8.索引优化
索引失效
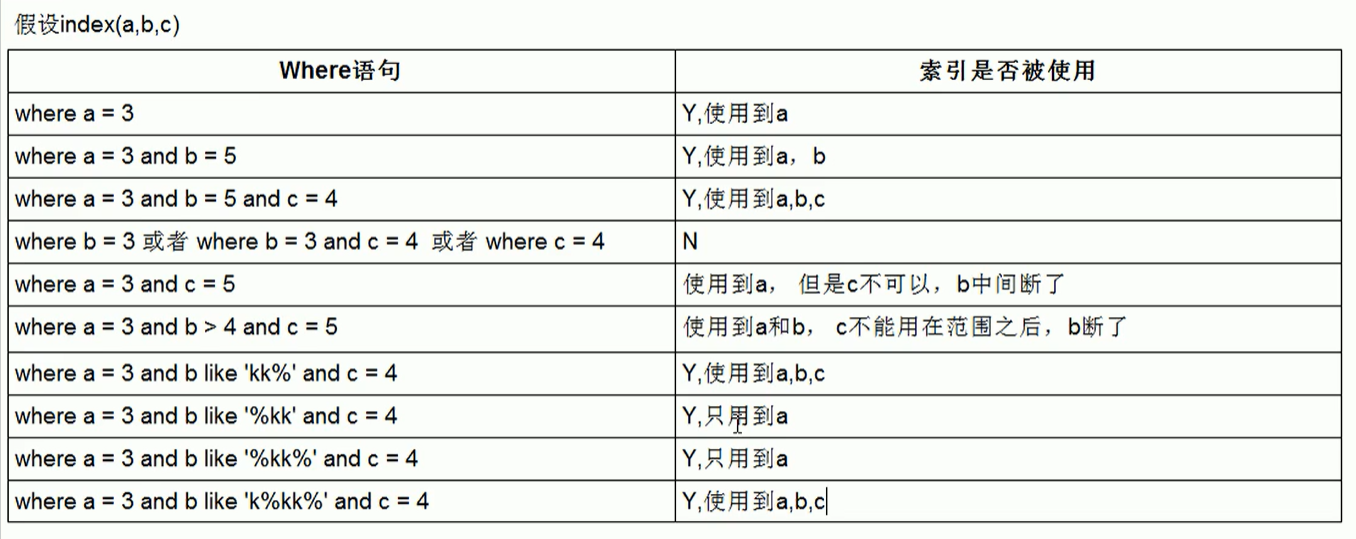
1.最佳左前缀原则: 如果索引了多列,要遵守最佳左前缀法则,指的是查询从索引的最左列开始,并且不跳过索引中的列.
如给表创建复合索引:create index on 表名(name,age,poit)
1.不会使用索引,具体情况参考:https://www.cnblogs.com/rjzheng/p/12557314.html,因为mysql底层使用b+数作为索引的数据结构
如果多列,会按照第一列排序,第一列相同的情况下再按照二列排序..,整体上2列并不是有序的
select * from user where age='18';
2.也不会用到索引
selec * from user where poit=15;
3.也不会用到索引
selet * form user where age=18 and ponit=15;
4.会使用索引
select * from user where age=19 and name='吴孟达';
mysql优化器会优化sql语句为:和索引的顺序相同
select * from user where name='吴孟达' and age=19;
5.name只用到了索引,point并没用到
select * from user where name='吴孟达' and point=15;
2.不在索引列上做任何操作(计算/函数/(自动or手动)类型转换),会导致索引失效而转向全表扫描
3.存储引擎不能使用索引中范围条件右边的列
select * from user where name='july' and age >25 and pos='manager';
只有name 和age用到索引,但是pos没有用到,因为age是范围查找,右边的失效
4.尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
如select name,age,poit from user;
5.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描
6.is null,is not null也无法使用索引
7.like以通配符开头('%abc')mysql索引失效会变成全表扫描的操作
如下图:
1.%放左边索引会失效
2.%放右边索引才会生效
那如果想使用 like '%%'双百分号,又想索引生效应该如何操作呢??
答案:使用覆盖索引:
即:查询的字段在创建的索引列表中,如
1.创建了复合索引(name,age,point)
2.是可以用到索引的
select name from user where name like '%吴孟达%'
select 任何在索引列表中的字段 where name like '%吴孟达%';
3.但当查询的字段超出覆盖索引范围:
如:用不到索引了
1.select * from user where name like '%吴孟达%'
2.select name,age,point,多余字段 from user where name like '%吴孟达%'
9.字符串不加单引号索引失效
10.少用or,用它连接会失效
11.一般order by是给定个范围,group by基本上都要进行排序,会有临时表的产生
查询截取分析
分析步骤:
1.观察,至少跑一天,看看生产的慢sql情况
2.开启慢查询日志,设置阈值,比如超过5秒钟的就是慢sql,并将他们抓取出来
3.explain+慢sql分析
4.show profile;查询sql在mysql服务器中的执行细节和声明周期情况
5.进行sql数据库服务器的参数调优
查询优化:
1.永远小表驱动大表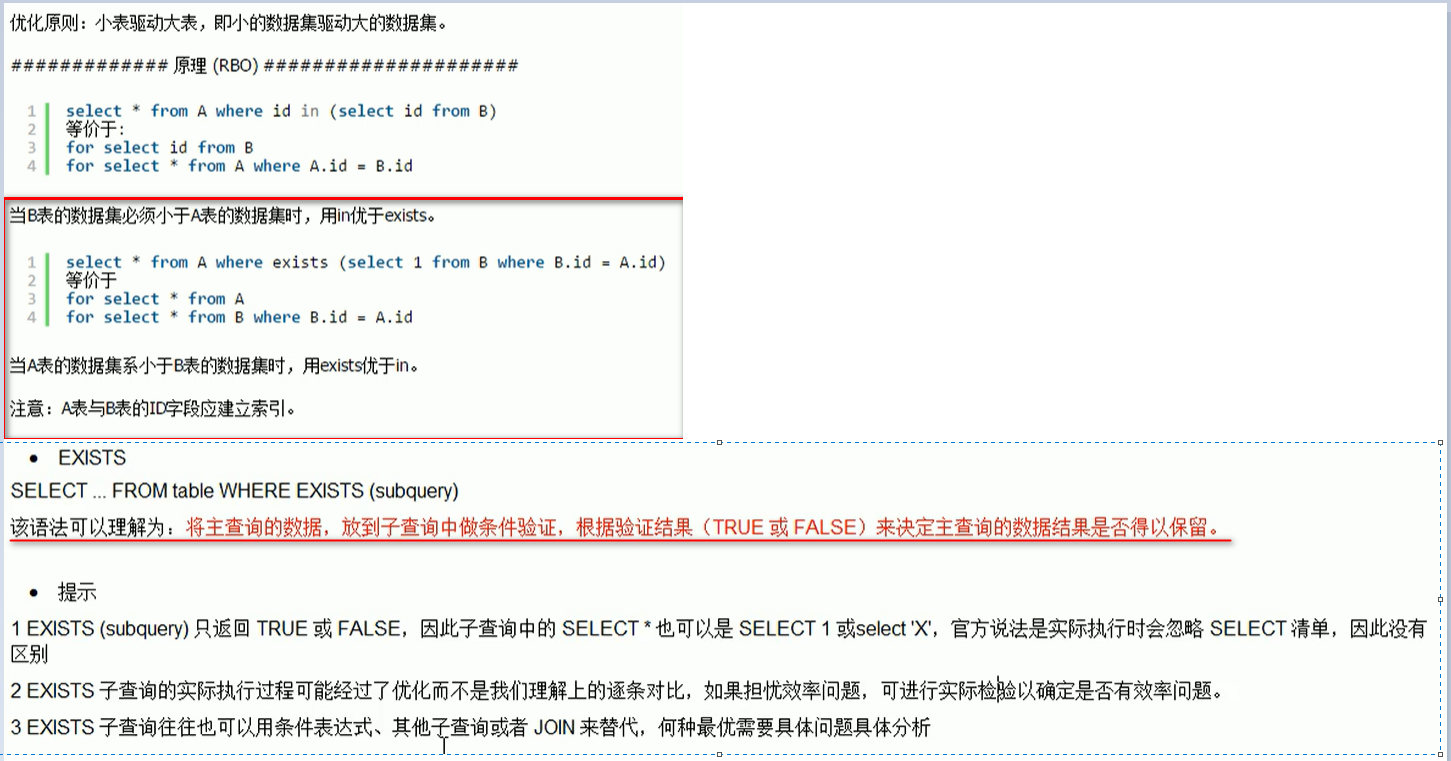
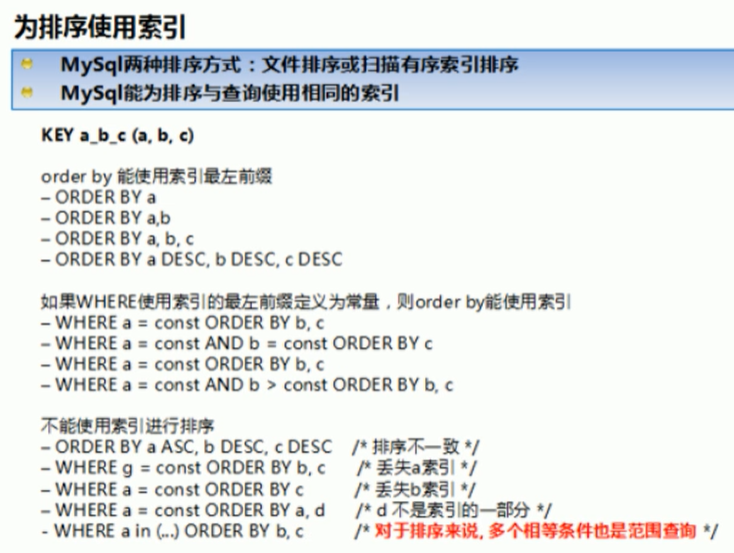
order by 排序优化
order by子句
1.尽量使用index方式排序,避免使用FileSort方式排序
2.尽可能在索引列上完成排序操作,最招索引建的最佳左前缀
3.mysql支持两种方式的排序,fileSort和index,index效率高,它指mysql扫描索引本身完成排序,filesort方式效率较低
4.order by满足两种情况,会使用index方式排序:
4.1order by语句使用索引最左前列
4.2使用where子句与order by子句条件列组合满足索引最左列
5.如果不在索引列上,filesort有两种算法,mysql就要启动双路排序和单路排序
1.双路排序(mysql4.1之前):取一批数据,要对磁盘进行两次扫描,I\O很耗
1.从磁盘中读取排序字段,在buffer中进行排序,2.再从磁盘中读取其他字段
2.单路排序(mysql4.1之后):
从磁盘读取查询所需要的的列,按照order by列在buffer对他们进行排序,然后扫描排序后的列表进行输出
他的效率会更快一点,避免了第二次读取数据,并且把随机IO变成了顺序ID,但是他会使用更多的空间
因为它每一行都保存在内存中
单路排序引申出的问题:在sort_buffer中,单路排序要比多路排序占用更多的空间,因为单路排序是把所有字段都取出放入内存中,
数据总大小可能超过sort_buffer的容量,导致每次只能读取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再
取sort_buffer容量大小,再排...从而进行多次I/O.
本想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失
group by(和order by的规则一致)
1.group by实质是先排序后进行分组,遵照索引建的最佳左前缀
2.无法使用索引列,增大max_length_for _sort_data参数+增大sort_Buffer_size参数的设置
3.where高于having,能写where限定条件就不要去having去限定了mysql慢查询
默认情况下,mysql数据库没有开启慢查询日志,需要我们手动设置这个参数
如果不是调优需要的话,一般不建议启动这个参数,因为开启慢查询日志会或多或少带来一定性能的影响,慢查询日志支持将日志记录写入文件
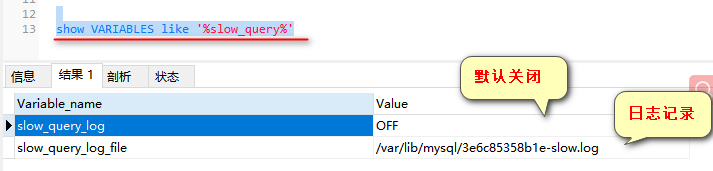
1.如何查看慢查询日志设置:
show VARIABLES like '%slow_query%'
2.打开慢查询
set flobal slow_query_log=1;
这么设置只针对当前数据库生效,数据库重启后失效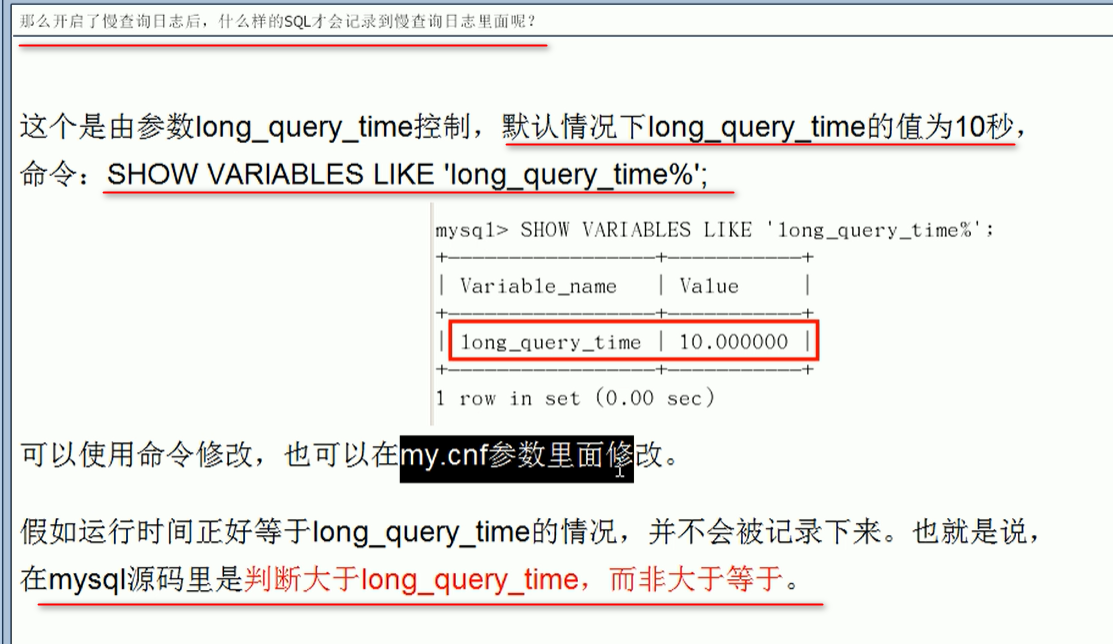
查看超过慢查询时间阈值的sql数:
show global status like '%Slow_queries%'日志分析工具:mysqldumpslow
1.s:表示以何种方式进行排序
2.c:访问次数
3.l:锁定时间
4.r:返回记录
5.t:查询时间
6.al:平均锁定时间
7.ar:平均返回记录数
8.at:平均查询时间
9.t:即为返回前面多少条数据
10.g:后面搭配一个正则匹配模式,大小写不敏感
show profile
是mysql提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于sql调优的测量
默认情况下,参数处于关闭状态,并保存最近15次的运行结果
1.查看profile状态:
show VARIABLES like 'profiling';
2.诊断sql
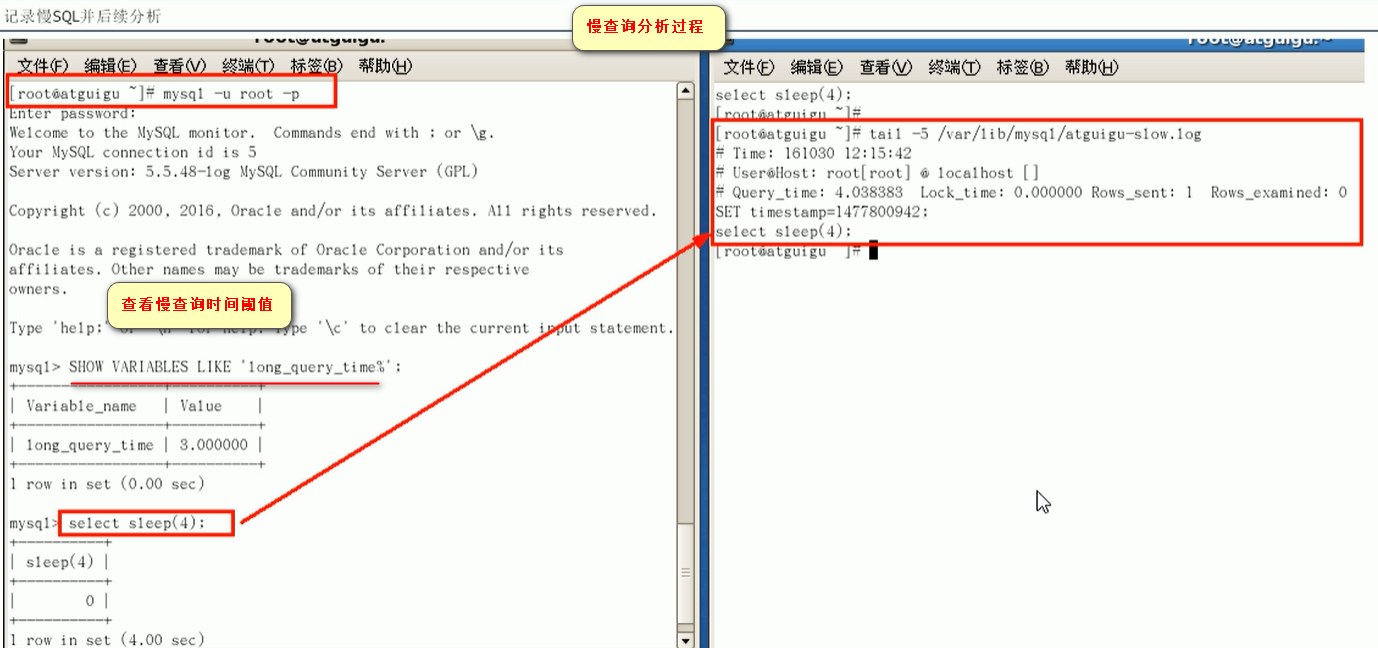
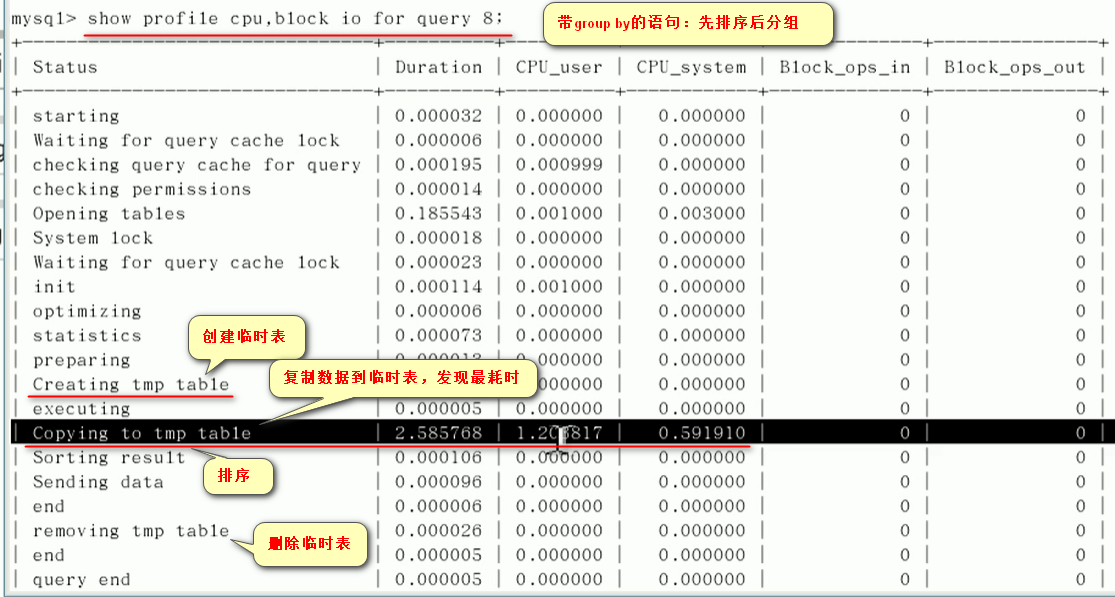
1.show profiles;查看查询过的sql和对应的id号
2.show profile cpu,block io for query id号;根据1的id号查询该条记录的详细执行耗时信息
如果2的查询结果中出现下面四种:就危险了...
1.converting HEAP to MyISAM:查询结果太大,内存不够用往磁盘上搬了
2.Creating tmp table:创建临时表
拷贝数据到临时表
用完再删除
3.Copying to tmp table on disk 把内存中临时表复制到磁盘,危险!!!
4.locked 
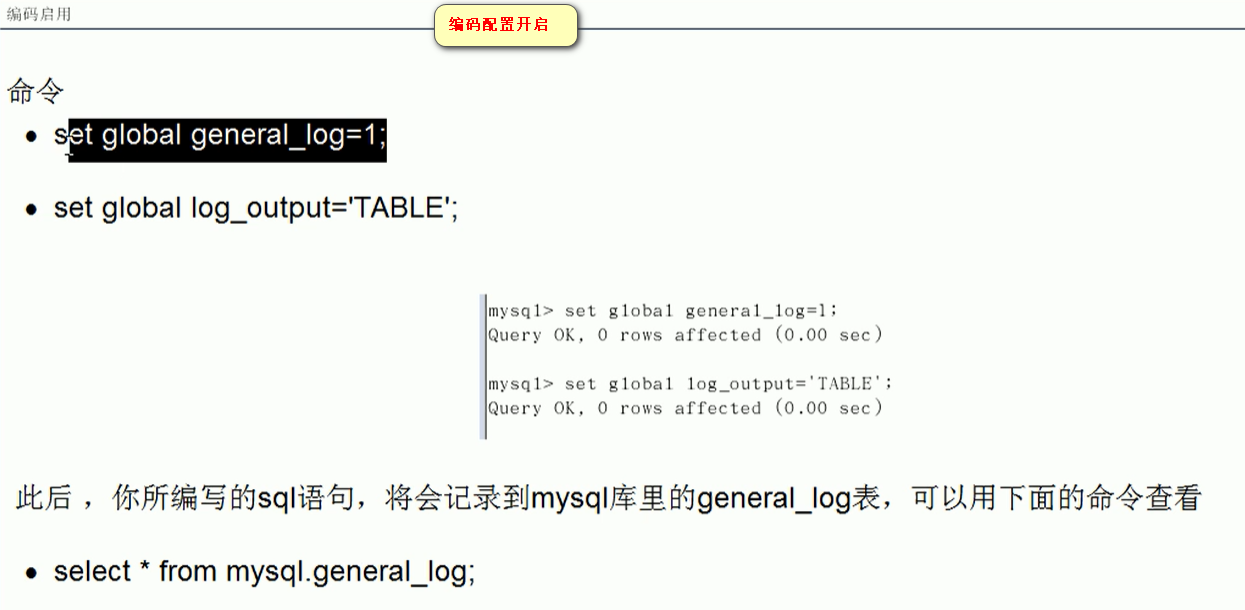
全局查询日志
只能测试环境用,不能生产环境用!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号