LightGBM新特性总结
LightGBM提出两种新方法:Gradient-based One-Side Sampling (GOSS) 和Exclusive Feature Bundling (EFB)(基于梯度的one-side采样和互斥的特征捆绑)
Gradient-based One-Side Sampling
针对数量大,GOSS保留所有的梯度较大的实例,在梯度小的实例上使用随机采样。为了抵消对数据分布的影响,计算信息增益的时候,GOSS对小梯度的数据引入常量乘数。GOSS首先根据数据的梯度绝对值排序,选取top a个实例。然后在剩余的数据中随机采样b个实例。接着计算信息增益时为采样出的小梯度数据乘以(1-a)/b,这样算法就会更关注训练不足的实例,而不会过多改变原数据集的分布。
在GOSS中,
- 首先根据数据的梯度将训练降序排序。
- 保留top a个数据实例,作为数据子集A。
- 对于剩下的数据的实例,随机采样获得大小为b的数据子集B。
- 最后我们通过以下方程估计信息增益:
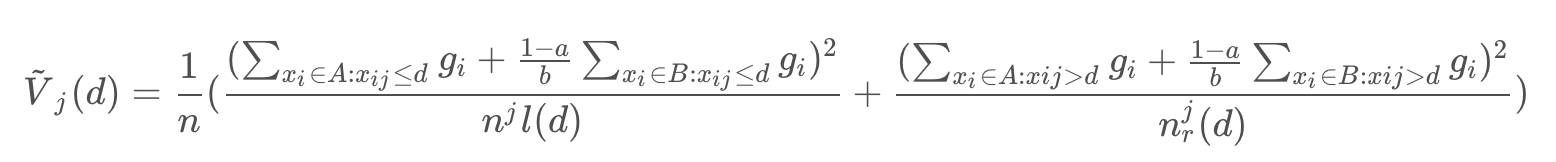
此处GOSS通过较小的数据集估计信息增益![]() ,将大大地减小计算量。更重要的是,理论表明GOSS不会丢失许多训练精度。
,将大大地减小计算量。更重要的是,理论表明GOSS不会丢失许多训练精度。
Exclusive Feature Bundling
针对特征维度高,而高维的数据通常是稀疏的,能否设计一种无损地方法来减少特征的维度。特别的,稀疏特征空间中,许多特征是互斥的,例如他们从不同时为非零值。我们可以绑定互斥的特征为单一特征,通过仔细设计特征臊面算法,作者从特征捆绑中构建了与单个特征相同的特征直方图。这种方式的间直方图时间复杂度从O(#data * #feature)降到O(#data * #bundle),由于#bundle << # feature,我们能够极大地加速GBDT的训练过程而且损失精度。
有两个问题:
- 怎么判定哪些特征应该绑在一起(build bundled)?
- 怎么把特征绑为一个(merge feature)?
bundle(什么样的特征被绑定)?
算法:
- 建立一个图,每个边有权重,其权重和特征之间总体冲突相关。
- 按照降序排列图中的度数来排序特征。
- 检查每个排序之后的每个特征,这个特征绑定到使得冲突最小的绑定,或者建立一个新的绑定。
为了继续提高效率,LightGBM提出了一个更加高效的无图的排序策略:将特征按照非零值个数排序,这和使用图节点的度排序相似,因为更多的非零值通常会导致冲突,新算法在之前算法基础上改变了排序策略。

merging features(特征合并)
通过将互斥特征放在不同的箱中来构建bundle。这可以通过将偏移量添加到特征原始值中实现,例如,假设bundle中有两个特征,原始特征A取值[0, 10],B取值[0, 20]。我们添加偏移量10到B中,因此B取值[10, 30]。通过这种做法,就可以安全地将A、B特征合并,使用一个取值[0, 30]的特征取代AB。算法见上图算法4。
EFB算法能够将许多互斥的特征变为低维稠密的特征,就能够有效的避免不必要0值特征的计算。实际,通过用表记录数据中的非零值,来忽略零值特征,达到优化基础的直方图算法。通过扫描表中的数据,建直方图的时间复杂度将从O(#data)降到O(#non_zero_data)。
参考
LightGBM原理-LightGBM: A Highly Efficient Gradient Boosting Decision Tree

 浙公网安备 33010602011771号
浙公网安备 33010602011771号