
Redis存取数据快的原因
1.Redis是完全基于内存的,绝大部分请求是纯粹的内存操作,这个数据存在内存中,类似于HashMap,而HashMap的优势就是查找和操作的时间复杂度都是0(1);
2.数据结构简单,对数据操作也简单,redis中的结构都是特殊设计的;
3.采用单线程,不存在多进程和多线程导致的切换而消耗CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现的死锁而导致的性能消耗;
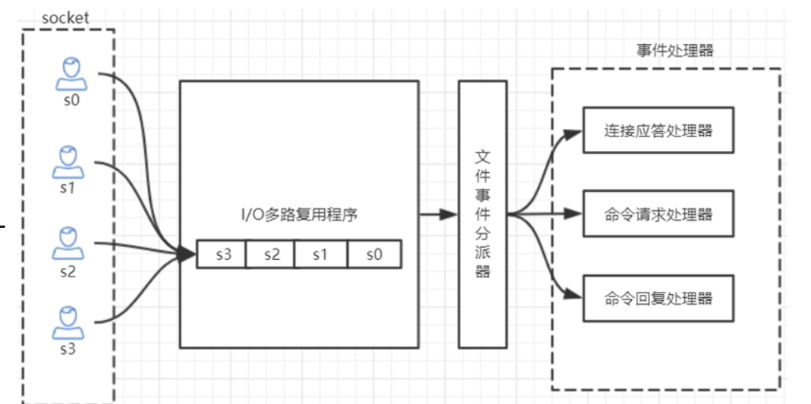
4.使用多路复用I/O模型,非阻塞IO,即NIO
5.Redis直接自己构建了VM机制
Redis的读写是单线程的,为什么那么快?
1、单线程,没有线程切换带来的开销
2、纯内存操作
3、IO多路复用【NIO】,非阻塞IO

 浙公网安备 33010602011771号
浙公网安备 33010602011771号