
ResNet网络再剖析
随着2018年秋季的到来,提前批和内推大军已经开始了,自己也成功得当了几次炮灰,不过在总结的过程中,越是了解到自己的不足,还是需要加油。
最近重新复习了resnet网络,又能发现一些新的理念,感觉很fantastic,顺便记录一下~
之前有转载一篇resnet的网络,很不错,链接在这:https://www.cnblogs.com/wmr95/articles/8848158.html
下面重新了解一下resnet,Let’s Go~~
《一》Resnet解决了什么问题
首先了解Resnet网络主要解决的问题是:关于深层网络训练带来的问题,包括梯度消失和网络退化。
深度卷积网络自然的整合了低中高不同层次的特征,特征的层次可以靠加深网络的层次来丰富。从而,在构建卷积网络时,网络的深度越高,可抽取的特征层次就越丰富。所以一般我们会倾向于使用更深层次的网络结构,以便取得更高层次的特征。但是在使用深层次的网络结构时我们会遇到两个问题,梯度消失,梯度爆炸问题和网络退化的问题。
但是当使用更深层的网络时,会发生梯度消失、爆炸问题,这个问题很大程度通过标准的初始化和正则化层来基本解决,这样可以确保几十层的网络能够收敛,但是随着网络层数的增加,梯度消失或者爆炸的问题仍然存在。
还有一个问题就是网络的退化,举个例子,假设已经有了一个最优化的网络结构,是18层。当我们设计网络结构的时候,我们并不知道具体多少层次的网络时最优化的网络结构,假设设计了34层网络结构。那么多出来的16层其实是冗余的,我们希望训练网络的过程中,模型能够自己训练这16层为恒等映射,也就是经过这层时的输入与输出完全一样。但是往往模型很难将这16层恒等映射的参数学习正确,那么就一定会不比最优化的18层网络结构性能好,这就是随着网络深度增加,模型会产生退化现象。它不是由过拟合产生的,而是由冗余的网络层学习了不是恒等映射的参数造成的。
注意这里冗余的16层网络并不一定是最后的16层,可能是穿插在网络各层当中。
《二》Resnet网络是如何解决问题
1. Resnet介绍
ResNet使用了一个新的思想,ResNet的思想是假设我们设计一个网络层,存在最优化的网络层次,那么往往我们设计的深层次网络是有很多网络层为冗余层的。那么我们希望这些冗余层能够完成恒等映射,保证经过该恒等层的输入和输出完全相同。具体哪些层是恒等层,这个会有网络训练的时候自己判断出来。将原网络的几层改成一个残差块,残差块的具体构造如下图所示:
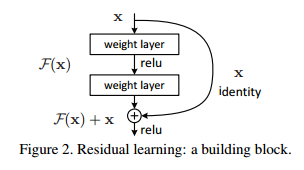
可以看到X是这一层残差块的输入,也称作F(x)为残差,x为输入值,F(X)是经过第一层线性变化并激活后的输出,该图表示在残差网络中,第二层进行线性变化之后激活之前,F(x)加入了这一层输入值X,然后再进行激活后输出。在第二层输出值激活前加入X,这条路径称作shortcut连接。
2. 在引入Resnet网络之前关于问题的解决方案:
我们发现,假设该层是冗余的,在引入ResNet之前,我们想让该层学习到的参数能够满足h(x)=x,即输入是x,经过该冗余层后,输出仍然为x。但是可以看见,要想学习h(x)=x恒等映射时的这层参数是比较困难的。ResNet想到避免去学习该层恒等映射的参数,使用了如上图的结构,让h(x)=F(x)+x;这里的F(x)我们称作残差项,我们发现,要想让该冗余层能够恒等映射,我们只需要学习F(x)=0。学习F(x)=0比学习h(x)=x要简单,因为一般每层网络中的参数初始化偏向于0,这样在相比于更新该网络层的参数来学习h(x)=x,该冗余层学习F(x)=0的更新参数能够更快收敛,如图所示:
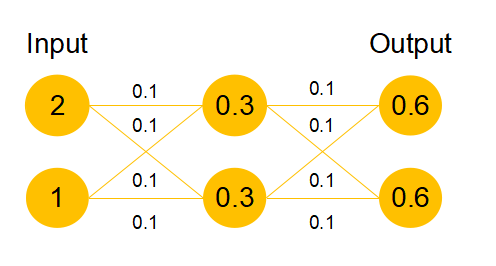
假设该曾网络只经过线性变换,没有bias也没有激活函数。我们发现因为随机初始化权重一般偏向于0,那么经过该网络的输出值为[0.6 0.6],很明显会更接近与[0 0],而不是[2 1],相比与学习h(x)=x,模型要更快到学习F(x)=0。
并且ReLU能够将负数激活为0,过滤了负数的线性变化,也能够更快的使得F(x)=0。这样当网络自己决定哪些网络层为冗余层时,使用ResNet的网络很大程度上解决了学习恒等映射的问题,用学习残差F(x)=0更新该冗余层的参数来代替学习h(x)=x更新冗余层的参数。所以说Resnet搭配ReLU线性激活是完美组合~
这样当网络自行决定了哪些层为冗余层后,通过学习残差F(x)=0来让该层网络恒等映射上一层的输入,使得有了这些冗余层的网络效果与没有这些冗余层的网络效果相同,这样很大程度上解决了网络的退化问题。
3. 引入Resnet网络后是如何解决问题
我们发现很深的网络层,由于参数初始化一般更靠近0,这样在训练的过程中更新浅层网络的参数时,很容易随着网络的深入而导致梯度消失,浅层的参数无法更新。
此处贴反向传播的图~~
可以看到,假设现在需要更新b1,w2,w3,w4参数因为随机初始化偏向于0,通过链式求导我们会发现,w1w2w3相乘会得到更加接近于0的数,那么所求的这个b1的梯度就接近于0,也就产生了梯度消失的现象。
ResNet最终更新某一个节点的参数时,由于h(x)=F(x)+x,由于链式求导后的结果如图所示,不管括号内右边部分的求导参数有多小,因为左边的1的存在,并且将原来的链式求导中的连乘变成了连加状态(正确?),都能保证该节点参数更新不会发生梯度消失或梯度爆炸现象。
这样ResNet在解决了阻碍更深层次网络优化问题的两个重要问题后,ResNet就能训练更深层次几百层乃至几千层的网络并取得更高的精确度了。
最后总结下ResNet网络:
1. 解决梯度消失的问题:引入残差项使得h(x)=F(x)+x,在反向传播的时候因为有x的存在,保证参数更新的时候不容易会出现梯度消失的现象。
2. 解决网络退化的问题:由于参数初始化一般更靠近0,所以对于网络来说训练残差项F(x)=0要比学习h(x)=x更容易收敛。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号