InnoDB引擎执行流程(更新sql如何执行的)
平时我们在做应用开发时,一般情况下都会连接到一个MySQL数据库上去,把MySQL当个黑盒子一样执行各种增删改查的语句。里面的逻辑很多人都不清楚。那现在一个简单的 update users set name = "靓仔" where name = "吴磊" 在执行的时候,究竟会经过哪几步呢?
首先前台操作触发Mysql服务器执行请求,通过web项目中自带的数据库连接池:如dbcp、c3p0、druid等,与数据库服务器的数据库连接池建立网络连接;数据库连接池中的线程监听到请求后,将接收到的sql语句通过SQL接口响应给查询解析器,查询解析器将sql按照sql的语法解析出查询哪个表的哪些字段,查询条件是啥;再通过查询优化器处理,选择最优的该sq最优的一套执行计划,然后执行器负责调用存储引擎的一系列接口,执行该计划而完成整个sql语句的执行。

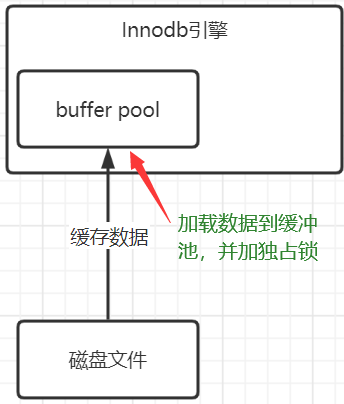
Buffer Pool
InnoDB引擎中我们执行crud时,都绕不开一个关键组件——"Buffer Pool(缓冲池)",不然每次都基于磁盘做io,性能岂不是极差,用屁股想想mysql也不可能这么设计。比如刚才的更新语句在执行的时候,它会先去buffer pool中找 "name = 吴磊" 的数据,如果没有的话,就会去磁盘中找到这条数据,然后加载到buffer pool中去,并且对数据加上独占锁。
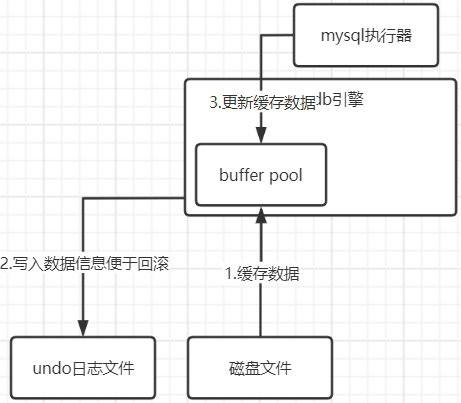
undo日志
我们在进行写操作的时候,都会伴随着事务的问题。现在我们要将"name"值由"吴磊"更新为"靓仔",此时它会首先将 旧值"吴磊"和"where name = 吴磊"过滤条件记录到undo中去,方便事务失败时回滚此次操作。

更新buffer pool的缓存数据
当我们将数据加载到buffer pool,然后写入undo日志后,就可以正式修改缓冲池中的数据了,此时的数据就是脏数据。因为缓存中的name是"靓仔",而磁盘中的是"吴磊"。
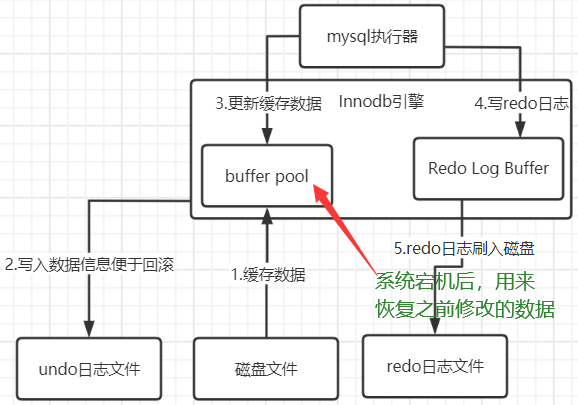
Redo Log Buffer
系统突然宕机,如何避免数据丢失?此时会将修改信息写入到内存的Redo Log Buffer中,它是一个缓冲区。它是存放redo日志文件的,比如将"name=吴磊的记录修改为name=靓仔"这就是一个日志。如果此时mysql宕机,那buffer pool修改的数据和redo log buffer的日志都会丢失,而且到目前为止我们还没提交事务,相当于没有做任何操作。

redo日志
接着mysql就会根据一定的策略将redo日志从redo log buffer刷到磁盘文件中去,策略是通过innodb_flush_log_at_trx_commit来配置的。他有几个选项。
*参数为0时,不会将redo log buffer的日志刷入磁盘。若提交事务时mysql宕机,那buffer pool的数据就会丢失。
*参数为1时,提交事务时,必须将redo log buffer日志刷入磁盘文件。此时宕机也不怕,因为redo日志已经记录了修改日志。通常都设置为1。
*参数为2时,提交事务时,将日志刷入os cache而不是磁盘文件中、会有延迟,可能出现第一种情况的后果。
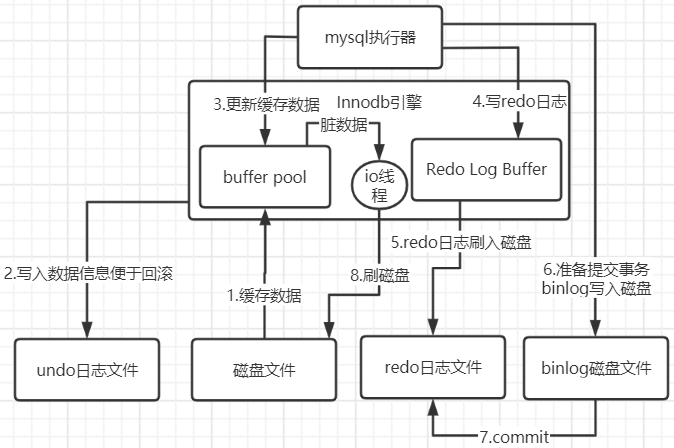
binlog
提交事务的时候,会把redo log buffer日志写入磁盘文件中去,其实同时还会把这次更新对应的binlog日志写入到磁盘文件中去。类似于"对users表中的name=吴磊的数据做了操作,修改后的值是靓仔"这样一条日志。redo log是innodb引擎特有的东西,binlog是属于mysql server自己的日志文件。binlog写入磁盘后,就完成了此次的事务提交,同时向redo中打入commit标记。
*binlog可以通过sync_binlog参数可以控制binlog的刷盘策略,他的默认值是0,写入在os cache(如果宕机当然就丢失了);如果是为1,就是直接写入磁盘文件。

io刷盘
最后就会有一条后台线程将buffer pool的数据同步到磁盘中去,即使宕机也没关系。它会找到redo带commit标记的日志,等合适的时机再同步。
。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号