MySQL随笔(四)
mysql 中 replace into 与 insert into on duplicate key update 的使用和不同点
replace into和insert into on duplicate key update都是为了解决我们平时的一个问题
就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录。
我们创建一个测试表test
CREATE TABLE `test` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(32) DEFAULT '' COMMENT '姓名',
`addr` varchar(256) DEFAULT '' COMMENT '地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
向该表中插入一些数据
INSERT INTO test
VALUES
(NULL, 'a', 'aaa'),
(NULL, 'b', 'bbb'),
(NULL, 'c', 'ccc'),
(NULL, 'd', 'ddd');
影响行数4,结果如下:
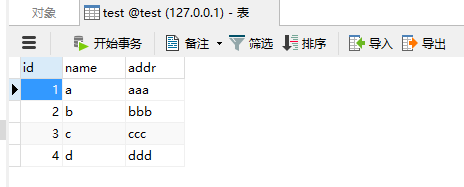
我们运行如下语句:
结果显示,影响行数1条,记录被插入成功了
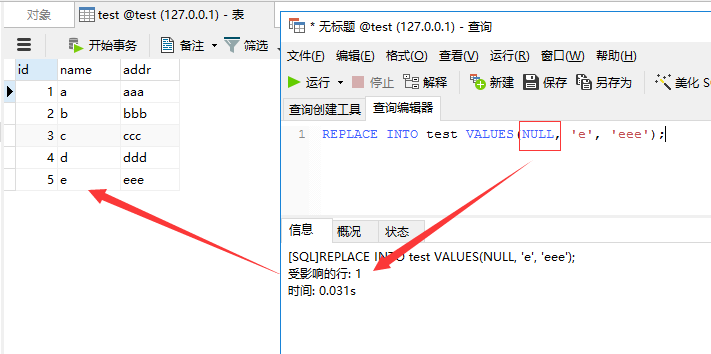
注意上面的语句,我们并没有填写主键ID。
然后我们再执行下面的语句:
REPLACE INTO test VALUES(1, 'aa', 'aaaa');
结果显示,影响行数2条,ID为1的记录被更新成功了
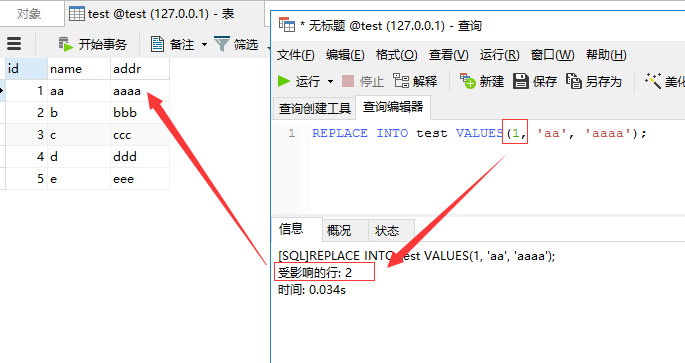
为什么会出现这种情况,原因就是replace into会首先尝试先往表里面插入记录,因为我们的ID是主键,不可重复,显然这条记录是无法插入成功的,然后replace into会把这条已存在的记录删掉,然后再插入,所以会显示影响行数是2。
我们再运行下面这条语句:
REPLACE INTO test(id,name) VALUES(1, 'aaa');
这里我们只指定id,name字段,我们来看看replace into后addr字段内容是否还存在
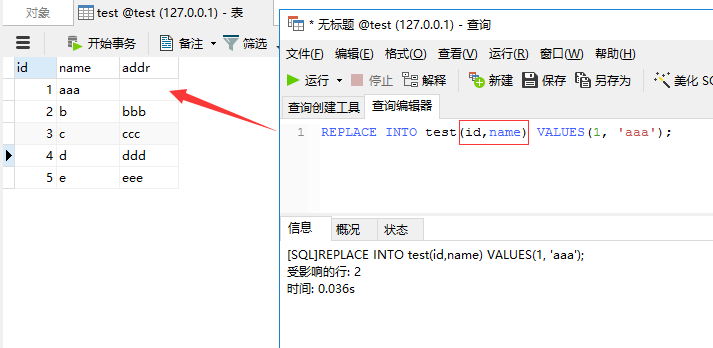
显然addr字段内容没有了,跟我们上面的分析是一致的,reaplce into先删除了id为1的记录,然后再插入记录,但我们并没有指定addr的值,所以会如上图所示那样。
但是有些时候我们的需求是,如果记录存在则更新指定字段的数据,原有字段数据仍保留,而不是上面所示的,addr字段数据没有了。
这里就需要用到insert into on duplicate key update。
1。INSERT INTO t_clear_warrant(id,asset_code,fund_no) VALUES(2,"JR1000114","F008") ON DUPLICATE KEY UPDATE id = VALUES(id), asset_code = VALUES(asset_code), fund_no = VALUES(fund_no);
2。INSERT INTO t_clear_warrant(id,asset_code,fund_no) VALUES(2,"JR1000113","F008") ON DUPLICATE KEY UPDATE id = 6, asset_code = "JR1000113", fund_no = "F008";
1、如果不存在VALUES(2,"JR1000114","F008")这条记录,就insert,存在就update。
2、如果不存在VALUES(2,"JR1000113","F008")这条记录,就insertid = 6, asset_code = "JR1000113", fund_no = "F008",存在就更新成。
执行如下语句:
INSERT INTO test (id, name)
VALUES(2, 'bb')
ON DUPLICATE KEY
UPDATE
name = VALUES(name);
VALUES(字段名)表示获取当前语句insert的列值,VALUES(name)表示的就是'bb'
结果显示,影响行数2条
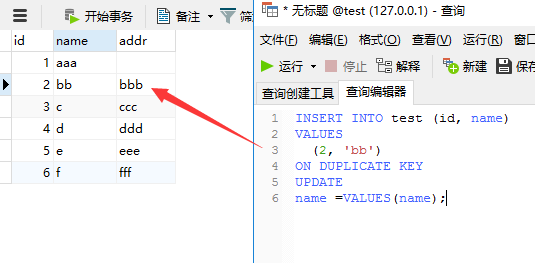
如上图所示,addr字段的值被保留了。
insert into on duplicate key update语句的做法是先插入记录,如果不成功,则更新记录,但是为什么影响的行数是2?
我们重新建一张表test2
CREATE TABLE `test2` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID',
`sn` varchar(32) DEFAULT '' COMMENT '唯一键',
`name` varchar(32) DEFAULT '' COMMENT '姓名',
`addr` varchar(256) DEFAULT '' COMMENT '地址',
PRIMARY KEY (`id`),
UNIQUE KEY `sn` (`sn`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
往里面插入点数据
INSERT INTO test2
VALUES
(NULL, '01', 'a', 'aaa'),
(NULL, '02', 'b', 'bbb'),
(NULL, '03', 'c', 'ccc'),
(NULL, '04', 'd', 'ddd');
我们运行如下语句:
INSERT INTO test2 (sn, name, addr)
VALUES
('02', 'bb', 'bbbb')
ON DUPLICATE KEY
UPDATE
name = VALUES(name),
addr = VALUES(addr);
结果如下:
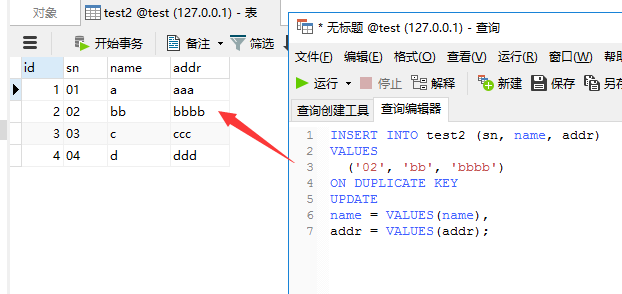
每运行一次上面的语句,虽然影响行数为0,但表test2的自增字段就加1。
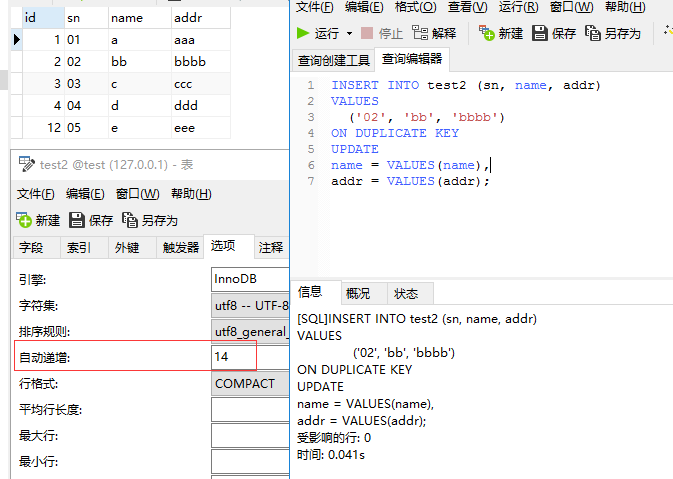
显然如果insert into on duplicate key update语句仅仅只是在原记录基础上进行更新操作的话,自增字段是不会自动加1的,说明它也进行了记录删除操作。
先插入记录,如果不成功,则删除原记录,但保留了除update语句后字段的值,然后把保留的值与需要更新的值合并,然后插入一条新记录。
INSERT INTO bis_own_risk_trans (
username,
idNo,
phone,
deviceId,
ip,
bankCard
)
VALUES
<foreach collection="list" item="item" index="index" separator=",">
(
#{item.username}, #{item.idNo}, #{item.phone},
#{item.deviceId}, #{item.ip}, #{item.bankCard}
)
</foreach>
ON DUPLICATE KEY UPDATE
username = VALUES(username),
idNo = VALUES(idNo),
phone = VALUES(phone),
deviceId = VALUES(deviceId),
ip = VALUES(ip),
bankCard = VALUES(bankCard)
总结:
replace into 与 insert into on duplicate key update都是先尝试插入记录,如果不成功,则删除记录,replace into不保留原记录的值,而insert into on duplicate key update保留。然后插入一条新记录。
on duplicate key update需要有在insert语句中有存在主键或者唯一索引的列,并且对应的数据已经在表中才会执行更新操作。而且如果要更新的字段是主键或者唯一索引,不能和表中已有的数据重复,否则插入更新都失败。
不管是更新还是增加语句都不允许将主键或者唯一索引的对应字段的数据变成表中已经存在的数据。
insert into on duplicate key udpate 和replace into 类似,也是可以插入和更新,它们的不同点是,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号