
【总结】GoogLeNet详解
接下来简单聊聊GoogLeNet的一些创新点:
1. NetWork In NetWork和1x1卷积
顾名思义,1x1卷积就是卷积核大小为1。第一反应就是:给特征响应图的每个值都乘了同一个系数。如果是一通道输入,一通道输出的情况下确实如此,但是对于多通道输入,多通道输出的情况就不同了。如下图所示:

图:1x1 卷积示意图
图中画出的是一组m通道的特征响应图通过1x1卷积得到n通道的新的n通道的特征响应示意图。我们关注特征图上某一位置的像素,或者说是同一位置的一组m个像素,经过1x1卷积后再对应位置会得到一组新的n个像素。所以如果只看特征图上指定位置的像素的话,其实就是一个全连接层,我们用xi表示第i个输入通道上指定位置的像素值,xj'表示第j个输出通道对应位置的像素值,则公式表示如下:
xj' = wj1x1 + wj2x2 + ... + wjmxm + bj = wjxT + bj
其中x=(x1,x2,...,xm)是把所有对应位置的像素看作是一个向量,进一步考虑所有输出通道对应位置像素的向量: x' = [w1 w2 ... wn]*xT + b
因为卷积核是对每位置像素进行同样的操作,所以1x1卷积相当于对所有的输入特征响应图做了一次线性组合,然后输出新的一组特征响应图。特别是如果m>n的情况下,通过训练之后相当于降维,这样再接新的卷积层就只需要在更少的n个通道上做卷积,节省了计算资源。
NIN论文里还提出了另外一种被广泛应用的方法叫做全局平均池化(Global Average Pooling),就是对最后一层卷积的响应图,每个通道求整个响应图的均值,这个就是全局池化。然后再接一层全连接,因为全局池化后的指相当于一像素,所以最后的全连接其实就成了一个加权相加的操作。这种结构比起直接的全连接更直观,并且泛化性能更好,成功运用到GoogLeNet当中。
2. Inception结构
如果把NIN结构中卷积+激活看作是一种广义线性模型,那么Inception就是用更有效的结构代替单纯的卷积+激活操作。Inception示意图如下:
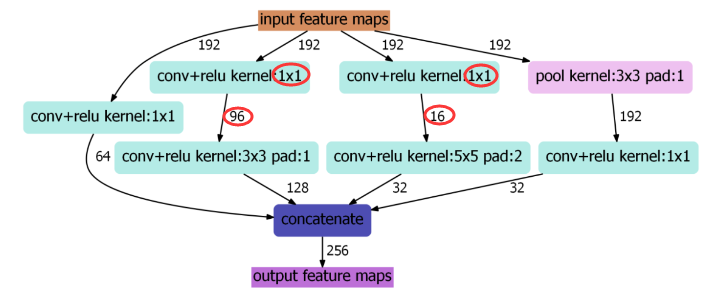
图:Inception结构示意图
通过上图可以看到,Inception主要做了两件事:第一件事是通过3x3池化,以及1x1,3x3和5x5这三种不同尺度的卷积核,一共四种方式对输入的特征响应图做特征抽取。第二件事是为了降低计算量,同时让信息通过更少的连接传递已达到更加稀疏的特性,采用1x1卷积核进行降维。上图可以看到,对于计算量略大的3x3卷积,把192通道的特征响应图降到了原来的一半96通道,而对于更大计算量的5x5卷积,则降到了16通道。
3.网络结构
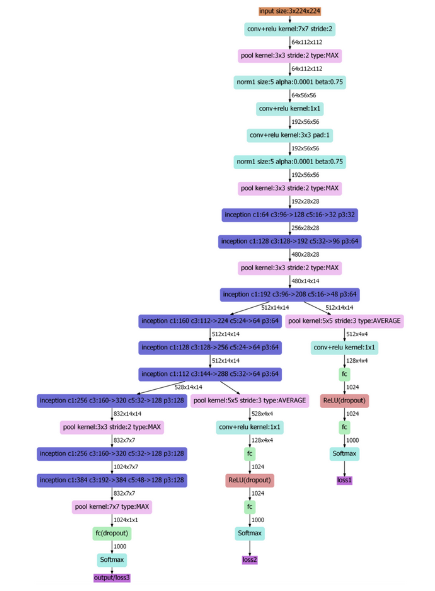
图:GoogLeNet结构示意图
首先注意到的是结构中出来了3个loss单元,也就是训练中计算代价函数的对应单元。这样做的目的是为了帮助网络的收敛。虽然ReLU单元能够一定程度解决梯度消失问题,但是并不能完全解决深层网络难以训练的问题(其一是信息传播中伴随着信息丢失,其二是梯度下降本质对函数做近似一阶线性近似),所以越是远离最后输出的层,就会不如靠近输出的层训练得好。在中间层加入辅助计算loss的单元,目的是计算损失的时候让低层的特征也有很好的区分能力,从而让网络更好的训练,而且低层学到了更好的特征也能加速整个网络的收敛。在论文中,这两个辅助loss(loss1,loss2)的计算被乘以系数0.3,然后和最后的loss(loss3)相加作为最终的损失函数来训练网络。其次还有一点就是把AlexNet中最后两层的全连接改为全局平均池化+一层全连接。通过这种方式去掉一层全连接后,不仅参数的数量减少了很多,而且模型准确率还有提升(论文中是0.6%)。
4.批规一化BN(Batch Normation,BN)
归一化的标准流程是减均值和除方差。看图理解一下:
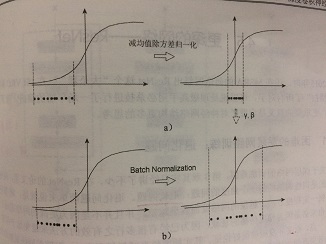
图:批规一化理解
上图左边是没有任何处理的输入数据,曲线是激活函数的曲线,比如Sigmoid。如果数据在如图所示梯度很小的区域,那么学习速率就会很慢甚至陷入长时间的停滞。减去均值再除以方差之后,数据被移到了中心区域,这个区域的梯度都是最大的或是有梯度的,这可以看作是一种对抗梯度消失的手段。如果对于每一层数据都这么操作,那么数据的分布就总是在随输入变化敏感的区域,相当于不用考虑数据分布变化,这样训练起来效率就高多了。不过有时候数据本身就不对称,那么这样的非线性变换有可能不能很好的体现,再加上最后一步:yi <- αxi + β (其中α,β是两个需要学习的参数),所以其实BN的本质就是利用优化变一下方差大小和均值的位置。当然训练模型时,数据分布的均值和方差尽可能贴近所有数据的分布,所以在训练过程中记录大量数据的均值和方差,得到整个训练样本的均值和方差期望值,训练结束后作为最后使用的均值和方差。
总结一下GoogLeNet的优点:
1.使用1x1卷积(进一步融合各个通道的特征;降维减少计算量)
2.使用Inception结构(使用四种方式对特征进行提取;使用1x1卷积降维,减少计算量)
3.结构优化(辅助loss1,loss2,目的让低层特征也有很好的区分能力;使用全局最大池化和一层全连接层代替原来的两层全连接层)
4.批规一化(使用BN操作优化均值大小和方差使得训练模型时数据尽量贴近所有数据的分布,可以用来作为对抗梯度消失的一种手段。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号