
Context Encoder论文及代码解读
经过秋招和毕业论文的折磨,提交完论文終稿的那一刻总算觉得有多余的时间来搞自己的事情。
研究论文做的是图像修复相关,这里对基于深度学习的图像修复方面的论文和代码进行整理,也算是研究生方向有一个比较好的结束。好啦,下面开始进入正题~
所有的image inpainting的介绍在这里: 基于深度学习的Image Inpainting(论文+代码)
Context encoders for image generation
1. Encoder-decoder pipeline
网络结构是一个简单的编码器-解码器结构,中间采用Channel-wise fully-connected layer来连接编码器和解码器,网络结构如图。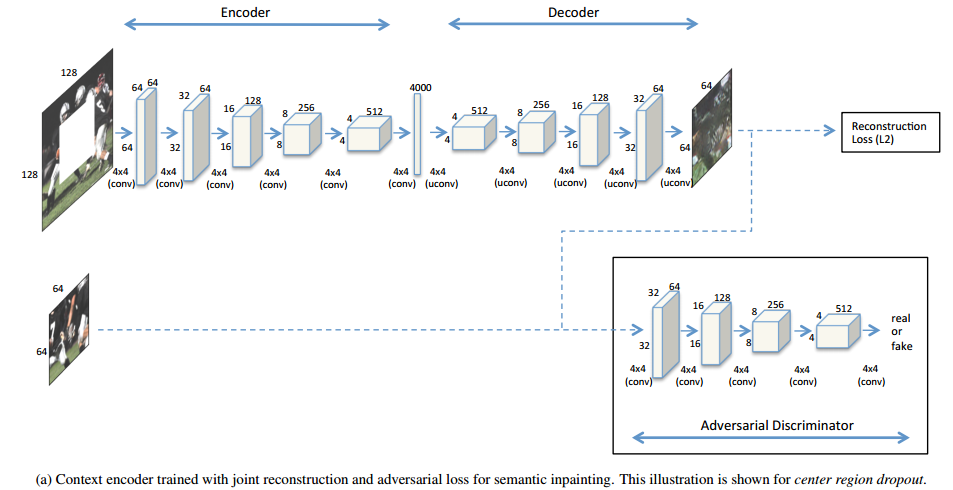
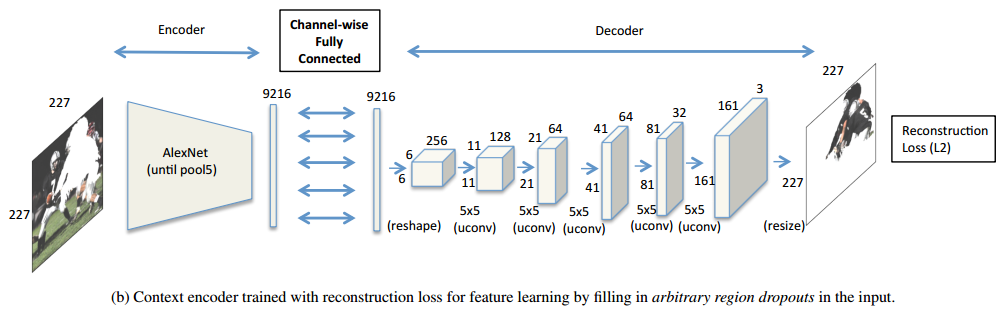
1.1 编码器:采用AlexNet网络作为baseline,五个卷积加上池化pool5,若输入图像为227x227,可以得到一个6x6x256的特征图。
1.2 Channel-wise fully-connected layer:减少网络参数,若使用全连接层,输入特征图为mxnxn,输出也为mxnxn,则需要m2n4的参数,而使用channel-wise仅需要mn4的参数,使用步长为1的卷积来将信息在通道之间传递。
1.3 解码器:就是一系列的五个上卷积的操作,使其恢复到与原图一样的大小。
2. Loss function
包含reconstruction(l2) loss和adversarial loss。
2.1 重建L2 loss主要是捕获缺失区域的整体结构,但是容易在预测输出中平均多种模式;

M作为二值化的掩码,没看懂最外面的M是干啥用。。
2.2 而adv loss则从多种可能的输出模式中选择一种,也可以说是进行特定模式选择,使得预测结果看起来更真实。
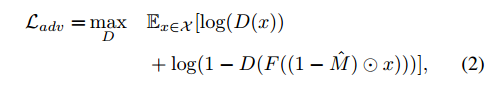
2.3 两种loss结合到一起,既具备结构性,也具备真实语义性。
对于任意区域的图像修复网络结构图如下。
我觉得这篇论文的创新点有以下两点:
1. 使用编码-解码器结构来完成图像修复的任务,并改用channel-wise的方式连接,节省了一定的参数。
2. 使用联合损失函数,结合重建l2 loss和对抗式adv loss,使得修复图像更加真实。
代码解读:train.lua
--------------------------------------------------------------------------- -- Adversarial discriminator net --------------------------------------------------------------------------- local netD = nn.Sequential() if opt.conditionAdv then local netD_ctx = nn.Sequential() -- input Context: (nc) x 128 x 128, going into a convolution netD_ctx:add(SpatialConvolution(nc, ndf, 5, 5, 2, 2, 2, 2)) -- state size: (ndf) x 64 x 64 local netD_pred = nn.Sequential() -- input pred: (nc) x 64 x 64, going into a convolution netD_pred:add(SpatialConvolution(nc, ndf, 5, 5, 2, 2, 2+32, 2+32)) -- 32: to keep scaling of features same as context -- state size: (ndf) x 64 x 64 local netD_pl = nn.ParallelTable(); netD_pl:add(netD_ctx) netD_pl:add(netD_pred) netD:add(netD_pl) netD:add(nn.JoinTable(2)) netD:add(nn.LeakyReLU(0.2, true)) -- state size: (ndf * 2) x 64 x 64 netD:add(SpatialConvolution(ndf*2, ndf, 4, 4, 2, 2, 1, 1)) netD:add(SpatialBatchNormalization(ndf)):add(nn.LeakyReLU(0.2, true)) -- state size: (ndf) x 32 x 32 else -- input is (nc) x 64 x 64, going into a convolution netD:add(SpatialConvolution(nc, ndf, 4, 4, 2, 2, 1, 1)) netD:add(nn.LeakyReLU(0.2, true)) -- state size: (ndf) x 32 x 32 end
train.lua中分别得到生成器和判别器的网络结构,然后准备数据,进行训练。这里选择判别器的网络结构代码分析。
网络结构中用到了nn.ParallelTable(),向介绍下torch中nn.Sequential,nn.Concat/ConcatTable,nn.Parallel/PararelTable之间的区别。
那么为什么生成器和判别器都需要用到nn.ParallelTable呢?即对每个成员模块应用与之对应的输入(第i个模块应用第i个输入)
我的理解:生成器需要将输入图像和noise输入到生成器中得到预测的图像;而判别器需要将真实的图像和预测的图像输入到判别器中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号