[转]哈夫曼树
一、哈夫曼树的概念和定义
什么是哈夫曼树?
让我们先举一个例子。
判定树:
if(score<60)
cout<<"Bad"<<endl;
else if(score<70)
cout<<"Pass"<<endl
else if(score<80)
cout<<"General"<<endl;
else if(score<90)
cout<<"Good"<<endl;
else
cout<<"Very good!"<<endl;

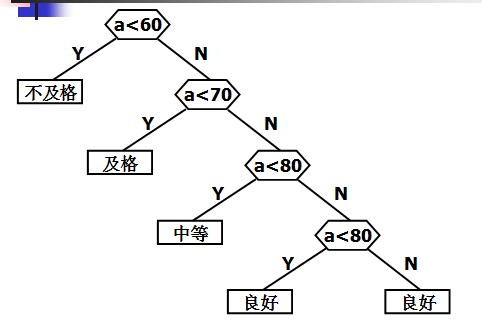
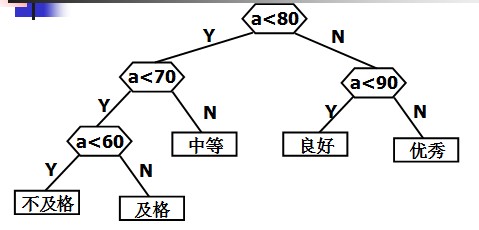
定义哈夫曼树之前先说明几个与哈夫曼树有关的概念:
路径: 树中一个结点到另一个结点之间的分支构成这两个结点之间的路径。
路径长度:路径上的分枝数目称作路径长度。
树的路径长度:从树根到每一个结点的路径长度之和。
结点的带权路径长度:在一棵树中,如果其结点上附带有一个权值,通常把该结点的路径长度与该结点上的权值
之积称为该结点的带权路径长度(weighted path length)
什么是权值?( From 百度百科 )
计算机领域中(数据结构)
权值就是定义的路径上面的值。可以这样理解为节点间的距离。通常指字符对应的二进制编码出现的概率。
至于霍夫曼树中的权值可以理解为:权值大表明出现概率大!
一个结点的权值实际上就是这个结点子树在整个树中所占的比例.
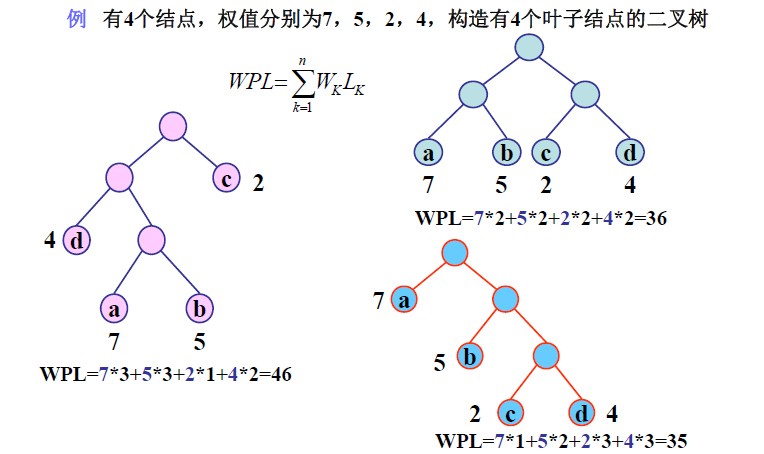
abcd四个叶子结点的权值为7,5,2,4. 这个7,5,2,4是根据实际情况得到的,比如说从一段文本中统计出abcd四个字母出现的次数分别为7,5,2,4. 说a结点的权值为7,意思是说a结点在系统中占有7这个份量.实际上也可以化为百分比来表示,但反而麻烦,实际上是一样的.
树的带权路径长度:如果树中每个叶子上都带有一个权值,则把树中所有叶子的带权路径长度之和称为树的带
权路径长度。
设某二叉树有n个带权值的叶子结点,则该二叉树的带权路径长度记为:
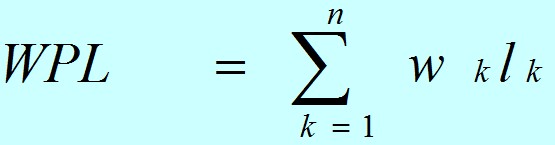
公式中,Wk为第k个叶子结点的权值;Lk为该结点的路径长度。
示例:
二、哈夫曼树的构造


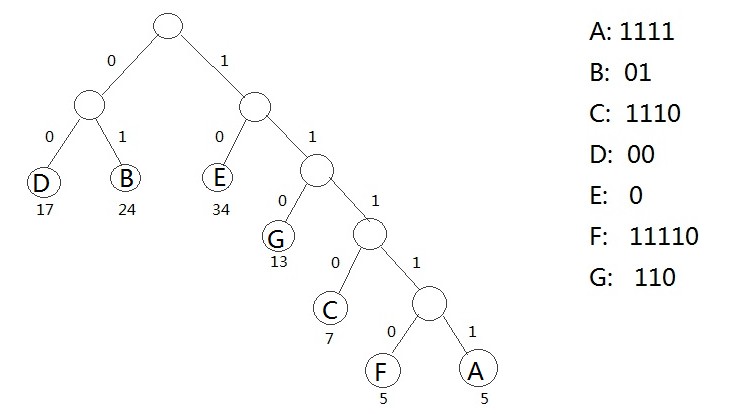
三、哈夫曼树的在编码中的应用
#include<iostream>
#include<cstdio>
#include<cstring>
using namespace std;
#define N 10 // 带编码字符的个数,即树中叶结点的最大个数
#define M (2*N-1) // 树中总的结点数目
class HTNode{ // 树中结点的结构
public:
unsigned int weight;
unsigned int parent,lchild,rchild;
};
class HTCode{
public:
char data; // 待编码的字符
int weight; // 字符的权值
char code[N]; // 字符的编码
};
void Init(HTCode hc[], int *n){
// 初始化,读入待编码字符的个数n,从键盘输入n个字符和n个权值
int i;
printf("input n = ");
scanf("%d",&(*n));
printf("\ninput %d character\n",*n);
fflush(stdin);
for(i=1; i<=*n; ++i)
scanf("%c",&hc[i].data);
printf("\ninput %d weight\n",*n);
for(i=1; i<=*n; ++i)
scanf("%d",&(hc[i].weight) );
fflush(stdin);
}//
void Select(HTNode ht[], int k, int *s1, int *s2){
// ht[1...k]中选择parent为0,并且weight最小的两个结点,其序号由指针变量s1,s2指示
int i;
for(i=1; i<=k && ht[i].parent != 0; ++i){
; ;
}
*s1 = i;
for(i=1; i<=k; ++i){
if(ht[i].parent==0 && ht[i].weight<ht[*s1].weight)
*s1 = i;
}
for(i=1; i<=k; ++i){
if(ht[i].parent==0 && i!=*s1)
break;
}
*s2 = i;
for(i=1; i<=k; ++i){
if(ht[i].parent==0 && i!=*s1 && ht[i].weight<ht[*s2].weight)
*s2 = i;
}
}
void HuffmanCoding(HTNode ht[],HTCode hc[],int n){
// 构造Huffman树ht,并求出n个字符的编码
char cd[N];
int i,j,m,c,f,s1,s2,start;
m = 2*n-1;
for(i=1; i<=m; ++i){
if(i <= n)
ht[i].weight = hc[i].weight;
else
ht[i].parent = 0;
ht[i].parent = ht[i].lchild = ht[i].rchild = 0;
}
for(i=n+1; i<=m; ++i){
Select(ht, i-1, &s1, &s2);
ht[s1].parent = i;
ht[s2].parent = i;
ht[i].lchild = s1;
ht[i].rchild = s2;
ht[i].weight = ht[s1].weight+ht[s2].weight;
}
cd[n-1] = '\0';
for(i=1; i<=n; ++i){
start = n-1;
for(c=i,f=ht[i].parent; f; c=f,f=ht[f].parent){
if(ht[f].lchild == c)
cd[--start] = '0';
else
cd[--start] = '1';
}
strcpy(hc[i].code, &cd[start]);
}
}
int main()
{
int i,m,n,w[N+1];
HTNode ht[M+1];
HTCode hc[N+1];
Init(hc, &n); // 初始化
HuffmanCoding(ht,hc,n); // 构造Huffman树,并形成字符的编码
for(i=1; i<=n; ++i)
printf("\n%c---%s",hc[i].data,hc[i].code);
printf("\n");
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号