二: Jvm内存模型
为什么jvm要有内存模型
在 上一章节 我们清楚代码的运行流程之后,那么下面一段代码我们就可以知道:
1. main线程启动,main()方法的栈帧压入main线程的虚拟机栈
2. web()方法的栈帧也压入main线程的虚拟机栈
3. web()栈帧中创建了局部变量test,并且指向Test对象
4. test调用完web()方法后,web()就会从main线程虚拟机中出栈,Test对象没有引用指向后,就会被垃圾回收器回收
5. 和上面一样,此时getUserOrder()栈帧开始入栈了
6. 创建了局部变量order,调用Order对象的getUserOrder方法
7. 执行完成后,getUserOrder()栈帧出栈,Order对象被清除。然后在while循环中反复横跳6~7步的过程。
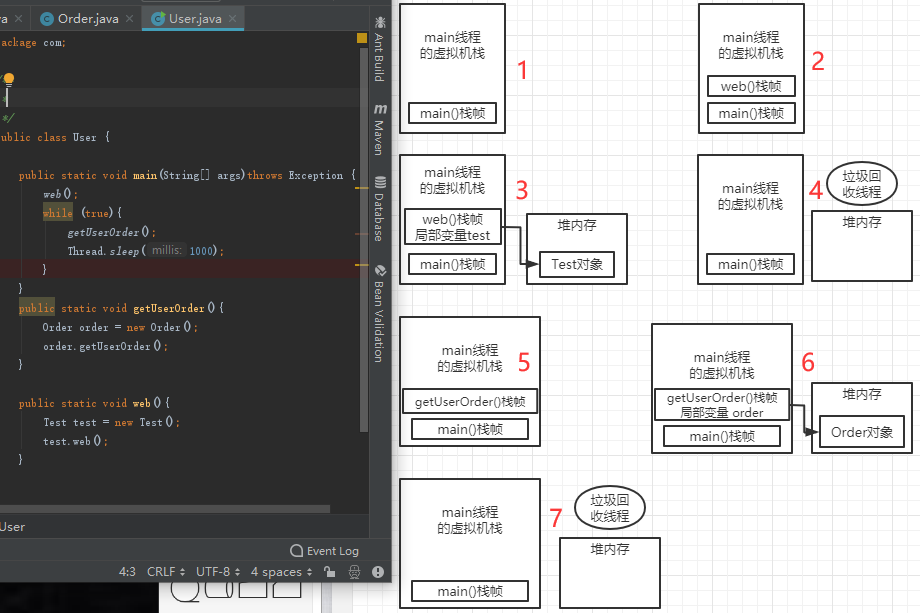
从上面的案例可以看出Test对象只是短暂的使用一下,而Order对象是需要经常使用的,那么代码我们就可以改造下:
1. 进入main()方法后,首先就去执行web栈帧中的代码了,里面的Test对象用完就回收,所以是放在年轻代里的。
2. 而Order对象被User类的静态变量order对象引用了,这是需要常驻在内存中使用的
* 所以为了管理对象存活的时间不一样,才需要内存模型。
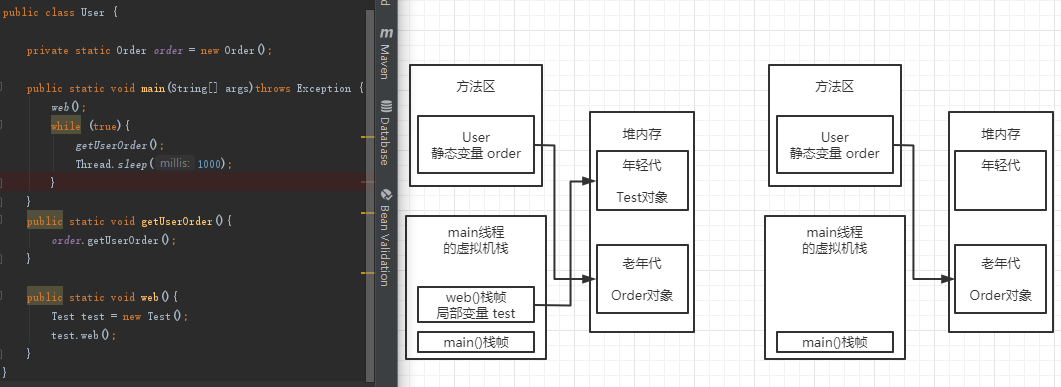
内存模型
因为每个对象生命周期不一样,jvm在做内存管理的时候,就帮我们分成了三个区域:
1. 新生代(回收频率高) 新生和老年默认大小比例为1:2
2. 老年代(回收频率低) 最好所有的对象都不要进入老年代,最好新生代能及时回收空对象释放空间供下次使用。
3. 永久代(一般放类的加载信息,常量,静态变量)。

从上图可以看出jdk1.8之前:新生代,老年代放在heap中, 永久代放在方法区中;
在jdk1.8的时候,就将永久代放到了一块叫Meta Space(元空间)的本地内存中。
官方之所以这么设计,是为了解决永久代会溢出的问题,meta space有点像ArrayList,拥有自动扩容的特性,从而防止溢出。当然它也不是越大越好,太大了会因为内存占用过多,从而使得堆外内存空间狭小而容易出现内存溢出的情况。这些都是可配置的。
指针碰撞
如下图,第一次创建对象的时候线程开辟了一个空间,第二次创建对象线程又开了一个空间,如果多个线程同时创建就会出现“抢占”空间的情况出现指针碰撞,jvm就通过CAS来控制先来后到的顺利,理解成线程锁一样。但是这样创建对象还是CAS还是会出现竞争激烈的情况从而消耗CPU影响性能。为了解决这个问题,jvm又提供了栈上分配。内存规整(即内存连续有规律)
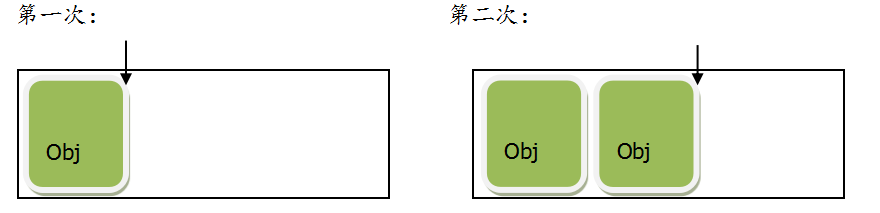
栈上分配
栈上分配的本质还是在堆中分配内存。
如下图:在堆里面,每个线程都有自己的Thread local Alltion Buffer,他们都是在自己的空间里面创建对象,这样就不会出现抢占的情况了,从而提高了性能。

对象分配规则
对象优先分配在Eden区、哪怕静态变量也不例外,如果Eden内存不够,新生代就执行一次Minor GC,有的时候我们 也叫“Young GC”
(1)大对象(大对象指需要大量连续内存空间的对象)直接进入老年代.这样做的目的是避免在Eden区和两个Survivor区之间发生大量的内存拷贝(新生代采用复制算法收集内存)。
(2)长期存活的对象进入老年代.虚拟机为每个对象都定义一个年龄计数器,如果对象经过一次Minor GC就去Survivor区,之后每经过一次Minor GC,年龄就会加一,直到15之后就去老年代。
(3)动态判断对象的年龄:如果本次gc后,新生代幸存区空间已占用50%+,那就年龄升序排列,属于50%后面的直接放入老年代。其实说白了,无论是哪个规则,都是希望那些可能是长期存活的对象,尽早进入老年代,别赖在新生代里占地方了。

。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号