
py15 面向对象编程
新式类与经典类的区别
python中类的发展
➤截止到python2.1,只存在旧式类。旧式类中,类名和type是无关的:如果x是一个旧式类,那么x.__class__定义了x的类名,但是type(x)总是返回<type 'instance'>。这反映了所有的旧式类的实例是通过一个单一的叫做instance的内建类型来实现的,这是它和类不同的地方。
➤新式类是在python2.2为了统一类和实例引入的。一个新式类只能由用户自定义。如果x是一个新式类的实例,那么type(x)和x.__class__是一样的结果(尽管这不能得到保证,因为新式类的实例的__class__方法是允许被用户覆盖的)。
➤Python 2.x中默认都是经典类,只有显式继承了object才是新式类
➤Python 3.x中默认都是新式类,经典类被移除,不必显式的继承object
新式类与经典类的区别
➤新式类都从object继承,经典类不需要。
➤新式类相同父类只执行一次构造函数,经典类重复执行多次。
➤区分方式:type(classname)
-新式类:type
-经典类: classobj
➤新式类的MRO(method resolution order 基类搜索顺序)算法采用C3算法广度优先搜索,而旧式类的MRO算法是采用深度优先搜索
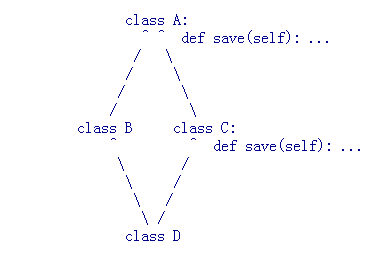
#经典类 class A: def __init__(self): print 'this is A' def save(self): print 'come from A' class B(A): def __init__(self): print 'this is B' class C(A): def __init__(self): print 'this is C' def save(self): print 'come from C' class D(B,C): def __init__(self): print 'this is D' d1=D() d1.save() #结果为'come from A
#新式类
class A(object): def __init__(self): print 'this is A'
def save(self): print 'come from A'
class B(A): def __init__(self): print 'this is B'
class C(A): def __init__(self): print 'this is C'
def save(self): print 'come from C'
class D(B,C): def __init__(self): print 'this is D' d1=D() d1.save() #结果为'come from C'
类会产生新的名称空间,用来存放类的变量名与函数名,可以通过类名.__dict__查看
对于经典类来说我们可以通过该字典操作类名称空间的名字(新式类有限制),但python为我们提供专门的.语法,点是访问属性的语法,类中定义的名字,都是类的属性
# .专门用来访问属性,本质操作的就是__dict__ print(type(OldClass), OldClass.__dict__['school']) # 等于经典类的操作OldboyStudent.__dict__['school']
print(type(NewClass), NewClass.__dict__['school'])
OldClass.school='Oldboy123' # 等于经典类的操作OldboyStudent.__dict__['school']='Oldboy' print(OldClass.school) # OldClass.x=1 #等于经典类的操作OldboyStudent.__dict__['x']=1 # del OldboyStudent.x #等于经典类的操作OldboyStudent.__dict__.pop('x')
(<type 'classobj'>, 'oldboy')
(<type 'type'>, 'oldboy')
Oldboy123
python为类内置的特殊属性
- 类名.__name__# 类的名字(字符串)
- 类名.__doc__# 类的文档字符串
- 类名.__base__# 类的第一个父类(在讲继承时会讲)
- 类名.__bases__# 类所有父类构成的元组(在讲继承时会讲)
- 类名.__dict__# 类的字典属性(能够查看类或对象中的所有成员)
- 类名.__module__#类定义所在的模块
- 类名.__class__# 实例对应的类(仅新式类中)
- __slots__,内存优化,不建议使用
''' 1.__slots__是什么:是一个类变量,变量值可以是列表,元祖,或者可迭代对象,也可以是一个字符串(意味着所有实例只有一个数据属性) 2.引子:使用点来访问属性本质就是在访问类或者对象的__dict__属性字典(类的字典是共享的,而每个实例的是独立的) 3.为何使用__slots__:字典会占用大量内存,如果你有一个属性很少的类,但是有很多实例,为了节省内存可以使用__slots__取代实例的__dict__ 当你定义__slots__后,__slots__就会为实例使用一种更加紧凑的内部表示。实例通过一个很小的固定大小的数组来构建,而不是为每个实例定义一个 字典,这跟元组或列表很类似。在__slots__中列出的属性名在内部被映射到这个数组的指定小标上。使用__slots__一个不好的地方就是我们不能再给 实例添加新的属性了,只能使用在__slots__中定义的那些属性名。 4.注意事项:__slots__的很多特性都依赖于普通的基于字典的实现。另外,定义了__slots__后的类不再 支持一些普通类特性了,比如多继承。大多数情况下,你应该 只在那些经常被使用到 的用作数据结构的类上定义__slots__比如在程序中需要创建某个类的几百万个实例对象 。 关于__slots__的一个常见误区是它可以作为一个封装工具来防止用户给实例增加新的属性。尽管使用__slots__可以达到这样的目的,但是这个并不是它的初衷。 更多的是用来作为一个内存优化工具。 ''' class Foo: __slots__='x' f1=Foo() f1.x=1 f1.y=2#报错 print(f1.__slots__) #f1不再有__dict__ class Bar: __slots__=['x','y'] n=Bar() n.x,n.y=1,2 n.z=3#报错 __slots__使用 - 类名.__str__,类名.__repr,类名.__format__
- #如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返回值,案例如下
# Tools:Pycharm 2017.3.2 # author ="wlx" __date__ = '2018/8/14 17:37' #_*_coding:utf-8_*_ __author__ = 'Linhaifeng' format_dict={ 'nat':'{obj.name}-{obj.addr}-{obj.type}',#学校名-学校地址-学校类型 'tna':'{obj.type}:{obj.name}:{obj.addr}',#学校类型:学校名:学校地址 'tan':'{obj.type}/{obj.addr}/{obj.name}',#学校类型/学校地址/学校名 } class School: def __init__(self,name,addr,type): self.name=name self.addr=addr self.type=type def __repr__(self): return 'School(%s,%s)' %(self.name,self.addr) def __str__(self): return '(%s,%s)' %(self.name,self.addr) def __format__(self, format_spec): # if format_spec if not format_spec or format_spec not in format_dict: format_spec='nat' fmt=format_dict[format_spec] return fmt.format(obj=self) s1=School('oldboy1','北京','私立') print('from repr: ',repr(s1)) print('from str: ',str(s1)) print(s1) ''' str函数或者print函数--->obj.__str__() repr或者交互式解释器--->obj.__repr__() 如果__str__没有被定义,那么就会使用__repr__来代替输出 注意:这俩方法的返回值必须是字符串,否则抛出异常 ''' print(format(s1,'nat')) print(format(s1,'tna')) print(format(s1,'tan')) print(format(s1,'asfdasdffd')) - 类名.__init__ # 构造方法,通过类创建对象时,自动触发执行。
- 类名.__del__ # 析构方法,当对象在内存中被释放时,自动触发执行。注:此方法一般无须定义,因为Python是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给Python解释器来执行,所以,析构函数的调用是由解释器在进行垃圾回收时自动触发执行的
- 类名. __call__ # 对象后面加括号或者 类()(),触发执行,对象执行生成对象类的call,类()()执行父类的call
注:构造方法的执行是由创建对象触发的,即:对象 = 类名() ;而对于 __call__ 方法的执行是由对象后加括号触发的,即:对象() 或者 类()() class Foo: def __init__(self): pass def __call__(self, *args, **kwargs): print '__call__' obj = Foo() # 执行 __init__ obj() # 执行 __call__
- .__getitem__、__setitem__、__delitem__ # 用于索引操作,如字典。以上分别表示获取、设置、删除数据
__setattr__,__delattr__,__getattr__
class Foo: def __init__(self,name): self.name=name def __getitem__(self, item): print(self.__dict__[item]) def __setitem__(self, key, value): self.__dict__[key]=value def __delitem__(self, key): print('del obj[key]时,我执行') self.__dict__.pop(key) def __delattr__(self, item): print('del obj.key时,我执行') self.__dict__.pop(item) f1=Foo('sb') print(f1.__dict__) f1['age']=18 # 自动调用setitem f1['age1']=19 print(f1.__dict__) res = f1['age'] # 自动调用getitem del f1.age1 # 自动调用delattr print(f1.__dict__) del f1['age'] # 自动调用delitem f1['name']='alex' print(f1.__dict__) ############## {'name': 'sb'} {'name': 'sb', 'age': 18, 'age1': 19} 18 del obj.key时,我执行 {'name': 'sb', 'age': 18} del obj[key]时,我执行 {'name': 'alex'} -
class Foo: x=1 def __init__(self,y): self.y=y def __getattr__(self, item): print('----> from getattr:你找的属性不存在') def __setattr__(self, key, value): print('----> from setattr') # self.key=value #这就无限递归了,你好好想想 # self.__dict__[key]=value #应该使用它 def __delattr__(self, item): print('----> from delattr') # del self.item #无限递归了 self.__dict__.pop(item) #__setattr__添加/修改属性会触发它的执行 f1=Foo(10) print(f1.__dict__) # 因为你重写了__setattr__,凡是赋值操作都会触发它的运行,你啥都没写,就是根本没赋值,除非你直接操作属性字典,否则永远无法赋值 f1.z=3 print(f1.__dict__) #__delattr__删除属性的时候会触发 f1.__dict__['a']=3#我们可以直接修改属性字典,来完成添加/修改属性的操作 del f1.a print(f1.__dict__) #__getattr__只有在使用点调用属性且属性不存在的时候才会触发 f1.xxxxxx 三者的用法演示
反射
hasattr,getattr,setattr,delattr
class BlackMedium:
feature = 'Ugly'
def __init__(self, name, addr):
self.name = name
self.addr = addr
def sell_house(self):
print('%s 黑中介卖房子啦,傻逼才买呢,但是谁能证明自己不傻逼' % self.name)
def rent_house(self):
print('%s 黑中介租房子啦,傻逼才租呢' % self.name)
b1 = BlackMedium('万成置地', '回龙观天露园')
# 检测是否含有某属性
print(hasattr(b1, 'name'))
print(hasattr(b1, 'sell_house'))
print(hasattr(b1, 'age'))
# 获取属性
n = getattr(b1, 'name')
print(n)
func = getattr(b1, 'rent_house')
func()
# getattr(b1,'aaaaaaaa') #报错
print(getattr(b1, 'aaaaaaaa', '不存在啊'))
# 设置属性
setattr(b1, 'sb', True)
setattr(b1, 'show_name', lambda self: self.name + 'sb')
print(b1.__dict__)
print(b1.show_name(b1))
# 删除属性
delattr(b1, 'addr')
delattr(b1, 'show_name')
delattr(b1, 'show_name111') # 不存在,则报错
print(b1.__dict__)
模块中使用反射
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import sys
def s1():
print 's1'
def s2():
print 's2'
this_module = sys.modules[__name__]
hasattr(this_module, 's1')
getattr(this_module, 's2')
反射当前模块成员
类的构造函数与实例化过程详解
构造函数的作用为:初始化类内的各种属性
构造函数示例:
class Role(object): #定义一个类, class是定义类的语法,Role是类名
def __init__(self,name,role,weapon,life_value=100,money=15000): #初始化函数,在生成一个角色时要初始化的一些属性就填写在这里
self.name = name #__init__中的第一个参数self,和这里的self都 是什么意思? 看下面解释
self.role = role
self.weapon = weapon
self.life_value = life_value
self.money = money
def sayhi(self): # 为什么类内定义的函数第一个参数都是self?有什么作用?
print("hello,I am a dog, my name is ",self.name)
如何理解self和实例化过程?
理解self和实例化的过程,要先了解实例化的几种方法。例如java中,java的实例化如下图
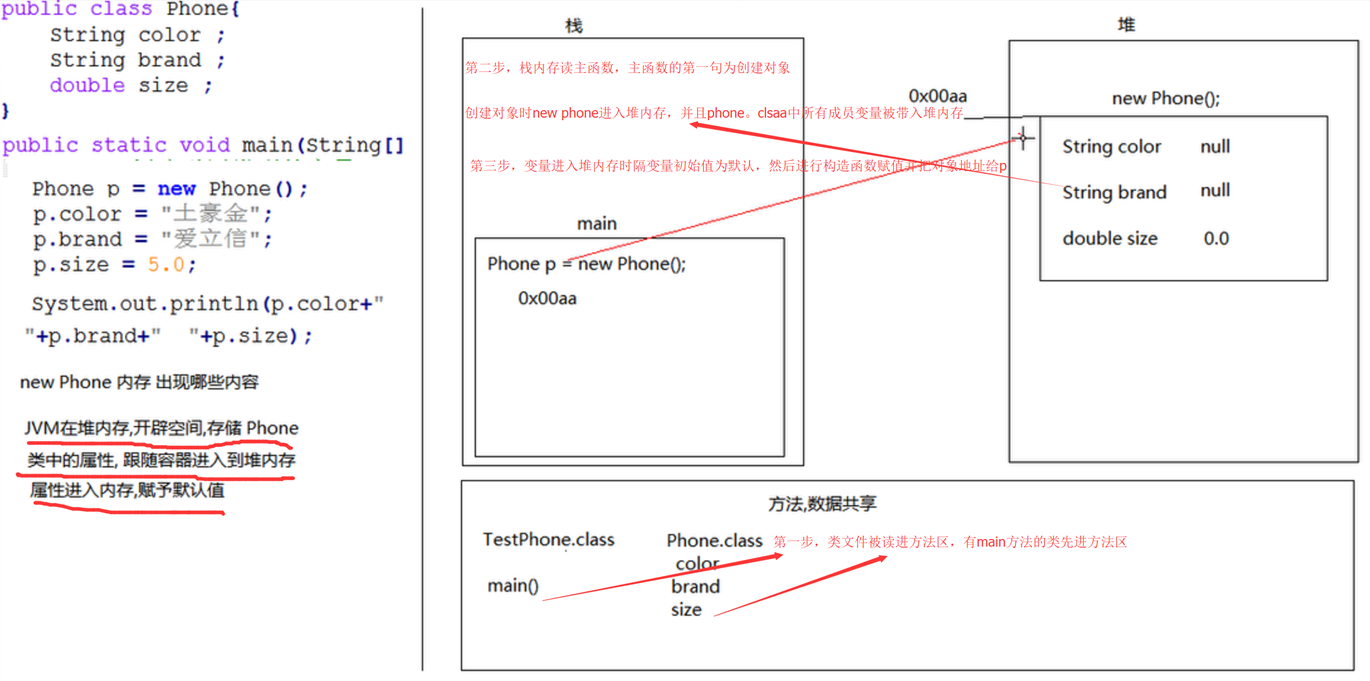

当main方法结束之后p就没有了,指向堆内存的地址就断开了,堆内存就释放了
在java的实例化过程中,创建对象语句先进对内存,成员变量置空,然后调用构造函数,初始化成员变量,然后把内存给栈内的对象p
python中的实例化
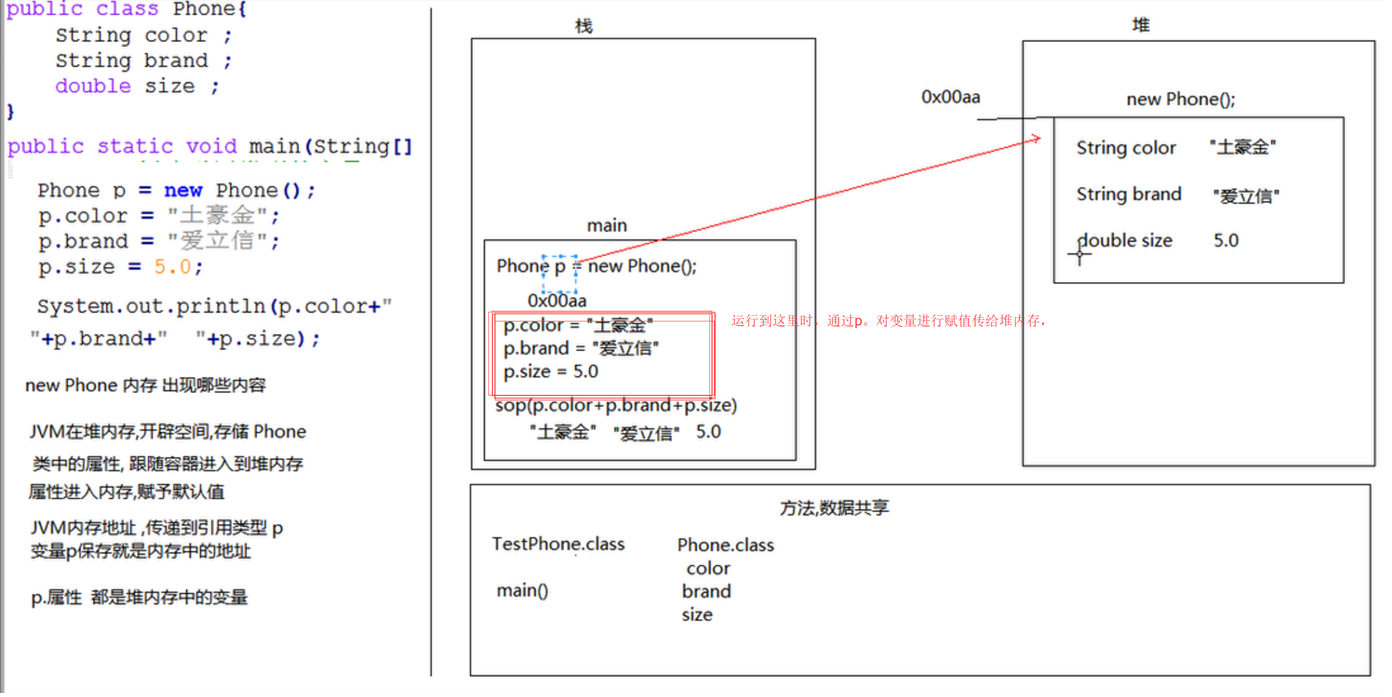
相比,在python中,实例化对象并没有采用java式的实例化方式,下面讲解python实例化方式和self的作用,有下面两个实例化语句:
实例化时相当于给__init__()函数传参,self自动传,不需要手动写。
r1 = Role('Alex','police','AK47’) #此时self 相当于 r1 , Role(r1,'Alex','police','AK47’)
r2 = Role('Jack','terrorist','B22’)#此时self 相当于 r2, Role(r2,'Jack','terrorist','B22’)
这里你一定会问为什么会自动传一个self参数呢,不是像java那样吧实例化后的地址给r1么?
- 在内存中开辟一块空间指向r1这个变量名(并不是开辟空间存各种初始化信息然后传地址)
- 调用Role这个类并执行其中的__init__(…)方法,相当于Role.__init__(r1,'Alex','police',’AK47’), 相当于把'Alex','police',’AK47’各成员变量都放到r1(self)的地址下,如此实现了成员变量和对象之间的关联,关联起来后,就可以直接r1.name, r1.weapon 这样来调用啦。所以,为实现这种关联,在调用__init__方法时,就必须把r1这个变量也传进去,否则__init__不知道要把那3个参数跟谁关联呀。
- 此时self.name = name , self.role = role 等等的意思就是要把这几个值 存到r1的内存空间里。
- 还没完,这里只是说构造函数中的self作用,还没解释为什么各个方法里也全都有self
现在我们知道了,实例化时通过构造函数,已经完成了成员变量和对象之间的关联,但是,对象里面还没有关联函数(方法)啊?
其实这里并没有给对象r1关联方法,而是用到类的方法时把r1(self)传给该函数,然后通过函数里的self.xxx进行使用,如下:
def buy_gun(self,gun_name):
print(“%s has just bought %s” %(self.name,gun_name) )
r1 = Role('Alex','police','AK47')
r1.buy_gun("B21”) #python 会自动帮你转成 Role.buy_gun(r1,”B21")
执行结果
#Alex has just bought B21
类变量和实例变量
类变量:类变量直接定义在类中且在函数体之外,类变量在整个实例化的对象中是公用的。
实例变量:定义在方法中的变量,只作用于当前实例。(对象调用时,实例变量和类变量重名以实例变量为先)
obj.name会先从obj自己的名称空间里找name,找不到则去类中找,类也找不到就找父类...最后都找不到就抛出异常
class Role:
n = 123 # 类变量
n_list = []
name = "我是类name"
def __init__(self, name, role, weapon, life_value=100, money=15000):
# 构造函数
# 在实例化时做一些类的初始化的工作
self.name = name # r1.name=name实例变量(静态属性),作用域就是实例本身
self.role = role
self.weapon = weapon
self.__life_value = life_value
self.money = money
def __del__(self):
pass # print("%s 彻底死了。。。。" %self.name)
r1 = Role('Chenronghua', 'police', 'AK47')
r2 = Role('jack', 'terrorist', 'B22')
看到这里时,你应该明白了python实例化时做了什么,类变量和实例变量的区别,那么问个问题来检验一下,在实例化之后,对对象r1赋一个新实例变量,是否符合语法?
r1.n_list.append('123')
r2.n_list.append('456')
print(r2.n_list)
# ['123', '456']
注意这种.append()形式并没有对r1创建新的实例变量,而是直接对类变量n_list进行操作
但是下面这种则是创建了r1的新实例变量
r1.n_list = ['879']
r2.n_list.append('456')
print(r2.n_list)
# ['456']
这种形式,相当于创建了r1的新实例变量,对类变量n_list没有影响
你以为你理解了么,试试下面的代码,看看输出和你预料的是不是一样的:
class D:
a = 10
def __init__(self):
self.b = 10
d1 = D()
d2 = D()
d1.a += 1
print(d1.a, d2.a)
D.a = 100
print(d1.a, d2.a)
这两个print的输出都是什么?结果如下:
11 10 11 100
如果你的预料的不对,去上面几行找答案吧
如何给对象添加类中没有的函数
不推荐使用,知道即可
class A:
def __init__(self, name, age, sex):
self.name = name
self.age = age
self.sex = sex
def speak(self): # 绑定和参数有关的函数
print('%s is roaring' %self.name)
def call(): # 绑定和参数无关的函数
print('someone is roaring')
a = A('wei', 18, 'male')
a.speak = speak
a.speak(a) # 参数有关,要传self(对象自身)
a.call = call
a.call()
print(a.__dict__)
################
wei is roaring
someone is roaring
{'name': 'wei', 'age': 18, 'sex': 'male', 'speak': <function speak at 0x000002689C702E18>, 'call': <function call at 0x00000268ABDBE268>}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号