mycat简易入门
环境:jdk8 mysql5.6 mycat1.4
mysql5.6 安装教程 : https://www.cnblogs.com/wlwl/p/9988245.html
Mycat支持的命令:
console 启动(控制台打印启动信息) start 普通启动 stop 停止
restart 重启 status 查看状态 dump 数据导出
mycat的默认端口号为:8066
【mycat安装】
1. 下载mycat https://github.com/MyCATApache/Mycat-download
2. cd /usr/local/wulei 上传mycat到服务器
3. 解压 tar -zxvf Mycat-server-1.4-release-20151019230038-linux.tar.gz 得到mycat文件夹
4. 测试 进到bin目录启动mycat cd mycat/bin ./mycat start ./mycat stop
5. 查看配置文件 vim mycat/conf/schema.xml 我这里把多余的注释都删了,看起来会清爽些!
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- testdb:逻辑库的库名,我们程序就是连的它,这个名称可以自定义。 --> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <!-- table:逻辑表 name:表名 dataNode:数据节点 rule:分片规则 auto-sharding-long规则是按照id分片,只能存储1500W条数据,多了就存不下了 --> <table name="travelrecord" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> <!-- 全局表被自动克隆到所有已定义的数据节点,因此可以连接任何表的分片节点都在同一个数据节点中 --> <table name="company" primaryKey="ID" type="global" dataNode="dn1,dn2,dn3" /> <table name="goods" primaryKey="ID" type="global" dataNode="dn1,dn2" /> <!-- 使用mod sharind规则随机分片 --> <table name="hotnews" primaryKey="ID" dataNode="dn1,dn2,dn3" rule="mod-long" /> <table name="employee" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile" /> <table name="customer" primaryKey="ID" dataNode="dn1,dn2" rule="sharding-by-intfile"> <childTable name="orders" primaryKey="ID" joinKey="customer_id" parentKey="id"> <childTable name="order_items" joinKey="order_id" parentKey="id" /> </childTable> <childTable name="customer_addr" primaryKey="ID" joinKey="customer_id" parentKey="id" /> </table> </schema>
<!-- dataNode:数据节点 dataHost:节点主机 database:物理库库名 --> <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost1" database="db2" /> <dataNode name="dn3" dataHost="localhost1" database="db3" />
<!-- 主机配置 一台服务器一个<dataHost>节点,集群环境下就有多个 --> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- 主节点(可多个) --> <writeHost host="hostM1" url="localhost:3306" user="root"password="123456"></writeHost> <!-- 从节点(可多个) --> <writeHost host="hostS1" url="localhost:3316" user="root" password="123456" /> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost>
</mycat:schema>
上面我们已经安装完成了,并对核心配置文件有了一个大致的认识。下面就开始配置一个集群分片~
==========================================================
我们这里也是伪集群,真实情况下都是一台服务器一个数据库。所以下图的<dataHost>标签会有多个,每一个<dataNode>和<dataHost>对应就好了 !
【一:简单测试】
1. 创建三个物理库 (如下图)
2. vim mycat/conf/schema.xml (如下图)
3. vim mycat/conf/server.xml (如下图)
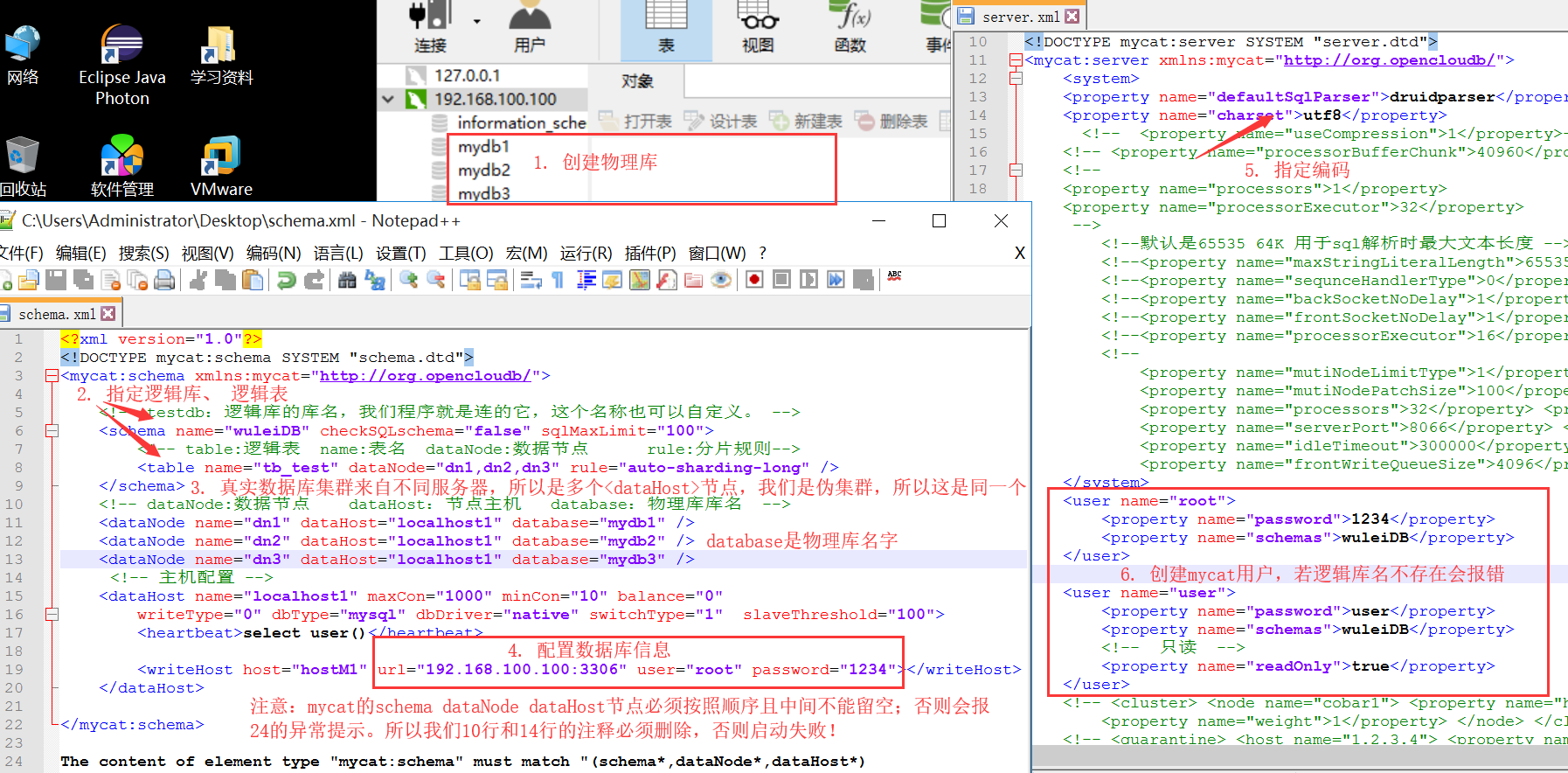
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://org.opencloudb/"> <!-- testdb:逻辑库的库名,我们程序就是连的它,这个名称也可以自定义。 --> <schema name="wuleiDB" checkSQLschema="false" sqlMaxLimit="100"> <!-- table:逻辑表 name:表名 dataNode:数据节点 rule:分片规则--> <table name="tb_test" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" /> </schema> <dataNode name="dn1" dataHost="localhost1" database="mydb1" /> <dataNode name="dn2" dataHost="localhost1" database="mydb2" /> <dataNode name="dn3" dataHost="localhost1" database="mydb3" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1" url="192.168.100.100:3306" user="root" password="1234"></writeHost> </dataHost> </mycat:schema>
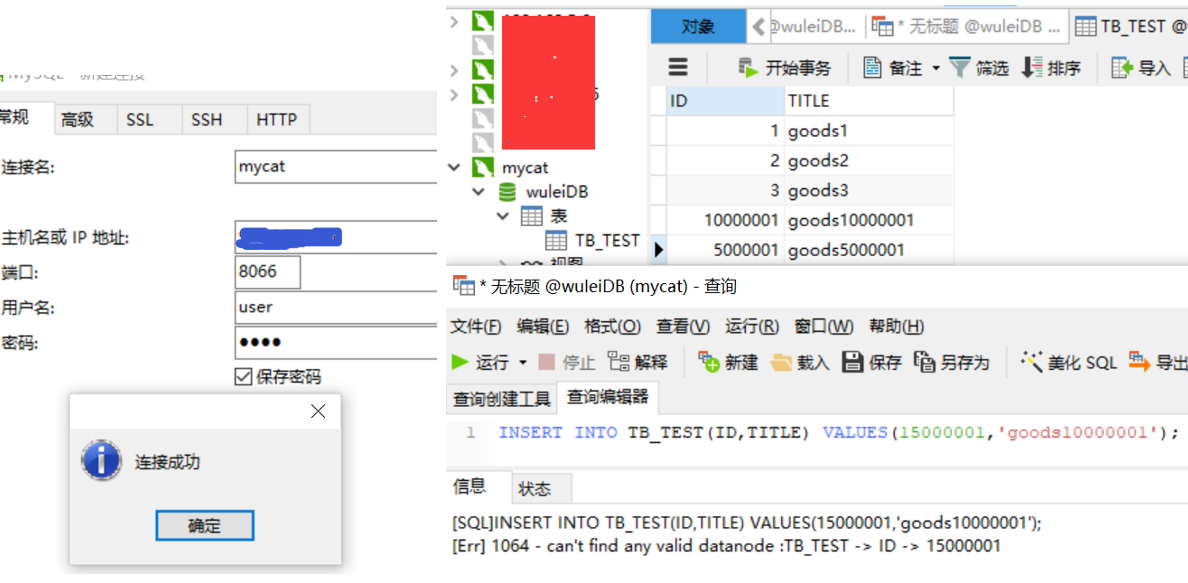
4. 重启mycat服务器, 客户机连接mycat。然后输入下面语句创建表测试一下!
CREATE TABLE tb_test ( id BIGINT(20) NOT NULL, title VARCHAR(100) NOT NULL , PRIMARY KEY (id) ) ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO TB_TEST(ID,TITLE) VALUES(1,'goods1'); INSERT INTO TB_TEST(ID,TITLE) VALUES(2,'goods2'); INSERT INTO TB_TEST(ID,TITLE) VALUES(3,'goods3'); INSERT INTO TB_TEST(ID,TITLE) VALUES(5000001,'goods5000001'); INSERT INTO TB_TEST(ID,TITLE) VALUES(10000001,'goods10000001'); INSERT INTO TB_TEST(ID,TITLE) VALUES(15000001,'goods10000001'); 可以看到前500w条数据插入了mydb1 500w - 1000w插入了mybd2 1000w-1500w插入了mydb3 大于1500w的直接报错无法执行
------
--------
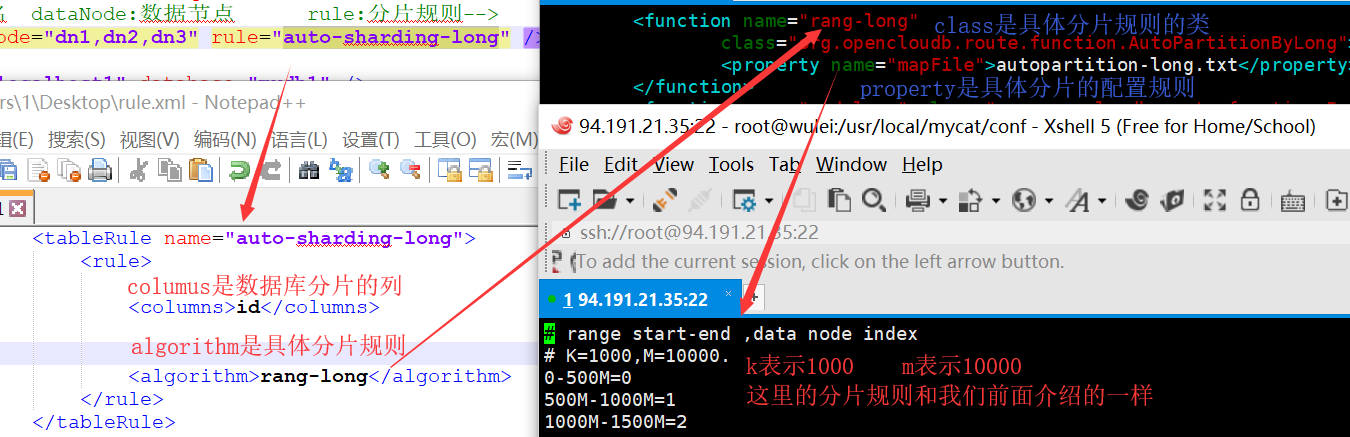
具体执行步骤:conf/schema.xml指定逻辑表的分片规则 (auto-sharding-long);
根据规则名找到conf/rule.xml具体的表规则(rand-long);
通过分片algorithm名称,往下找具体分片配置文件(autopartition-long.txt);
在mycat/conf文件夹里面找到改配置文件。
【二:一致性哈希分片】
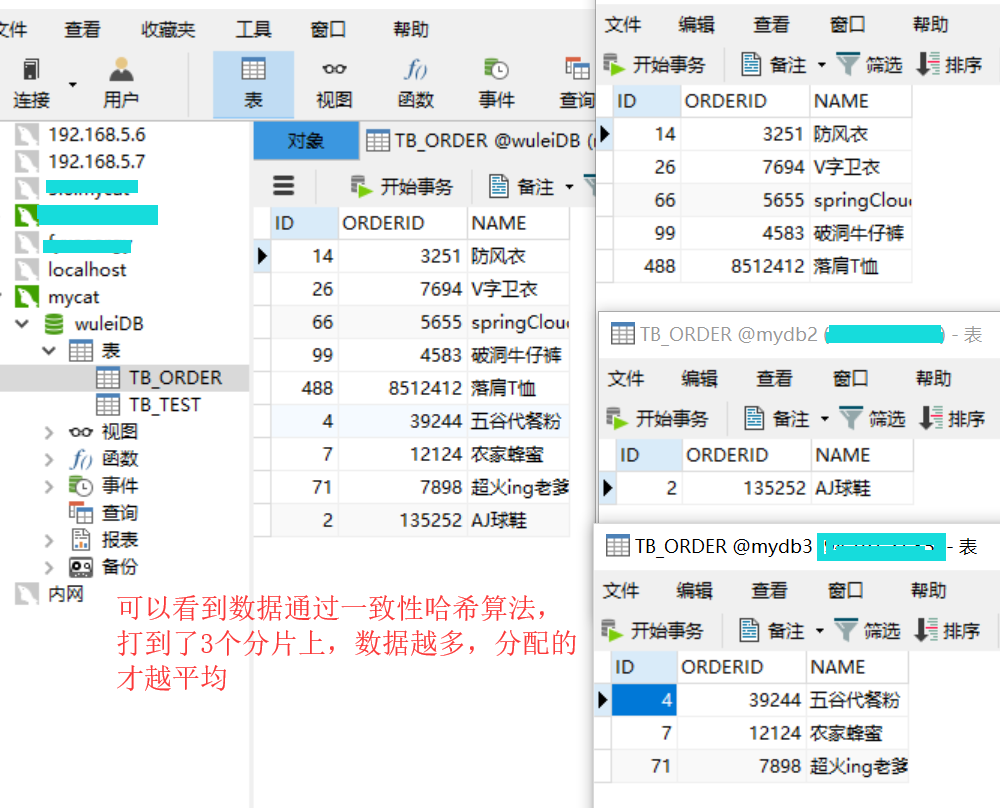
现在我们定义一个逻辑表,按照一致性哈希来分表,这个算法会将所有数据尽量平均的插到每个分片上。重启mycat!
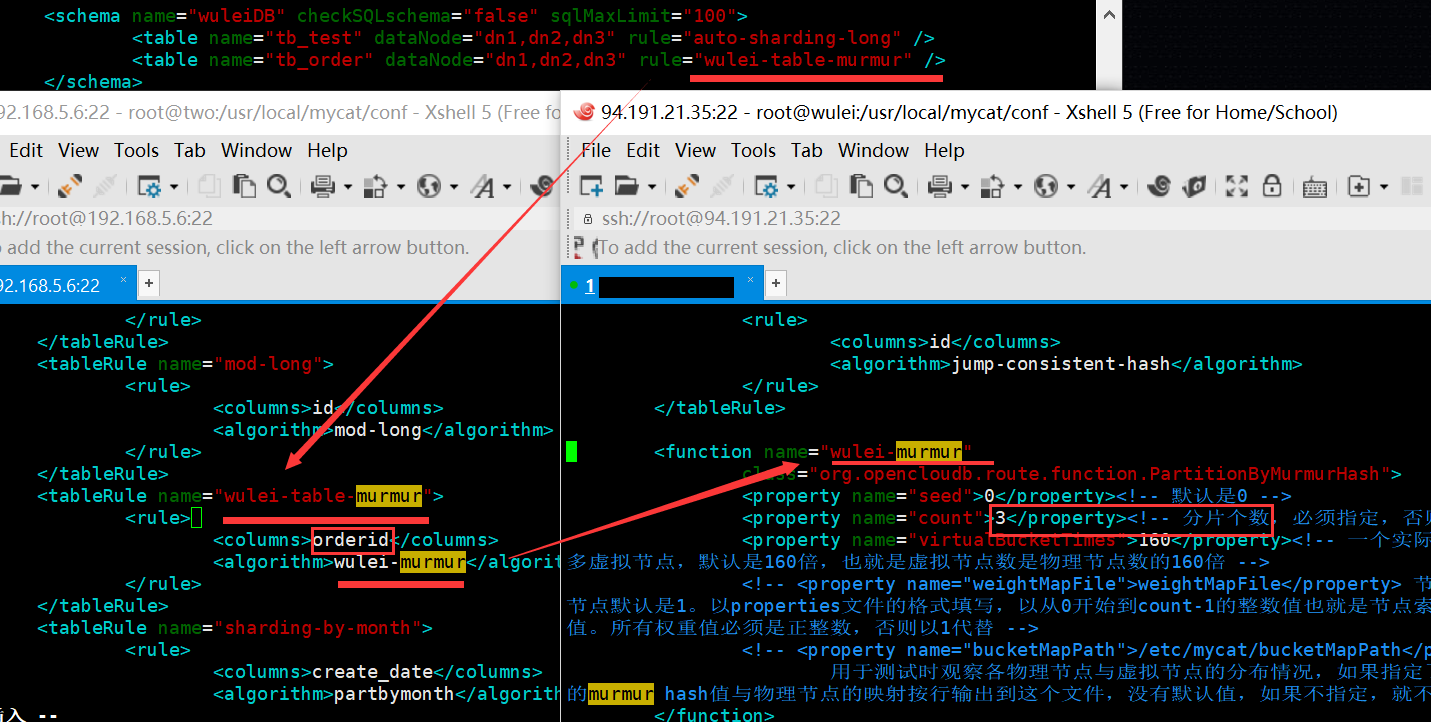
<function name="murmur" class="org.opencloudb.route.function.PartitionByMurmurHash"> <!-- 默认是0 --> <property name="seed">0</property> <!-- 分片个数我们这里是3个分片,必须指定,否则没法分片 --> <property name="count">3</property> <!-- 默认一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 --> <property name="virtualBucketTimes">160</property> <!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写, 以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。 所有权重值必须是正整数,否则以1代替 --> <!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> 用于测试时观察各物理节点与虚拟节点的分布情况, 如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输 出到这个文件,没有默认值,如果不指定,就不会输出任何东西 --> </function> CREATE TABLE tb_order ( id BIGINT(20) NOT NULL, orderid BIGINT(20) NOT NULL, name VARCHAR(100) NOT NULL , PRIMARY KEY (id) ) ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(2,135252,'AJ球鞋'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(7,12124,'农家蜂蜜'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(4,39244,'五谷代餐粉'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(26,7694,'V字卫衣'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(488,8512412,'落肩T恤'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(99,4583,'破洞牛仔裤'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(14,3251,'防风衣'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(71,7898,'超火ing老爹鞋'); INSERT INTO TB_ORDER(ID,ORDERID,NAME) VALUES(66,5655,'springCloud实战');
查看测试结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号