mysql(约束,截取,虚表,截取,字符串连接,别名,模糊查询,子查询,排序,分组)
1. 约束
主键约束:
primary key 非空且唯一
(1).一个表中最多只能有一个主键
(2).多个字段可以联合起来共同做主键(复合主键)
(3).主要使用于id字段
非空约束:
not null 非空
(1)>必填的字段
默认约束:
default 有默认值
唯一约束:
unique key 唯一
(1).不能重复存在的内容
自增长约束
auto_increment 会自动增长
(1).通常和主键绑定,设置自增
(2).自增的值我们可以设置,但不建议; 默认自增是1
外健约束
foreign key 用于多张表
(1).建立外健的表之间数据是相互关联的约束的
(2).InnDB才支持外健设置(数据库的存储引擎)
存储引擎:
- InnoDB
- MyISAM
2.null:null和所有数据相加,结果还是null
ifnull(参数1,参数2):判断参数1字段是否为null,
如果为null,则取参数2的值
3.length,substr,trim
lenggth(字段名):获取指定的字段值得长度
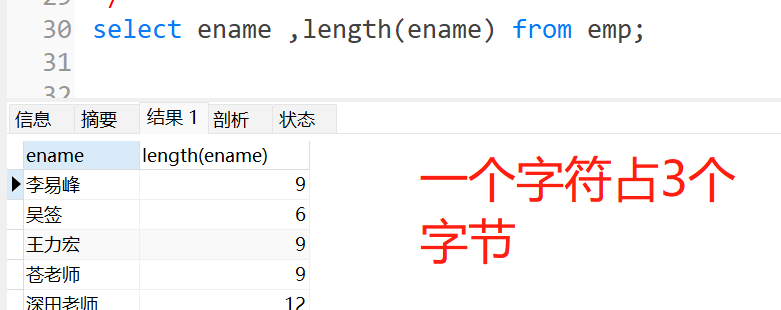
substr(字段名,截取的下标,截取的长度):截取字段(mysql数据库中的截取下标从1开始)
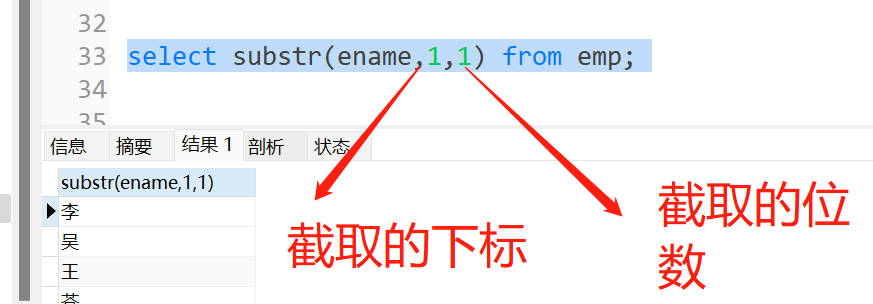
trim():去除两边的空格
ltrim():去除字段左边的空格
rtrim():去除字段右边的空格
dual虚表:不是一个真实存在的表,通常是用来补全语法的
因为查询语句必须接from表名,但是没表名的时候,就可以用dual
4.round,truncate,mod,ceil,floor
round(字段名,保留的小数位):四舍五入
truncate():截取
mod(字段1,字段2):取余 字段1除字段2的余数
ceil(字段):向上取整,取字段的值要大的最小整数
floor(字段):向下取整,取比字段的值要小的最大整数

5.自增长约束,外健约束
- 自增长约束:
1.可以设置步长
set @@auto_increment_increment=2; 设置步长
2.可以设置自增长从指定的数字开始
创建user表,主键从100开始自增
create table user(
id int(4) primary key auto_increment,
name varchar(12),
age int(4)
)auto_increment=100
8.外键约束:可以设置两个表以上
foreign key
- 有外键的表示从表,做关联有主键/唯一约束的字段表叫主表
- 主表中对应的字段数据(必须是设置了主键/唯一约束),保证主表中该字段的值是唯一的,此时在从表中做外键的字段的值必须是主表中有的,否则不能添加
注意:如果想要删除,可以先删从表中对应的数据,让主表该字段的值没有对应了,则可以删除主表字段值.
创建外键的方式:
在建表的时候创建
create table student(
gId int(4),
sname varchar(12),
constraint fk_gid foreign key (gId) references grade(gradeId)
)
在创建表之后,插入数据之前创建外键(使用alter)
alter table student add
constraint fk_gid foreign key (gId) references grade(gradeId)
删除外健
删外健:alter table 表名 drop foreign key 外建名
删索引:alter table 表名 drop index 外健名
注意:删除外健的同时还需要将对应的索引删除(索引和外健名一样)
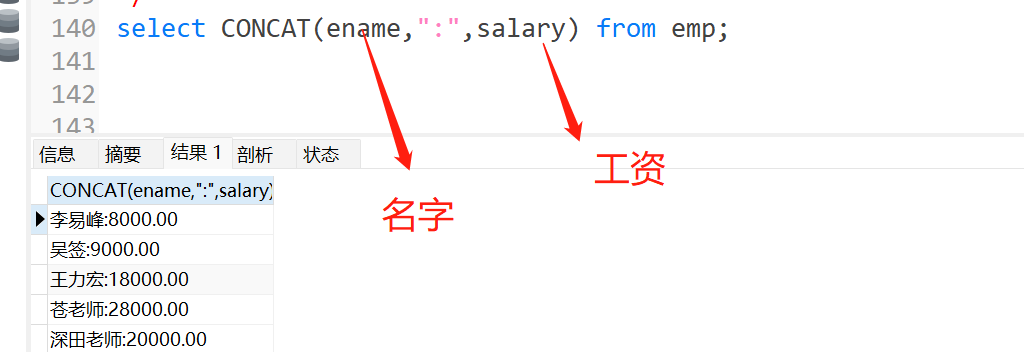
9.concat():字符串连接
10.笛卡尔积:
-笛卡尔积:多个表关联的时候,数据两两相连,会导致表中数据翻倍,在做多表联查的时候,一定要避免笛卡尔积
-
- select * from 表1,表2 where 表1.关联字段=表2.关联字段
注意:在做多表联查的时候,一定要添加where条件,找到几个表之间的关联关系
- select * from 表1,表2 where 表1.关联字段=表2.关联字段
11.别名
- 别名:当表做关联的时候,如果表名或者字段名过长,又或者为了数据的安全,不想让别人看见数据库表中真实的字段,我们可以选择给查询出来的字段起个别名
select e.ename as 姓名,e.deptno as 部门编号,d.dname as 部门名称 FROM dept as d,emp as e where e.deptno=d.deptno
注意:as关键字可省略
select e.ename 姓名,e.deptno 部门编号,d.dname 部门名称 FROM dept d,emp e where e.deptno=d.deptno
12.模糊查询
关键字:like
%:表示任意字符
_:表示单个字符
例如
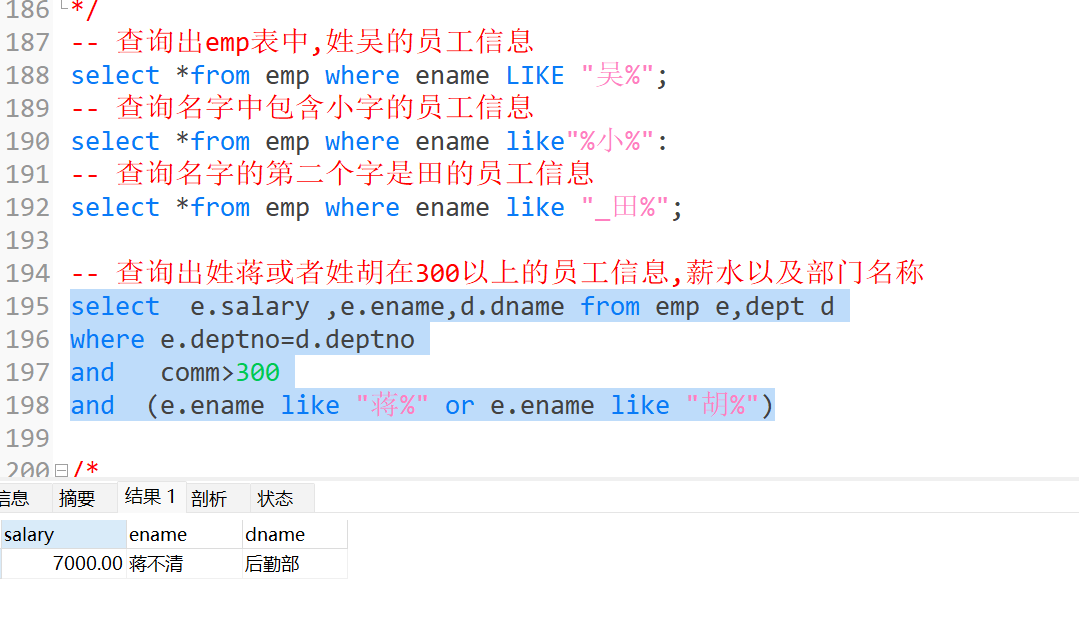
13.in( )
in( ):在...里面 和or相似
例如
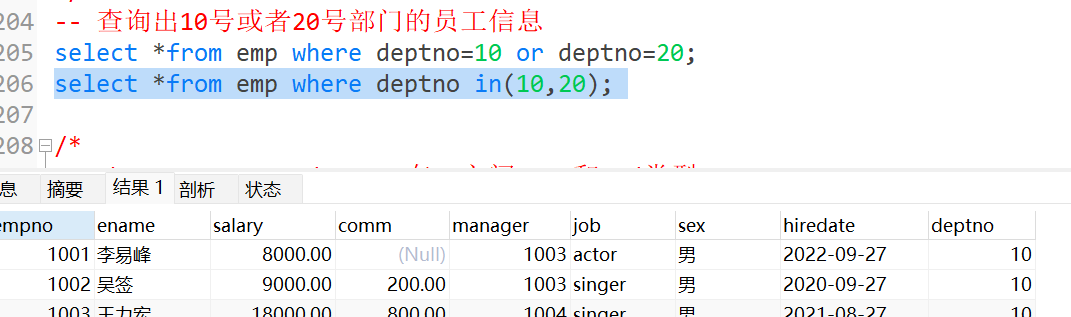
14.between...and -> ..在..之间 和and类型
between A and B
注意:会包含 A 和 B 的值
例如

15.any(任意的),all(所有的)
注意:这两个并不能单独使用,必须搭配>,<一起使用
>all:大于结果集中最小的即可
<all:小于结果集中最大的即可
>any:大于结果集中最大的
<any:小于结果集中最小的
16.子查询
- 查询中还有子查询
![image]()
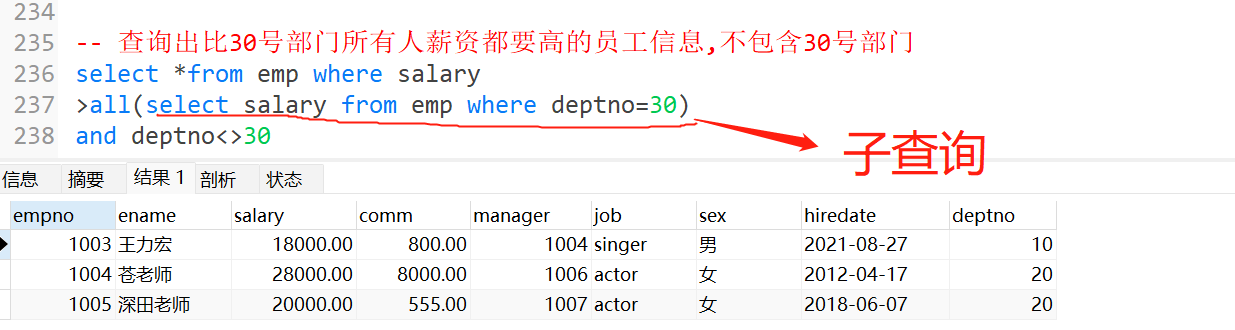
17.distinct ->去重
去除表中重复的数据
例如

18.order by ->排序
- desc:降序
- asc :升序(默认升序)
例如
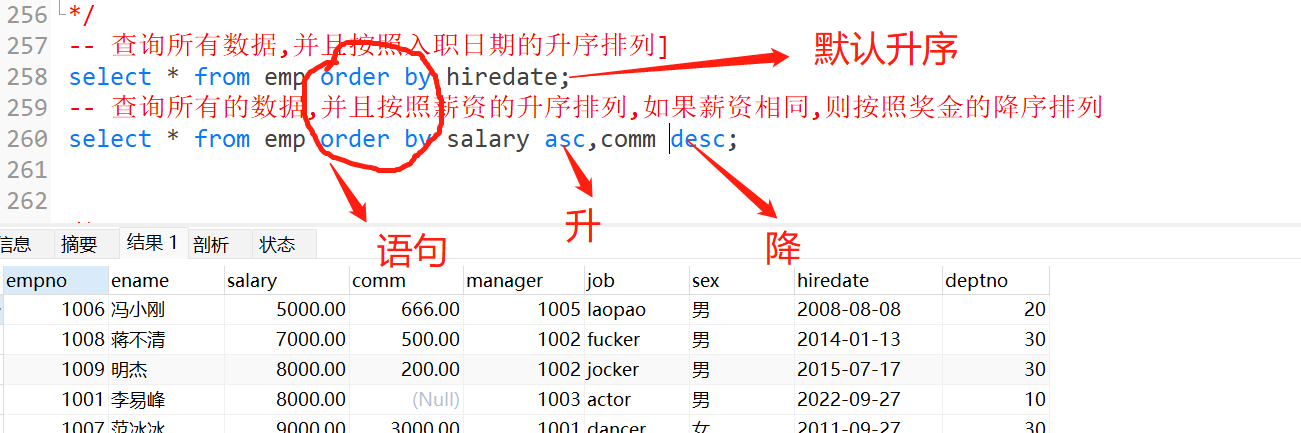
19.聚合函数/多行函数/分组函数:
max( ):最大值
min( ):最小值
avg( ):平均值
sum( ):求和
count( ):统计个数
例如

20.group by ->分组
例如
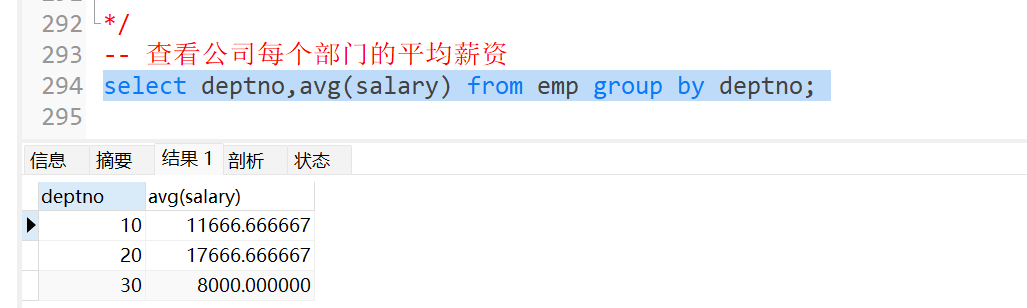
将查询出来的结果集按照某个字段值相同的分为一组,通常和聚合函数连用
注意:group by 后面出现的字段可以出现在select后面,
但是如果group by后面没有出现的字段出现在select后面,则有可能导致查询的结果不正确
当聚合函数出现过滤条件中时,并且有 gruop by 的情况下
我们不能使用where
having:当gruop by 后面需要使用聚合函数过滤条件是,使用having

 浙公网安备 33010602011771号
浙公网安备 33010602011771号