PO模式介绍、PO模式封装、数据驱动
一、PO模式介绍
1、认识PO模式
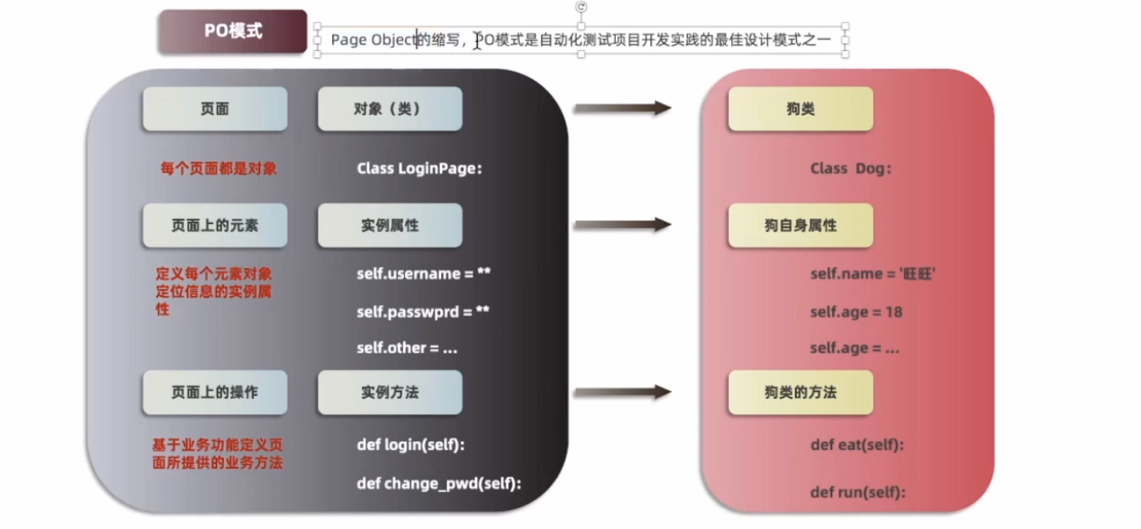
2、PO模式页面对象

3、PO如何做
Base 层:
存放所有页面的公共方法
Page 层:
基于页面或者模块单独封装当前页面要操作的对象
Script 层:
脚本测试 + unittest
二、PO模式封装(在新建项目目录下,新建三个文件夹:base、page、script)
1、base 结构搭建 及 查找方法:实现页面的公共方法(在base 文件夹下新建 base.py)
''' Base类:存放所有page页面功能操作方法: ''' from selenium.webdriver.support.wait import WebDriverWait class Base(object): #类属性 def __init__(self,driver): self.driver = driver #查找元素方法 def base_find_element(self,loc,timeout=10,poll_frequency=0.5): #显示等待 -- 查找元素。loc = (By.ID,"userA"),loc[0]),loc[1] 也可以写为 *loc .都是解包 WebDriverWait(self.driver,timeout,poll_frequency).until(lambda x:x.find_element(loc[0]),loc[1]) #输入方法 def base_input(self,loc,value): #1、获取元素 el = self.base_find_element(loc) #2、清空输入框内容 el.clear() #3、输入内容 el.send_keys(value) #点击方法 def base_click(self,loc): self.base_find_element(loc).click() #获取文本值 def base_get_text(self,loc): self.base_find_element(loc).text
2、page文件夹(在文件夹下新建page_xxx.py文件)
page_模块名,类名:大驼峰,当前页面操作什么元素就封装什么方法
''' 实际方法 ''' from selenium.webdriver.common.by import By from ..Base.base import Base #用户名 username = By.CSS_SELECTOR,"#username" #密码 password = By.CSS_SELECTOR,"#password" #验证码 verify_code = By.CSS_SELECTOR,"#verify_code" #登录按钮 login_btn = By.CSS_SELECTOR,"#login_btn" #昵称(登陆成功后,页面有昵称显示 nick_name = By.CSS_SELECTOR,".userinfo" #登录页面操作方法,继承Base类 class PageLogin(Base): #输入用户名和密码 def __page_username(self,value): self.base_find_element(username,value) #输入密码 def __page_password(self,value): self.base_find_element(password,value) #输入验证码 def __page_verify(self,value): self.base_find_element(verify_code,value) #点击登录 def __page_click_login_btn(self): self.base_click(login_btn) #获取文本方法 def page_get_nickname(self): self.base_get_text(nick_name) #组合业务(测试业务层调用此方法,便捷) def page_login(self,phone,password,code): self.__page_username(phone) self.__page_password(password) self.__page_verify(code) self.__page_click_login_btn()
3、script 文件夹(新建测试页面方法,test01_login.py)
import unittest from selenium import webdriver #导入测试页面方法 from ..page.page_login import PageLogin class TestLogin(unittest.TestCase): def setUp(self) -> None: self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.get("http://hmtpshop.com") #实例化页面 self.login = PageLogin(self.driver) def tearDown(self) -> None: self.driver.quit() def test01_login(self,phone="12345678901",password="123456",code="8888",expect_text="12345678901"): #调用登录业务 self.login.page_login(phone,password,code) #断言 nick_name = self.login.page_get_nickname() self.assertEqual(nick_name,expect_text)
三、数据驱动
什么是数据驱动
以测试数据驱动用例执行(测试数据和代码分离)
为什么要数据驱动
便于维护(维护的焦点从代码转到测试数据)
数据驱动如何操作
编写数据存储文件
编写数据读取工具
使用参数化引用
1、实际操作
新建一个 data 文件夹,存放文件
新建 json 文件,有几个模块写几个 key,值为列表。值 = 说明 + 参数数据 + 预期结果
新建 login_data.json文件
{ "login": [ {"desc": "登陆成功", "phone":"12345678901", "password": "123456", "code": "8888", "expect_code": "12345678901" }, { "desc": "密码为空", "phone":"12345678901", "password": "", "code": "8888", "expect_code": "12345678901" } ] }
封装文件读取工具(新建 utils.py工具)
import json #读取json文件 import os.path def red_json(filename,key): #读取文件路径 file_path = os.path.dirname(__file__) + os.sep + "data" + os.sep +filename #设置空列表,放置读取的值 arr = [] #打开文件 with open(file_path,"r",encoding="utf-8") as f: for data in json.loads(f).get(key): #此时 key 为login,获取login里面的列表的值 arr.append(tuple(data.values())[1:]) #切片,不需要desc 的值 return arr if __name__ == "__main__": red_json()
数据驱动(参数化),在测试层设置参数化
import unittest from selenium import webdriver from parameterized import parameterized from ..utils import red_json #导入测试页面方法 from ..page.page_login import PageLogin class TestLogin(unittest.TestCase): def setUp(self) -> None: self.driver = webdriver.Chrome() self.driver.maximize_window() self.driver.get("http://hmtpshop.com") #实例化页面 self.login = PageLogin(self.driver) def tearDown(self) -> None: self.driver.quit() @parameterized.expand(red_json("login_data","login")) def test01_login(self,phone,password,code,expect_text): try: #调用登录业务 self.login.page_login(phone,password,code) #断言 nick_name = self.login.page_get_nickname() self.assertEqual(nick_name,expect_text) except Exception as e: print(e)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号