mbit allot 1514 cell 8 avpkt 1000 mpu 64
# tc class add dev eth1 parent 1:0 classid 1:1 cbq bandwidth 10Mbit \
rate 10Mbit allot 1514 cell 8 weight 1Mbit prio 8 maxburst 20 avpkt 1000
# c0: 1100 0000, 它是匹配TOS的第7和6位,即交互和控制位 置位的数据包.
# tc class add dev eth1 parent 1:1 classid 1:2 cbq bandwidth 10Mbit \
rate 1Mbit allot 1514 cell 8 weight 100Kbit prio 3 maxburst 20 avpkt 1000 split 1:0 defmap c0
# 3f:0011 1111, 它是匹配TOS的1~5位,也就是将剩余的所有数据包都匹配到本子类中.
# tc class add dev eth1 parent 1:1 classid 1:3 cbq bandwidth 10Mbit \
rate 8Mbit allot 1514 cell 8 weight 800Kbit prio 7 maxburst 20 avpkt 1000 split 1:0 defmap 3f
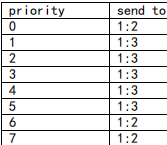
root节点1:0接收到的数据包将被分配到1:3 和 1:2子类中的情况为:
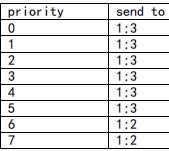
补充:
# tc class change dev eth1 classid 1:2 cbq defmap 01/01
# 这个change 可以给defmap提供一个mask(掩码),但是暂时不理解它是什么意思.
# 这是原作者提供的 经过掩码计算后, 优先权值的变化:
HTB(Hierarchical Token Bucket : 分层令牌桶)
有一个固定速率的链路,希望分割给多种不同的用途使用,为每种用途做出带宽承诺并实现定量的带宽借用,
这时你就需要使用HTB队列规则了,它配置相比于CBQ简单.
HTB参数解释:
rate: 设定期望的最大限制速率.
burst: 设置突发流量在现有基础上,可以增大多少.
ceil: 设置速率最高可达到多少. 此参数表明该子类可借用其兄弟类的空闲带宽。
# tc qdisc add dev eth0 root handle 1: htb default 30
注:
default 30: 表明若过滤器没有匹配到的流量都将被分配到root qdisc的1:30这个子类中.
# tc class add dev eth0 parent 1: classid 1:1 htb rate 6mbit burst 15k
# tc class add dev eth0 parent 1:1 classid 1:10 htb rate 5mbit burst 15k
注:
1:10这个子类,它的最大速率为5Mbps,它不可用借用其兄弟类的带宽.
但下面两个设置ceil ,表明它们可借用兄弟类空闲带宽,最大速率可达到6Mbps.
# tc class add dev eth0 parent 1:1 classid 1:20 htb rate 3mbit ceil 6mbit burst 15k
# tc class add dev eth0 parent 1:1 classid 1:30 htb rate 1kbit ceil 6mbit burst 15k
# tc qdisc add dev eth0 parent 1:10 handle 10: sfq perturb 10
# tc qdisc add dev eth0 parent 1:20 handle 20: sfq perturb 10
# tc qdisc add dev eth0 parent 1:30 handle 30: sfq perturb 10
注:
perturb: 设定SFQ(随机公平队列)每隔10秒更新一次随机散列算法,以便入队数据包有机会被排在前面,
最终达到它们都能在可接受的时间内被发送.
添加过滤器,直接把流量导向相应的类:
# U32="tc filter add dev eth0 protocol ip parent 1:0 prio 1 u32"
# $U32 match ip dport 80 0xffff flowid 1:10
# $U32 match ip sport 25 0xffff flowid 1:20
以上命令创建的TC结构图:
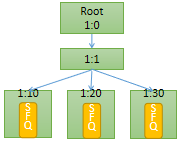
TC过滤器创建:
# tc filter add dev 网卡名 parent 父类句柄 protocol ip prio 优先级值 u32 \
[match [ip [[src |dst [IPAddr/CIDR Mask]] [sport |dport 端口号 Mask] | protocol 协议号 Mask]] | \
handle FirewallMark fw] \
flowid 前面父类的子类句柄
注:
protocol: 支持/etc/protocols中定义的协议号.
创建基于端口的过滤器:
# tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match ip dport 22 0xffff flowid 10:1
# tc filter add dev eth0 protocol ip parent 10: prio 1 u32 match ip sport 80 0xffff flowid 10:1
注:
上面两个是精确匹配80, 即: 80和0xffff或运算的值 必须与 目标端口 匹配.
u32: 是一种根据协议内容做数据提取,与指定参数做匹配的参数.
# tc filter add dev eth0 protocol ip parent 10: prio 2 flowid 10:2 #默认所有流量都匹配.
创建基于地址的过滤器:
# tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 match ip dst 4.3.2.1/32 flowid 10:1
# tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 match ip src 1.2.3.4/32 flowid 10:1
注:
IP/32: 这是精确匹配主机IP. 若需要匹配网络地址,可使用指定CIDR值,如:192.168.0.0/24
# tc filter add dev eth0 protocol ip parent 10: prio 2 flowid 10:2
基于源地址 和 源端口的过滤器:
# tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 match ip src 4.3.2.1/32 match ip sport 80 0xffff flowid 10:1
基于协议号的过滤器:
# tc filter add dev eth0 parent 10:0 protocol ip prio 1 u32 match ip protocol 1 0xff flowid 10:1
基于防火墙标记的过滤器:
# tc filter add dev eth1 protocol ip parent 1:0 prio 1 handle 6 fw flowid 1:1
# iptables -A PREROUTING -t mangle -i eth0 -j MARK --set-mark 6
基于TOS字段的过滤器:
# tc filter add dev ppp0 parent 1:0 protocol ip prio 10 u32 match ip tos 0x10 0xff flowid 1:4
高级过滤器:
基于路由的过滤器:
目的地址匹配:
# ip route add 192.168.10.0/24 via 192.168.10.1 dev eth1 realm 10
注:
realm :用于定义一个realm号码,用于表示网络或主机路由.
# tc filter add dev eth1 parent 1:0 protocol ip prio 100 route to 10 classid 1:10
注:
此命令定义节点 1:0 里添加了一个优先级是 100 的路由过滤器(或加分类器),
当来自192.168.10.0/24网络的数据包到达这个节点时,就会查询路由表,
若它要从eth1接口被路由出去,则匹配此路由,进而被发送到类1:10,并赋予优先级值为 100。
源地址匹配:
# ip route add 192.168.2.0/24 dev eth2 realm 2
# tc filter add dev eth1 parent 1:0 protocol ip prio 100 route from 2 classid 1:2
注:
若匹配到从192.168.2.0/24网络过来的数据包,则将其送到1:2节点,并赋予优先级值为100.
管理大量过滤器:
注: 不建议使用,若真的有这类需求,可尝试使用ipset 和 mark结合
当你需要管理大量过滤器时,为了避免大量过滤器对每一个数据包都做匹配,带来严重的系统性能问题,
这里提供一种通过散列表来构建 多个链表,每个链表中仅有几条规则过滤器,以便高效匹配过滤器.
下面的例子是对IP做散列表的示例:
假如说你有 1024 个用户使用一个 Cable MODEM,IP 地址范围是 1.2.0.0 到 1.2.3.255,
每个 IP 都需要不同过滤器来对待,最佳的做法如下:
1. 首先创建一个root过滤器
# tc filter add dev eth1 parent 1:0 prio 5 protocol ip u32
2. 然后构建出一个256项的散列表
# tc filter add dev eth1 parent 1:0 prio 5 handle 2: protocol ip u32 divisor 256
3.然后我们向表项中添加一些规则:利用IP地址的后半段做为
# tc filter add dev eth1 protocol ip parent 1:0 prio 5 u32 ht 2:7b: match ip src 1.2.0.123 flowid 1:1
# tc filter add dev eth1 protocol ip parent 1:0 prio 5 u32 ht 2:7b: match ip src 1.2.1.123 flowid 1:2
# tc filter add dev eth1 protocol ip parent 1:0 prio 5 u32 ht 2:7b: match ip src 1.2.3.123 flowid 1:3
# tc filter add dev eth1 protocol ip parent 1:0 prio 5 u32 ht 2:7b: match ip src 1.2.4.123 flowid 1:2
注:
这是第 123 项,包含了为 1.2.0.123、1.2.1.123、1.2.2.123 和 1.2.3.123 准备的匹配
规则,分别把它们发给 1:1、1:2、1:3 和 1:2。注意,我们必须用 16 进制来表示
散列表项,0x7b 就是 123
4.然后创建一个“散列过滤器”,直接把数据包发给散列表中的合适表项:
# tc filter add dev eth1 protocol ip parent 1:0 prio 5 u32 ht 800:: \
match ip src 1.2.0.0/16 \
hashkey mask 0x000000ff at 12 \
link 2:
注:
“800::” 这表示创建一个散列表,所有的过滤都将从这里开始.
at 12: 表示从IP头的第12位开始匹配 mask的长度, IP头的第12~15字节为源IP地址位.
”link 2:“ 表示匹配后,发送数据包发送到前面创建的第2个散列表项,即: 2:
IMQ(Intermediate queueing device: 中介队列设备)
若需要使用IMQ,需要对内核,netfilter,iptables打补丁后才能使用:
https://blog.csdn.net/dayancn/article/details/45871523
这篇文章详细讲解了如何给Linux-kernel2.6.18的内核打上IMQ补丁的详细步骤.
在Linux中由于队列规定只能附加到网卡上,因此有两个局限:
1. 虽可在入口做队列规定,但在上面实现分类队列规定可能性很小,所以相当于只支持出口整形.
2. 一个队列规定只能处理一个网卡流量,无法全局限速.
IMQ就是为解决这两个问题而诞生的,简单说: 你可往一个队列规定中放任何方向的流量, 我们可通过
iptables将打了特定标记的数据包在netfilter的NF_IP_PRE_ROUTING和NF_IP_POST_ROUTING两个
钩子函数处被拦截,并被送到附加在IMQ虚拟网卡上的队列规定中, 这样你就可对进入刚进入网卡的
数据包打上标记做入口整形,或把所有网卡当成一个个类来对待,做全局整形控制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号