
[转]二叉查找树算法的实现
树(Tree)是n(n≥0)个结点的有限集。在任意一棵非空树中:(1)有且仅有一个特定的被称为根(Root)的结点;(2)当n>1时,其余结点可分为m(m>0)个互不相交的有限集T1,T2,…,Tm,其中每一个集合本身又是一棵树,并且称为根的子树(SubTree)。
结点拥有的子树数称为结点的度(Degree)。度为0的结点称为叶子(Leaf)或终端结点。度不为0的结点称为非终端结点或分支结点。
树的度是树内各结点的度的最大值。
结点的子树的根称为该结点的孩子(Child),相应地,该结点称为孩子的双亲(Parent)。
结点的层次(Level)是从根结点开始计算起,根为第一层,根的孩子为第二层,依次类推。树中结点的最大层次称为树的深度(Depth)或高度。
如果将树中结点的各子树看成从左至右是有次序的(即不能互换),则称该树为有序树,否则称为无序树。
1、二叉树
二叉树(Binary Tree)的特点是每个结点至多具有两棵子树(即在二叉树中不存在度大于2的结点),并且子树之间有左右之分。
二叉树的性质:
(1)、在二叉树的第i层上至多有2i-1个结点(i≥1)。
(2)、深度为k的二叉树至多有2k-1个结点(k≥1)。
(3)、对任何一棵二叉树,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。
一棵深度为k且有2k-1个结点的二叉树称为满二叉树。
可以对满二叉树的结点进行连续编号,约定编号从根结点起,自上而下,自左至右,则由此可引出完全二叉树的定义。深度为k且有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1到n的结点一一对应时,称之为完全二叉树。
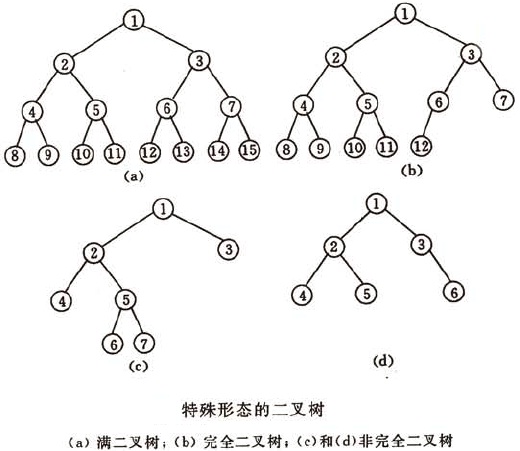
(4)、具有n个结点的完全二叉树的深度为不大于log2n的最大整数加1。
(5)、如果对一棵有n个结点的完全二叉树的结点按层序编号(从第1层到最后一层,每层从左到右),则对任一结点i(1≤i≤n),有
a、如果i=1,则结点i是二叉树的根,无双亲;如果i>1,则其双亲是结点x(其中x是不大于i/2的最大整数)。
b、如果2i>n,则结点i无左孩子(结点i为叶子结点);否则其左孩子是结点2i。
c、如果2i+1>n,则结点i无右孩子;否则其右孩子是结点2i+1。
二叉树的链式存储:
链式二叉树中的每个结点至少需要包含三个域,数据域和左、右指针域。

二叉树的遍历:
假如以L、D、R分别表示遍历左子树、访问根结点和遍历右子树,则可有DLR、DRL、LRD、LDR、RLD、RDL这六种遍历二叉树的方案。若限定先左后右,则只有三种方案,分别称之为先(根)序遍历、中(根)序遍历和后(根)序遍历,它们以访问根结点的次序来区分。
2、二叉查找树
二叉查找树(BinarySearch Tree,也叫二叉搜索树,或称二叉排序树Binary Sort Tree)或者是一棵空树,或者是具有下列性质的二叉树:
(1)、若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值;
(2)、若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值;
(3)、它的左、右子树也分别为二叉查找树。
3、二叉查找树的基本运算
/* bst - binary search/sort tree
* by Richard Tang <tanglinux@gmail.com>
*/
#include <stdio.h>
#include <stdlib.h>
typedef int data_type;
typedef struct bst_node {
data_type data;
struct bst_node *lchild, *rchild;
}bst_t, *bst_p;
(1)、插入
在二叉查找树中插入新结点,要保证插入新结点后仍能满足二叉查找树的性质。例子中的插入过程如下:
a、若二叉查找树root为空,则使新结点为根;
b、若二叉查找树root不为空,则通过search_bst_for_insert函数寻找插入点并返回它的地址(若新结点中的关键字已经存在,则返回空指针);
c、若新结点的关键字小于插入点的关键字,则将新结点插入到插入点的左子树中,大于则插入到插入点的右子树中。
static bst_p search_bst_for_insert(bst_p *root, data_type key)
{
bst_p s, p = *root;
while (p) {
s = p;
if (p->data == key)
return NULL;
p = (key < p->data) ? p->lchild : p->rchild;
}
return s;
}
void insert_bst_node(bst_p *root, data_type data)
{
bst_p s, p;
s = malloc(sizeof(struct bst_node));
if (!s)
perror("Allocate dynamic memory");
s -> data = data;
s -> lchild = s -> rchild = NULL;
if (*root == NULL)
*root = s;
else {
p = search_bst_for_insert(root, data);
if (p == NULL) {
fprintf(stderr, "The %d already exists.\n", data);
free(s);
return;
}
if (data < p->data)
p->lchild = s;
else
p->rchild = s;
}
}
(2)、遍历
static int print(data_type data)
{
printf("%d ", data);
return 1;
}
int pre_order_traverse(bst_p root, int (*visit)(data_type data))
{
if (root) {
if (visit(root->data))
if (pre_order_traverse(root->lchild, visit))
if (pre_order_traverse(root->rchild, visit))
return 1;
return 0;
}
else
return 1;
}
int post_order_traverse(bst_p root, int (*visit)(data_type data))
{
if (root) {
if (post_order_traverse(root->lchild, visit))
if (visit(root->data))
if (post_order_traverse(root->rchild, visit))
return 1;
return 0;
}
else
return 1;
}
中序遍历二叉查找树可得到一个关键字的有序序列。
(3)、删除
删除某个结点后依然要保持二叉查找树的特性。例子中的删除过程如下:
a、若删除点是叶子结点,则设置其双亲结点的指针为空。
b、若删除点只有左子树,或只有右子树,则设置其双亲结点的指针指向左子树或右子树。
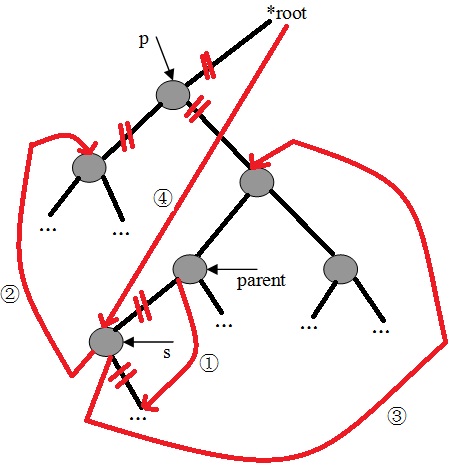
c、若删除点的左右子树均不为空,则:
1)、查询删除点的右子树的左子树是否为空,若为空,则把删除点的左子树设为删除点的右子树的左子树。
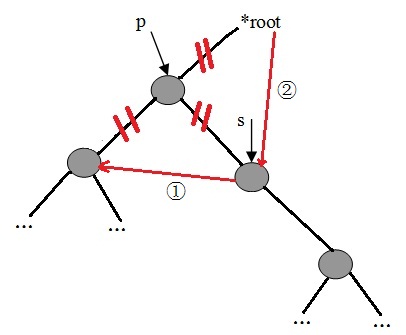
2)、若不为空,则继续查询左子树,直到找到最底层的左子树为止。
void delete_bst_node(bst_p *root, data_type data)
{
bst_p p = *root, parent, s;
if (!p) {
fprintf(stderr, "Not found %d.\n", data);
return;
}
if (p->data == data) {
/* It's a leaf node */
if (!p->rchild && !p->lchild) {
*root = NULL;
free(p);
}
/* the right child is NULL */
else if (!p->rchild) {
*root = p->lchild;
free(p);
}
/* the left child is NULL */
else if (!p->lchild) {
*root = p->rchild;
free(p);
}
/* the node has both children */
else {
s = p->rchild;
/* the s without left child */
if (!s->lchild)
s->lchild = p->lchild;
/* the s have left child */
else {
/* find the smallest node in the left subtree of s */
while (s->lchild) {
/* record the parent node of s */
parent = s;
s = s->lchild;
}
parent->lchild = s->rchild;
s->lchild = p->lchild;
s->rchild = p->rchild;
}
*root = s;
free(p);
}
}
else if (data > p->data) {
delete_bst_node(&(p->rchild), data);
}
else if (data < p->data) {
delete_bst_node(&(p->lchild), data);
}
}
4、二叉查找树的查找分析
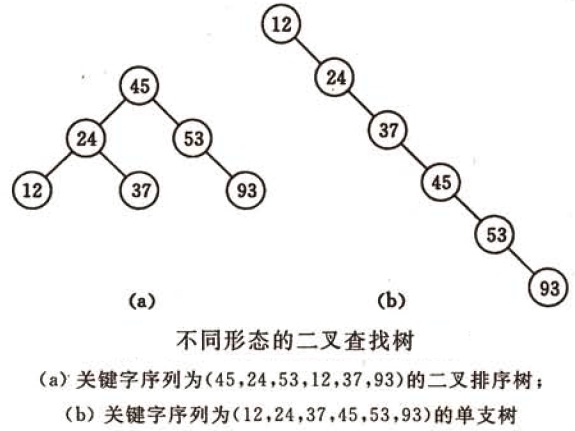
同样的关键字,以不同的插入顺序,会产生不同形态的二叉查找树。
int main(int argc, char *argv[])
{
int i, num;
bst_p root = NULL;
if (argc < 2) {
fprintf(stderr, "Usage: %s num\n", argv[0]);
exit(-1);
}
num = atoi(argv[1]);
data_type arr[num];
printf("Please enter %d integers:\n", num);
for (i = 0; i < num; i++) {
scanf("%d", &arr[i]);
insert_bst_node(&root, arr[i]);
}
printf("\npre order traverse: ");
pre_order_traverse(root, print);
printf("\npost order traverse: ");
post_order_traverse(root, print);
printf("\n");
delete_bst_node(&root, 45);
printf("\npre order traverse: ");
pre_order_traverse(root, print);
printf("\npost order traverse: ");
post_order_traverse(root, print);
printf("\n");
return 0;
}
运行两次,以不同的顺序输入相同的六个关键字:
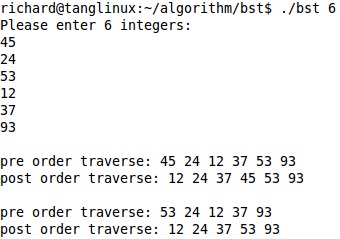

根据前序遍历的结果可得到两次运行所产生的二叉查找树的形态并不相同,如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号