

5.分布式集群
6.3.1 单节点集群
我们在包含一个空节点的集群内创建名为 users 的索引,为了演示目的,我们将分配 3个主分片和一份副本(索引分为三个主分片,每个主分片拥有一个副本分片),整个集群中只有一个节点称为单节点集群
默认情况下,主分片是1,副本是1
此处将es的9200端口改为1001启动,模仿单机节点
#PUT http://127.0.0.1:1001/users
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
集群现在是拥有一个索引的单节点集群。所有 3 个主分片都被分配在 node-1

通过 elasticsearch-head 插件(一个Chrome插件)查看集群情况
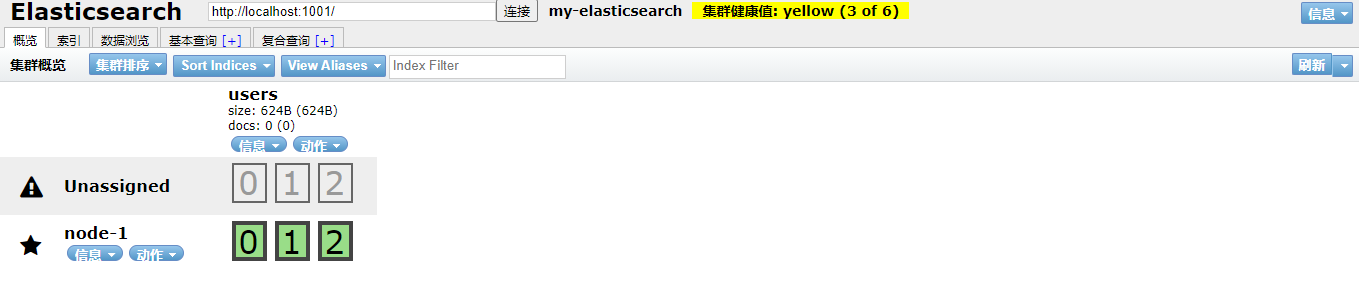
上面这个图片副本标灰,未分配,目前是单节点的,如果你分片数据和副本数据在一起,挂掉数据就全部丢失了,所以是黄色状态,黄色状态容易丢失数据
- 集群健康值:yellow( 3 of 6 ):表示当前集群的全部主分片都正常运行,但是副本分片没有全部处在正常状态。
 :3 个主分片正常
:3 个主分片正常
 :3 个副本分片都是 Unassigned,它们都没有被分配到任何节点。 在同 一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点 上的所有副本数据
:3 个副本分片都是 Unassigned,它们都没有被分配到任何节点。 在同 一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点 上的所有副本数据
当前集群是正常运行的,但存在丢失数据的风险
elasticsearch-head chrome插件安装
插件获取网址:GitHub - mobz/elasticsearch-head: A web front end for an elastic search cluster,下载压缩包,解压后将内容放入自定义命名为elasticsearch-head文件夹。
接着点击Chrome右上角选项->工具->管理扩展(或则地址栏输入chrome://extensions/),选择打开“开发者模式”,让后点击“加载已解压得扩展程序”,选择elasticsearch-head/_site,即可完成chrome插件安装
6.3.2 故障转移
当集群中只有一个节点在运行时,意味着会有一个单点故障问题——没有冗余。 幸运的是,我们只需再启动一个节点即可防止数据丢失。当你在同一台机器上启动了第二个节点时,只要它和第一个节点有同样的 cluster.name 配置,它就会自动发现集群并加入到其中。但是在不同机器上启动节点的时候,为了加入到同一集群,你需要配置一个可连接到的单播主机列表。之所以配置为使用单播发现,以防止节点无意中加入集群。只有在同一台机器上运行的节点才会自动组成集群
如果启动了第二个节点,集群将会拥有两个节点 : 所有主分片和副本分片都已被分配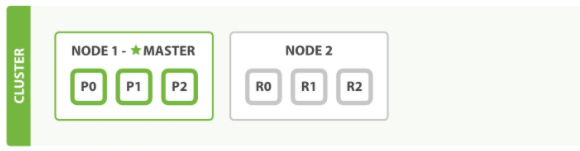
通过 elasticsearch-head 插件查看集群情况

上图边框加粗的为主分片,下面细的边框是备份,加星号的标识master主节点

集群的健康值为green,表示每个分片都能起作用
第二个节点加入到集群后, 3 个副本分片将会分配到这个节点上——每 个主分片对应一个副本分片。这意味着当集群内任何一个节点出现问题时,我们的数据都完好无损。所 有新近被索引的文档都将会保存在主分片上,然后被并行的复制到对应的副本分片上。这就保证了我们 既可以从主分片又可以从副本分片上获得文档
6.3.3 水平扩容
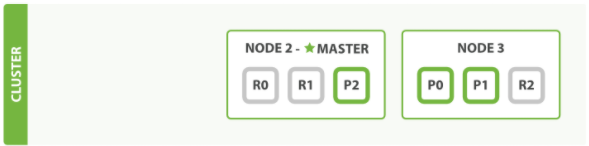
怎样为我们的正在增长中的应用程序按需扩容呢?当启动了第三个节点,我们的集群将会拥有三个节点的集群 : 为了分散负载而对分片进行重新分配
当增加一个集群节点,我们的分片会转移到不同的节点上面去,增强吞吐量
通过 elasticsearch-head 插件查看集群情况。

1.Node 1 和 Node 2 上各有一个分片被迁移到了新的 Node 3 节点,现在每个节点上都拥有 2 个分片, 而不是之前的 3 个。 这表示每个节点的硬件资源(CPU, RAM, I/O)将被更少的分片所共享,每个分片的性能将会得到提升
2.分片是一个功能完整的搜索引擎,它拥有使用一个节点上的所有资源的能力。 我们这个拥有 6 个分 片(3 个主分片和 3 个副本分片)的索引可以最大扩容到 6 个节点,每个节点上存在一个分片,并且每个 分片拥有所在节点的全部资源
但是如果我们想要扩容超过 6 个节点怎么办呢?
1.主分片的数目在索引创建时就已经确定了下来。实际上,这个数目定义了这个索引能够存储的最大数据量。(实际大小取决于你的数据、硬件和使用场景。) 但是,读操作——搜索和返回数据——可以同时被主分片 或 副本分片所处理,所以当你拥有越多的副本分片时,也将拥有越高的吞吐量。因为你创建索引之后,主分片数量就不好改了,只能改副本数量
2.在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把副本数从默认的 1 增加到 2
将es的9200端口改为1001后启动
#PUT http://127.0.0.1:1001/users/_settings
{
"number_of_replicas" : 2
}通过 elasticsearch-head 插件查看集群情况:

- 当然,如果只是在相同节点数目的集群上增加更多的副本分片并不能提高性能,因为每个分片从节点上获得的资源会变少。 你需要增加更多的硬件资源来提升吞吐量。
- 但是更多的副本分片数提高了数据冗余量:按照上面的节点配置,我们可以在失去 2 个节点的情况下不丢失任何数据。
6.3.4 应对故障
我们关闭第一个节点,这时集群的状态为:关闭了一个节点后的集群
- 我们关闭的节点是一个主节点。而集群必须拥有一个主节点来保证正常工作,所以发生的第一件事情就是选举一个新的主节点: Node 2 。在我们关闭 Node 1 的同时也失去了主分片 1 和 2 ,并且在缺失主分片的时候索引也不能正常工作。 如果此时来检查集群的状况,我们看到的状态将会为red :不是所有主分片都在正常工作。
- 幸运的是,在其它节点上存在着这两个主分片的完整副本, 所以新的主节点立即将这些分片在Node 2 和 Node 3 上对应的副本分片提升为主分片, 此时集群的状态将会为yellow。这个提升主分片的过程是瞬间发生的,如同按下一个开关一般
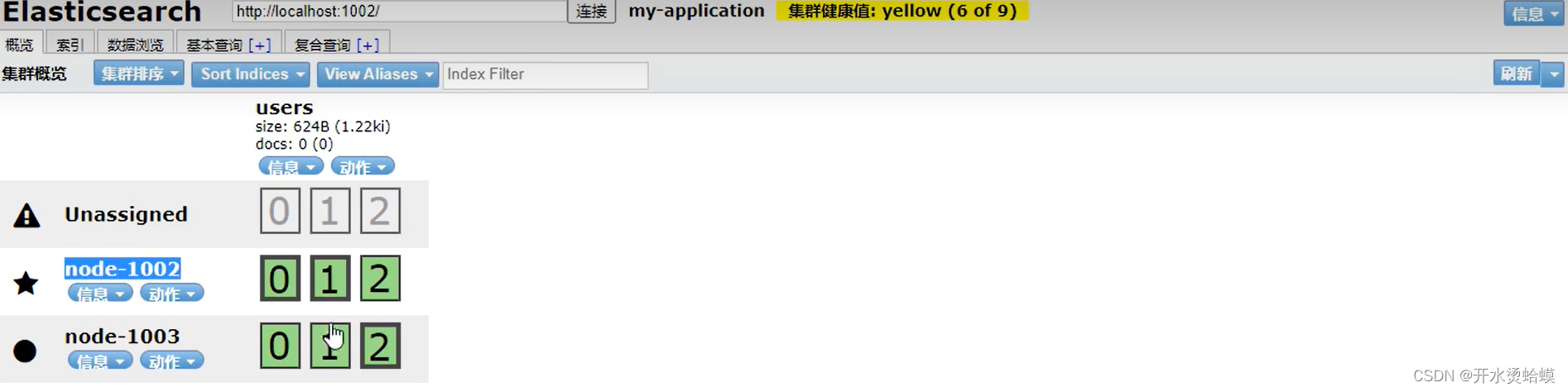
1001挂掉,副本用不了,集群健康值变为黄色,因为原来9个,你变为6个,少了3个分片,提供正常服务没问题,因为主分片依然存在
如果重启第一个服务器,首先要配置一下信息,能够找到其他两个服务器,加入集群
唯一的变化就是master变更,主分片变了没有事,重要的是哪个来管理
6.3.5 路由计算 & 分片控制
路由计算
当你插入数据的时候,首先要保证主分片有数据,然后再去考虑副本,现在就是你数据放到哪个主分片里,假设放到P0,取数据的时候去哪个分片里去取呢,所以最后制定增加数据和查询数据是根据规则来,这种规则称之为路由计算
例如下面:三个分区,两个副本,每个分区都有两个副本与之对应,例如:p0主分区,有两个R0副本与对应

当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:shard = hash(数据主键id) % number_of_primary_shards(主分片数量)
1.routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置。一旦你保存成功,副本里肯定也有数据了,其实你访问主分片和副本都是可以的,你最终访问哪个这种叫做分片控制,一般是轮询,第一会访问这个,下一次访问那个,有可能当时这个节点很忙
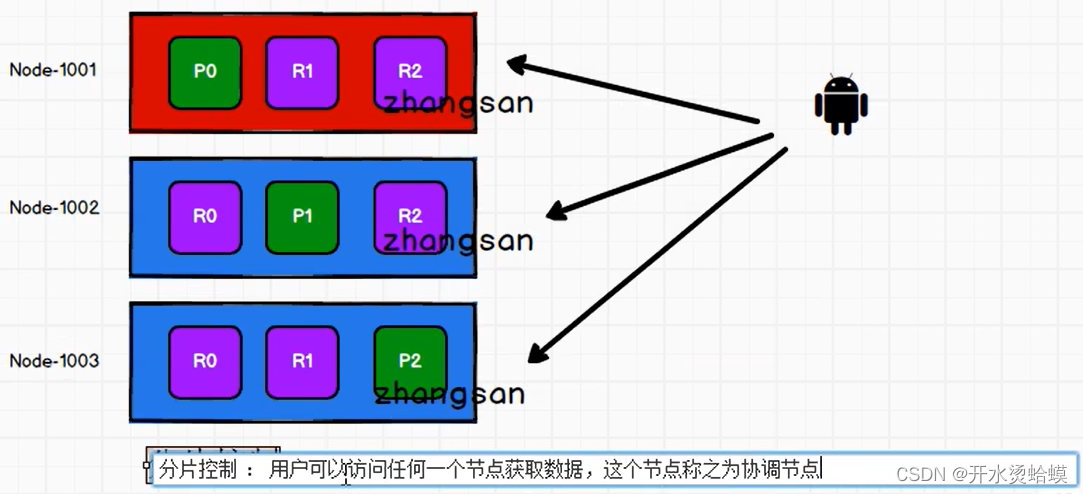 当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点
当发送请求的时候, 为了扩展负载,更好的做法是轮询集群中所有的节点
6.3.6 数据写流程
新建、索引和删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。
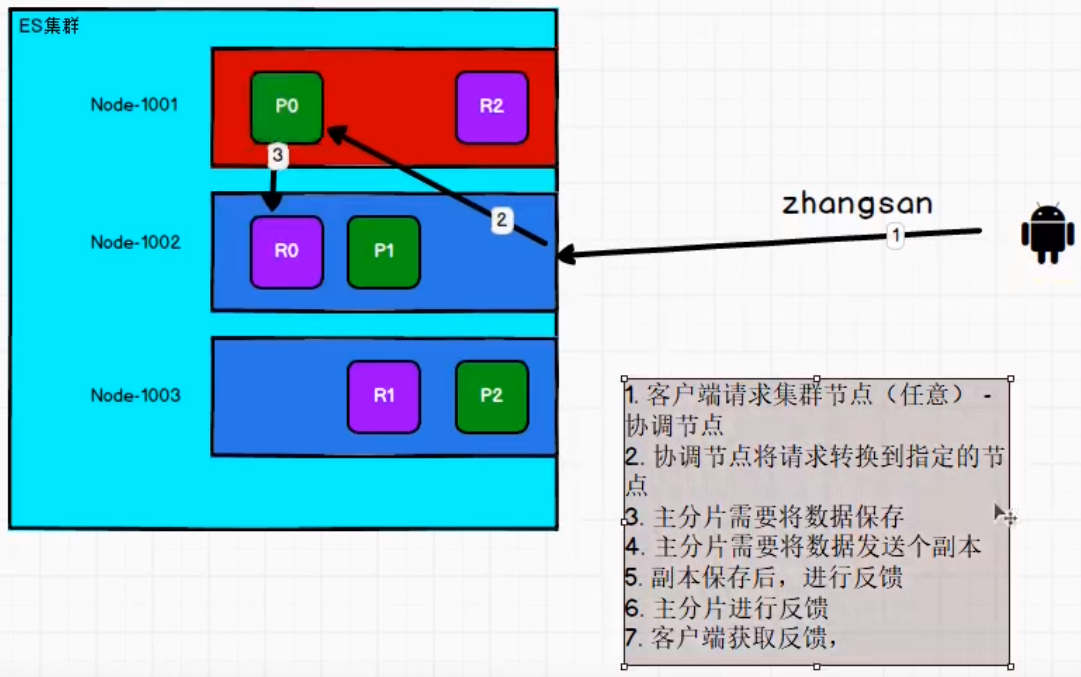
在客户端收到成功响应时,文档变更已经在主分片和所有副本分片执行完成,变更是安全的。有一些可选的请求参数允许您影响这个过程,可能以数据安全为代价提升性能。这些选项很少使用,因为 Elasticsearch 已经很快,但是为了完整起见, 请参考下文:
1.consistency
即一致性。在默认设置下,即使仅仅是在试图执行一个写操作之前,主分片都会要求必须要有规定数量quorum(或者换种说法,也即必须要有大多数)的分片副本处于活跃可用状态,才会去执行写操作(其中分片副本 可以是主分片或者副本分片)。这是为了避免在发生网络分区故障(network partition)的时候进行写操作,进而导致数据不一致。 规定数量即: int((primary + number_of_replicas) / 2 ) + 1
consistency 参数的值可以设为:
- one :只要主分片状态 ok 就允许执行写操作。主分片写完即可查询
- all:必须要主分片和所有副本分片的状态没问题才允许执行写操作。
- quorum:默认值为quorum , 即大多数的分片副本状态没问题就允许执行写操作。
注意,规定数量的计算公式中number_of_replicas指的是在索引设置中的设定副本分片数,而不是指当前处理活动状态的副本分片数。如果你的索引设置中指定了当前索引拥有3个副本分片,那规定数量的计算结果即:int((1 primary + 3 replicas) / 2) + 1 = 3,如果此时你只启动两个节点,那么处于活跃状态的分片副本数量就达不到规定数量,也因此您将无法索引和删除任何文档。
2.timeout
- 如果没有足够的副本分片会发生什么?Elasticsearch 会等待,希望更多的分片出现。默认情况下,它最多等待 1 分钟。 如果你需要,你可以使用timeout参数使它更早终止:100是100 毫秒,30s是30秒。
- 新索引默认有1个副本分片,这意味着为满足规定数量应该需要两个活动的分片副本。 但是,这些默认的设置会阻止我们在单一节点上做任何事情。为了避免这个问题,要求只有当number_of_replicas 大于1的时候,规定数量才会执行。
6.3.7 数据读流程

协调节点:集群中的任意一个节点
在处理读取请求时,协调结点在每次请求的时候都会通过轮询所有的副本分片来达到负载均衡。在文档被检索时,已经被索引的文档可能已经存在于主分片上但是还没有复制到副本分片。 在这种情况下,副本分片可能会报告文档不存在,但是主分片可能成功返回文档。 一旦索引请求成功返回给用户,文档在主分片和副本分片都是可用的
6.3.8 更新流程 & 批量操作流程
更新流程
部分更新一个文档结合了先前说明的读取和写入流程:

部分更新一个文档的步骤如下:
- 客户端向Node 1发送更新请求。
- 它将请求转发到主分片所在的Node 3 。
- Node 3从主分片检索文档,修改_source字段中的JSON,并且尝试重新索引主分片的文档。如果文档已经被另一个进程修改,它会重试步骤3 ,超过retry_on_conflict次后放弃。
- 如果 Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和 Node 2上的副本分片,重新建立索引。一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果 Elasticsearch 仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档
批量操作流程
mget和 bulk API的模式类似于单文档模式。区别在于协调节点知道每个文档存在于哪个分片中。它将整个多文档请求分解成每个分片的多文档请求,并且将这些请求并行转发到每个参与节点
协调节点一旦收到来自每个节点的应答,就将每个节点的响应收集整理成单个响应,返回给客户端

用单个 mget 请求取回多个文档所需的步骤顺序:
- 客户端向 Node 1 发送 mget 请求。
- Node 1为每个分片构建多文档获取请求,然后并行转发这些请求到托管在每个所需的主分片或者副本分片的节点上。一旦收到所有答复,Node 1 构建响应并将其返回给客户端
可以对docs数组中每个文档设置routing参数。
bulk API, 允许在单个批量请求中执行多个创建、索引、删除和更新请求。
bulk API 按如下步骤顺序执行:
- 客户端向Node 1 发送 bulk请求。
- Node 1为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机。
- 主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端
6.3.8 倒排索引
分片原理
- 分片是Elasticsearch最小的工作单元。但是究竟什么是一个分片,它是如何工作的?
- 传统的数据库每个字段存储单个值,但这对全文检索并不够。文本字段中的每个单词需要被搜索,对数据库意味着需要单个字段有索引多值的能力。最好的支持是一个字段多个值需求的数据结构是倒排索引
倒排索引原理
- Elasticsearch使用一种称为倒排索引的结构,它适用于快速的全文搜索。
- 见其名,知其意,有倒排索引,肯定会对应有正向索引。正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
- 所谓的正向索引,就是搜索引擎会将待搜索的文件都对应一个文件ID,搜索时将这个ID和搜索关键字进行对应,形成K-V对,然后对关键字进行统计计数。
词条:索引中最小存储和查询单元(英文环境:一个单词。中文:一个词组)
词典:词条的集合,底层是B+数,Hash表
倒排表:
6.3.9 文档搜索
早期的全文搜索会为整个文档集合创建一个很大的道袍索引并将其写入到磁盘,一旦新的索引就绪,旧的就会被其替代,这样最近的变化便可以被检索到。
倒排索引被写入磁盘后是不可以改变的:它永远不会修改
不变性有重要的价值。:
- 不需要锁,如果你从来不更新索引,你就不需要担心多进程同时修改数据的问题。
- 一旦索引被读入内核的文件系统缓存,便会留在那里。,由于其不变性,只要文件系统缓存中含有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。浙江提升很大的性能。
- 其他缓存(像filter缓存),在索引的生命周期内始终有效,它们不需要在每次数据改变时被重建,因为数据不会变化。
- 写入单个大的倒排索引允许数据被压缩,减少磁盘io和需要被缓存到内存的索引的使用量。
当然一个不变的索引也有不好的地方,主要事实它是不可变,你不能修改它。如果你需要让一个新的文档被搜索,你需要重建整个索引。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!