全网最通透的Java8版本特性讲解

- 「MoreThanJava」 宣扬的是 「学习,不止 CODE」,本系列 Java 基础教程是自己在结合各方面的知识之后,对 Java 基础的一个总回顾,旨在 「帮助新朋友快速高质量的学习」。
- 当然 不论新老朋友 我相信您都可以 从中获益。如果觉得 「不错」 的朋友,欢迎 「关注 + 留言 + 分享」,文末有完整的获取链接,您的支持是我前进的最大的动力!
1|0特性总览
以下是 Java 8 中的引入的部分新特性。关于 Java 8 新特性更详细的介绍可参考这里。
- 接口默认方法和静态方法
- Lambda 表达式
- 函数式接口
- 方法引用
- Stream
- Optional
- Date/Time API
- 重复注解
- 扩展注解的支持
- Base64
- JavaFX
- 其它
- JDBC 4.2 规范
- 更好的类型推测机制
- HashMap 性能提升
- IO/NIO 的改进
- JavaScript 引擎 Nashorn
- 并发(Concurrency)
- 类依赖分析器 jdeps
- JVM 的 PermGen 空间被移除
2|0一. 接口默认方法和静态方法
2|1接口默认方法
在 Java 8 中,允许为接口方法提供一个默认的实现。必须用 default 修饰符标记这样一个方法,例如 JDK 中的 Iterator 接口:
这将非常有用!如果你要实现一个迭代器,就需要提供 hasNext() 和 next() 方法。这些方法没有默认实现——它们依赖于你要遍历访问的数据结构。不过,如果你的迭代器是 只读 的,那么就不用操心实现 remove() 方法。
默认方法也可以调用其他方法,例如,我们可以改造 Collection 接口,定义一个方便的 isEmpty() 方法:
这样,实现 Collection 的程序员就不用再操心实现 isEmpty() 方法了。
在 JVM 中,默认方法的实现是非常高效的,并且通过字节码指令为方法调用提供了支持。默认方法允许继续使用现有的 Java 接口,而同时能够保障正常的编译过程。这方面好的例子是大量的方法被添加到java.util.Collection接口中去:stream(),parallelStream(),forEach(),removeIf()等。尽管默认方法非常强大,但是在使用默认方法时我们需要小心注意一个地方:在声明一个默认方法前,请仔细思考是不是真的有必要使用默认方法。
2|2解决默认方法冲突
如果先在一个接口中将一个方法定义为默认方法,然后又在类或另一个接口中定义同样的方法,会发生什么?
测试输出:
➡️ 对于 Scale 或者 C++ 这些语言来说,解决这种具有 二义性 的情况规则会很复杂,Java 的规则则简单得多:
- 类优先。如果本类中提供了一个具体方法符合签名,则同名且具有相同参数列表的接口中的默认方法会被忽略;
- 接口冲突。如果一个接口提供了一个默认方法,另一个接口提供了一个同名且参数列表相同的方法 (顺序和类型都相同) ,则必须覆盖这个方法来解决冲突 (就是👆代码的情况,不覆盖编译器不会编译..);
Java 设计者更强调一致性,让程序员自己来解决这样的二义性似乎也显得很合理。如果至少有一个接口提供了一个实现,编译器就会报告错误,程序员就必须解决这个二义性。(如果两个接口都没有为共享方法提供默认实现,则不存在冲突,要么实现,要么不实现..)
➡️ 我们只讨论了两个接口的命名冲突。现在来考虑另一种情况,一个类继承自一个类,同时实现了一个接口,从父类继承的方法和接口拥有同样的方法签名,又将怎么办呢?
程序输出:
还记得我们说过的方法调用的过程吗 (先找本类的方法找不到再从父类找)?加上这里提到的 “类优先” 原则 (本类中有方法则直接调用),这很容易理解!
千万不要让一个默认方法重新定义
Object类中的某个方法。例如,不能为toString()或equals()定义默认方法,尽管对于 List 之类的接口这可能很有吸引力,但由于 类优先原则,这样的方法绝对无法超越Object.toString()或者Object.equals()。
2|3接口静态方法
在 Java 8 中,允许在接口中增加静态方法 (允许不构建对象而直接使用的具体方法)。理论上讲,没有任何理由认为这是不合法的,只是这有违将接口作为抽象规范的初衷。
例子:
调用:
目前为止,通常的做法都是将静态方法放在 伴随类 (可以理解为操作继承接口的实用工具类) 中。在标准库中,你可以看到成对出现的接口和实用工具类,如 Collection/ Collections 或 Path/ Paths。
在 Java 11 中,Path 接口就提供了一个与之工具类 Paths.get() 等价的方法 (该方法用于将一个 URI 或者字符串序列构造成一个文件或目录的路径):
这样一来,Paths 类就不再是必要的了。类似地,如果实现你自己的接口时,没有理由再额外提供一个带有实用方法的工具类。
➡️ 另外,在 Java 9 中,接口中的方法可以是 private。private 方法可以是静态方法或实例方法。由于私有方法只能在接口本身的方法中使用,所以它们的用法很有限,只能作为接口中其他方法的辅助方法。
3|0二. Lambda 表达式
Lambda表达式 (也称为闭包) 是整个 Java 8 发行版中最受期待的在 Java 语言层面上的改变,Lambda 允许把函数作为一个方法的参数,即 行为参数化,函数作为参数传递进方法中。
3|1什么是 Lambda 表达式
我们知道,对于一个 Java 变量,我们可以赋给一个 「值」。

如果你想把 「一块代码」 赋给一个 Java 变量,应该怎么做呢?
比如,我想把右边的代码块,赋值给一个叫做 blockOfCode 的 Java 变量:
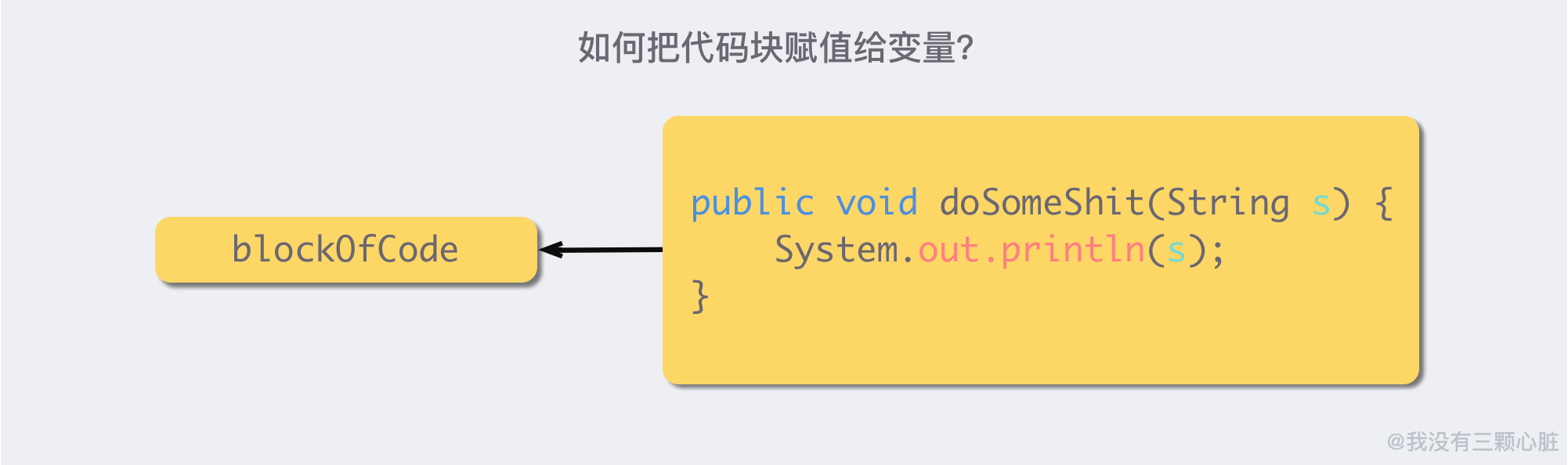
在 Java 8 之前,这个是做不到的,但是 Java 8 问世之后,利用 Lambda 特性,就可以做到了。
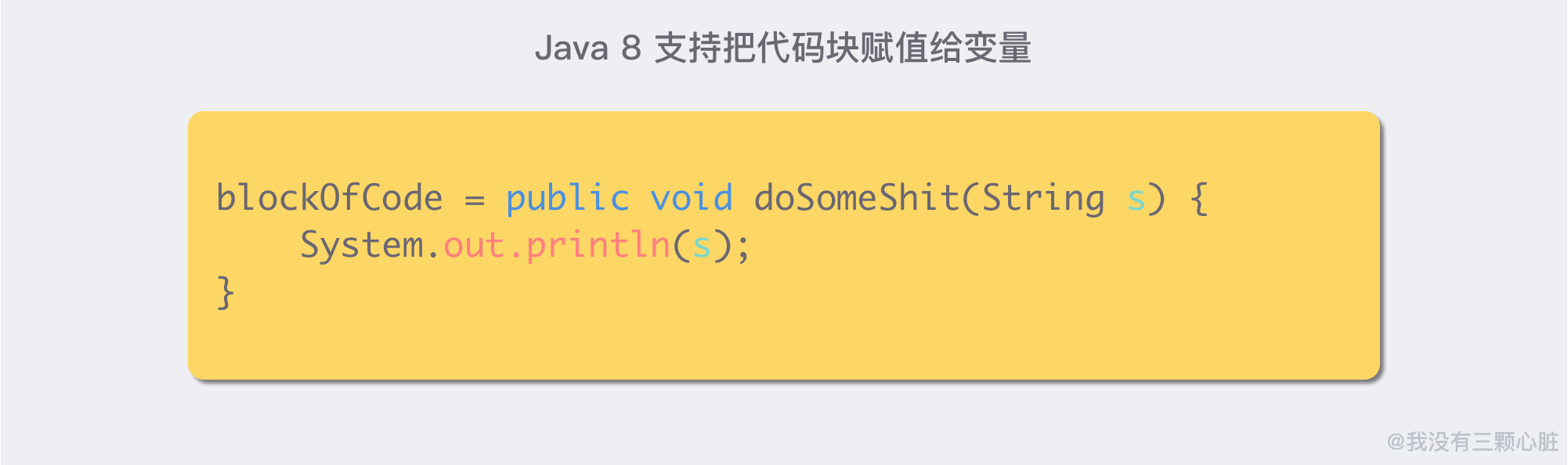
当然,这个并不是一个很简洁的写法,所以为了让这个赋值操作变得更加优雅,我们可以移除一些没有必要的声明。
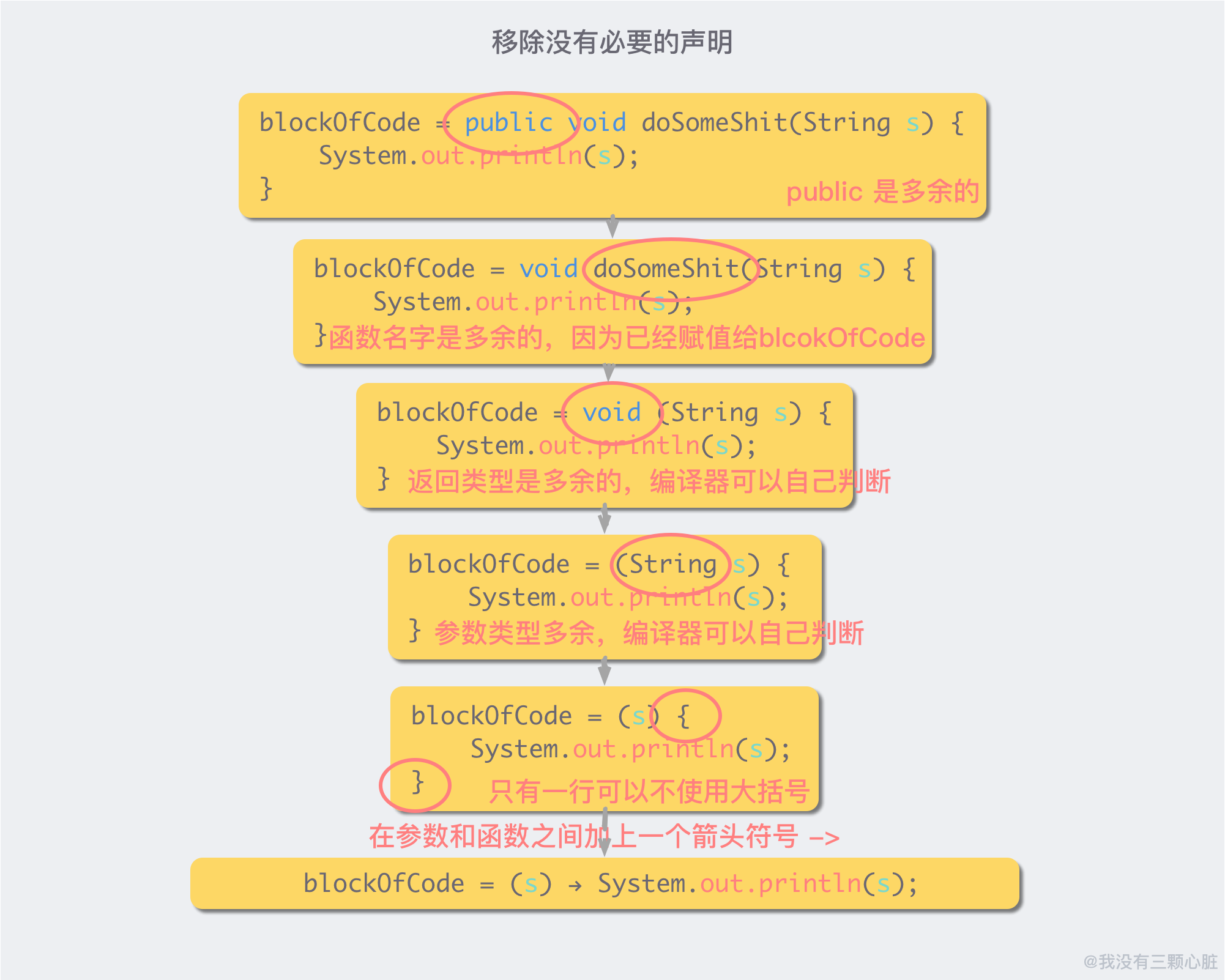
这样,我们就成功的非常优雅的把「一块代码」赋给了一个变量。而「这块代码」,或者说「这个被赋给一个变量的函数」,就是一个 Lambda 表达式。
但是这里仍然有一个问题,就是变量 blockOfCode 的类型应该是什么?
在 Java 8 里面,所有的 Lambda 的类型都是一个接口,而 Lambda 表达式本身,也就是「那段代码」,需要是这个接口的实现。这是理解 Lambda 的一个关键所在,简而言之就是,Lambda 表达式本身就是一个接口的实现。直接这样说可能还是有点让人困扰,我们继续看看例子。我们给上面的 blockOfCode 加上一个类型:

这种只有一个接口函数需要被实现的接口类型,我们叫它「函数式接口」。
为了避免后来的人在这个接口中增加接口函数导致其有多个接口函数需要被实现,变成「非函数接口」,我们可以在这个上面加上一个声明 @FunctionalInterface, 这样别人就无法在里面添加新的接口函数了:
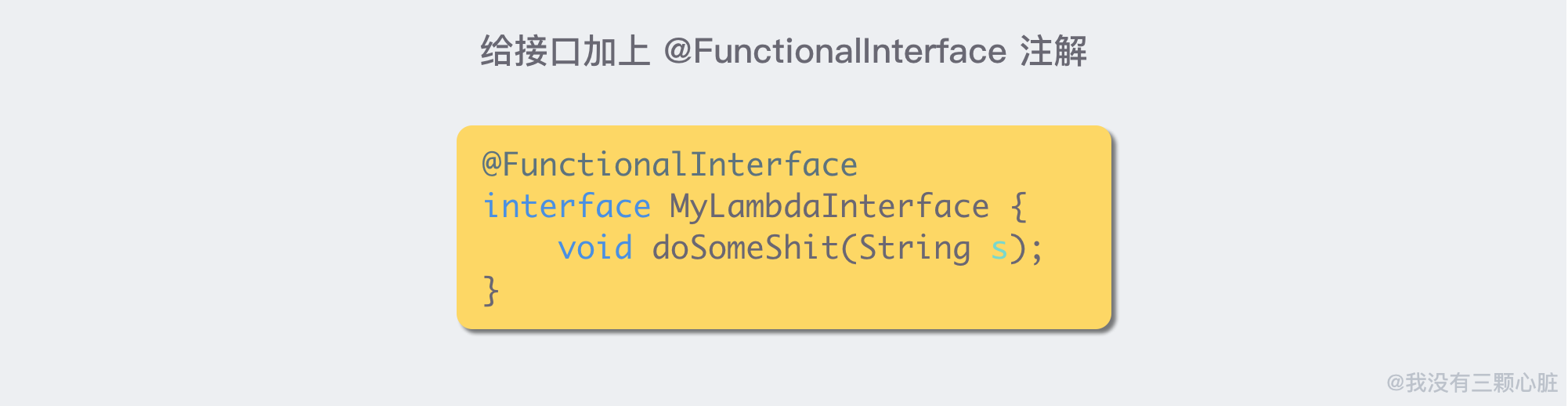
这样,我们就得到了一个完整的 Lambda 表达式声明:

3|2Lambda 表达式的作用
Lambda 最直观的作用就是使代码变得整洁.。
我们可以对比一下 Lambda 表达式和传统的 Java 对同一个接口的实现:
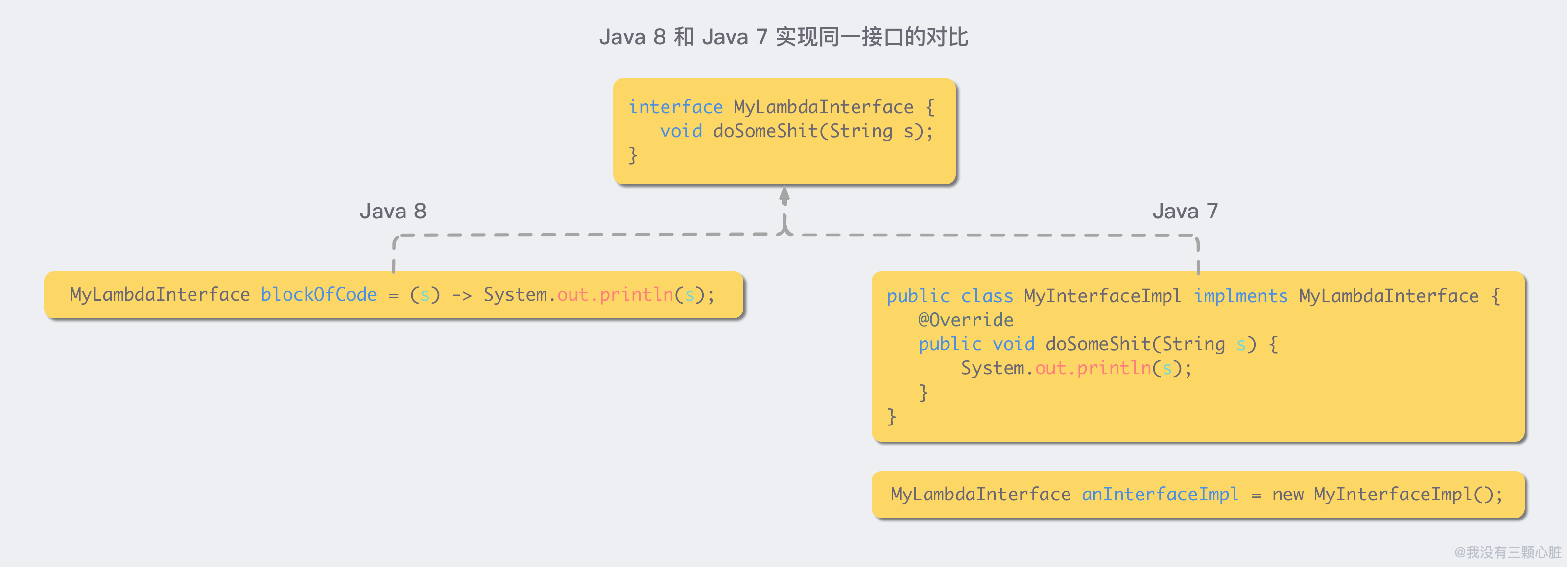
这两种写法本质上是等价的。但是显然,Java 8 中的写法更加优雅简洁。并且,由于 Lambda 可以直接赋值给一个变量,我们就可以直接把 Lambda 作为参数传给函数, 而传统的 Java 必须有明确的接口实现的定义,初始化才行。
有些情况下,这个接口实现只需要用到一次。传统的 Java 7 必须要求你定义一个“污染环境”的接口实现 MyInterfaceImpl,而相较之下 Java 8 的 Lambda, 就显得干净很多。
4|0三. 函数式接口
上面我们说到,只有一个接口函数需要被实现的接口类型,我们叫它「函数式接口」。Lambda 表达式配合函数式接口能让我们代码变得干净许多。
Java 8 API 包含了很多内建的函数式接口,在老 Java 中常用到的比如Comparator或者Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在Lambda上。
Java 8 API 同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自 Google Guava 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到 Lambda 上使用的。
4|11 - Comparator(比较器接口)
Comparator是老Java中的经典接口, Java 8 在此之上添加了多种默认方法。源代码及使用示例如下:
4|22 - Consumer(消费型接口)
Consumer 接口表示执行在单个参数上的操作。源代码及使用示例如下:
更多的Consumer接口
BiConsumer:void accept(T t, U u);: 接受两个参数的二元函数DoubleConsumer:void accept(double value);: 接受一个double参数的一元函数IntConsumer:void accept(int value);: 接受一个int参数的一元函数LongConsumer:void accept(long value);: 接受一个long参数的一元函数ObjDoubleConsumer:void accept(T t, double value);: 接受一个泛型参数一个double参数的二元函数ObjIntConsumer:void accept(T t, int value);: 接受一个泛型参数一个int参数的二元函数ObjLongConsumer:void accept(T t, long value);: 接受一个泛型参数一个long参数的二元函数
4|33 - Supplier(供应型接口)
Supplier 接口是不需要参数并返回一个任意范型的值。其简洁的声明,会让人以为不是函数。这个抽象方法的声明,同 Consumer 相反,是一个只声明了返回值,不需要参数的函数。也就是说 Supplier 其实表达的不是从一个参数空间到结果空间的映射能力,而是表达一种生成能力,因为我们常见的场景中不止是要consume(Consumer)或者是简单的map(Function),还包括了 new 这个动作。而 Supplier 就表达了这种能力。源代码及使用示例如下:
更多Supplier接口
BooleanSupplier:boolean getAsBoolean();: 返回boolean的无参函数DoubleSupplier:double getAsDouble();: 返回double的无参函数IntSupplier:int getAsInt();: 返回int的无参函数LongSupplier:long getAsLong();: 返回long的无参函数
4|44 - Predicate(断言型接口)
Predicate 接口只有一个参数,返回 boolean 类型。该接口包含多种默认方法来将 Predicate 组合成其他复杂的逻辑(比如:与,或,非)。Stream 的 filter 方法就是接受 Predicate 作为入参的。这个具体在后面使用 Stream 的时候再分析深入。源代码及使用示例如下:
更多的Predicate接口
BiPredicate:boolean test(T t, U u);: 接受两个参数的二元断言函数DoublePredicate:boolean test(double value);: 入参为double的断言函数IntPredicate:boolean test(int value);: 入参为int的断言函数LongPredicate:boolean test(long value);: 入参为long的断言函数
4|55 - Function(功能型接口)
Function 接口有一个参数并且返回一个结果,并附带了一些可以和其他函数组合的默认方法(compose, andThen)。源代码及使用示例如下:
更多的Function接口
BiFunction :R apply(T t, U u);: 接受两个参数,返回一个值,代表一个二元函数;DoubleFunction :R apply(double value);: 只处理double类型的一元函数;IntFunction :R apply(int value);: 只处理int参数的一元函数;LongFunction :R apply(long value);: 只处理long参数的一元函数;ToDoubleFunction:double applyAsDouble(T value);: 返回double的一元函数;ToDoubleBiFunction:double applyAsDouble(T t, U u);: 返回double的二元函数;ToIntFunction:int applyAsInt(T value);: 返回int的一元函数;ToIntBiFunction:int applyAsInt(T t, U u);: 返回int的二元函数;ToLongFunction:long applyAsLong(T value);: 返回long的一元函数;ToLongBiFunction:long applyAsLong(T t, U u);: 返回long的二元函数;DoubleToIntFunction:int applyAsInt(double value);: 接受double返回int的一元函数;DoubleToLongFunction:long applyAsLong(double value);: 接受double返回long的一元函数;IntToDoubleFunction:double applyAsDouble(int value);: 接受int返回double的一元函数;IntToLongFunction:long applyAsLong(int value);: 接受int返回long的一元函数;LongToDoubleFunction:double applyAsDouble(long value);: 接受long返回double的一元函数;LongToIntFunction:int applyAsInt(long value);: 接受long返回int的一元函数;
4|66 - Operator
Operator 其实就是 Function,函数有时候也叫作算子。算子在Java8中接口描述更像是函数的补充,和上面的很多类型映射型函数类似。算子 Operator 包括:UnaryOperator 和 BinaryOperator。分别对应单(一)元算子和二元算子。
算子的接口声明如下:
Operator只需声明一个泛型参数 T 即可。对应的使用示例如下:
更多的Operator接口
LongUnaryOperator:long applyAsLong(long operand);: 对long类型做操作的一元算子IntUnaryOperator:int applyAsInt(int operand);: 对int类型做操作的一元算子DoubleUnaryOperator:double applyAsDouble(double operand);: 对double类型做操作的一元算子DoubleBinaryOperator:double applyAsDouble(double left, double right);: 对double类型做操作的二元算子IntBinaryOperator:int applyAsInt(int left, int right);: 对int类型做操作的二元算子LongBinaryOperator:long applyAsLong(long left, long right);: 对long类型做操作的二元算子
4|77 - 其他函数式接口
java.lang.Runnablejava.util.concurrent.Callablejava.security.PrivilegedActionjava.io.FileFilterjava.nio.file.PathMatcherjava.lang.reflect.InvocationHandlerjava.beans.PropertyChangeListenerjava.awt.event.ActionListenerjavax.swing.event.ChangeListener
5|0四. 方法引用
5|11 - 概述
在学习了 Lambda 表达式之后,我们通常使用 Lambda 表达式来创建匿名方法。然而,有时候我们仅仅是调用了一个已存在的方法。如下:
在 Java 8 中,我们可以直接通过方法引用来简写 Lambda 表达式中已经存在的方法。
这种特性就叫做方法引用(Method Reference)。
方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法。方法引用提供了一种引用而不执行方法的方式,它需要由兼容的函数式接口构成的目标类型上下文。计算时,方法引用会创建函数式接口的一个实例。当 Lambda 表达式中只是执行一个方法调用时,不用 Lambda 表达式,直接通过方法引用的形式可读性更高一些。方法引用是一种更简洁易懂的 Lambda 表达式。
注意: 方法引用是一个 Lambda 表达式,其中方法引用的操作符是双冒号
::。
5|22 - 分类
方法引用的标准形式是:类名::方法名。(注意:只需要写方法名,不需要写括号)
有以下四种形式的方法引用:
- 引用静态方法: ContainingClass::staticMethodName
- 引用某个对象的实例方法: containingObject::instanceMethodName
- 引用某个类型的任意对象的实例方法:ContainingType::methodName
- 引用构造方法: ClassName::new
5|33 - 示例
使用示例如下:
测试类:
6|0五. Stream 流操作
流是 Java8 中 API 的新成员,它允许你以 声明式 的方式处理数据集合(通过查询语句来表达,而不是临时编写一个实现)。这有点儿像是我们操作数据库一样,例如我想要查询出热量较低的菜品名字我就可以像下面这样:
您看,我们并没有对菜品的什么属性进行筛选(比如像之前使用迭代器一样每个做判断),我们只是表达了我们想要什么。那么为什么到了 Java 的集合中,这样做就不行了呢?
另外一点,如果我们想要处理大量的数据又该怎么办?是否是考虑使用多线程进行并发处理呢?如果是,那么可能编写的关于并发的代码比使用迭代器本身更加的复杂,而且调试起来也会变得麻烦。
基于以上的几点考虑,Java 设计者在 Java 8 版本中 (真正把函数式编程风格引入到 Java 中),引入了流的概念,来帮助您节约时间!并且有了 Lambda 的参与,流操作的使用将更加顺畅!
6|11 - 流操作特点
特点一:内部迭代
就现在来说,您可以把它简单的当成一种高级的迭代器(Iterator),或者是高级的 for 循环,区别在于,前面两者都是属于外部迭代,而流采用内部迭代。
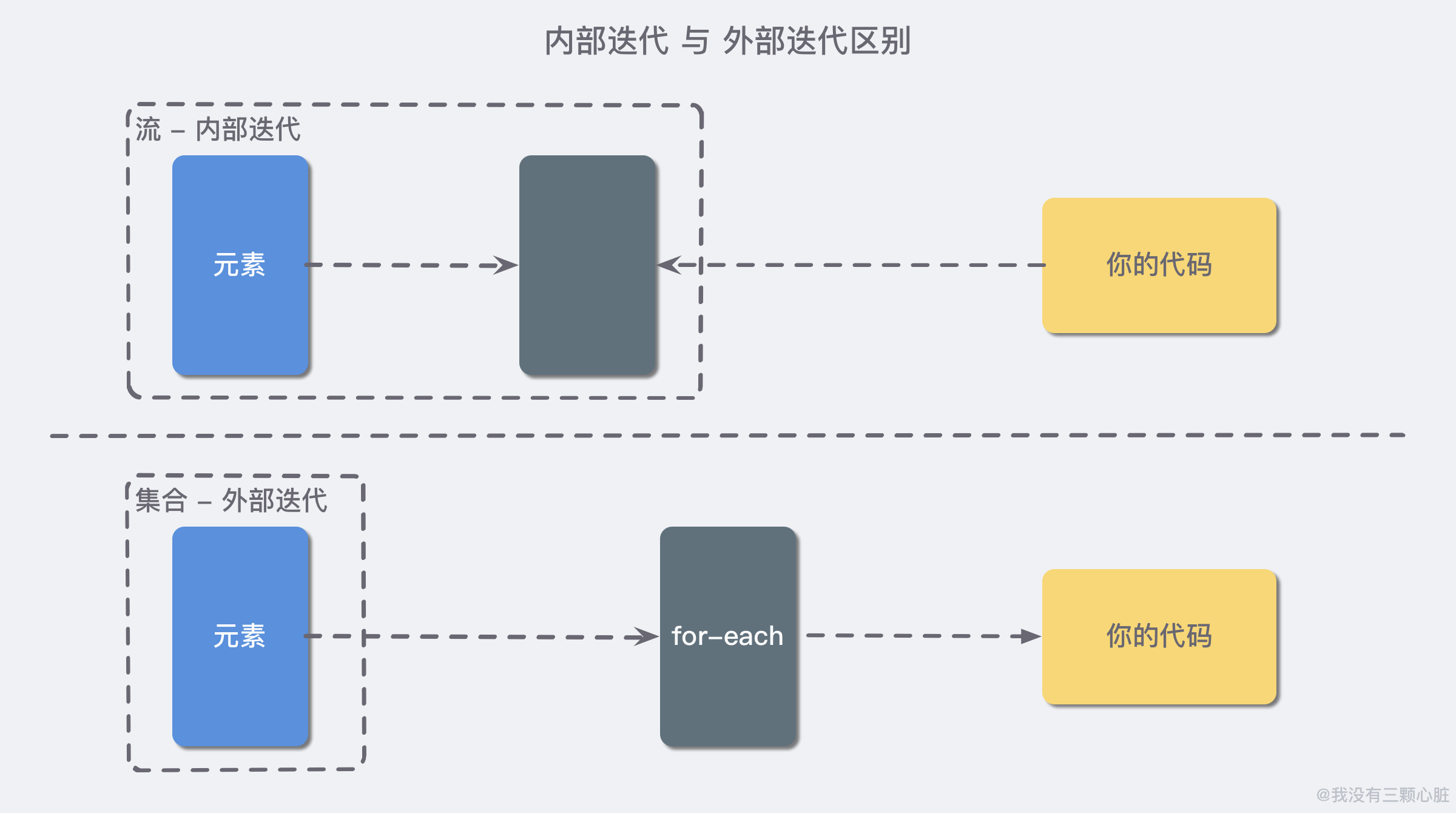
上图简要说明了内部迭代与外部迭代的差异,我们再举一个生活中实际的例子(引自《Java 8 实战》),比如您想让您两岁的孩子索菲亚把她的玩具都收到盒子里面去,你们之间可能会产生如下的对话:
- 你:“索菲亚,我们把玩具收起来吧,地上还有玩具吗?”
- 索菲亚:“有,球。”
- 你:“好,把球放进盒子里面吧,还有吗?”
- 索菲亚:“有,那是我的娃娃。”
- 你:“好,把娃娃也放进去吧,还有吗?”
- 索菲亚:“有,有我的书。”
- 你:“好,把书也放进去,还有吗?”
- 索菲亚:“没有了。”
- 你:“好,我们收好啦。”
这正是你每天都要对 Java 集合做的事情。你外部迭代了一个集合,显式地取出每个项目再加以处理,但是如果你只是跟索菲亚说:“把地上所有玩具都放进盒子里”,那么索菲亚就可以选择一手拿娃娃一手拿球,或是选择先拿离盒子最近的那个东西,再拿其他的东西。
采用内部迭代,项目可以透明地并行处理,或者用优化的顺序进行处理,要是使用 Java 过去的外部迭代方法,这些优化都是很困难的。
这或许有点鸡蛋里挑骨头,但这差不多就是 Java 8 引入流的原因了——Streams 库的内部迭代可以自动选择一种是和你硬件的数据表示和并行实现。
特点二:只能遍历一次
请注意,和迭代器一样,流只能遍历一次。当流遍历完之后,我们就说这个流已经被消费掉了,你可以从原始数据那里重新获得一条新的流,但是却不允许消费已消费掉的流。例如下面代码就会抛出一个异常,说流已被消费掉了:
特点三:方便的并行处理
Java 8 中不仅提供了方便的一些流操作(比如过滤、排序之类的),更重要的是对于并行处理有很好的支持,只需要加上 .parallel() 就行了!例如我们使用下面程序来说明一下多线程流操作的方便和快捷,并且与单线程做了一下对比:
以上程序分别使用了单线程流和多线程流计算了一千万个随机数的和,输出如下:
并行流的内部使用了默认的 ForkJoinPool 分支/合并框架,它的默认线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors() 得到的(当然我们也可以全局设置这个值)。我们也不再去过度的操心加锁线程安全等一系列问题。
6|22 - 一些重要方法说明
stream: 返回数据流,集合作为其源parallelStream: 返回并行数据流, 集合作为其源filter: 方法用于过滤出满足条件的元素map: 方法用于映射每个元素对应的结果forEach: 方法遍历该流中的每个元素limit: 方法用于减少流的大小sorted: 方法用来对流中的元素进行排序anyMatch: 是否存在任意一个元素满足条件(返回布尔值)allMatch: 是否所有元素都满足条件(返回布尔值)noneMatch: 是否所有元素都不满足条件(返回布尔值)collect: 方法是终端操作,这是通常出现在管道传输操作结束标记流的结束
6|33 - 一些使用示例
Filter 过滤
Sort 排序
Map 映射
Match 匹配
Count 计数
Reduce 归约
这是一个最终操作,允许通过指定的函数来将 stream 中的多个元素规约为一个元素,规越后的结果是通过 Optional 接口表示的。代码如下:
想了解更多请参考:https://www.wmyskxz.com/2019/08/03/java8-liu-cao-zuo-ji-ben-shi-yong-xing-neng-ce-shi/
7|0六. Optional
到目前为止,臭名昭著的空指针异常是导致 Java 应用程序失败的最常见原因。以前,为了解决空指针异常,Google公司著名的 Guava 项目引入了 Optional 类,Guava 通过使用检查空值的方式来防止代码污染,它鼓励程序员写更干净的代码。受到 Google Guava 的启发,Optional类已经成为 Java 8 类库的一部分。
Optional 实际上是个容器:它可以保存类型 T 的值,或者仅仅保存 null。Optional 提供很多有用的方法,这样我们就不用显式进行空值检测。
我们下面用两个小例子来演示如何使用 Optional 类:一个允许为空值,一个不允许为空值。
如果 Optional 类的实例为非空值的话,isPresent() 返回 true,否从返回 false。为了防止 Optional 为空值,orElseGet() 方法通过回调函数来产生一个默认值。map() 函数对当前 Optional 的值进行转化,然后返回一个新的 Optional 实例。orElse() 方法和 orElseGet() 方法类似,但是 orElse 接受一个默认值而不是一个回调函数。下面是这个程序的输出:
让我们来看看另一个例子:
下面是程序的输出:
7|1Lambda 配合 Optinal 优雅解决 null
这里假设我们有一个 person object,以及一个 person object 的 Optional wrapper:
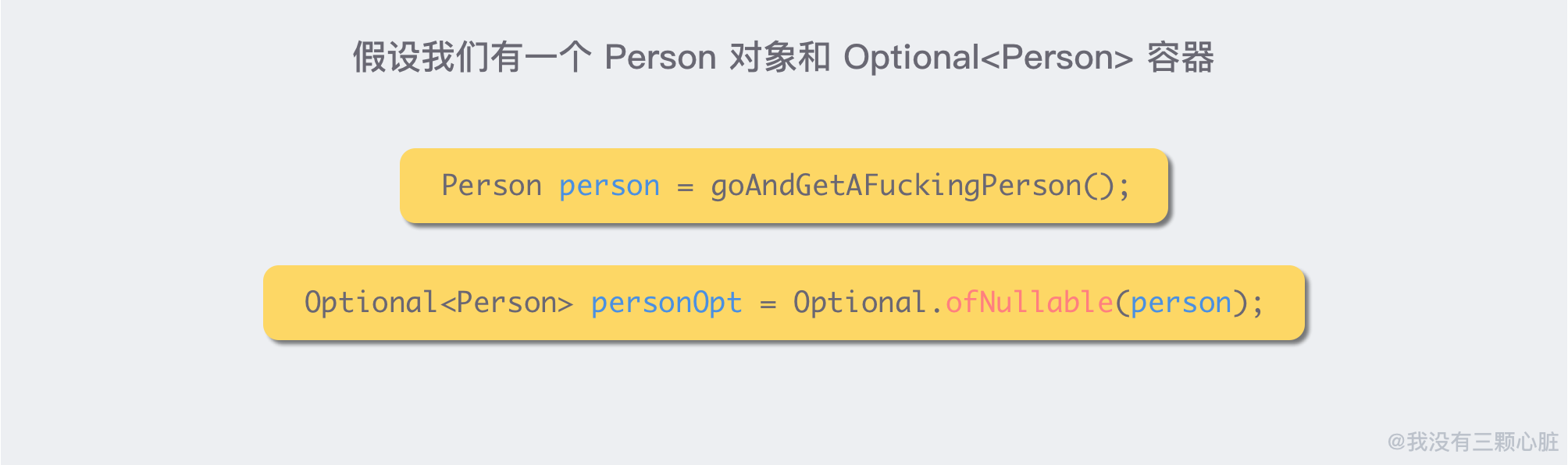
Optional<T> 如果不结合 Lambda 使用的话,并不能使原来繁琐的 null check 变的简单。

只有当 Optional<T> 结合 Lambda 一起使用的时候,才能发挥出其真正的威力!
我们现在就来对比一下下面四种常见的 null 处理中,Java 8 的 Lambda + Optional<T> 和传统 Java 两者之间对于 null 的处理差异。
情况一:存在则继续
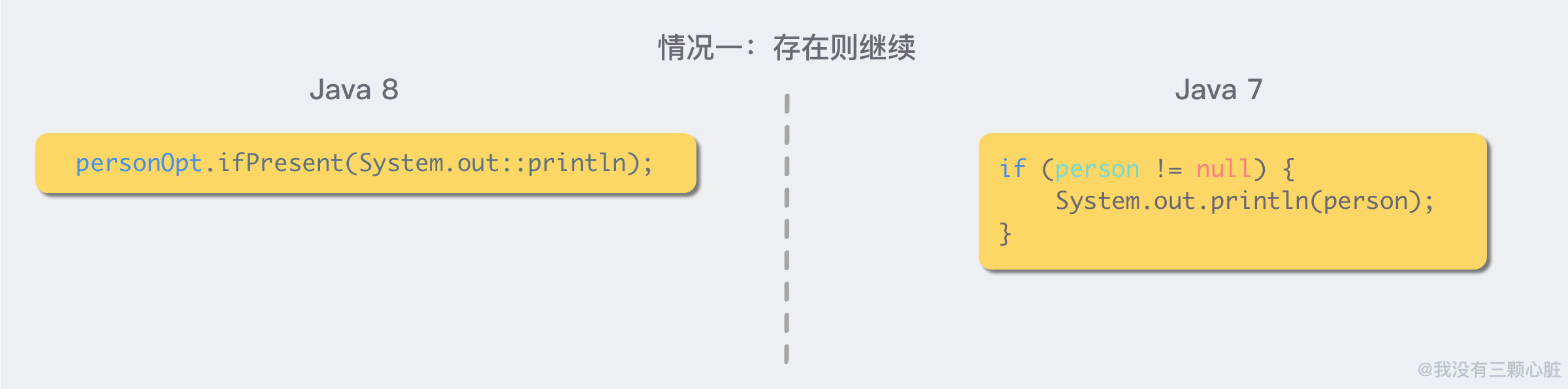
情况二:存在则返回,无则返回不存在

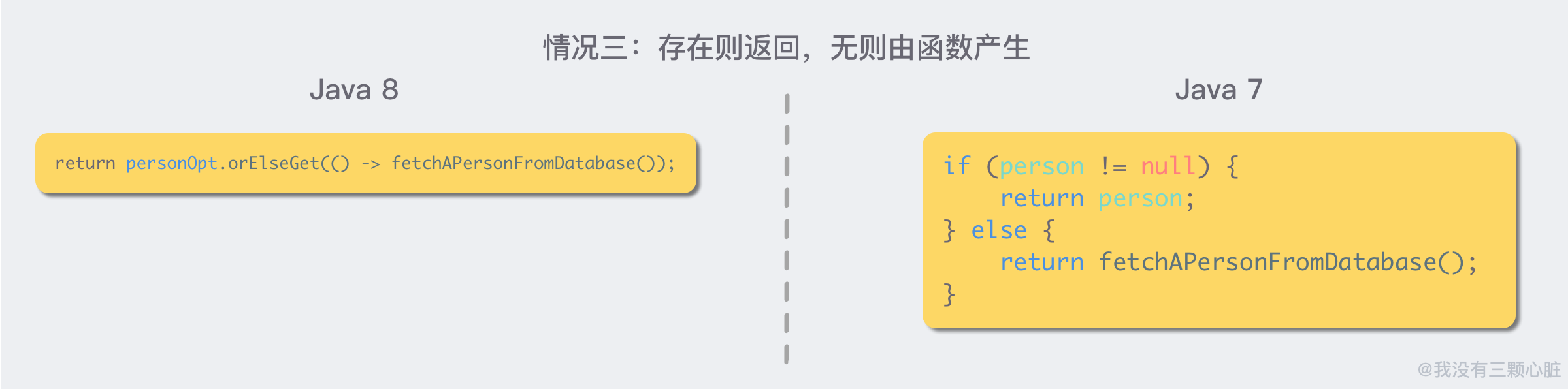
情况三:存在则返回,无则由函数产生
情况四:夺命连环 null 检查
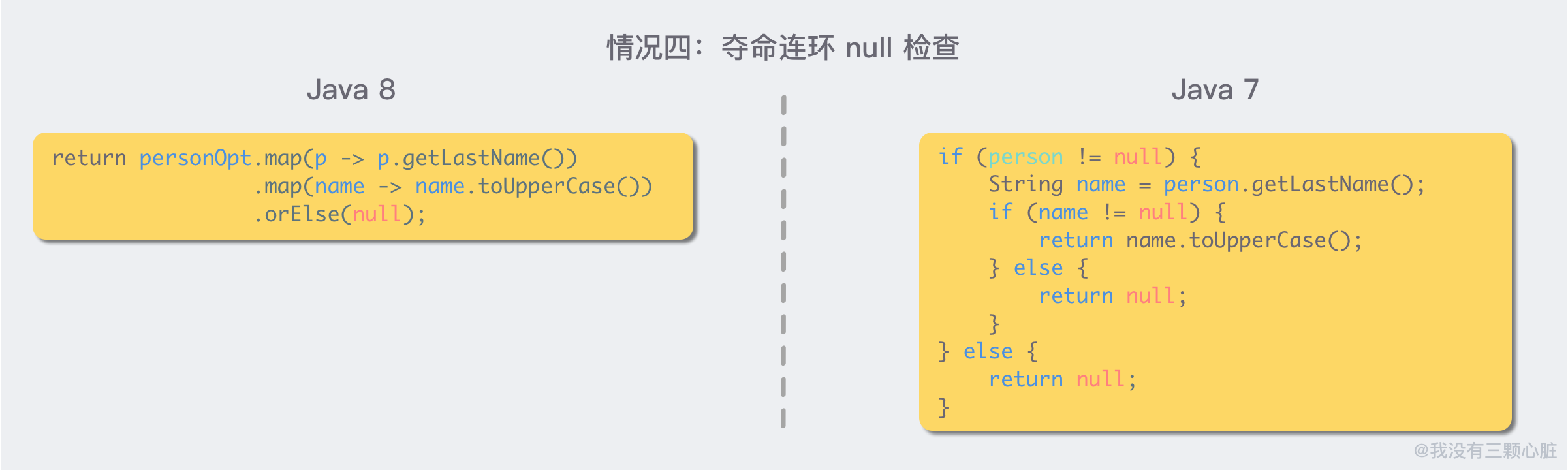
由上述四种情况可以清楚地看到,Optional<T> + Lambda 可以让我们少写很多 ifElse 块。尤其是对于情况四那种夺命连环 null 检查,传统 Java 的写法显得冗长难懂,而新的 Optional<T> +Lambda 则清新脱俗,清楚简洁。
8|0七. Data/Time API
Java 8 在包 java.time 下包含了一组全新的时间日期API。新的日期API和开源的 Joda-Time 库差不多,但又不完全一样,下面的例子展示了这组新API里最重要的一些部分:
8|11 - Clock 时钟
Clock 类提供了访问当前日期和时间的方法,Clock 是时区敏感的,可以用来取代 System.currentTimeMillis() 来获取当前的微秒数。某一个特定的时间点也可以使用 Instant 类来表示,Instant 类也可以用来创建老的 java.util.Date 对象。代码如下:
8|22 - Timezones 时区
在新 AP I中时区使用 ZoneId 来表示。时区可以很方便的使用静态方法 of 来获取到。时区定义了到 UTS 时间的时间差,在 Instant 时间点对象到本地日期对象之间转换的时候是极其重要的。代码如下:
8|33 - LocalTime 本地时间
LocalTime 定义了一个没有时区信息的时间,例如 晚上 10 点,或者 17:30:15。下面的例子使用前面代码创建的时区创建了两个本地时间。之后比较时间并以小时和分钟为单位计算两个时间的时间差。代码如下:
LocalTime 提供了多种工厂方法来简化对象的创建,包括解析时间字符串。代码如下:
8|44 - LocalData 本地日期
LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和 LocalTime 基本一致。下面的例子展示了如何给 Date 对象加减天/月/年。另外要注意的是这些对象是不可变的,操作返回的总是一个新实例。代码如下:
从字符串解析一个 LocalDate 类型和解析 LocalTime 一样简单。代码如下:
8|55 - LocalDateTime 本地日期时间
LocalDateTime同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime和LocalTime还有LocalDate一样,都是不可变的。LocalDateTime提供了一些能访问具体字段的方法。代码如下:
只要附加上时区信息,就可以将其转换为一个时间点Instant对象,Instant时间点对象可以很容易的转换为老式的java.util.Date。代码如下:
格式化LocalDateTime和格式化时间和日期一样的,除了使用预定义好的格式外,我们也可以自己定义格式。代码如下:
和java.text.NumberFormat不一样的是新版的DateTimeFormatter是不可变的,所以它是线程安全的。
9|0八. 重复注解
自从 Java 5 引入了注解机制,这一特性就变得非常流行并且广为使用。然而,使用注解的一个限制是相同的注解在同一位置只能声明一次,不能声明多次。Java 8 打破了这条规则,引入了重复注解机制,这样相同的注解可以在同一地方声明多次。
重复注解机制本身必须用 @Repeatable 注解。事实上,这并不是语言层面上的改变,更多的是编译器的技巧,底层的原理保持不变。让我们看一个快速入门的例子:
正如我们看到的,这里有个使用 @Repeatable(Filters.class) 注解的注解类 Filter,Filters 仅仅是 Filter 注解的数组,但Java编译器并不想让程序员意识到 Filters 的存在。这样,接口 Filterable 就拥有了两次 Filter(并没有提到Filter)注解。
同时,反射相关的API提供了新的函数getAnnotationsByType()来返回重复注解的类型(请注意Filterable.class.getAnnotation(Filters.class)`经编译器处理后将会返回Filters的实例)。
10|0九. 扩展注解的支持
Java 8 扩展了注解的上下文。现在几乎可以为任何东西添加注解:局部变量、泛型类、父类与接口的实现,就连方法的异常也能添加注解。下面演示几个例子:
11|0十. Base64
在 Java 8 中,Base64 编码已经成为 Java 类库的标准。它的使用十分简单,下面让我们看一个例子:
程序在控制台上输出了编码后的字符与解码后的字符:
Base64 类同时还提供了对 URL、MIME 友好的编码器与解码器(Base64.getUrlEncoder() / Base64.getUrlDecoder(), Base64.getMimeEncoder() / Base64.getMimeDecoder())。
12|0十一. JavaFX
JavaFX是一个强大的图形和多媒体处理工具包集合,它允许开发者来设计、创建、测试、调试和部署富客户端程序,并且和Java一样跨平台。从Java8开始,JavaFx已经内置到了JDK中。关于JavaFx更详细的文档可参考JavaFX中文文档。
13|0十二. 其它
13|11. JDBC4.2规范
JDBC4.2主要有以下几点改动:
- 增加了对
REF Cursor的支持 - 修改返回值大小范围(update count)
- 增加了
java.sql.DriverAction接口 - 增加了
java.sql.SQLType接口 - 增加了
java.sql.JDBCtype枚举 - 对
java.time包时间类型的支持
13|22. 更好的类型推测机制
Java 8 在类型推测方面有了很大的提高。在很多情况下,编译器可以推测出确定的参数类型,这样就能使代码更整洁。让我们看一个例子:
这里是Value<String>类型的用法。
Value.defaultValue()的参数类型可以被推测出,所以就不必明确给出。在Java 7中,相同的例子将不会通过编译,正确的书写方式是Value.<String>defaultValue()。
13|33. HashMap性能提升
Java 8 中,HashMap 内部实现又引入了红黑树,使得 HashMap 的总体性能相较于 Java 7 有比较明显的提升。以下是对 Hash 均匀和不均匀的情况下的性能对比
Hash较均匀的情况

Hash极不均匀的情况

想要了解更多 HashMap 的童鞋戳这里吧:传送门
13|44. IO/NIO 的改进
Java 8 对IO/NIO也做了一些改进。主要包括:改进了java.nio.charset.Charset的实现,使编码和解码的效率得以提升,也精简了jre/lib/charsets.jar包;优化了String(byte[], *)构造方法和String.getBytes()方法的性能;还增加了一些新的IO/NIO方法,使用这些方法可以从文件或者输入流中获取流(java.util.stream.Stream),通过对流的操作,可以简化文本行处理、目录遍历和文件查找。
新增的 API 如下:
BufferedReader.line(): 返回文本行的流Stream<String>File.lines(Path, Charset): 返回文本行的流Stream<String>File.list(Path): 遍历当前目录下的文件和目录File.walk(Path, int, FileVisitOption): 遍历某一个目录下的所有文件和指定深度的子目录File.find(Path, int, BiPredicate, FileVisitOption...): 查找相应的文件
下面就是用流式操作列出当前目录下的所有文件和目录:
13|55. JavaScript 引擎 Nashorn
Java 8 提供了一个新的Nashorn javascript引擎,它允许我们在 JVM 上运行特定的 javascript 应用。Nashorn javascript 引擎只是javax.script.ScriptEngine另一个实现,而且规则也一样,允许Java和JavaScript互相操作。这里有个小例子:
输出如下:
13|66. 并发(Concurrency)
在新增Stream机制与Lambda的基础之上,在java.util.concurrent.ConcurrentHashMap中加入了一些新方法来支持聚集操作。同时也在java.util.concurrent.ForkJoinPool类中加入了一些新方法来支持共有资源池(common pool)(请查看我们关于Java 并发的免费课程)。
新增的java.util.concurrent.locks.StampedLock类提供一直基于容量的锁,这种锁有三个模型来控制读写操作(它被认为是不太有名的java.util.concurrent.locks.ReadWriteLock类的替代者)。
在java.util.concurrent.atomic包中还增加了下面这些类:
- DoubleAccumulator
- DoubleAdder
- LongAccumulator
- LongAdder
13|77. 类依赖分析器jdeps
Jdeps是一个功能强大的命令行工具,它可以帮我们显示出包层级或者类层级java类文件的依赖关系。它接受class文件、目录、jar文件作为输入,默认情况下,jdeps会输出到控制台。
作为例子,让我们看看现在很流行的 Spring 框架的库的依赖关系报告。为了让报告短一些,我们只分析一个 jar: org.springframework.core-3.0.5.RELEASE.jar.
jdeps org.springframework.core-3.0.5.RELEASE.jar这个命令输出内容很多,我们只看其中的一部分,这些依赖关系根绝包来分组,如果依赖关系在classpath里找不到,就会显示 not found。
13|88. JVM 的 PermGen 空间被移除
PermGen空间被移除了,取而代之的是Metaspace(JEP 122)。JVM 选项-XX:PermSize与-XX:MaxPermSize分别被-XX:MetaSpaceSize与-XX:MaxMetaspaceSize所代替。
区别:
- 元空间并不在虚拟机中,而是使用本地内存
- 默认情况下,元空间的大小仅受本地内存限制
- 也可以通过-XX:MetaspaceSize指定元空间大小
14|0参考资料
- 「MoreThanJava」Day 7:接口详解 - https://www.wmyskxz.com/2020/08/13/morethanjava-day-7-jie-kou-xiang-jie/
- 【知乎问题】Lambda 表达式 有何用处?如何使用? | @Mingqi - https://www.zhihu.com/question/20125256
- Java8新特性及使用(一) | 闪烁之狐 - http://blinkfox.com/2018/11/13/hou-duan/java/java8-xin-te-xing-ji-shi-yong-yi/#toc-heading-21
- Java8新特性及使用(二) | 闪烁之狐 - http://blinkfox.com/2018/11/14/hou-duan/java/java8-xin-te-xing-ji-shi-yong-er/
15|0文章推荐
- 这都JDK15了,JDK7还不了解? - https://www.wmyskxz.com/2020/08/18/java7-ban-ben-te-xing-xiang-jie/
- 你记笔记吗?关于最近知识管理工具革新潮心脏有话要说 - https://www.wmyskxz.com/2020/08/16/ni-ji-bi-ji-ma-guan-yu-zui-jin-zhi-shi-guan-li-gong-ju-ge-xin-chao-xin-zang-you-hua-yao-shuo/
- 黑莓OS手册是如何详细阐述底层的进程和线程模型的? - https://www.wmyskxz.com/2020/07/31/hao-wen-tui-jian-hei-mei-os-shou-ce-shi-ru-he-xiang-xi-chan-shu-di-ceng-de-jin-cheng-he-xian-cheng-mo-xing-de/
- 「MoreThanJava」系列文集 - https://www.wmyskxz.com/categories/MoreThanJava/
- 本文已收录至我的 Github 程序员成长系列 【More Than Java】,学习,不止 Code,欢迎 star:https://github.com/wmyskxz/MoreThanJava
- 个人公众号 :wmyskxz,个人独立域名博客:wmyskxz.com,坚持原创输出,下方扫码关注,2020,与您共同成长!

非常感谢各位人才能 看到这里,如果觉得本篇文章写得不错,觉得 「我没有三颗心脏」有点东西 的话,求点赞,求关注,求分享,求留言!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
__EOF__

本文链接:https://www.cnblogs.com/wmyskxz/p/13527583.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?