


2019.5.7
构建MLO,编译u-boot时候,文档中一些错误
路径问题,文件在home/wmy/ti-processor-sdk-linux-am57xx-evm-05.02.00.10/board-support_4.3.1.2/u-boot-2017.01+gitAUTOINC+c68ed086bd-gc68ed086bd/configs路径下,make CROSS_COMPILE=arm-linux-gnueabihf- JN-industrPi_defconfig
运行报如下错误

解决办法:
sudo apt-get install device-tree-compiler安装device-tree-compiler
然后重新编译下就可以了。
ubuntu查看本地ip:ifconfig -a
得到本地ip地址为:10.5.130.199
正常关闭终端:exit
minicom退出方法:ctrl+a,再x,会显示确定退出,回车即可
若没有正常关闭minicom,则再次上电时会出现/dev/ttyUSB0 is locked的错误,此时进入路径/var/lock,将LOCK文件删除即可。
打开图形显示界面:
1.先打开weston 显示服务:/etc/init.d/weston start
2.打开Matrix 界面:/etc/init.d/matrix-gui-2.0 start
将yolo移植到该开发板上。
下载源码,在开发板上编译,将生成可执行文件darknet
进入该目录:cd /run/media/mmcblk0p2/darknet
运行可执行文件:./darknet
结果显示:usage: ./darknet <function>
使用yolov3-tiny做图像检测,运行命令:./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
将输出网络结构,加载一张图片大概14s,之后会显示段错误。
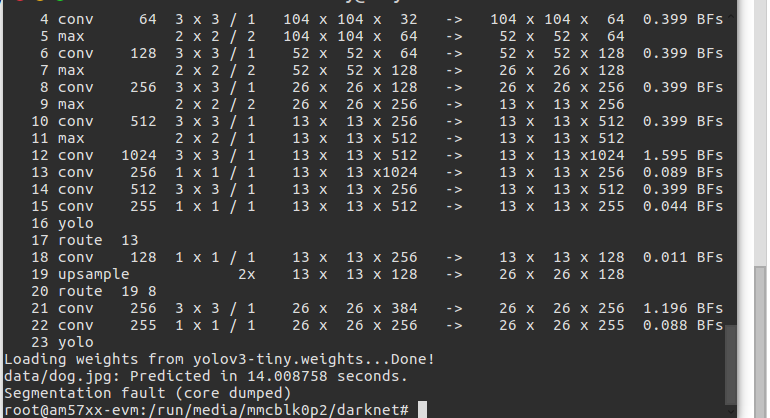
如果只做分类的话,则会显示结果
输入命令:./darknet classify cfg/tiny.cfg tiny.weights data/dog.jpg
会显示分类结果
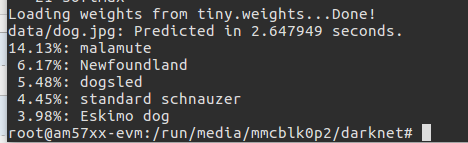
但分类结果也不是很正确,不知道什么原因。
sd卡分区工具:disk
在搜索框中搜索disk
点击磁盘,可对sd卡进行分区。
图形界面,比命令行直观。
嵌入式分为片上内存和片外内存,片上内存,离处理器核心电路很近,因此访问消费的能量很小,但是片上内存较小,一般只有1-10 MB;片外内存可以大,大于1G左右,但是访问速度慢,而且离处理器远,访问一次需要消耗巨大的能量,相当于做200次乘法运算,是一次访问片上内存所需能量的 128 倍。
因此,在做模型压缩的时候,除了要考虑模型大小、计算量,还要考虑减小片外内存访问。
目前为模型瘦身的方法大致分为两类:修改模型拓扑结构、模型压缩。
模型压缩一种方法是在数据上减少精度,如将32位浮点数减小为16位或8位浮点数,此做法的主要原因是数据位长减小可大幅度减小存储模型所需的存储空间(1KB 可以存储 256 个 32-bit 浮点数,但可以存储 1024 个 8-bit 定点数)。虽然该做法一定会损失精度,因此为了解决,提出了很多优化策略,如非线性编码。
另一种是网络修剪,神经学习中有些神经元是冗余的,因此网络修剪就是去掉不活跃的神经元,然而如何观察神经元的活跃程度呢???
Deep Compression将两种方法结合起来,达到了35倍的压缩。

