


16.哨兵模式
哨兵模式前奏:
有两种主从模式:
1.
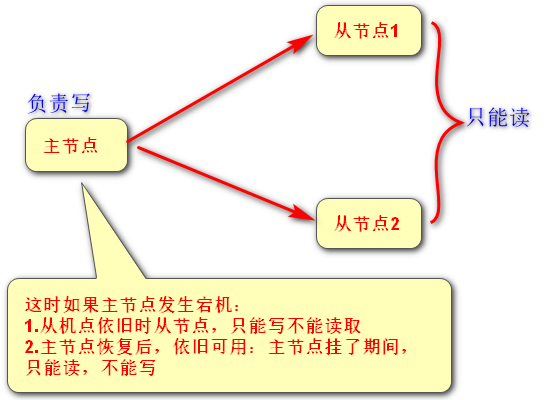
2.层层链路(必须手动执行)
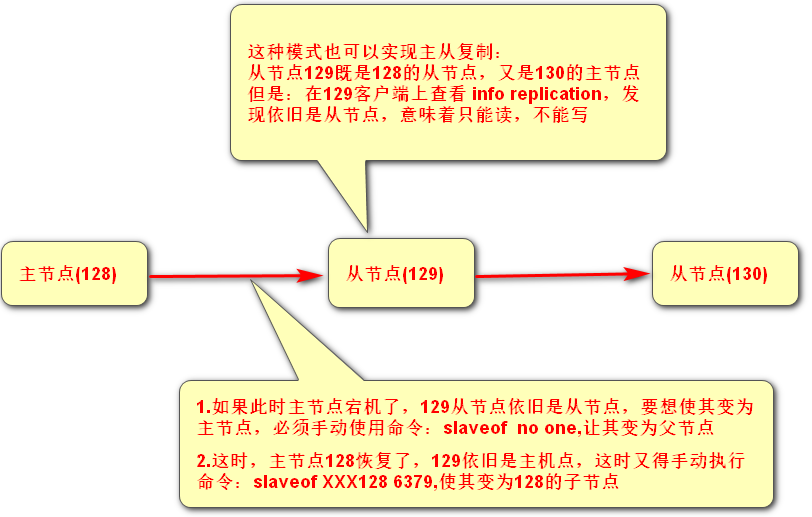
哨兵模式(主节点宕机后,自动推选出主节点)
哨兵模式是一种特殊的模式,首先Redis提供了哨兵的命令,哨兵是一个单独的进程,作为进程,他会独立运行。其原理是
哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个Redis实例
这里的哨兵有两个作用
1.通过命令,让Redis服务器返回其运行状态,包括主服务器和从服务器
2.当哨兵检测到mastr宕机,会自动将slave切换到master,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让他们切换主机
然而一个哨兵进程对Redis服务器进行监控,可能会出现问题,为此我们可以使用多个哨兵进行监控,各个哨兵之间还进行监控,这样就形成了多哨兵模式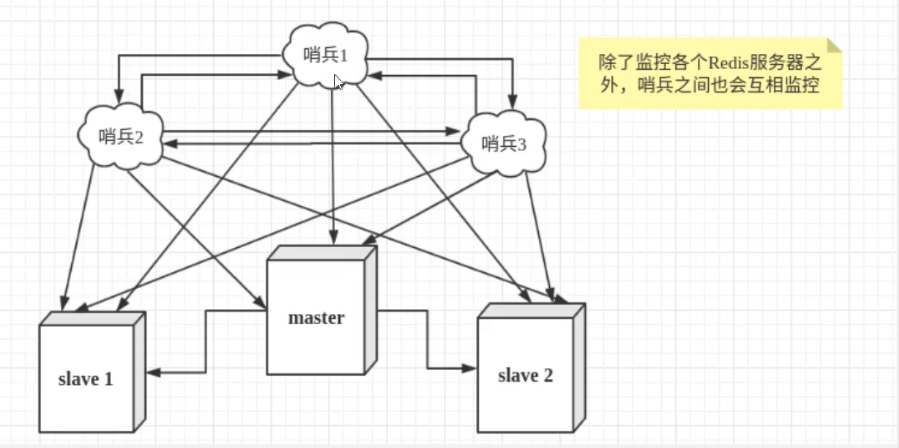
假设主服务宕机,哨兵1现检测到这个结果,系统并不会马上进行重新选举的过程,仅仅是哨兵1主管的认为主服务器不可用,这个现象成为主观下线()
当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间会进行一次投票,投票的结果由一个哨兵发起,进行故障转移操作,重新
选举master。操作成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器切换到主机,这个过程成为客观下线1.将哨兵的配置文件上传至宿主机的挂载目录,和redis.conf文件放在一起
2.或者使用命令从官网下载哨兵文件:wget -c http://download.redis.io/redis-stable/sentinel.conf
哨兵文件的参数解读:
1.port 26379
sentinel监听端口,默认是26379,可以修改。
2.sentinel monitor <master-name> <ip> <redis-port> <quorum>
告诉sentinel去监听地址为ip:port的一个master,这里的master-name可以自定义,quorum是一个数字,指明当有多少个sentinel认为一个master失效时,master才算真正失效。master-name只能包含英文字母,数字,和“.-_”这三个字符需要注意的是master-ip 要写真实的ip地址而不要用回环地址(127.0.0.1)。
配置示例:
sentinel monitor mymaster 192.168.0.5 6379 2
3.sentinel auth-pass <master-name> <password>
设置连接master和slave时的密码,注意的是sentinel不能分别为master和slave设置不同的密码,因此master和slave的密码应该设置相同。
配置示例:
sentinel auth-pass mymaster 0123passw0rd
4.sentinel down-after-milliseconds <master-name> <milliseconds>
这个配置项指定了需要多少失效时间,一个master才会被这个sentinel主观地认为是不可用的。 单位是毫秒,默认为30秒
配置示例:
sentinel down-after-milliseconds mymaster 30000
5.sentinel parallel-syncs <master-name> <numslaves>
这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
配置示例:
sentinel parallel-syncs mymaster 1
6. sentinel failover-timeout <master-name> <milliseconds>
failover-timeout 可以用在以下这些方面:
1. 同一个sentinel对同一个master两次failover之间的间隔时间。
2. 当一个slave从一个错误的master那里同步数据开始计算时间。直到slave被纠正为向正确的master那里同步数据时。
3.当想要取消一个正在进行的failover所需要的时间。
4.当进行failover时,配置所有slaves指向新的master所需的最大时间。不过,即使过了这个超时,slaves依然会被正确配置为指向master,但是就不按parallel-syncs所配置的规则来了。
配置示例:
sentinel failover-timeout mymaster1 20000
7.sentinel的notification-script和reconfig-script是用来配置当某一事件发生时所需要执行的脚本,可以通过脚本来通知管理员,例如当系统运行不正常时发邮件通知相关人员。对于脚本的运行结果有以下规则:
若脚本执行后返回1,那么该脚本稍后将会被再次执行,重复次数目前默认为10
若脚本执行后返回2,或者比2更高的一个返回值,脚本将不会重复执行。
如果脚本在执行过程中由于收到系统中断信号被终止了,则同返回值为1时的行为相同。
一个脚本的最大执行时间为60s,如果超过这个时间,脚本将会被一个SIGKILL信号终止,之后重新执行。
1).sentinel notification-script <master-name> <script-path>
通知型脚本:当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会去调用这个脚本,这时这个脚本应该通过邮件,SMS等方式去通知系统管理员关于系统不正常运行的信息。调用该脚本时,将传给脚本两个参数,一个是事件的类型,一个是事件的描述。如果sentinel.conf配置文件中配置了这个脚本路径,那么必须保证这个脚本存在于这个路径,并且是可执行的,否则sentinel无法正常启动成功。
配置示例:
sentinel notification-script mymaster /var/redis/notify.sh
2).sentinel client-reconfig-script <master-name> <script-path>
当一个master由于failover而发生改变时,这个脚本将会被调用,通知相关的客户端关于master地址已经发生改变的信息。以下参数将会在调用脚本时传给脚本:
<master-name> <role> <state> <from-ip> <from-port> <to-ip> <to-port>
目前<state>总是“failover”, <role>是“leader”或者“observer”中的一个。 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的。这个脚本应该是通用的,能被多次调用,不是针对性的。
配置示例:
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh
3.根据上述修改sentinel.conf文件
主要修改(监控的主节点ip和端口):sentinel monitor mymaster 192.168.2.128 6379 2
后台进程打开:daemonize yes
每个sentinel.conf都配置监控主节点你的ip和端口
4.重启redis服务:因为哨兵的配置文件存储在宿主机/usr/local/docker/redis/config,所以要挂载到docker容器中的/etc/redis中
docker run -p 6379:6379 --name redis -v /usr/local/docker/redis/config/:/etc/redis -v /usr/local/docker/redis/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes
5.启动哨兵模式
[root@wmd03 config]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
092a7c58a64a redis "docker-entrypoint.s…" 11 minutes ago Up 11 minutes 0.0.0.0:6379->6379/tcp redis
[root@wmd03 config]# docker exec -it 092a7c58a64a /bin/bash
root@092a7c58a64a:/data# cd /etc/redis/(进入docker中redis哨兵配置文件的挂载目录)
root@092a7c58a64a:/etc/redis# ls
redis.conf sentinel.conf
root@092a7c58a64a:/etc/redis# redis-sentinel sentinel.conf(启动哨兵)
6.检查哨兵启动是否成功
[root@wmd02 config]# ps -ef|grep redis
polkitd 6528 6516 0 23:10 ? 00:00:03 redis-server *:6379
root 6965 6516 0 23:22 ? 00:00:00 redis-sentinel *:26379 [sentinel](哨兵启动成功)
root 6997 6874 0 23:24 pts/1 00:00:00 grep --color=auto redis

如果此时我们将主机点:128的redis停掉
过30秒后,主节点不恢复,自动选举出新的主节点
129服务器上:
127.0.0.1:6379> info replication
# Replication
role:master-------------------------------------->发现129成了父节点,130成了子节点
connected_slaves:1
slave0:ip=192.168.2.130,port=6379,state=online,offset=0,lag=0
master_replid:efb2d9eae08f9706b821cce1e1f4e00cf43c1ff1
master_replid2:fe482bbdb6799260c0c7f49f03578f75c8d1f482
master_repl_offset:24785
second_repl_offset:24485
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:24785
130服务器上:
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.2.129----------->父节点变成129
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_repl_offset:28733
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:efb2d9eae08f9706b821cce1e1f4e00cf43c1ff1
master_replid2:fe482bbdb6799260c0c7f49f03578f75c8d1f482
master_repl_offset:28733
second_repl_offset:24485
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:15
repl_backlog_histlen:28719
重启128父节点:
128服务器上:
root@0428235828f3:/data# redis-cli
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.2.129------------------>发现其变为了子节点,父节点变为129了
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:76552
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:efb2d9eae08f9706b821cce1e1f4e00cf43c1ff1
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:76552
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:74276
repl_backlog_histlen:2277
问题:128redis挂掉后,会将哨兵进程也停掉,需要重启下,注意!!

