redis的线程模型 与 压力测试
为什么redis要用单线程
我们知道,一般使用多线程可以增加系统吞吐率,但是如果没有经过良好的系统设计的话,线程数量上升到一定级别时,系统吞吐量反而会下降。出现这个情况的主要原因就是多个线程共享同一个数据结构时,为了保证共享资源的正确性、那就必须有额外机制进行保证,而这个额外机制就会带来性能开销降低吞吐量。比如redis的list数据结构通过lpop/lpush来操作队列,如果是多个线程同时进行操作,最后得到的数据一定就会有问题。
现在的redis6.X号称多线程,其实也只是在处理网络数据读写和协议解析上而已,底层的数据操作还是单线程。
redis线程模型
当客户端与ServerSocket产生连接时,会产生一个 AE_REABLE / AE_WRITABL 事件, 多个Socket可能并发产生不同的事件,IO多路复用程序会监听这些Socket,按照顺序将这些Socket放到队列中排队。然后每次从队列中取出一个Socket来进行相应的操作。(这种io多路复用+事件驱动模式,在redis和netty中得到了很好的应用)

*IO多路复用:可以参考我的这篇博客https://www.cnblogs.com/wlwl/p/10293057.html
下面举一个例子来说明io多路复用,模拟一个tcp服务器处理30个客户socket。
假设你是一个老师,让30个学生解答一道题目,然后检查学生做的是否正确,你有下面几个选择:
1. 第一种选择:按顺序逐个检查,先检查A,然后是B,之后是C、D。。。这中间如果有一个学生
卡主,全班都会被耽误。这种模式就好比,你用循环挨个处理socket,根本不具有并发能力。
2. 第二种选择:你创建30个分身,每个分身检查一个学生的答案是否正确。 这种类似于为每一个
用户创建一个进程或者线程处理连接。
3. 第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下
去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。。。 这种就是IO复用模型。
*文件事件处理器:
如果是客户端要连接redis,那么会为socket关联连接应答处理器
如果是客户端要写数据到redis,那么会为socket关联命令请求处理器
如果是客户端要从redis读数据,那么会为socket关联命令回复处理器
*客户端与redis通信的一次流程:
在redis启动初始化的时候,redis会将连接应答处理器跟AE_READABLE事件关联起来,接着如果一个客户端跟redis发起连接,此时会产生一个AE_READABLE事件,然后由连接应答处理器来处理跟客户端建立连接,创建客户端对应的socket,同时将这个socket的AE_READABLE事件跟命令请求处理器关联起来。
当客户端向redis发起请求的时候(不管是读请求还是写请求,都一样),首先就会在socket产生一个AE_READABLE事件,然后由对应的命令请求处理器来处理。这个命令请求处理器就会从socket中读取请求相关数据,然后进行执行和处理。接着redis这边准备好了给客户端的响应数据之后,就会将socket的AE_WRITABLE事件跟命令回复处理器关联起来,当客户端这边准备好读取响应数据时,就会在socket上产生一个AE_WRITABLE事件,会由对应的命令回复处理器来处理,就是将准备好的响应数据写入socket,供客户端来读取。
命令回复处理器写完之后,就会删除这个socket的AE_WRITABLE事件和命令回复处理器的关联关系。
*为啥redis单线程模型也能效率这么高?
1)简洁的命令表达式
2)纯内存操作
3)核心是基于非阻塞的IO多路复用机制
4)单线程反而避免了多线程的频繁上下文切换问题
压力测试
redis自带redis-benchmark这个压力测试工具,我以一台2G2核的虚拟机为例做一下压力测试:
cd /redis/bin
*1. 模拟100个连接,一共发起100000个请求,它会打印出redis各个命令的执行效率
./redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 100000
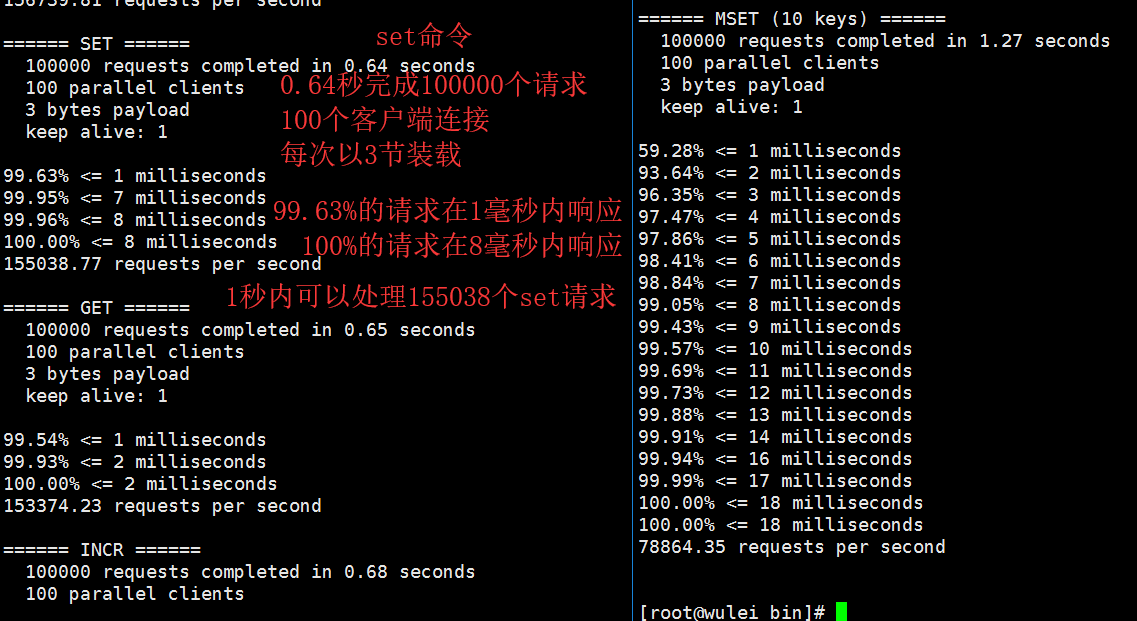
2. 查看简单信息:
以100个字节装载来压测 (-q表示简单信息,只会打印出每个命令的每秒处理请求个数)
./redis-benchmark -h 127.0.0.1 -p 6379 -q -d 100

3. 查看指定命令每秒处理请求量
查看set/lpush命令的tps
./redis-benchmark -t set,lpush -n 10000 -q


 浙公网安备 33010602011771号
浙公网安备 33010602011771号