散列

散列的定义
散列(hash)常用的算法思想之一。
一般来说,将一个元素通过一个函数转换为一个整数,使得该整数可以尽量唯一的代表这个元素。
这个转换函数称为散列函数 H,也就是说,转换之前为key,转换之后就变成了一个整数H(key)。
对key是整数的情况有以下方法:
直接定址法:恒等变换即H(key)=key。以下问题即是。
还有线性变换H(key)=a*key+b;平方取中法;
问题:给出N个正整数,M个正整数;问这M个数中的每个数是否在N个数中出现过?(N,M<=100000,且所有正整数均不超过10^5)
思路:空间换时间,即设定一个bool型数组HashTable[100010],其中HashTable[x]==ture表示正整数x在N个正整数中出现过。
这样,就可以在一开始读入N个正整数时就进行预处理。
显然,这种时间复杂度为O(N+M)。
/* 给出N个正整数,M个正整数;问这M个数中的每个数是否在N个数中出现过? (N,M<=100000,且所有正整数均不超过10^5) */ #include<iostream> using namespace std; const int maxn=100010; bool hashTable[maxn]={false}; int main() { int n,m,x; cout << "n="; cin >> n; cout << "m="; cin >> m; for(int i=0;i<n;i++) { cin >> x; hashTable[x]=true; //数字x出现过 } for(int i=0;i<m;i++) { cin >> x; if(hashTable[x]==true) //如果再次出现x,则输出YES { cout << x << " YES!" << endl; } else { cout << x << " NO!" << endl; } } return 0; }
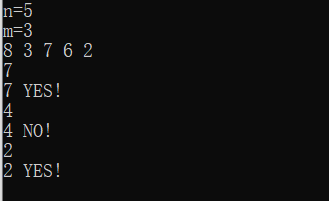
如果,要求M个欲查询的数中每个数在N个数中出现的次数?
思路,把hasnTable数组替换为int型,然后在输入N个数时进行预处理。即当输入x时,令hashTable[x]++。
/*求每个数出现的次数*/ #include<iostream> using namespace std; const int maxn=100010; int hashTable[maxn]={0}; int main() { int n,m,x; cout << "N="; cin >> n; cout << "M="; cin >> m; for(int i=0;i<n;i++) { cin >> x; hashTable[x]++; } for(int j=0;j<m;j++) { cin >> x; cout << hashTable[x] << endl; } return 0; }
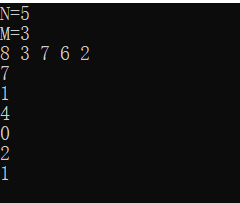
两个问题的共同的特点就是把输入的数作为数组的下标直接使用。
一般来说,常用的是除留余数法
是指把key除以一个数mod得到的余数作为hash值。
即H(key)=key%mod
可以将很大的数转换为不超过mod的数。这样就可以作为数组的下标。
(表长不可以超过mod,不然会越界)
显然,当mod是一个素数时,H(key)能尽可能覆盖[0,mod)范围内的每个数。
“冲突”情况:不同的数key1和key2的hash值是相同的。——不可避免。
三种方法:
线性探查法:当得到key的hash值H(key),但表中下表为H(key)的位置已经被占领时,那就检查下一个位置H(key)+1是否被占,如果没有就使用这个位置;否则就检查下一个位置。如果检查过程中超过了表长,那就回到表的首位置继续循环,直到找到一个可使用的位置。或者发现表中的所有位置都被使用。
显然,这种做法很容易扎堆,即连续若干个位置都被使用。
平方探查法:为尽可能避免扎堆现象,当下标为H(key)的位置被占时,将按下面的顺序检查表的位置:
H(key)+1^2,H(key)-1^2,H(key)+2^2,H(key)-2^2,H(key)+3^2,……
如果检查过程中,H(key)+k^2的值超过表长TSize,就把H(key)+k^2对表长TSize取模。
如果出现H(key)-k^2<0的情况,将((H(key)-k^2)%TSize+TSize)%TSize作为结果。
链地址法(拉链法):
不计算新得hash值而是把所有H(key)相同的key连接成一条单链表。
可以设定一个数组Link,范围是Link[0]~Link[mod-1],其中Link[h]存放H(key)=h的一条单链表。
字符串hash初步
字符串hash是指将一个字符串S映射成一个整数,使得该整数可以尽可能唯一的代表字符串S。
为讨论问题方便,先假设字符串均为大写字母A~Z构成。
在这个基础上不妨把A~Z视为0~25,这样就把26个大写字母对应到二十六进制中。
//hash函数,将字符串转换成整数 int hashFunc(char S[],int len) { int id=0; for(int i=0;i<len;i++) { id=id*26+(S[i]-'A'); //将二十六进制转换为十进制 } return id; }
需要注意len的值不能太大,转换成的数最大为26^len-1,len为字符串长度。
如果字符串中出现小写字母,那么把A~Z作为0~25,把a~z作为26~51——52进制问题
int hashFunc(char S[],int len) //将字符串转换为整数 { int id=0; for(int i=0;i<len;i++) { if(S[i]>='A'&&S[i]<='Z'){ id=id*52+(S[i]-'A'); } else if(S[i]>='a'&&S[i]<='z'){ id=id*52+(S[i]-'a')+26; } } return id; }
如果出现数字:
1.增大进制至62
2.如果保证在字符串末尾是确定个数的数字,就把后面的数字拼接上去。
//字符数字混合,例:BCD4 int hashFunc(char S[],int len) { int id=0; for(int i=0;i<len-1;i++) //末位为数字,因此除末尾 { id=id*26+(S[i]-'A'); } id=id*10+(S[len-1]-'0'); retur id; }
#include<iostream> using namespace std; const int maxn=1000; char S[maxn][5],temp[5]; int hashTable[26*26*26+10]; int hashFunc(char S[],int len) { int id=0; for(int i=0;i<len;i++) id=id*26+(S[i]-'A'); return id; } int main() { int n,m; cin >> n >> m; for(int i=0;i<n;i++) { cin >> S[i]; int id=hashFunc(S[i],3); //将字符串S[i]转换为整数 hashTable[id]++; //将字符串的出现次数加一 } for(int i=0;i<m;i++) { cin >> temp; int id=hashFunc(temp,3); //将字符串temp转换为整数 cout << hashTable[id] << endl; } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号