Seata源码解析
2PC
事务是最小单元,必须保证 ACID 原子性、一致性、隔离性、持久性。但是多数据源或多个系统间业务调用的时候就会有分布式事务问题了,说到分布式事务,我们可以先聊会两阶段提交。
阶段1:
TM通知各个RM准备提交它们的事务分支。如果RM判断自己进行的工作可以被提交,那就对工作内容进行持久化, 再给TM肯定答复;要是发生了其他情况,那给TM的都是否定答复然后回滚当前事务,RM就可以丢弃这个事务分支信息。
阶段2:
TM根据阶段1各个RM prepare的结果,决定是提交还是回滚事务。如果所有的RM都prepare成功,那么TM通知所有 的RM进行提交;如果有RM prepare失败的话,则TM通知所有RM回滚自己的事务分支。
以mysql数据库为例,如果第一阶段中所有数据库都prepare成功,那么事务管理器向数据库服务器发出"确认提 交"请求,数据库服务器把事务的"可以提交"状态改为"提交完成"状态,然后返回应答。如果在第一阶段内有任何一个数 据库的操作发生了错误,或者事务管理器收不到某个数据库的回应,则认为事务失败,回撤所有数据库的事务。数据库 服务器收不到第二阶段的确认提交请求,也会把"可以提交"的事务回撤。
import com.mysql.jdbc.jdbc2.optional.MysqlXAConnection; import com.mysql.jdbc.jdbc2.optional.MysqlXid; import javax.sql.XAConnection; import javax.transaction.xa.XAException; import javax.transaction.xa.XAResource; import javax.transaction.xa.Xid; import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; public class Demo { public static void main(String[] args) throws SQLException { //true表示打印XA语句, 用于调试 boolean logXaCommands = true; // 1 创建数据库连接对象 Connection conn1 = DriverManager.getConnection ("jdbc:mysql://localhost:3306/db_user", "root", "root"); // 2 然后基于 连接对象 构造出一个支持XA规范的连接对象(XA是2pc的实现) XAConnection xaConn1 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn1, logXaCommands); // 3 获得资源管理器操作接口实例 RM1 XAResource rm1 = xaConn1.getXAResource(); // 同理获得 资源管理器实例 RM2 Connection conn2 = DriverManager.getConnection("jdbc:mysql://localhost:3306/db_account", "root", "root"); XAConnection xaConn2 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn2, logXaCommands); XAResource rm2 = xaConn2.getXAResource(); // 4. 模拟AP请求TM执行一个分布式事务,TM生成全局事务xid byte[] gtrid = "g12345".getBytes(); int formatId = 1; try { // ==============分别执行RM1和RM2上的事务分支==================== // 5. TM生成rm1上的事务分支bid byte[] bqual1 = "b00001".getBytes(); // 将全局事务id 和 分支事务id 绑定在一起 Xid xid1 = new MysqlXid(gtrid, bqual1, formatId); // 6. 执行rm1上的事务分支 rm1.start(xid1, XAResource.TMNOFLAGS);//One of TMNOFLAGS, TMJOIN, or TMRESUME. PreparedStatement ps1 = conn1.prepareStatement("INSERT into user(name) VALUES ('Fox')"); ps1.execute(); rm1.end(xid1, XAResource.TMSUCCESS); // 同理执行rm2 byte[] bqual2 = "b00002".getBytes(); Xid xid2 = new MysqlXid(gtrid, bqual2, formatId); rm2.start(xid2, XAResource.TMNOFLAGS); PreparedStatement ps2 = conn2.prepareStatement("INSERT into account(user_id,money) VALUES (1,10000000)"); ps2.execute(); rm2.end(xid2, XAResource.TMSUCCESS); // ===================两阶段提交================================ // 6. phase1:询问所有的RM 准备提交事务分支 int rm1_prepare = rm1.prepare(xid1); int rm2_prepare = rm2.prepare(xid2); // 7. phase2:提交所有事务分支 boolean onePhase = false; //TM判断有2个事务分支,所以不能优化为一阶段提交 if (rm1_prepare == XAResource.XA_OK && rm2_prepare == XAResource.XA_OK) { //所有事务分支都prepare成功,提交所有事务分支 rm1.commit(xid1, onePhase); rm2.commit(xid2, onePhase); } else { //如果有事务分支没有成功,则回滚 rm1.rollback(xid1); rm2.rollback(xid2); } } catch (XAException e) { // 如果出现异常,也要进行回滚 e.printStackTrace(); } } }
看似完美的2PC解决了分布式事务问题,但是有3个致命的缺点:
1.阻塞
两阶段的ACID严重依赖RM,是把两个分支事务提升到全局事务的层次,串行的执行效率是很低的。
2.单点故障
比如第二阶段,协调者TM故障后那么RM会一直阻塞下去。尽管协调者TM故障后可以重新选举一个,但无法处理已经参与事务的RM阻塞状态。
3.数据不一致
二阶段中,TM向RM发送commit请求后,由于网络异常只有部分RM能正常commit,其他部分没接收到命令就会数据不一致。
3PC
因此,为了解决这个问题,出现了3PC协议。主要是引入超时机制, 解决了阻塞、单点问题;但数据不一致还是没有解决。
CanCommit阶段:
TM向RM发送CanCommit请求。如果RM认为自身可以顺利执行任务就返回yes,进入预备阶段;反之则是no。
PreCommit阶段:
若都是yes,RM执行事务并记录undo和redo日志;若有一个no,所有RM中断事务。
DoCommit阶段:
若第二步成功,RM提交事务并告诉TM,TM收到ack响应后结束任务;若第二步中断,RM回滚事务并告诉TM,任务结束。
Seata的三大角色
在 Seata 的架构中,一共有三个角色:
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
如何开启全局事务的
我们使用seata分布式事务,是在方法上加 @GlobalTransactional 注解,以这个注解为入口可以发现,有一个它的扫描类。它实现了 AOP 的 AbstractAutoProxyCreator 这个自动代理类。重写了后置方法 wrapIfNecessary() 。
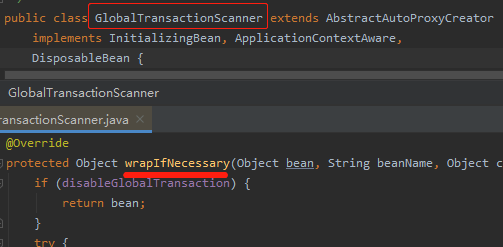
在这个方法里面,创建了拦截器,这个拦截器实现了 aop 的 MethodInterceptor 方法拦截器。
if (interceptor == null) { interceptor = new GlobalTransactionalInterceptor(failureHandlerHook); }
然后通过 invoker() 反射获取注解信息,执行全局事务方法。
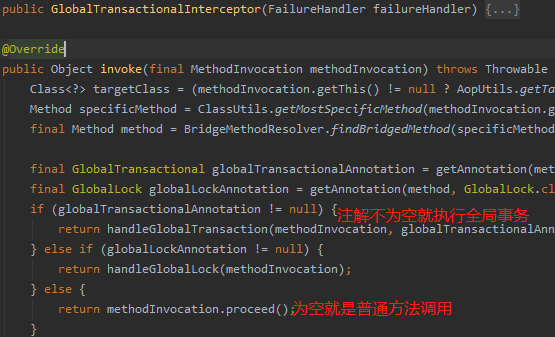
在这个方法里面执行了事务模板 transactionalTemplate.execute() 方法,这个是核心入口。他首先就获取了全局事务对象 GlobalTransaction 。
public Object execute(TransactionalExecutor business) throws Throwable { // 1. 获取全局事务 GlobalTransaction tx = GlobalTransactionContext.getCurrentOrCreate(); // 1.1 获取事务信息 TransactionInfo txInfo = business.getTransactionInfo(); if (txInfo == null) { throw new ShouldNeverHappenException("transactionInfo does not exist"); } try { // 2. 开启事务 beginTransaction(txInfo, tx); Object rs = null; try { // 执行业务方法 rs = business.execute(); } catch (Throwable ex) { // 3. 异常回滚事务 completeTransactionAfterThrowing(txInfo,tx,ex); throw ex; } // 4. 提交当前事务 commitTransaction(tx); return rs; } finally { //5. clear triggerAfterCompletion(); cleanUp(); } }
GlobalTransaction 是一个接口,里面定义了 begin() getXid()几个方法,其中 getXid() 就是获取全局事务id的方法。他是 begin() 开启全局事务的时候创建的。他首先会判断是否是事务发起者。如果是的话,就会创建一个XID 。然后 RootContext.bind(xid); 将他绑定到 context 上去,传递到下一个RM。
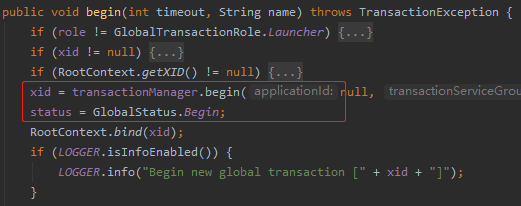
这个具体创建 xid 的方法点进去呢,可以看到是 TM 通过 netty 发送同步请求去 TC 服务创建的,XID 就是一个 ip:port:uuid 的格式 。创建完之后seata就会保存到 undo_log 数据库表中去。此时获取 xid ,并开启全局事务成功。
如何开启分支事务的
发起者下面这段代码加了 全局事务注解 后,就会开启全局事务,然后执行本地保存的时候呢,他除了会保存本地数据,还会然后注册了分支事务。但是他只是一个普通的 mapper 接口,那他是在哪里做这些事情的呢?我们在配置 seata 的时候会配置一个代理数据源, 其实这个就是他的代码入口。
seata 获取到数据库的代理连接后,此时 commit() 也是 seata 的代理对象进行操作的,他首先会执行提交分支事务,然后把回滚数据提交到 undo_log 里面去,最后提交第一阶段的本地事务。之后就 context.reset() 清除上下文。
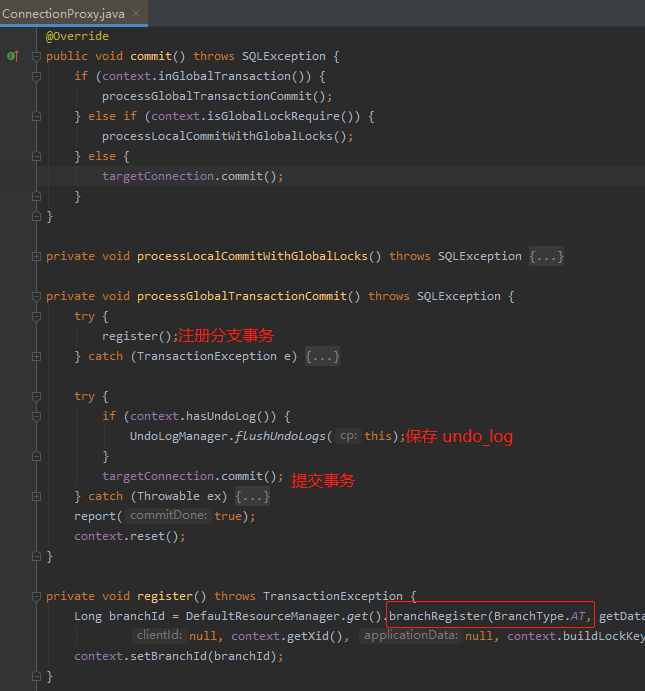
发送 RPC 到TC,TC收到请求后,首先会检查全局事务是否可用、添加全局事务的监听器,然后基于全局事务对象 new 一个分支事务出来。最后加锁,锁的key 就是 库名+表名+主键。
前置镜像与后置镜像
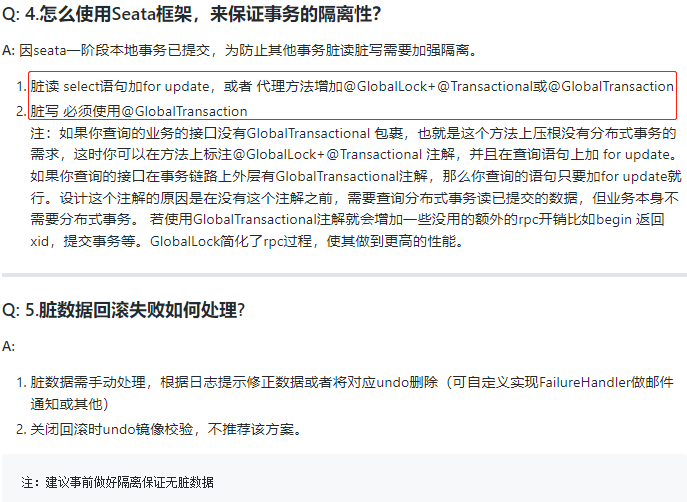
上面我们可以看到本地保存执行完,其实第一阶段的本地事务就已经提交了。按照我们对 mysql 的理解,事务提交了,那么其他线程就会拿到最新的数据。但是对于我们的业务而言,流程还没走完,实际上是不应该被其他线程感知到最新数据的。所以 seata 官方引出了 @GlobalLock 全局锁的概念,具体干嘛的我在下面解释下。
seata 回滚事务就是基于 这个 rollback_info 去实现的。里面存储了写操作前后的数据,即:前置镜像和后置镜像。那么它是什么时候创建的呢?
我们用mybatis去操作数据库,最终是通过执行器去处理的,这里 seata 它也是做了一个代理,根据我们的操作类型,看你是 update 或者是其他什么操作,获取到 ExecuteTemplate 执行器代理对象,然后做了功能增强。
public static <T, S extends Statement> T execute(SQLRecognizer sqlRecognizer, StatementProxy<S> statementProxy, StatementCallback<T, S> statementCallback, Object... args) throws SQLException { // 1. 不在 全局锁 或者全局事务中,那么就是一条普通的sql,否则就执行后面的逻辑 if (!RootContext.inGlobalTransaction() && !RootContext.requireGlobalLock()) { return statementCallback.execute(statementProxy.getTargetStatement(), args); } // 2. 获取到 sql识别器 和 sql类型 if (sqlRecognizer == null) { sqlRecognizer = SQLVisitorFactory.get( statementProxy.getTargetSQL(), statementProxy.getConnectionProxy().getDbType()); } Executor<T> executor = null; if (sqlRecognizer == null) { executor = new PlainExecutor<T, S>(statementProxy, statementCallback); } else { // 3. 然后根据你的sql类型是 insert 或者 update 啊,获取具体的执行器. switch (sqlRecognizer.getSQLType()) { case INSERT: executor = new InsertExecutor<T, S>(statementProxy, statementCallback, sqlRecognizer); break; case UPDATE: executor = new UpdateExecutor<T, S>(statementProxy, statementCallback, sqlRecognizer); break; case DELETE: executor = new DeleteExecutor<T, S>(statementProxy, statementCallback, sqlRecognizer); break; case SELECT_FOR_UPDATE: executor = new SelectForUpdateExecutor<T, S>(statementProxy, statementCallback, sqlRecognizer); break; default: executor = new PlainExecutor<T, S>(statementProxy, statementCallback); break; } } T rs = null; try { // 4. 拿到增强执行器之后,就去执行具体的方法了。 rs = executor.execute(args); } catch (Throwable ex) { if (!(ex instanceof SQLException)) { // Turn other exception into SQLException ex = new SQLException(ex); } throw (SQLException)ex; } return rs; }
也就是 AbstractDMLBaseExecutor#doExecute() 方法,如果是手动提交事务的话,就会创建出 前/后置镜像了。在生成前置镜像的时候,它会加上 for update 加锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号