Linux搭建 elk 7.3.0
Elasticsearch
1. 下载地址
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.0-linux-x86_64.tar.gz
2. 上传tar包并解压
tar -zxvf elasticsearch-7.3.0-linux-x86_64.tar.gz
3. 设置权限
chmod -R 777 elasticsearch-7.3.0
4. 添加非root用户 adduser wulei && passwd wulei
参考https://blog.csdn.net/u010454261/article/details/70227164/
5. 切换登陆用户(不能root启动,会报错)
su - wulei
6. 启动 cd /elasticsearch-7.3.0/bin
./elasticsearch
后台启动1
./elasticsearch -d
后台启动方式2
nohup ./elasticserach &
7. 检查是否启动成功 curl localhost:9200
8. 关闭
ps -ef | grep elasticsearch
kill -9 pid
【启动报错】ES7.3.0 必须是jdk11+,我们是jdk8,启动就失败
[wulei@node2 bin]$ ./elasticsearch future versions of Elasticsearch will require Java 11; your Java version from [/usr/local/wulei/jdk8/jre] does not meet this requirement
1. 下载jdk https://download.java.net/java/GA/jdk11/13/GPL/openjdk-11.0.1_linux-x64_bin.tar.gz
2. 解压 tar -zxvf openjdk-11.0.1_linux-x64_bin.tar.gz //我是解压在 /usr/local/wulei/elasticsearch-7.3.0/jdk-11.0.1
3. 修改配置 vim elasticsearch-7.3.0/bin/elasticsearch
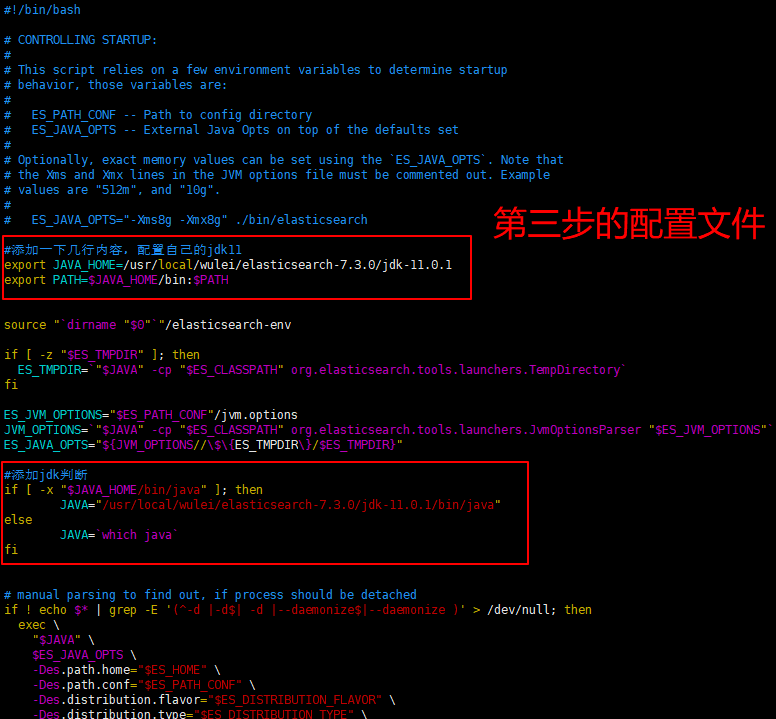
# 添加一下几行内容,配置自己的jdk11(配置如下图,下面的缩进不要用tab 否则会找不到,用空格就好了)
export JAVA_HOME=/usr/local/wulei/elasticsearch-7.3.0/jdk-11.0.1
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/usr/local/wulei/elasticsearch-7.3.0/jdk-11.0.1/bin/java"
else
JAVA=`which java`
fi
4. 修改为g1垃圾回收,否则启动报错 vim elasticsearch-7.3.0/config/jvm.options
将: -XX:+UseConcMarkSweepGC 改为:-XX:+UseG1GC
== 再重新启动es就成功了,然后 curl localhost:9200 验证
解决外网无法访问es问题
如果仅仅只是修改节点名称和端口还是可以启动的,但是如果要外网(浏览器)可以访问,必须指定network.host。但是指定 network.host 启动会报错。


# 集群名称: 同一网段如果有多个节点,集群名称相同情况下,会自动加入成一个集群 cluster.name: my-application # 节点名称: 类似于pid node.name: node-1 # 指定服务器ip,否则只能内网访问无法外网访问 network.host: 0.0.0.0 http.port: 9200 # 开启跨域访问 http.cors.enabled: true http.cors.allow-origin: "*" #添加配置 discovery.seed_hosts: ["127.0.0.1"] cluster.initial_master_nodes: ["node-1"]
启动报错解决办法:
ERROR: [2] bootstrap checks failed [1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] [2]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 解决办法: 1. vim /etc/security/limits.conf在文件末尾追加下面配置 * soft nofile 65536 * hard nofile 65536 2. vim /etc/sysctl.conf在文件末尾追加 vm.max_map_count=655360保存后执行sysctl -p 3. 重启服务器 reboot
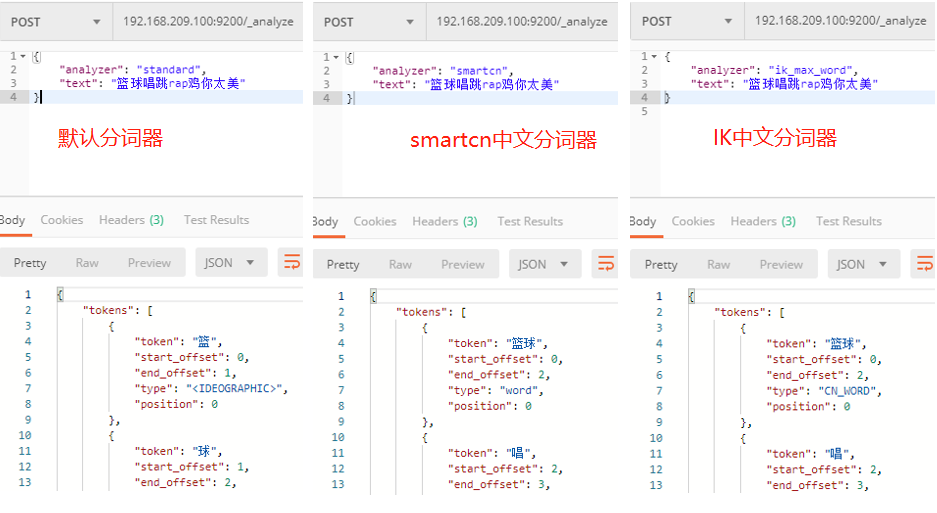
ik分词器
如果实在kibana搜索日志,就不用安装分词器了。不然会把搜索关键字分割成多个去匹配。
1. 下载 https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.3.0 2. 进入 cd elasticsearch-7.3.0/plugins mkdir elasticsearch-analysis-ik-7.3.0 cd elasticsearch-analysis-ik-7.3.0 unzip elasticsearch-analysis-ik-7.3.0.zip rm -rf elasticsearch-analysis-ik-7.3.0.zip 3. 重启es
4. 测试
GET 192.168.200.100:9200/_analyze
{
"analyzer": "ik_max_word",
"text": ["能不能给我一首歌的时间"]
}
Kibana
Kibana 是一款开源的数据分析和可视化平台,可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
1. 下载地址
https://artifacts.elastic.co/downloads/kibana/kibana-7.3.0-linux-x86_64.tar.gz
2. 上传并解压
tar -zxvf kibana-7.3.0-linux-x86_64.tar.gz
3. 修改配置
vim kibana-7.3.0-linux-x86_64/config/kibana.yml
#配置Kibana的远程访问
server.host: 0.0.0.0
#配置es访问地址
elasticsearch.hosts: ["http://192.168.42.21:9200"]
#汉化界面
i18n.locale: "zh-CN"
4. 授权
chmod -R 777 kibana-7.3.0-linux-x86_64
5. 像es一样创建用户来启动kibana,或者直接用之前es创建的用户来启动
su - wulei
6. 启动 cd kibana-7.3.0-linux-x86_64/bin/
./kibana
或者:
[esuser@192 bin]$ nohup ./kibana &
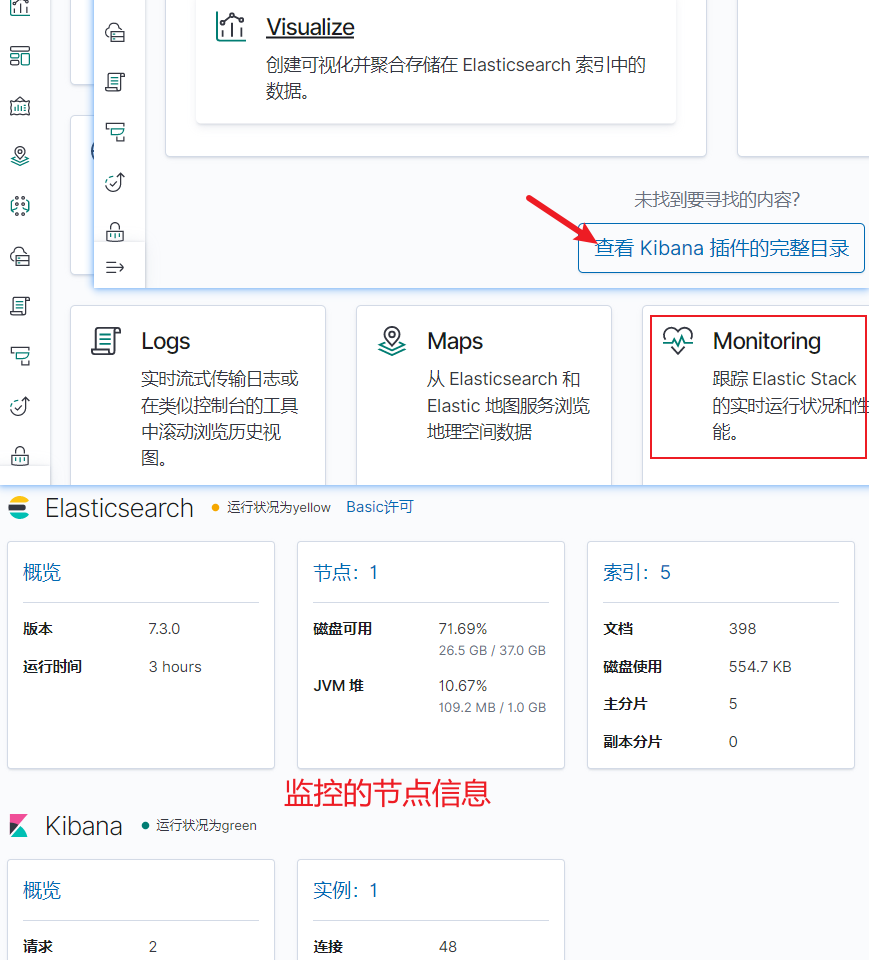
测试访问首页,选择 monitoring 查看节点信息 : http://192.168.200.101:5601
Logstash
Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,用于收集、丰富和统一所有数据,而不管格式或模式。
1. 下载地址
https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.tar.gz
2. 上传并解压
tar -zxvf logstash-7.3.0.tar.gz
3. 启动
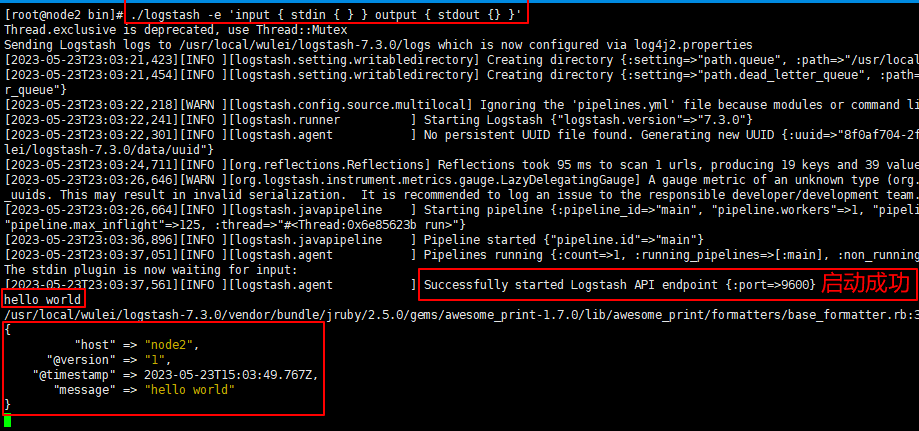
cd logstash-7.3.0/bin && ll
./logstash -e 'input { stdin { } } output { stdout {} }'
4. 启动后,输入 hello world 测试是否正常
5. 关闭logstash: CTRL + D
上面只是简单测试下,我们可以新建好配置文件,启动时指定规则文件
# 接收输入信息的格式 input { tcp { # 监听指定端口 port => 5044 # 输入为json数据 codec => json_lines } } # 数据转换和过滤,这里是处理时间格式 filter { ruby { code => "event.set('timestamp', event.get('@timestamp').time.localtime + 8*60*60)" } ruby { code => "event.set('@timestamp',event.get('timestamp'))" } mutate { remove_field => ["timestamp"] } } # 输出配置,写入到es,每天生成一个文件 output { # 这个是logstash的控制台打印(进行安装调试的时候开启,稍后成功后去掉这个配置即可) stdout { codec => rubydebug } # elasticsearch配置 elasticsearch { hosts => ["192.168.200.102:9200"] # 索引名称,没有会自动创建 index => "logstash-%{[server_name]}-%{+YYYY.MM.dd}" } }
启动(启动成功后,看到进程在的话,我们就可以通过代码来验证了)
cd logstash-7.3.0
./bin/logstash -f config/logstash-es.conf
springboot
1. 添加依赖
<dependency> <groupId>net.logstash.logback</groupId> <artifactId>logstash-logback-encoder</artifactId> <version>6.3</version> </dependency>
2. 配置logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- 控制台输出 --> <appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender"> <layout class="ch.qos.logback.classic.PatternLayout"> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %highlight(%-5level) %cyan(%logger{50}.%M.%L) - %highlight(%msg) %n</pattern> </layout> </appender> <!--logback输出--> <appender name="STASH" class="net.logstash.logback.appender.LogstashTcpSocketAppender"> <destination>192.168.31.242:5044</destination> <encoder class="net.logstash.logback.encoder.LogstashEncoder"> <!-- 打印行号、方法名,官方不建议在生产环境开启此配置,默认为false(关闭),具网友测试开启后的耗时是未开启的大约360倍的时间(业务量小的时候可以忽略) --> <includeCallerData>true</includeCallerData> <!-- 设置时区--> <timeZone>UTC</timeZone> <!-- 日期格式化--> <!-- <timestampPattern>yyyy-MM-dd'T'HH:mm:ss.SSS</timestampPattern>--> <!-- 添加自定义属性,这里的server_name是服务名,对应 logstash-es.conf 中的变量 --> <customFields>{"server_name":"demo-server"}</customFields> </encoder> <!-- 设置超时时间, 默认没有,使用集群的时候可以加上--> <!--<writeTimeout>30 seconds</writeTimeout>--> </appender> <root level="INFO"> <!--本地开发调试将控制台输出打开,同时将日志文件输出关闭,提高日志性能;线上部署请务必将控制台输出关闭--> <appender-ref ref="STDOUT"/> <appender-ref ref="STASH"/> </root> </configuration>
3. 启动项目,此时会产生日志,输出到es中。可以找到我们的索引文件名
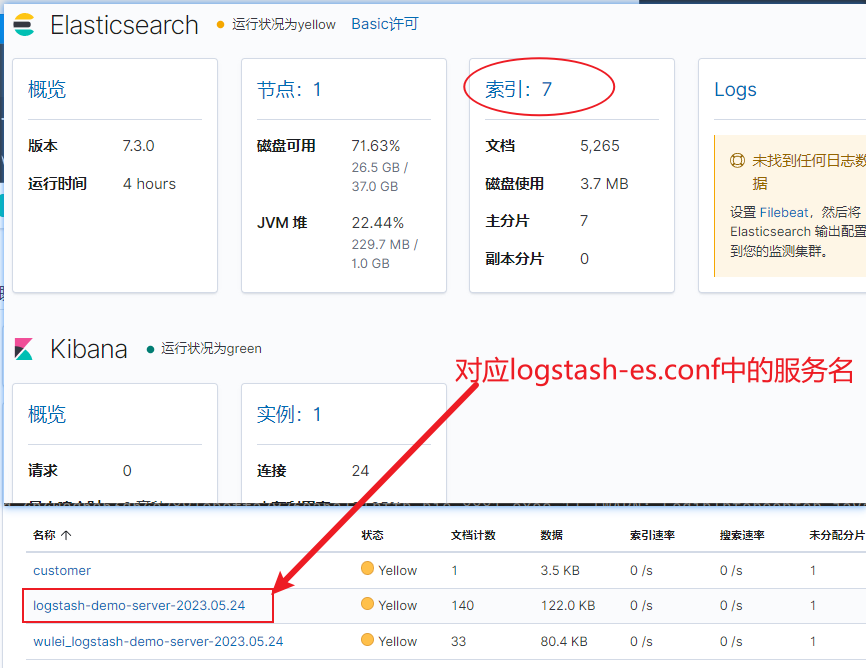
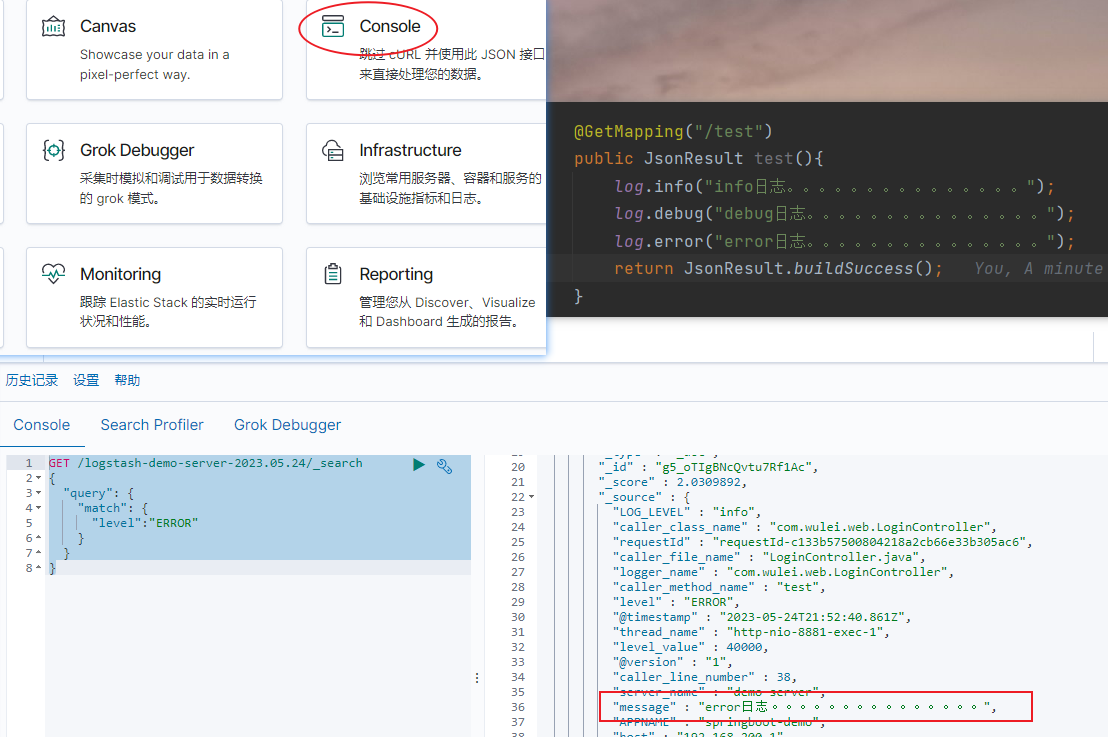
4. 日志搜索。进入kinbana的console面板中,搜索 error 级别的日志。
GET /logstash-demo-server-2023.05.24/_search { "query": { "match": { "level":"ERROR" } } }
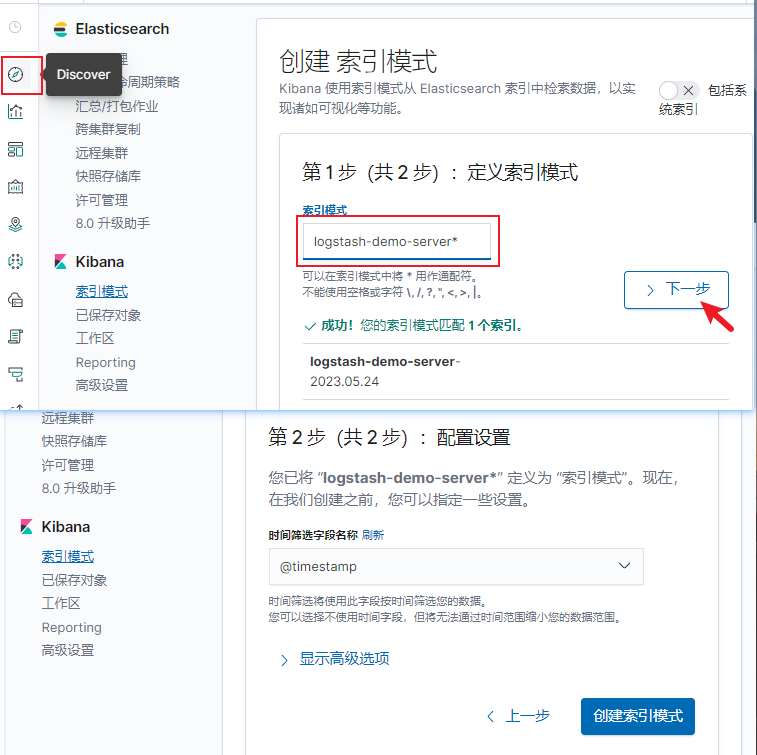
Discover
上面通过语法搜索日志太麻烦了,我们可以通过kibana 的 Discover 创建索引来查看日志。
也可以在管理控制台创建索引。Discover 主要只是查看,没办法创建多个索引,我们在这里创建多个索引之后,就可以选择在Discover 选择索引,进行筛选了。
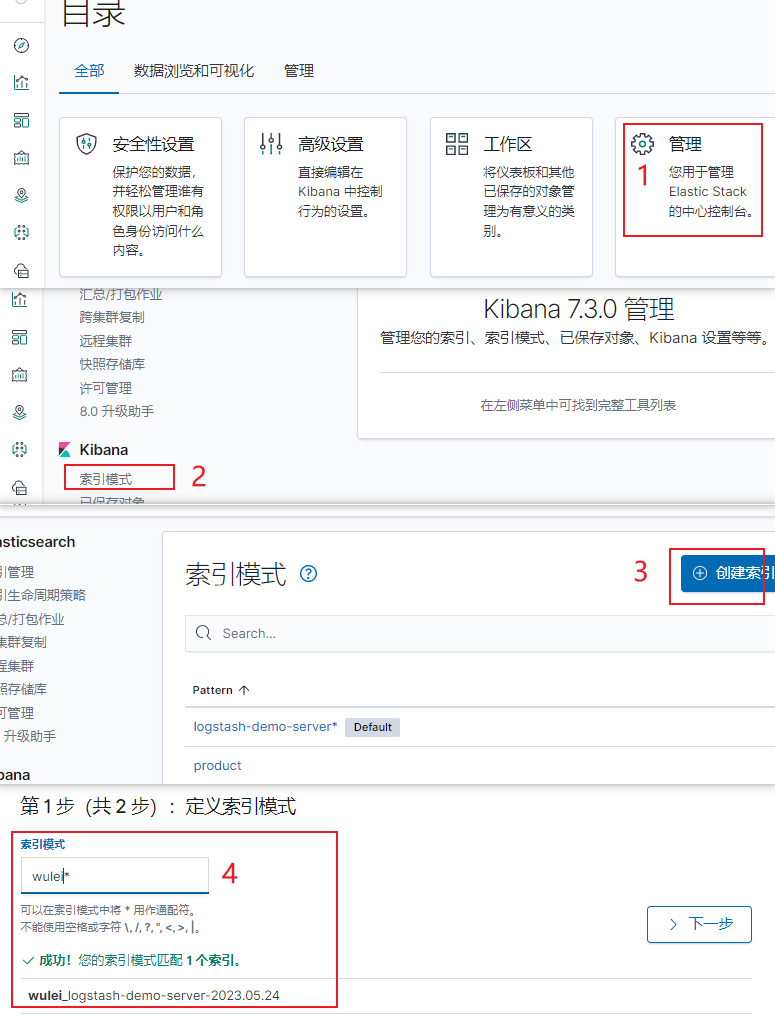
创建好索引之后,再重新进入Discover页面刷新,我们就可以用仪表盘的形式展示了。
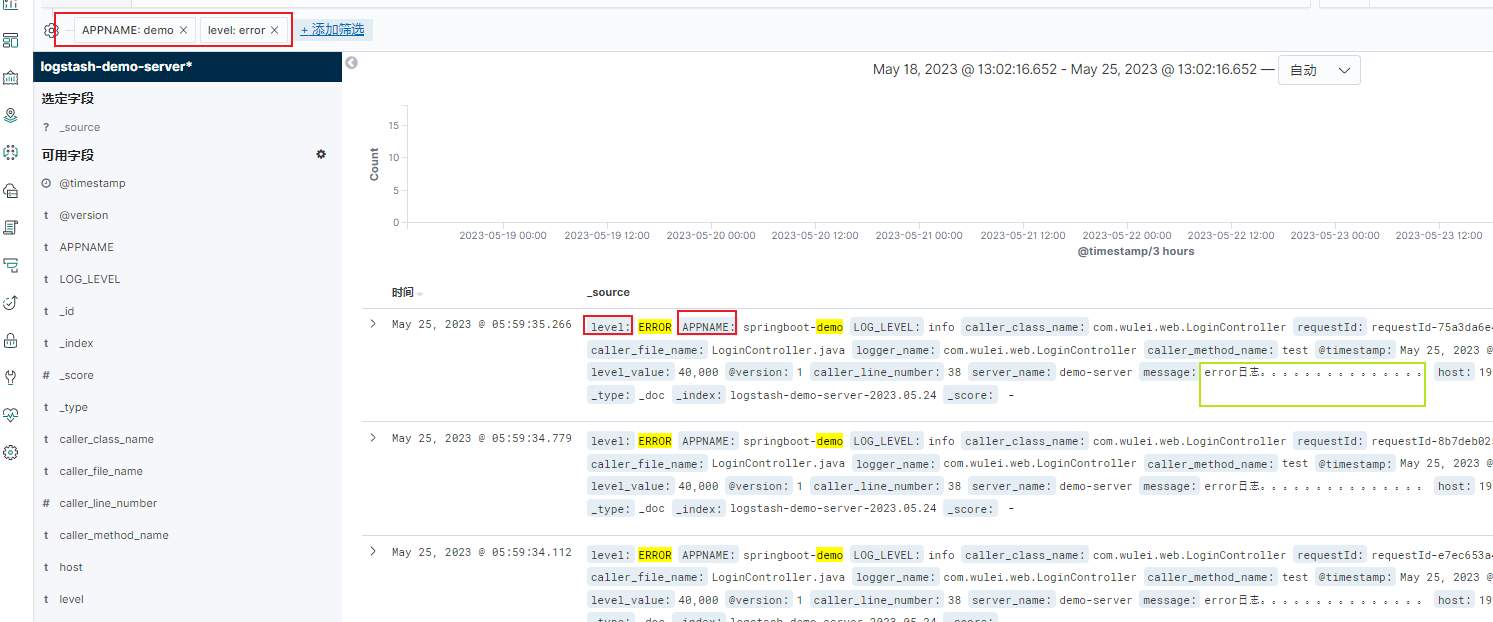
常用筛选说明
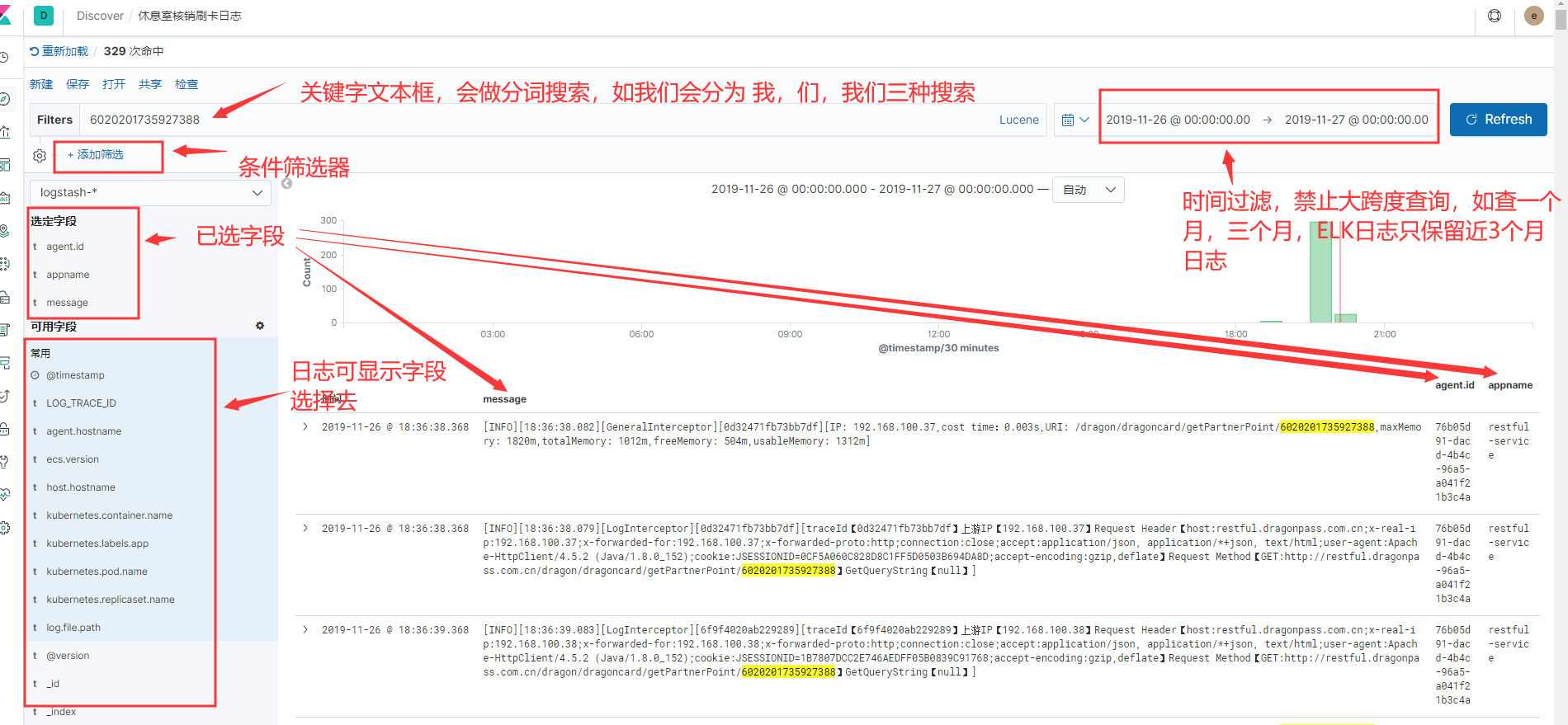
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号