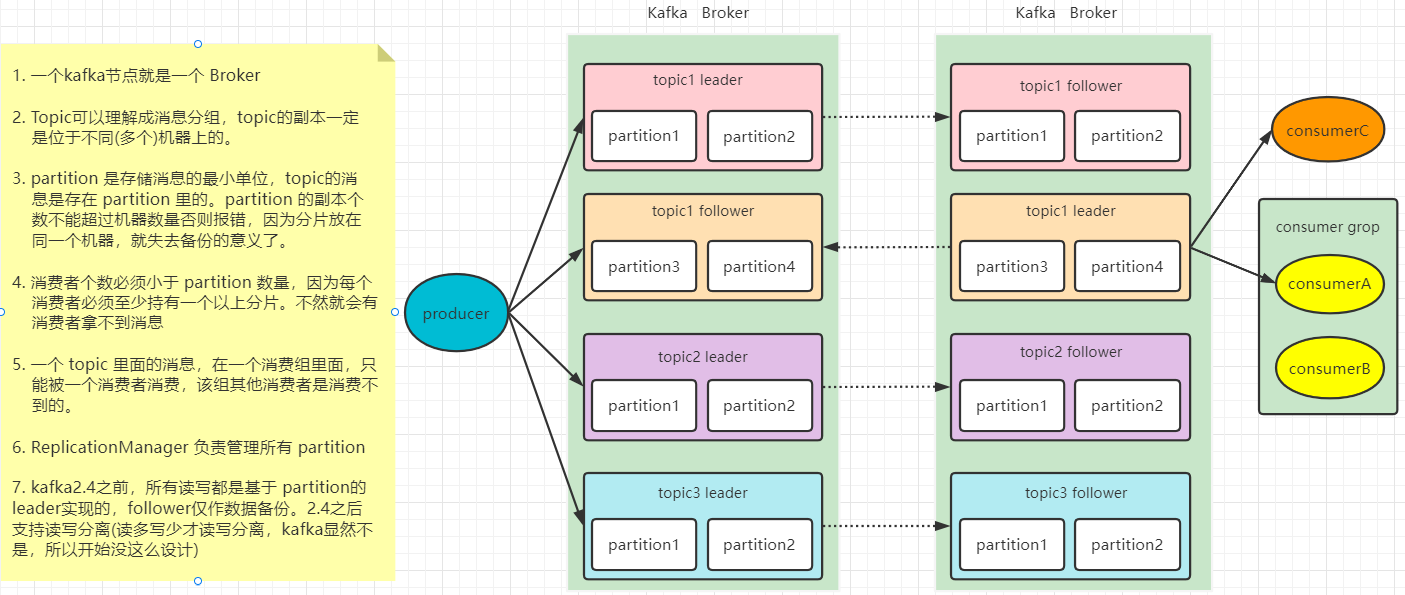
kafka
安装
首先要安装好zookeeper
1. 解压安装包
tar -zxvf kafka.tgz
2. 配置
vim kafka/config/server.properties
3. 进入bin目录启动服务
cd kafka/bin
./kafka-server-start.sh -daemon ../config/server.properties &
4. 停止
./kafka-server-stop.sh
修改配置文件的话,主要是指定ip地址,注册中心地址等,存储目录、其他那些保持默认就好了。

############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. # 集群中 brokerId 必须不一样 broker.id=0 ############################# Socket Server Settings ############################# # The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 # 指定服务器内网ip,我这里虚拟机就192.168.200.100 #listeners=PLAINTEXT://:9092 listeners=PLAINTEXT://192.168.200.100:9092 # Hostname and port the broker will advertise to producers and consumers. If not set, # it uses the value for "listeners" if configured. Otherwise, it will use the value # returned from java.net.InetAddress.getCanonicalHostName(). # 同上,这里指定外网ip,我是虚拟机就不用指定了 #advertised.listeners=PLAINTEXT://your.host.name:9092 # Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details #listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # The number of threads that the server uses for receiving requests from the network and sending responses to the network num.network.threads=3 # The number of threads that the server uses for processing requests, which may include disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=102400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=102400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 ############################# Log Basics #############################
# kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以
# 配置多个磁盘路径,路径与路径之间可以用","分隔。
log.dirs=/usr/local/wulei/kafka/datas # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=1 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=1 ############################# Internal Topic Settings ############################# # The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state" # For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3. offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 ############################# Log Flush Policy ############################# # The number of messages to accept before forcing a flush of data to disk #log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush #log.flush.interval.ms=1000 ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion due to age log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log unless the remaining # segments drop below log.retention.bytes. Functions independently of log.retention.hours. #log.retention.bytes=1073741824 # 每个日志文件大小 log.segment.bytes=1073741824 # 日志保留策略 log.retention.check.interval.ms=300000 ############################# Zookeeper ############################# # 注册中心地址 zookeeper.connect=localhost:2181 # 连接到zookeeper的超时(毫秒) zookeeper.connection.timeout.ms=18000 ############################# Group Coordinator Settings ############################# # The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance. # The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms. # The default value for this is 3 seconds. # We override this to 0 here as it makes for a better out-of-the-box experience for development and testing. # However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup. group.initial.rebalance.delay.ms=0
基本命令
创建topic (所有脚本都在bin目录,所以需要去到那个目录执行命令)
连接zookeeper, 创建一个副本,一个partitions分区 ,指定topic名称
./kafka-topics.sh --create --zookeeper 192.168.200.100:2181 --replication-factor 1 --partitions 1 --topic wulei-topic
查看topic列表 (配置文件指定了存储在/tmp/kafka-logs文件中,我们的topic就在这个文件夹下)
./kafka-topics.sh --list --zookeeper 192.168.200.100:2181
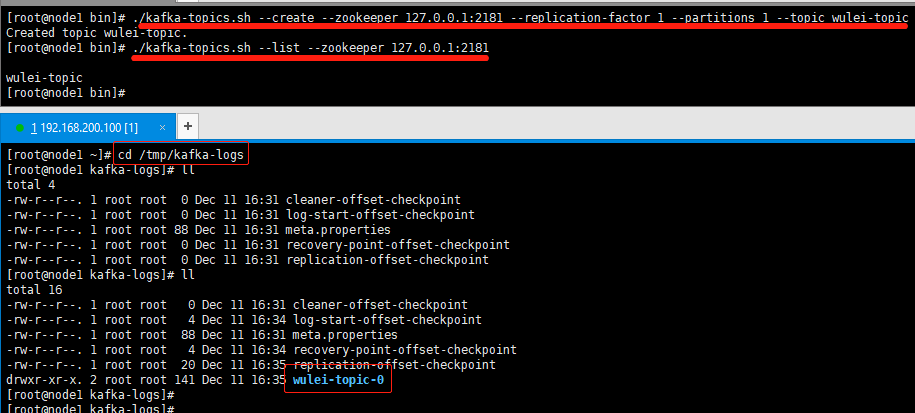
如果创建topic的时候,副本的个数大于机器的数量,就会直接报错。

删除topic (指定zookeeper地址,删除 wulei-test 这个topic)
./kafka-topics.sh --zookeeper 192.168.200.100:2181 --delete --topic wulei-test

查看topic详情
./kafka-topics.sh --describe --zookeeper 192.168.200.100:2181 --topic wulei-topic

收发消息
./kafka-console-producer.sh --broker-list 192.168.200.100:9092 --topic haha-topic
./kafka-console-consumer.sh --bootstrap-server 192.168.200.100:9092 --topic haha-topic

发布订阅模型
消费者配置默认在consume.properties文件中。
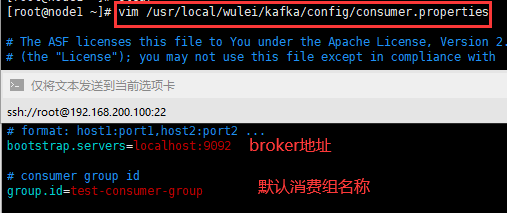
创建 topic 名叫 t1,一个副本 2个分片
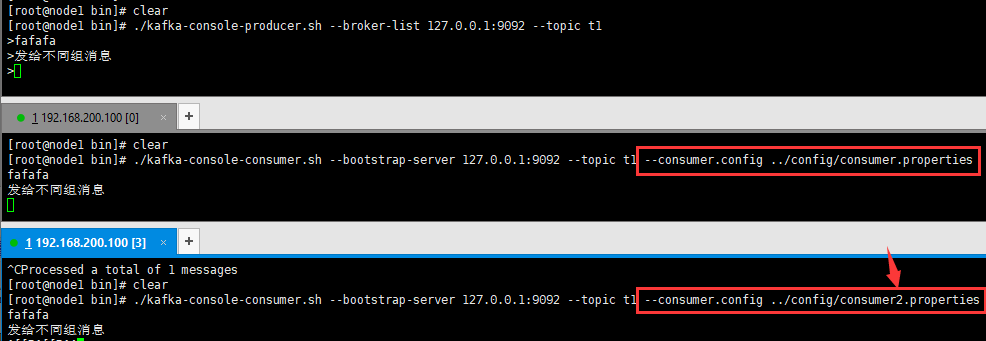
./kafka-topics.sh --create --zookeeper 192.168.200.100:2181 --replication-factor 1 --partitions 2 --topic t1
监听 t1 这个topic,分别指定不同的配置文件(在不同的配置文件里面指定消费组名称)
./kafka-console-consumer.sh --bootstrap-server 192.168.200.100:9092 --topic t1 --consumer.config ../config/consumer.properties
./kafka-console-consumer.sh --bootstrap-server 192.168.200.100:9092 --topic t1 --consumer.config ../config/consumer2.properties
*可以看到不同消费组下,消费者是都可以获取到消息的
点对点模型
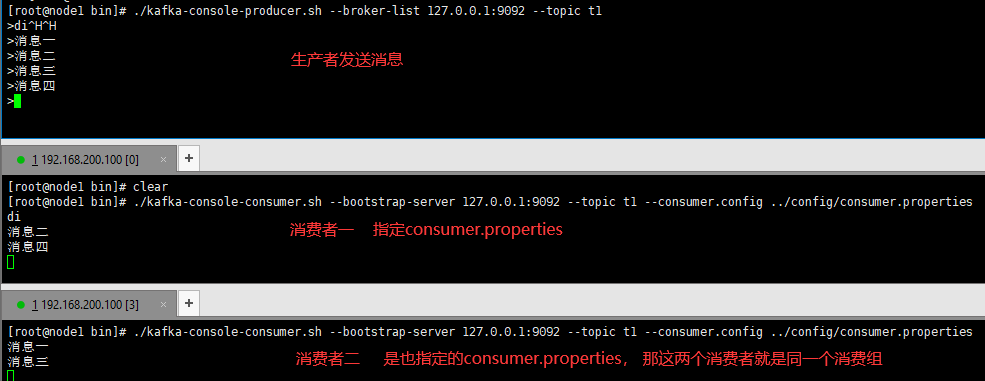
*可以看到默认是轮询策略,同一个消费组下,只有一个机器消费到了消息
partitions(分片)
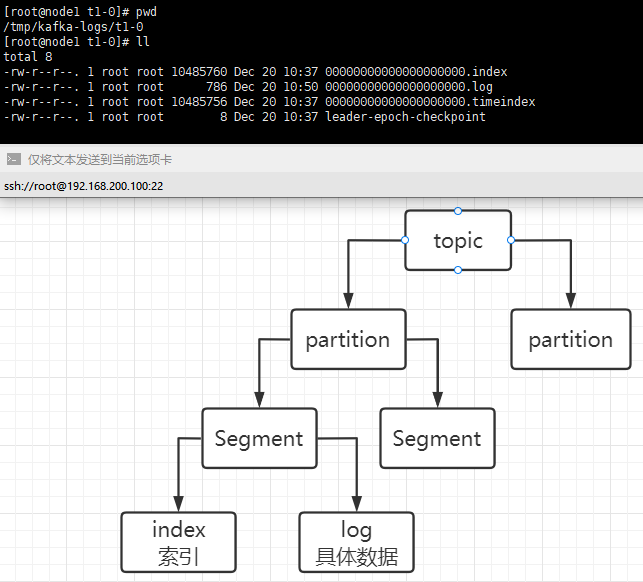
partitions 是 topic 物理上的分组,一个 topic 可以分为多个 partitions,每一个 partitions 是一个有序的队列是以文件夹的形式存储在 broker 本机上的。比如我们刚才的 --partitions 2 --topic t1 这个 t1 topic 就有两个分片,分别是 t1-0 和 t1-1 。
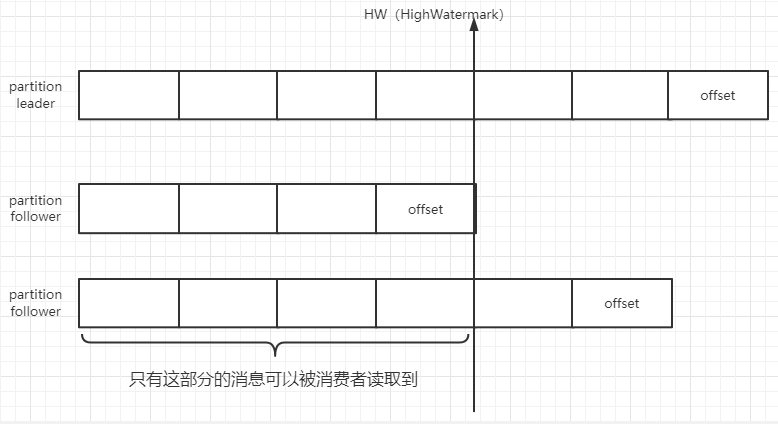
partition中每个消息都有一个连续的序列号offset,用来标识唯一消息。hw 表示 partition 的各个 replicas 都同步完的消息。
kafka 默认是采用轮询的方式写入 topic 的 partition 中去
如果指定了 key,则会采用hash(key)写入 partition
如果制定了 partition id 或者同时指定 partition id 和 key,则会写入指定的 partition 中去。
通过这种方式我们就可以实现顺序消息。注意:product 只会与 partition leader 去交互。
kafka 默认通过轮询算法,保证消息均匀的落到每个分片上。比如es、mongoDB中的分片叫做 shard;HBase 中的叫做 Region。他们叫法不同,但是思想确实从未改变,通过多分片的机制细化读写粒度、从而提供负载均衡能力,增加系统的吞吐量。如果我们要保证消息的顺序性,可以通过发送指定 分区 来实现。
每个 partition 由多个 Segment 组成,每个 Segment 包括 index 和 data 两部分,都别是 *.index 和 *.log。
消息丢失
1. 发送丢失
一般是 producer.send(msg) 发送消息,他是异步的,也就是说其实你投递失败了你也是不知道的。使用 producer.send(msg, callback),这里的 callback(回调),它能准确地告诉你消息是否真的提交成功了。一旦出现消息提交失败的情况,你就可以有针对性地进行处理。
2. 写入丢失
设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的级别定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义,这样能确保一定写入到broker成功了。
3. 消费丢失
consumer 是有个“位移”的概念,表示这个 Consumer 当前消费到的 Topic 分区的位置,就像书签一样,标记你看书看到哪里了,如果Consumer 自动提交位移,与你没有确认书籍内容被全部读完就将书归还类似,你没有真正地确认消息是否真的被消费就“盲目”地更新了位移,就会消息丢失。所以最好是生产者重试+消费者手动提交。
大致方向就上面三个,然后由于kafka的特性,还有一些其他参数也需要处理下:
1. 设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
2. 设置 replication.factor >= 3。这也是 Broker 端的参数(副本的数量)。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
3. 设置 min.insync.replicas > 1。这依然是 Broker 端参数(最小同步副本数)。控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
4. 确保确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。一般比它大一就够了。
原理概括
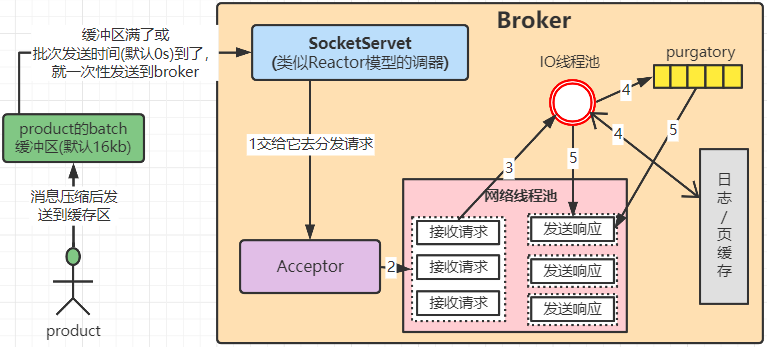
1. product 发送消息会先通过 压缩算法 进行压缩,暂存到缓冲区,最后发送到broker。
2. broker会通过 事件驱动架构的Reactor模式 去处理请求。Kafka 的 Broker 端有个 SocketServer 组件,类似于 Reactor 模式中的 Dispatcher,它也有对应的 Acceptor 线程和一个工作线程池(网络线程池)。默认会创建 3 个网络线程处理请求。
3. 网络线程拿到请求后,将请求放入到一个共享请求队列中(图中‘接收请求’的那个)。
4. IO线程池 从队列中取出请求,执行真正的处理。(默认是创建8个线程)。如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
5. 最后每个网络线程自己发送 Response 给客户端。请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属的,所以这些 Response 也就没必要放在一个公共的地方。
图中有一个叫 Purgatory 的组件,它是用来缓存延时请求(Delayed Request)的。所谓延时请求,就是那些一时未满足条件不能立刻处理的请求。比如设置了 acks=all 的 PRODUCE 请求,一旦设置了 acks=all,那么该请求就必须等待 ISR 中所有副本都接收了消息后才能返回,此时处理该请求的 IO 线程就必须等待其他 Broker 的写入结果。当请求不能立刻处理时,它就会暂存在 Purgatory 中。稍后一旦满足了完成条件,IO 线程会继续处理该请求,并将 Response 放入对应网络线程的响应队列中。
。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix