ConcurrentHashMap实现原理
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。操作时是通过ReentrantLock对Segment进行加锁,也就是分段锁的概念。
static class Segment<K,V> extends ReentrantLock implements Serializable {

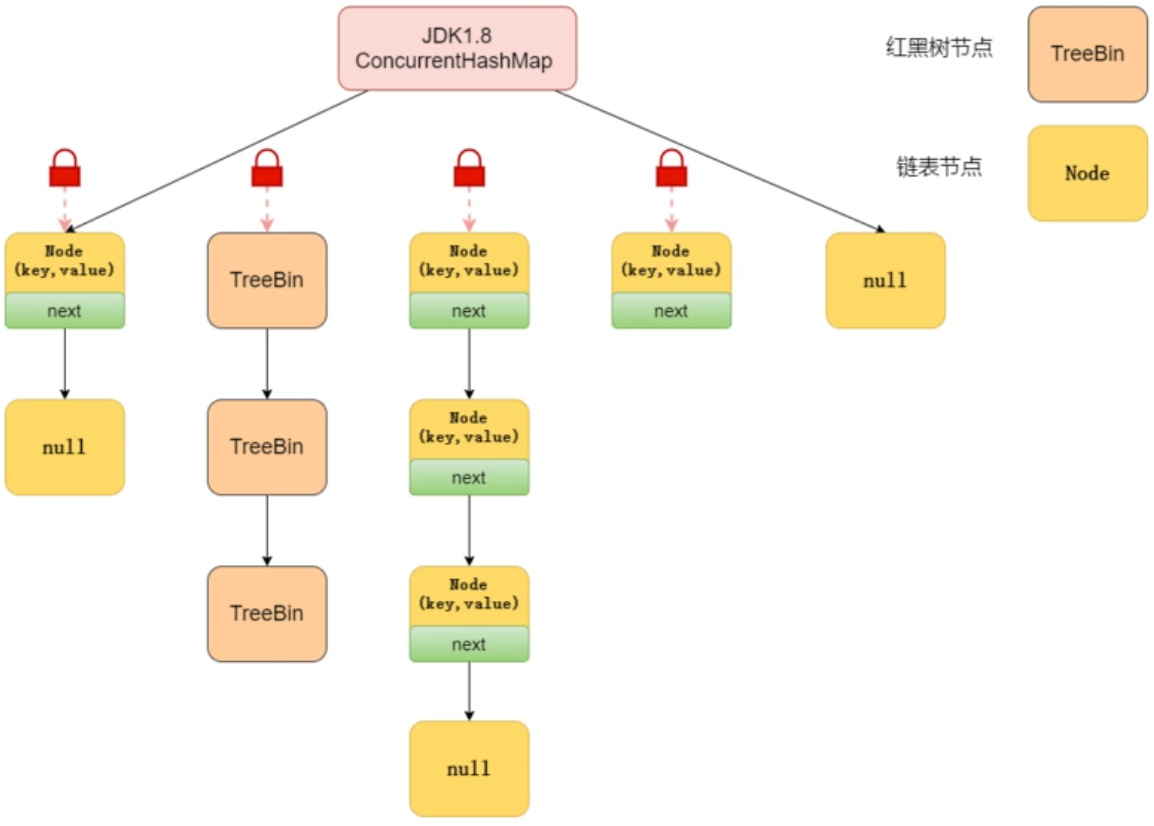
JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+红黑树形式。nade数组对应之前的hashentry。插入数据时先通过CAS进行添加,由于并发时CAS自旋效率不一定会高,所以hash冲突的话,会通过synchronized开解决并发问题。


public V put(K key, V value) { return putVal(key, value, false); } /** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); //两次hash,减少hash冲突,可以均匀分布 int binCount = 0; for (Node<K,V>[] tab = table;;) { //对这个table进行迭代 Node<K,V> f; int n, i, fh; //这里就是上面构造方法没有进行初始化,在这里进行判断,为null就调用initTable进行初始化,属于懒汉模式初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//如果i位置没有数据,就直接无锁插入 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED)//如果在进行扩容,则先进行扩容操作 tab = helpTransfer(tab, f); else { V oldVal = null; //如果以上条件都不满足,那就要进行加锁操作,也就是存在hash冲突,锁住链表或者红黑树的头结点 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { //表示该节点是链表结构 binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; //这里涉及到相同的key进行put就会覆盖原先的value if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { //插入链表尾部 pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) {//红黑树结构 Node<K,V> p; binCount = 2; //红黑树结构旋转插入 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { //如果链表的长度大于8时就会进行红黑树的转换 if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount);//统计size,并且检查是否需要扩容 return null; }
为什么不支持 key 或者 value 为 null
value 为什么不能为 null。因为 ConcurrentHashMap 是用于多线程的 ,如果ConcurrentHashMap.get(key)得到了 null ,这就无法判断,是映射的value是 null ,还是没有找到对应的key而为 null ,就有了二义性。至于key为什么不能为空,我不知道,反正源码就是那么写的。可以参考下作者的回复https://mp.weixin.qq.com/s?__biz=Mzg3NjU3NTkwMQ==&mid=2247505071&idx=1&sn=5b9bbe01a71cbfae4d277dd21afd6714&source=41#wechat_redirect
size操作
由于是并发操作的,你在计算size的时候,可能某些Segment[]还在插入数据,jdk1.7为了解决这个问题提供了两种解决方案:
1. 多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为计算的结果是准确的
2. 如果上述方法得到的结果不一致,就给所有Segment都加上锁,然后计算总的size返回。
而jdk1.8的 CAS+synchronized 方案直接就没有这个问题了。
并发度是什么
并发度可以理解为代码运行时能够同时更新 ConccurentHashMap且不产生锁竞争的最大线程数。即Segment[]的数组长度,默认是16,这个值可以在构造函数中设置。如果并发度设置的过小,会带来严重的锁竞争问题;如果并发度设置的过大,原本位于同一个Segment内的访问会扩散到不同的Segment中,CPU cache命中率会下降,从而引起程序性能下降。在JDK1.8中,已经摒弃了Segment的概念,直接CAS+synchronized 给优化了。
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号