
半小时学会卷积神经网络
觉得这篇关于卷积神经网络讲的比较全面清晰易懂。
原文链接:https://zhuanlan.zhihu.com/p/30504700?utm_medium=social&utm_source=wechat_timeline&from=timeline&isappinstalled=0
(文中有些内容可能不是很清晰,会加上一些自己的理解,用红色字体标出,后续不断更新。)
以全连接层为基础的深度神经网络是深度神经网络的基石,要说应用最广、影响最大的深度神经网络,那非卷积神经网络莫属。在本文中全面阐述卷积神经网络。卷积神经网络虽然发布的时间较早,但直到2006年Hilton解决深度神经网络的训练问题后才焕发生机。卷积神经网络现在几乎是图像识别研究的标准配置。
简单回顾卷积神经网络的发展历程。日本科学家福岛邦彦(Kunihiko Fukushima)在1986年提出Neocognitron(神经认知机),直接启发了后来的卷积神经网络。Yann LeCun于1998年提出的卷积神经LeNet,首次提出了多层级联的卷积结构,可对手写数字进行有效识别。2012年, Alex依靠卷积神经网络AlexNet夺得ILSVRC 2012比赛的冠军,吹响了卷积神经网络研究的号角。AlexNet成功应用了ReLu、Dropout、最大池化、LRN(Local Response Normalization,局部响应归一化)、GPU加速等新技术,启发了后续更多的技术创新,加速了卷积神经网络和深度学习的研究。从此,深度学习研究进入蓬勃发展的新阶段。2014年Google提出的GoogleNet,运用Inception Module这个可以反复堆叠高效的卷积网络结构,获得了当年的ImageNet ILSVRC比赛的冠军,同年的亚军VGGNet全程使用3×3的卷积,成功训练了深度达19层的网络。2015年,微软提出了ResNet,包含残差学习模块,成功训练了152层的网络,一举拿下当年ILSVRC比赛的冠军。
卷积神经网络技术的发展风起云涌,尽管卷积神经网络(convolutional neural network, CNN)最初是为解决计算机视觉等问题设计的,现在其应用范围不仅仅局限于图像和视频领域,也可用于音频信号等。本文主要通过卷积神经网络在计算机视觉上应用来讲解卷积神经网络的基本原理以及如何使用PyTorch实现卷积神经网络。
首先介绍人类视觉和计算机视觉的基本原理,计算机视觉中特征提取和选择。然后介绍卷积神经网络的主体思想和整体结构,并将详细讲解卷积层和池化层的网络结构,PyTorch对这些网络结构的支持,如何设置每一层神经网络的配置,以及更加复杂的卷积神经网络结构,如AlexNet, VGGNet , ResNet等。最后在MNIST数据集上通过PyTorch实现卷积神经网络。
1 计算机视觉
1.1 人类视觉和计算机视觉
视觉是人类观察和认识世界非常重要的手段。据统计,人类从外部世界获取的信息约80%从视觉获取,这既说明视觉信息量巨大,又体现了视觉功能的重要性。同时,人类视觉是如此的功能强大,在很短的时间里,迅速地辨识视线里的物体,在人的视觉系统中,人的眼睛捕捉物体得到光信息。这些光信息经过处理,运送到大脑的视觉皮层,分析得到以下信息:有关物体的空间、色彩、形状和纹理等。有了这些信息,大脑作出对该物体的辨识。对于人类而言,通过视觉来识别数字、识别图片中的物体或者找出图片中人脸的轮廓是非常简单的任务。然而对于计算机而言,让计算机识别图片中的内容就不是一件容易的事情。计算机视觉希望借助计算机程序来处理、分析和理解图片中的内容,使得计算机可以从图片中自动识别各种不同模式的目标和对象。
在深度学习出现之前,图像识别的一般过程,前端是特征提取,后端是模式识别算法。后端的模式识别算法包括:K近邻算法(K-Nearest Neighbors)、支持向量机(SVM),神经网络等。对于不同的识别场景和越来越复杂的识别目标,寻找合适的前端特征显得尤为重要。
1.2 特征提取
对于特征提取,抽象于人的视觉原理,提取有关轮廓、色彩、纹理、空间等相关的特征。以色彩为例,它是一种现在仍然在广泛使用的特征,称之为颜色直方图特征,这是一种简单、直观,对实际图片颜色进行数字化表达的方式。颜色的值用RGB三原色进行表示,颜色直方图的横轴表示颜色的RGB值,表示该物品所有颜色的集合,纵轴表示整个图像具有某个颜色值像素的数量,这样,计算机就可以对图像进行颜色表征。
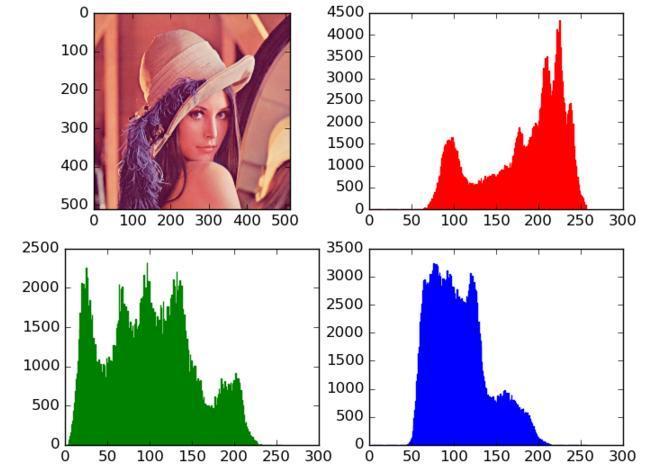
图1 颜色直方图
以纹理特征为例,桔子会有凸凹不平的纹理,而苹果的纹理则非常光滑。这种局部的纹理刻画,如何通过特征抽象表示出来?Gabor 特征可以用来描述图像纹理信息的特征,Gabor 滤波器的频率和方向与人类的视觉系统类似,特别适合于纹理表示与判别。SIFT(Scale Invariant Feature Transform)特征全称尺度不变特征变换,是一种检测局部特征的算法,该算法通过把图中特征点用特征向量进行描述,该特征向量具有对图像缩放、平移、旋转不变的特性,对于光照、仿射和投影变换也有一定的不变性。

图2 Garbor特征示意图
形状特征也是图像特征的重要一类,HOG(Histogram of Oriented Gradients)特征就是其中一种。HOG特征是一种描述图像局部梯度方向和梯度强度分布的特征。其核心内容是:在边缘具体位置未知的情况下,边缘方向的分布也可以很好地表示目标的外形轮廓。

图3 HOG特征检测示意图
上述特征提取算法提取的特征还是有局限的,尽管在颜色为黑白的数据集MNIST上的最好结果错误率为0.54%,但是在大型和复杂的数据ImageNet ILSVRC比赛的最好结果的错误率也在26%以上,而且难以突破。同时,提取的特征只在特定的场合有效,场景变化后,需要重新提取特征和调整模型参数。卷积神经网络能够自动提取特征,不必人为地提取特征,这样提取的特征能够达到更好的效果。同时,它不需要将特征提取和分类训练两个过程分开,在训练的过程自动地提取特征,循环迭代,自动选取最优的特征。
1.3 数据集
卷积神经网络的成功,计算机视觉领域的几大数据集可谓功不可没。在计算机视觉中有以下几大基础数据集。
1) MNIST
MNIST数据集是用作手写体识别的数据集。MNIST数据集包含60000张训练图片,10000张测试图片。其中每一张图片都是0~9中的一个数字。图片尺寸为28×28。由于数据集中数据相对比较简单,人工标注错误率仅为0.2%。

图4 MNIST数据集样例
2) Cifar数据集
Cifar数据集是一个图像分类数据集。Cifar数据集分为了Cifar-10和Cifar-100两个数据集。Cifar数据集中的图片为32×32的彩色图片,这些图片是由Alex Krizhenevsky教授、Vinod Nair博士和Geoffrey Hilton教授整理的。Cifar-10数据集收集了来自10个不同种类的60000张图片,这些种类有:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。在Cifar-10数据集上,人工标注的正确率为94%。

图5 Cifar数据集样例
3) ImageNet数据集
ImageNet数据集是一个大型图像数据集,由斯坦福大学的李飞飞教授带头整理而成。在ImageNet中,近1500万张图片关联到WordNet中20000个名次同义词集上。ImageNet每年举行计算机视觉相关的竞赛—Image Large Scale Visual Recognition Challenge(ILSVRC), ImageNet的数据集涵盖计算机视觉的各个研究方向,其用做图像分类的数据集是ILSVRC2012图像分类数据集。ILSVRC2012数据集的数据和Cifar-10数据集一致,识别图像中主要物体,其包含了来自1000个种类的120万张图片,每张图片只属于一个种类,大小从几千字节到几百万字节不等。卷积神经网络也正是在此数据集上一战成名。

图6 ImageNet数据集样例
2 卷积神经网络
计算机视觉作为人工智能的重要领域,在2006年后取得了很多突破性的进展。本文介绍的卷积神经网络就是这些突破性进展背后的技术基础。在前面章节中介绍的神经网络每两层的所有节点都是两两相连的,所以称这种网络结构为全连接层网络结构。可将只包含全连接层的神经网络称之为全连接神经网络。卷积神经网络利用卷积结构减少需要学习的参数量,从而提高反向传播算法的训练效率。在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一个卷积操作只处理一小块图像,进行卷积操作后传递到后面的网络,每一层卷积都会提取数据中最有效的特征。这种方法可以提取到图像中最基础的特征,比如不同方向的拐角或者边,而后进行组合和抽象成更高阶的特征,因此卷积神经网络对图像缩放、平移和旋转具有不变性。
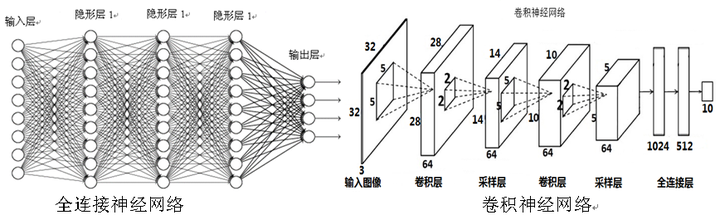
图7全连接神经网络和卷积神经网络结构示意图
在图像处理中,图像是一个或多个的二维矩阵,如之前文中提到的MNIST手写体图片是一个28×28的二维矩阵。传统的神经网络都是采用全连接的方式,即输入层到隐藏层的神经元都是全部连接的,这样导致参数量巨大,使得网络训练耗时甚至难以训练,并容易过拟合,而卷积神经网络则通过局部连接、权值共享等方法避免这一困难。
对于一个200×200的输入图像而言,如果下一个隐藏层的神经元数目为10^4个,采用全连接则有200×200×10^4 = 4×10^8个权值参数,如此数目巨大的参数几乎难以训练;而采用局部连接,隐藏层的每个神经元仅与图像中4×4的局部图像相连接,那么此时的权值参数数量为4×4×10^4 = 1.6×10^5,将直接减少3个数量级。
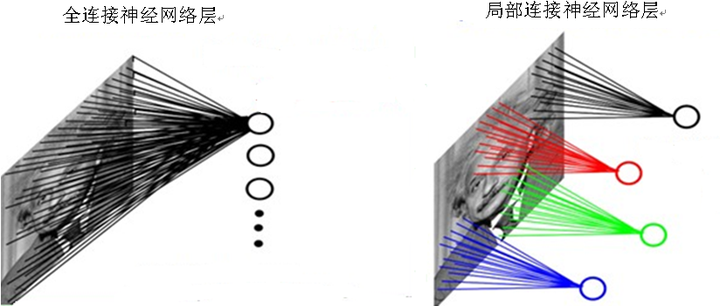
图8全连接神经网络和局部连接网络
尽管减少了几个数量级,但参数数量依然较多。能否再进一步减少参数?方法就是权值共享。一个卷积层可以有多个不同的卷积核,而每一个卷积核都对应一个滤波后映射出的新图像,同一个新图像中每一个像素都来自完全相同的卷积核,就就是卷积核的权值共享。具体做法是,在局部连接中隐藏层的每一个神经元连接的是一个4×4的局部图像,因此有4×4个权值参数,将这4×4个权值参数共享给剩下的神经元,也就是说隐藏层中4×10^4个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 4×4个权值参数(也就是卷积核的大小),如图9所示。
(我觉得这里说的权值共享就是每一层神经层layer的所有神经元的权重都是一样的,而不管隐藏层神经元的数目。当然也有同一层不同神经元节点采用权值是不同的,我倒觉得这种是大多数的。)
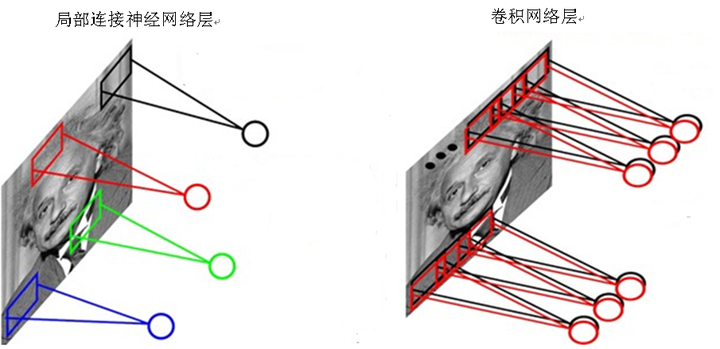
图9 局部连接神经网络和卷积
这大概就是卷积神经网络的神奇之处,尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,可以增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为特征映射。如果有100个卷积核,最终的权值参数也仅为100×100=10^4个而已。另外,偏置参数也是共享的,同一种滤波器共享一个。
总结一下,卷积神经网络的要点就是卷积层中的局部连接、权值共享、和池化层中降采样。局部连接、权值共享和降采样降低了参数量,使得训练复杂度大大降低,并减轻了过拟合的风险。同时还赋予了卷积神经网络对平移、形变、尺度的某种程度的不变性,提高了模型的泛化能力。
一般的卷积神经网络由以下几个层组成:卷积层,池化层,全连接层,Softmax层。这四者构成了常见的卷积神经网络。
1.卷积层。 卷积层是一个卷积神经网络最重要的部分,也是卷积神经网络得名的缘由。卷积层中每一个节点的输入是上一层神经网络的一小块,卷积层试图将神经网络中的每一个小块进行更加深入地分析从而得到抽象程度更高的特征。
2.池化层。池化层的神经网络不会改变三维矩阵的深度,但是它将缩小矩阵的大小。池化层操作将分辨率较高的图片转化为分辨率较低的图片。
3.全连接层。 经过多轮的卷积层和池化层处理后,卷积神经网络一般会接1到2层全连接层来给出最后的分类结果。
4.Softmax层。Softmax层主要用于分类问题。
在卷积神经网络中用到全连接层和Softmax层在前面章节已有详细的介绍,这里不作赘述。在下面的2.1节和2.2节中将详细介绍卷积神经网络中特殊的两个网络结构—卷积层和池化层及具体参数的计算。
2.1 卷积层
图10显示了卷积层神经网络结构中最重要的部分,这个称之为过滤器(filter)或者卷积核(kernel),在PyTorch文档将这个结构称为卷积核(kernel),因此在本书中将统称这个结构为卷积核。如图10所示,卷积核将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个节点矩阵。
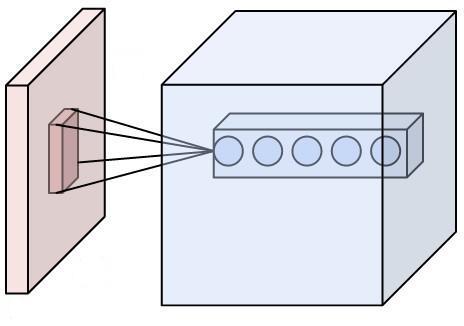
图10 卷积核结构示意图
在卷积层中,卷积核所处理的节点矩阵的长、宽都是人工指定的,这个节点矩阵的尺寸称之为卷积核的尺寸。卷积核处理的深度和当前层的神经网络节点矩阵的深度是一致的,即便节点矩阵是三维的,卷积核的尺寸只需指定两个维度。一般地,卷积核的尺寸是3×3和5×5。在图10中,左边表示输入的数据,输入数据的尺寸为3×32×32(注意:在PyTorch中,数据输入形式表示3×32×32),中间表示卷积核,右边每一个小圆点表示一共神经元,图中有5个神经元。假设卷积核尺寸为5×5,卷积层中每个神经元会有输入数据中3×5×5区域的权重,一共75个权重。这里再次强调下卷积核的深度必须为3,和输入数据保持一致。
在卷积层,还需说明神经元的数量,它们的排列方式、滑动步长、以及边界填充。
首先,神经元的数量,就是卷积层的输出深度,形如图10的5个神经元,该参数是用户指定的,它和使用的滤波器数量一致。
其次,卷积核进行运算时,必须指定滑动步长。比如步长为1,说明卷积核每次移动1个像素点。当步长为2,卷积核会滑动2个像素点。滑动的操作使得输出的数据变得更少。
最后,介绍边界填充。边界填充如果为0,可以保证输入和输出在空间上尺寸一致;如果边界填充大于0,可以确保在进行卷积操作时,不损失边界信息。
那么,输出的尺寸最终如何计算?在PyTorch中,可以用一个公式来计算,就是floor((W-F+2P)/ S + 1)。其中,floor 表示下取整操作,W表示输入数据的大小,F表示卷积层中卷积核的尺寸,S表示步长,P表示边界填充0的数量。比如输入是5×5,卷积核是3×3,步长是1,填充的数量是0,那么根据公式,就能得到(3+2×0)/ 1 + 1 = 3,输出的空间大小为3×3;如果步长为2,那么(3+2×0)/ 2 + 1 = 2,输出的空间大小为2×2。
在图11中,以一维空间来说明卷积操作,右上角表示神经网络的权重,其中输入数据的大小为5,卷积核的大小为3;左边表示滑动步长为1,且填充也为1;右边表示滑动步长为2,填充为1。
(这里其实是下面是输入数据,经过卷积核处理后得到上面的输出,与上面解释稍有不同。)

图11一维空间上的卷积操作
在PyTorch中, 类nn.Conv2d()是卷积核模块。卷积核及其调用例子如下:
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0,dilation=1,groups=1, bias=True)
一般地,其调用如下:
# With square kernels and equal stride
m = nn.Conv2d(16, 33, 3, stride=2)
# non-square kernels and unequal stride and with padding
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2))
# non-square kernels and unequal stride and with padding and dilation
m = nn.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1))
nput = autograd.Variable(torch.randn(20, 16, 50, 100))
output = m(input)
nn.Conv2d中参数含义:in_channels表示输入数据体的深度;out_channels表示输出数据体的深度;kernel_size 表示卷积核的大小;stride表示滑动的步长;padding表示边界0填充的个数;dilation表示输入数据体的空间间隔;groups 表示输入数据体和输出数据体在深度上的关联;bias 表示偏置。
2.2 池化层
通常会在卷积层后面插入池化层,其作用是逐渐降低网络的空间尺寸,达到减少网络中参数的数量,减少计算资源的使用的目的,同时也能有效地控制过拟合。
池化层一般有两次方式:Max Pooling 和 Mean Pooling。以下以Max Pooling来说明池化层的具体内容。池化层操作不改变模型的深度,对输入数据体在深度上的切片作为输入,不断地滑动窗口,取这些窗口的最大值作为输出结果,减少它的空间尺寸。池化层的效果如图12所示。
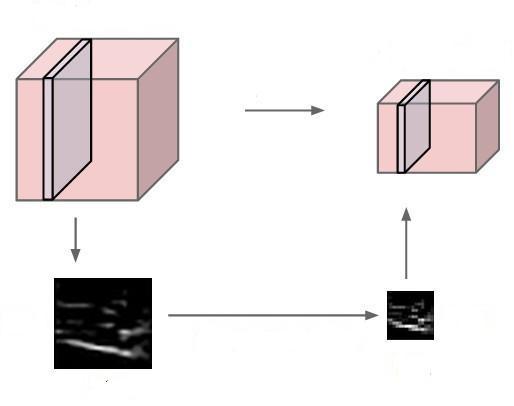
图12池化层的处理效果
图13说明池化层的具体计算,以窗口大小是2,滑动步长是2为例:每次都从2x2的窗口中选择最大的数值,同时每次滑动2个步长进入新的窗口。
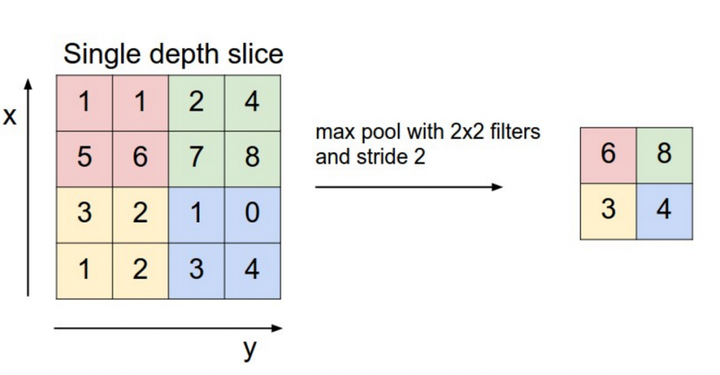
图13池化层计算
池化层为什么有效?图片特征具有局部不变性,也就是说,即便通过下采样也不会丢失图片拥有的特征。由于这种特性,可以将图片缩小再进行卷积处理,这样能够大大地降低卷积计算的时间。最常用的池化层尺寸是2x2,滑动步长为2,对图像进行下采样,将其中75%的信息丢弃,选择其中最大的保留下来,这样也达到去除一些噪声信息的目的。
在PyTorch中,池化层是包括在类nn.MaxPool2d和nn.AvgPoo2d。下面介绍一下nn.MaxPool2d及其调用例子。其调用如下
nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1,
return_indices=False,ceil_mode=False)
一般地,用法可如下
# pool of square window of size=3, stride=2
m = nn.MaxPool2d(3, stride=2)
# pool of non-square window
m = nn.MaxPool2d((3, 2), stride=(2, 1))
input = autograd.Variable(torch.randn(20, 16, 50, 32))
output = m(input)
nn.MaxPool2d中各个参数的含义。其中,kernel_size, stride,padding, dilation在nn.Conv2d中已经解释过。return_indices表示是否返回最大值所处的下标;ceil_model表示使用方格代替层结构。
2.3 经典卷积神经网络
下面讲述三种经典的卷积神经网络:LeNet 、AlexNet 、VGGNet。这三种卷积神经网络的结构不算特别复杂,有兴趣的也可以去了解下GoogleNet和ResNet。
1. LeNet
LeNet具体指的是LeNet-5。LeNet-5模型是Yann LeCun教授于1998年在论文Gradient-based
learning
applied to document
recognition中提出的,它是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据集上,LeNet-5模型可以达到大约99.2%的正确率。LeNet-5模型总共有7层,包括有2个卷积层,2个池化层,2个全连接层和一个输出层,图14展示了LeNet-5模型的架构。
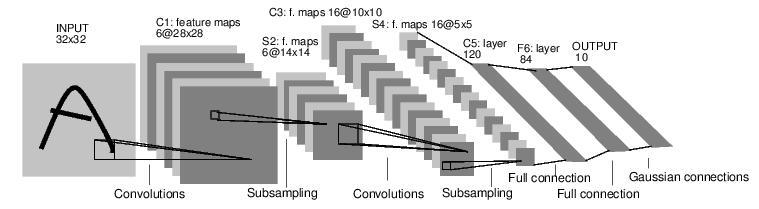
图14 LeNet-5模型结构图
论文提出的LeNet-5模型中,卷积层和池化层的实现与PyTorch的实现有细微的区别,这里不过多的讨论具体细节。
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
out = F.relu(self.conv1(x))
out = F.max_pool2d(out, 2)
out = F.relu(self.conv2(out))
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
2.AlexNet
2012年, Hilton的学生Alex Krizhevsky提出了卷积神经网络模型AlexNet。AlexNet在卷积神经网络上成功地应用了Relu,Dropout和LRN等技巧。在ImageNet竞赛上,AlexNet以领先第二名10%的准确率而夺得冠军。成功地展示了深度学习的威力。它的网络结构如下:
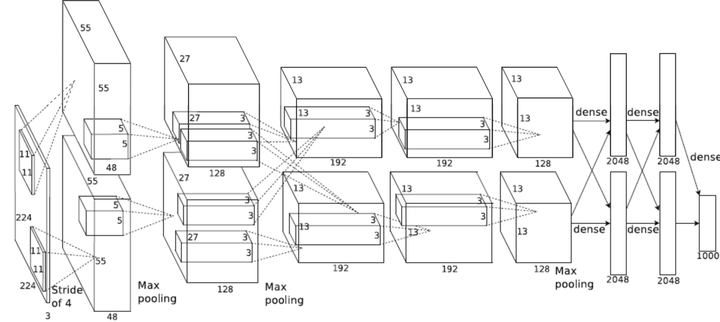
图15 AlexNet模型结构图
图15看起来有点复杂,这是由于当时GPU计算能力不强,AlexNet使用了两个GPU并行计算,现在可以用一个GPU替换。以单个GPU的AlexNet模型为例,包括有:5个卷积层,3个池化层,3个全连接层。其中卷积层和全连接层包括有relu层,在全连接层中还有dropout层。具体参数的配置可以参看图16。
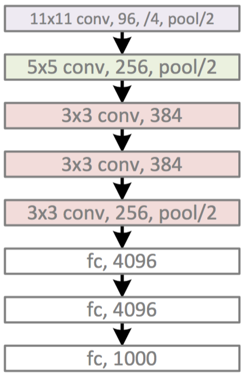
图16 AlexNet 网络结构精简版
具体参数的配置可以参看具体的PyTorch源码。
下面给出PyTorch的程序实现AlexNet模型的卷积神经网络。
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 256, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
3. VGGNet
VGGNet是牛津大学计算机视觉组和Google DeepMind公司的研究人员一起研发的一种卷积神经网络。通过堆叠3×3 的小型卷积核和2×2的最大池化层,VGGNet成功地构筑了最深达19层的卷积神经网络。VGGNet取得了2014年Image NET 比赛的第二名,由于VGGNet的拓展性强,迁移到其他图片数据上的泛化性比较好,可用作迁移学习。表1显示了VGGNet各级别的网络结构图。虽然从A到E每一级网络逐渐变深,但是网络的参数量并没有增长很多,因为参数量主要都消耗在最后3个全连接层。前面的卷积层参数很深,参数量并不是很多,但是在训练时计算量大,比较耗时。D和E模型就是VGGNet-16和VGGNet-19。
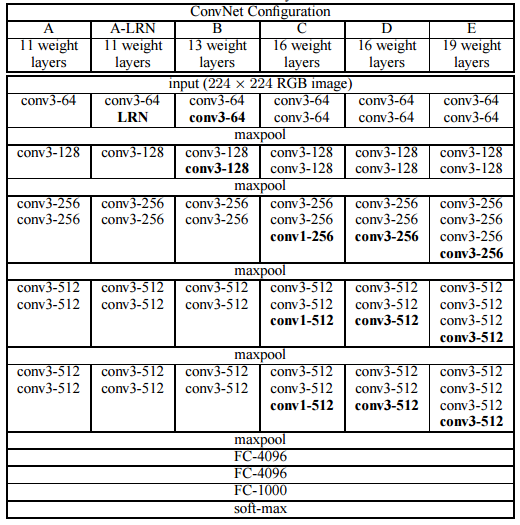
表1 VGGNet模型各级别网络结构图
下面给出PyTorch的程序实现VGGNet模型的卷积神经网络。
cfg = {
'VGG11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'VGG16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'VGG19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
class VGG(nn.Module):
def __init__(self, vgg_name):
super(VGG, self).__init__()
self.features = self._make_layers(cfg[vgg_name])
self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
def _make_layers(self, cfg):
layers = []
in_channels = 3
for x in cfg:
if x == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1),
nn.BatchNorm2d(x),
nn.ReLU(inplace=True)]
in_channels = x
layers += [nn.AvgPool2d(kernel_size=1, stride=1)]
return nn.Sequential(*layers)
3 MNIST数据集上卷积神经网络的实现
本节讲解如何使用PyTorch实现一个简单的卷积神经网络,使用的数据集是MNIST,预期可以达到97.05%左右的准确率。该神经网络由2个卷积层和3个全连接层构建,读者通过这个例子可以掌握设计卷积神经网络的特征以及参数的配置。
1. 配置库和配置参数
#coding=utf-8
#配置库
import torch
from torch import nn, optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
# 配置参数
torch.manual_seed(1) #设置随机数种子,确保结果可重复
batch_size = 128 #批处理大小
learning_rate = 1e-2 #学习率
num_epoches = 10 #训练次数
2. 加载MINSIT数据
# 下载训练集 MNIST 手写数字训练集
train_dataset = datasets.MNIST(
root='./data', #数据保持的位置
train=True, # 训练集
transform=transforms.ToTensor(),# 一个取值范围是[0,255]的PIL.Image
# 转化为取值范围是[0,1.0]的torch.FloadTensor
download=True) #下载数据
test_dataset = datasets.MNIST(
root='./data',
train=False, # 测试集
transform=transforms.ToTensor())
3. 数据的批处理
#数据的批处理,尺寸大小为batch_size,
#在训练集中,shuffle 必须设置为True, 表示次序是随机的
train_loader =
DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader =
DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
4. 创建CNN模型
和以前一样, 我们用一个类来建立 CNN 模型. 这个 CNN 整体流程是 卷积(Conv2d) -> 激励函数(ReLU) -> 池化, 向下采样 (MaxPooling) -> 再来一遍 -> 展开多维的卷积成的特征图 -> 接入全连接层 (Linear) -> 输出。
# 定义卷积神经网络模型
class Cnn(nn.Module):
def __init__(self, in_dim, n_class): # 1x28x28
super(Cnn, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_dim, 6, 3, stride=1, padding=1), #28 x 28
nn.ReLU(True),
nn.MaxPool2d(2, 2), # 14 x 14
nn.Conv2d(6, 16, 5, stride=1, padding=0), # 16 x 10 x 10
nn.ReLU(True), nn.MaxPool2d(2, 2)) # 16x5x5
self.fc = nn.Sequential(
nn.Linear(400, 120), # 400 = 16 x 5 x 5
nn.Linear(120, 84),
nn.Linear(84, n_class))
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), 400) # 400 = 16 x 5 x 5
out = self.fc(out)
return out
model = Cnn(1, 10) # 图片大小是28x28, 10是数据的种类
打印模型,呈现网络结构
print(model)
5. 训练
下面我们开始训练, 将 img, label 都用 Variable 包起来, 然后放入 model 中计算 out, 最后再计算less和正确率.
# 定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 开始训练
for epoch in range(num_epoches):
running_loss = 0.0
running_acc = 0.0
for i, data in enumerate(train_loader, 1): #批处理
img, label = data
img = Variable(img)
label = Variable(label)
# 前向传播
out = model(img)
loss = criterion(out, label) # loss
running_loss += loss.data[0] * label.size(0) # total loss , 由于loss 是batch 取均值的,需要把batch size 乘回去
_, pred = torch.max(out, 1) # 预测结果
num_correct = (pred == label).sum() #正确结果的num
#accuracy = (pred == label).float().mean() #正确率
running_acc += num_correct.data[0] # 正确结果的总数
# 后向传播
optimizer.zero_grad() #梯度清零,以免影响其他batch
loss.backward() # 后向传播,计算梯度
optimizer.step() #利用梯度更新 W ,b参数
#打印一个循环后,训练集合上的loss 和正确率
print('Train {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(
train_dataset))))
6. 在测试集测试识别率
#模型测试,
model.eval() #由于训练和测试 BatchNorm, Dropout配置不同,需要说明是否模型测试
eval_loss = 0
eval_acc = 0
for data in test_loader: #test set 批处理
img, label = data
img = Variable(img, volatile=True) # volatile 确定你是否不调用.backward(), 测试中不需要
label = Variable(label, volatile=True)
out = model(img) # 前向算法
loss = criterion(out, label) # 计算 loss
eval_loss += loss.data[0] * label.size(0) # total loss
_, pred = torch.max(out, 1) # 预测结果
num_correct = (pred == label).sum() # 正确结果
eval_acc += num_correct.data[0] #正确结果总数
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc * 1.0 / (len(test_dataset))))
最后的训练和测试上loss和识别率分别是:
Train 1 epoch, Loss: 2.226007, Acc: 0.320517
Train 2 epoch, Loss: 0.736581, Acc: 0.803717
Train 3 epoch, Loss: 0.329458, Acc: 0.901117
Train 4 epoch, Loss: 0.252310, Acc: 0.923550
Train 5 epoch, Loss: 0.201800, Acc: 0.939000
Train 6 epoch, Loss: 0.167249, Acc: 0.949550
Train 7 epoch, Loss: 0.145517, Acc: 0.955617
Train 8 epoch, Loss: 0.128391, Acc: 0.960817
Train 9 epoch, Loss: 0.117047, Acc: 0.964567
Train 10 epoch, Loss: 0.108246, Acc: 0.966550
Test Loss: 0.094209, Acc: 0.970500
本文有内容和代码来自网络,侵删。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号