

3.集合类不安全
1.List集合在多线程下是不安全的
1.测试代码:创建30个线程同时操作一个资源list
public class NotSafeDemo {
public static void main(String[] args) {
List<String> list=new ArrayList<>();
for(int i=0;i<30;i++){
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,5));
System.out.println(list);
},"线程"+i).start();
}
}
}
运行时会报错误(并发修改异常):java.util.ConcurrentModificationException
问题:、
1.为什么会这样?
因为 ArrayList 线程不安全。
2.那为什么 ArrayList 线程不安全?
因为它的 add 方法没有加锁,多个线程并发过来add,就可能会出现异常。
源码如下:发现其add方法并没有加锁!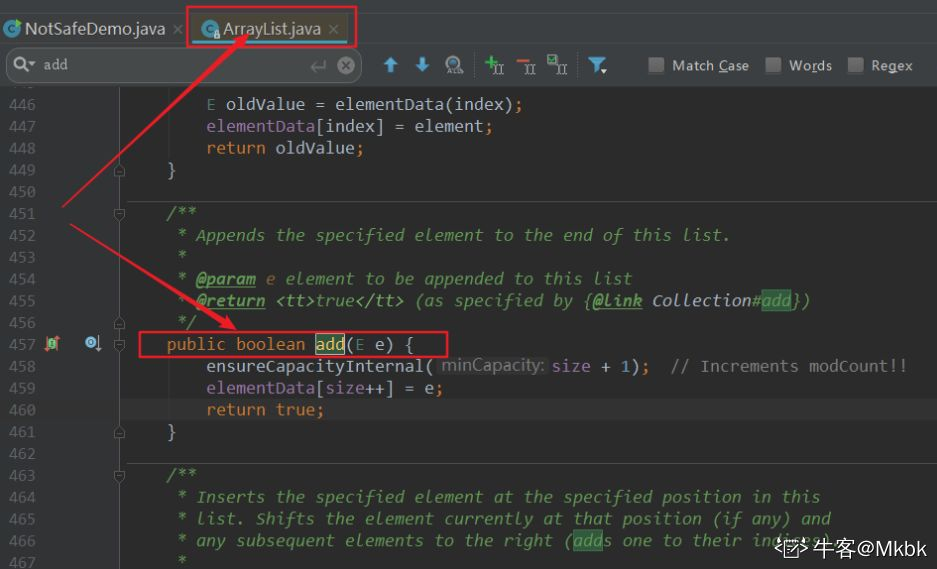
2.解决集合类不安全的方法
2.1Vector
ArrayList 和 Vector 的区别:

1.Vector 是 List 接口的古老实现类,ArrayList 是 List 接口后面新增的实现类。
2.除了线程安全问题与扩容方式不同,Vector 几乎与 ArrayList 一样。
3.可以把 Vector 作为解决 ArrayList 线程安全的一种方式(不过 Vector 效率太低),只是加上了synchronized关键字。
4.如果不需要线程安全性,推荐使用ArrayList替代Vector
测试代码如下:
public class NotSafeDemo {
public static void main(String[] args) {
重点1:创建Vector
List<String> list=new Vector<>();
for(int i=0;i<30;i++){
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,5));
System.out.println(list);
},"线程"+i).start();
}
}
}
运行不会报错!
分析原因是:
1.Vector 的 add 方法加了锁,如下截图:
2.其实 Vector 读方法也加了锁,相当于读的时候,同一时刻也只能有一个线程能读!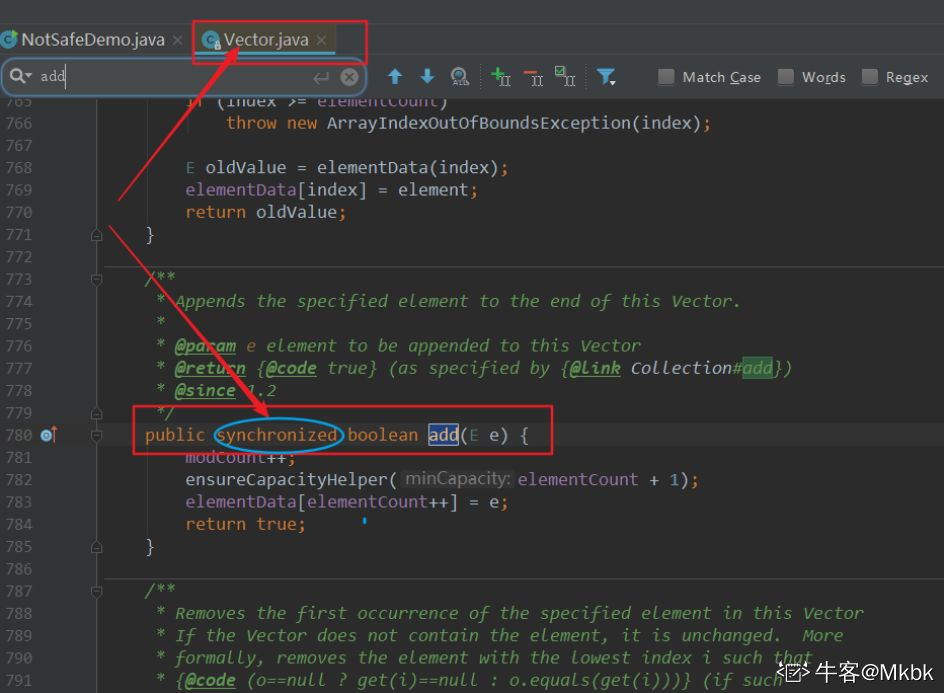
2.2 Collections
Collections是Collection的工具类,其中就提供了一个方法,可以将线程不安全的 ArrayList 转换成线程安全的!
具体测试代码如下:重点:List<String> list= Collections.synchronizedList(new ArrayList<>());
public class NotSafeDemo {
public static void main(String[] args) {
重点1:使用Collections.synchronizedList(new ArrayList<>())将不安全的ArrayList改为线程安全的
List<String> list= Collections.synchronizedList(new ArrayList<>());
for(int i=0;i<30;i++){
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,5));
System.out.println(list);
},"线程"+i).start();
}
}
}
具体的源码如下:发现add方法也是加了锁的,并且有个mutex对象,这个对象赋值为this,即锁定的是调用者对象!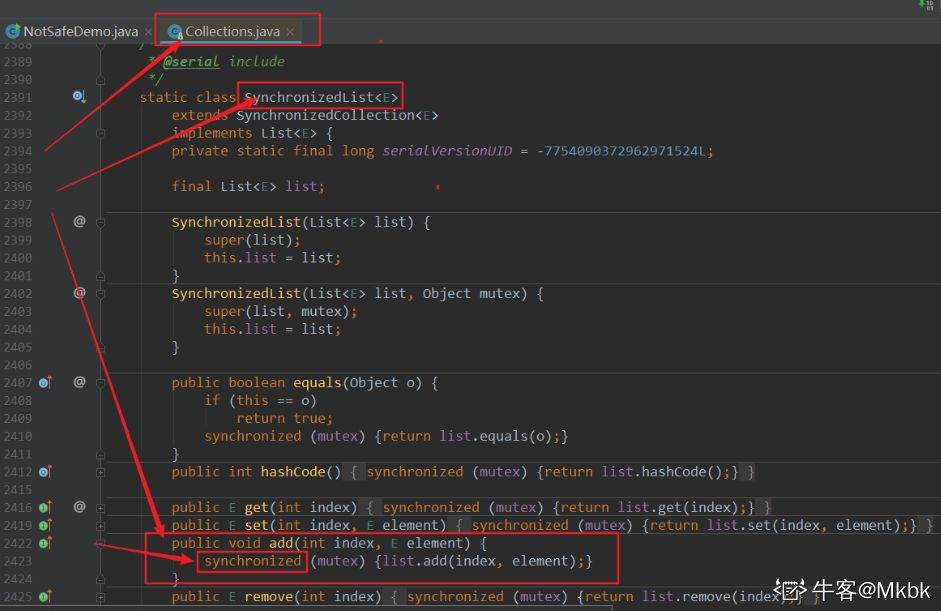
并且 Collections 工具类也支持将 HashMap, HashSet 等转换成安全的。
这个地方要注意两个地方:
1.迭代操作必须加锁,可以使用synchronized关键字修饰;
2.synchronized持有的监视器对象必须是synchronized (list),即包装后的list,
使用其他对象如synchronized (new Object())会使add,remove等方法与迭代方法使用的锁不一致,
无法实现完全的线程安全性。
源码迭代:
//迭代操作并未加锁,所以需要手动同步
public ListIterator<E> listIterator() {
return list.listIterator();
}
所以在遍历时需要手动加锁:
List list = Collections.synchronizedList(new ArrayList());
//必须对list进行加锁
synchronized (list) {
Iterator i = list.iterator();
while (i.hasNext())
foo(i.next());
}2.3 CopyOnWriteArrayList(写时复制)
JUC的常用!
实现代码如下:
List<String> list= new CopyOnWriteArrayList<>();
源码结构:(可以看到CopyOnWriteArrayList底层实现为Object[] array数组。)
1.先看一下 CopyOnWriteArrayList 的结构:
public class CopyOnWriteArrayList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private static final long serialVersionUID = 8673264195747942595L;
final transient ReentrantLock lock = new ReentrantLock();
private transient volatile Object[] array;
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
}
2.添加元素:(可以看到每次添加元素时都会进行Arrays.copyOf操作,代价非常昂贵,并且发下其加锁方式是手动加锁lock)
public boolean add(E e) {
final ReentrantLock lock = this.lock;
//重点1:手动加锁
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
重点2:数组复制扩容//创建出一个新的数组去操作,读写分离的思想
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
重点:有两点必须讲一下。我认为CopyOnWriteArrayList这个并发组件,其实反映的是两个十分重要的分布式理念:
1.读写分离
我们读取CopyOnWriteArrayList的时候读取的是CopyOnWriteArrayList中的Object[] array,
但是修改的时候,操作的是一个新的Object[] array,读和写操作的不是同一个对象,这就是读写分离。
这种技术数据库用的非常多,在高并发下为了缓解数据库的压力,即使做了缓存也要对数据库做读写分离,
读的时候使用读库,写的时候使用写库,然后读库、写库之间进行一定的同步,这样就避免同一个库上读、写的IO操作太多
2.最终一致
对CopyOnWriteArrayList来说,线程1读取集合里面的数据,未必是最新的数据。
因为线程2、线程3、线程4四个线程都修改了CopyOnWriteArrayList里面的数据,
但是线程1拿到的还是最老的那个Object[] array,新添加进去的数据并没有,
所以线程1读取的内容未必准确。不过这些数据虽然对于线程1是不一致的,
但是对于之后的线程一定是一致的,它们拿到的Object[] array一定是三个线程都操作完毕之后的Object array[],
这就是最终一致。最终一致对于分布式系统也非常重要,它通过容忍一定时间的数据不一致,提升整个分布式系统的可用性与分区容错性。
当然,最终一致并不是任何场景都适用的,像火车站售票这种系统用户对于数据的实时性要求非常非常高,就必须做成强一致性的。Vector/CopyOnWriteArrayList/Collections.synchronizedList的性能比较
通过前面的分析可知:
1.Vector对所有操作进行了synchronized关键字修饰,性能应该比较差
2.CopyOnWriteArrayList在写操作时需要进行copy操作,读性能较好,写性能较差
3.Collections.synchronizedList性能较均衡,但是迭代操作并未加锁,所以需要时需要额外注意
并发测试结果如图:
1.可以看到随着线程数的增加,三个类操作时间都有所增加。
2.Vector的遍历操作和CopyOnWriteArrayList的写操作(图片中标红的部分)性能消耗尤其严重
3.出乎意料的是Vector的读写操作和Collections.synchronizedList比起来并没有什么差别
(印象中Vector性能很差,实际性能差的只是遍历操作,看来还是纸上得来终觉浅,绝知此事要躬行啊)
4.仔细分析了下代码,虽然Vector使用synchronized修饰方法,Collections.synchronizedList使用synchronized修饰语句块,
但实际锁住内容并没有什么区别,性能相似也在情理之中
总结
1.CopyOnWriteArrayList的写操作与Vector的遍历操作性能消耗尤其严重,不推荐使用。
2.CopyOnWriteArrayList适用于读操作远远多于写操作的场景。
3.Vector读写性能可以和Collections.synchronizedList比肩,但Collections.synchronizedList不仅可以包装ArrayList,
也可以包装其他List,扩展性和兼容性更好。
3.set安全问题
set:用于存储无序(存入和取出的顺序不一定相同)元素,值不能重复
测试代码如下:
public class NotSafeDemo {
public static void main(String[] args) {
//重点1:创建一个线程不安全的set
Set<String> set = new HashSet();
for (int i=0;i<=30;i++){
new Thread(()->{
set.add(UUID.randomUUID().toString().substring(0,5));
System.out.println(set);
},"线程"+i).start();
}
}
}
运行会出现问题:(并发修改异常)java.util.ConcurrentModificationException
如何解决上述问题呢:
1.Collections工具类:
Set<String> set=Collections.synchronizedSet(new HashSet<>());
2.CopyOnWriteArraySet:
Set<String> set=new CopyOnWriteArraySet<>();
底层是:CopyOnWriteArrayList
CopyOnWriteArraySet的构造方法
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
调到set的add方法最终会调用到:
public boolean addIfAbsent(E e) {
Object[] snapshot = getArray();
//会判断list中是否有重复的,有的话就不放,没有再放
return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :
addIfAbsent(e, snapshot);
}
set特征:
1.无序性
2.不能重复
3.允许有null但是只能有一个
hashset的底层是什么呢?
set源码:发现其底层就是HashMap
public HashSet() {
map = new HashMap<>();
}
add方法:
public boolean add(E e) {
//发现其放入的是map的key,值是固定的,所以说set里的值是hashmap的key,
return map.put(e, PRESENT)==null;
}4.HashMap的线程安全问题
不使用Map<String, Object> map = new HashMap<> ();
而是用:
1.Map<String,Object> map=new ConcurrentHashMap<>();
2.Map<String,Object> map= Collections.synchronizedMap(new HashMap<>());5.Callable
Callable 接口类似于 Runnable,两者都是为那些其实例可能被另一个线程执行的类设计的。但是 Runnable 不会返回结果,并且无法抛出经过检查的异常。
特点:
1.Callable 可以抛出异常
2.Callable 可以返回结果
3.Callable 调用get方法时会阻塞
4.Callable 需要借助FutureTask 去和Thread关联启动
样例:
public class Juc_Test_Lock {
public static void main(String[] args) {
//重点1:创建Callable接口实例
MyThread myThread=new MyThread();
//重点2:创建Callable关联的FutureTask
FutureTask futureTask=new FutureTask(myThread);
new Thread(futureTask,"线程1").start();
//重点3:这个方法会阻塞,因为要等待线程执行完毕拿到结果
Integer result= (Integer) futureTask.get();
System.out.println("线程返回:"+result);
}
}
//重点4:实现Callable接口
class MyThread implements Callable<Integer>{
@Override
public Integer call() throws Exception {
System.out.println("call方法");
return 1024;
}
}
输出:
call方法
线程返回:1024
问题:如果是两个线程同时启动呢?
new Thread(futureTask,"线程1").start();
new Thread(futureTask,"线程2").start();
输出:发现也是调用了一次call方法,理由如下!
call方法
线程返回:1024
FutureTask的构造器如下:会有一个state去标记,如果执行了一次,这个状态会变化!下次就不会执行了
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
}6.常用辅助类
1.CountDownLatch(减法计数器)
1.CountDownLatch:减法记数器
有三个重要方法:
1.初始化,并确定计数器最大值
CountDownLatch countDownLatch = new CountDownLatch(6);
2.计数器数量-1
countDownLatch.countDown();
3.等待计数器归0,然后再往下执行
countDownLatch.await();
样例代码如下:
public class CountDownLatch_Test {
public static void main(String[] args) throws InterruptedException {
//重点1:创建CountDownLatch减法计数器,初始值为6
CountDownLatch countDownLatch = new CountDownLatch(6);
for (int i = 0; i < 6; i++) {
//重点2:每个线程间隔2秒启动
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(() -> {
countDownLatch.countDown();
System.out.println(Thread.currentThread().getName() + "当前时间:" + DateTime.now() + ":数量减一 当前数量:" + countDownLatch.getCount());
}, "线程" + i).start();
}
//重点3:等待记数器归0,然后往下执行
countDownLatch.await();
System.out.println("所有线程等待");
}
}
输出:
线程0当前时间:2021-08-04 22:52:54:数量减一 当前数量:6
线程1当前时间:2021-08-04 22:52:56:数量减一 当前数量:5
线程2当前时间:2021-08-04 22:52:58:数量减一 当前数量:4
线程3当前时间:2021-08-04 22:53:00:数量减一 当前数量:3
线程4当前时间:2021-08-04 22:53:02:数量减一 当前数量:2
线程5当前时间:2021-08-04 22:53:04:数量减一 当前数量:1
所有线程等待
注意点:这里不是等待所有线程都执行完毕后再执行countDownLatch.await();后的方法
而是等计数器归0,即执行了countDownLatch.countDown();后,将记数器归0,切记!
所以需要等线程都执行完毕后再执行,可以将countDownLatch.countDown()方法放在每个线程的最后!
场景:需要多个线程执行完毕/或者启动某些线程后,才能执行后续代码!2.CyclicBarrier(加法计数器)
加法记数器:
主要方法:
1.构造方法,第一个参数是从0加到多少时,会执行第二个参数中的方法
CyclicBarrier cyclicBarrier=new CyclicBarrier(7,()->{})
2.该方法,底层会调用--count,但是也会堵塞该线程,cyclicBarrier.await()后面的代码会等CyclicBarrier条件满足后再一起执行,看下执行结果!
cyclicBarrier.await();
样例代码如下:
public class CyclicBarrier_Test {
public static void main(String[] args) throws InterruptedException {
//重点1:构造方法,如果加法计数器上达到最大值7时,会执行下面的输出方法
CyclicBarrier cyclicBarrier=new CyclicBarrier(7,()->{
System.out.println("召唤神龙成功!");
});
for (int i = 0; i < 7; i++){
TimeUnit.SECONDS.sleep(3);
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+":时间:"+ DateTime.now()+" 当前数量:"+cyclicBarrier.getNumberWaiting());
//重点2:该方法底层会调用--count,但是会阻塞住该队列,等条件满足后,会一起执行后续方法!
cyclicBarrier.await();
System.out.println(Thread.currentThread().getName()+"等待完毕!");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
},"线程:"+i).start();
}
}
}
输出:
线程:0:时间:2021-08-04 23:15:45 当前数量:0
线程:1:时间:2021-08-04 23:15:48 当前数量:1
线程:2:时间:2021-08-04 23:15:51 当前数量:2
线程:3:时间:2021-08-04 23:15:54 当前数量:3
线程:4:时间:2021-08-04 23:15:57 当前数量:4
线程:5:时间:2021-08-04 23:16:00 当前数量:5
线程:6:时间:2021-08-04 23:16:03 当前数量:6
召唤神龙成功!
线程:6等待完毕!
线程:0等待完毕!
线程:1等待完毕!
线程:2等待完毕!
线程:4等待完毕!
线程:3等待完毕!
线程:5等待完毕!3.Semaphore(信号量)
常用方法:类似于线程池的概念
1.获取线程资源
semaphore.acquire();
2.释放线程资源:
semaphore.release();
有两个目的:
1.用于多种共享资源的互斥使用
2.用于并发线程的控制
样例代码如下:
public class Semaphore_Test {
public static void main(String[] args) {
//类比停车场:3个停车位,有六辆车
//重点1:规定同时访问的线程数
Semaphore semaphore = new Semaphore(3);
for (int i =0; i < 6; i++){
new Thread(()->{
//1.获取停车位
try {
//重点2:获取线程资源
semaphore.acquire();
System.out.println(Thread.currentThread().getName()+"得到车位,停2秒!");
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
System.out.println(Thread.currentThread().getName()+"开走了..");
//重点3:释放线程资源
semaphore.release();
}
},"线程"+i).start();
}
}
}
输出:
线程2得到车位,停2秒!
线程0得到车位,停2秒!
线程1得到车位,停2秒!
线程0开走了..
线程3得到车位,停2秒!
线程1开走了..
线程4得到车位,停2秒!
线程2开走了..
线程5得到车位,停2秒!
线程5开走了..
线程4开走了..
线程3开走了..
结论:
发现只能有3个线程同时访问,其他的等待!
作用:
1.多个共享资源互斥的使用!
2.并发限流,控制最大额线程数!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!