jvm线上调优实战
在前面文章我们了解到了jvm的内存模型、对象分配的规则、以及对象何时进入到老年代、垃圾回收器,并且知道jvm调优的本质就是对堆内存进行调优,尽量使对象留在新生代中、少触发老年代gc。那么本文将介绍生产环境上如何去排查问题这样的一个思路。用的是最原始、有low、也最有效的jstat命令,因为每个公司情况不一样你不一定有权限使用jConsole、VisualVM那些可视化工具。
如何监控进程jvm信息
我们通过 jstat -gc PID 命令就可以来监控java进程的内存和GC情况了。

S0C:第一个幸存区的总大小(单位kb,1mb=1024kb,可以看到整个新生代一共刚好是设置的100mb)
S1C:第二个幸存区的总大小
S0U:第一个幸存区当前已使用大小
S1U:第二个幸存区当前已使用大小
EC: 伊甸园区的总大小
EU: 伊甸园区的使用大小
OC:老年代总大小
OU:老年代当前已使用大小
MC:方法区(元空间)总大小
MU:方法区(元空间)当前已使用大小
CCSC:压缩类空间大小
CCSU:压缩类空间使用大小
YGC:系统迄今为止年轻代垃圾回收次数
YGCT:年轻代垃圾回收总消耗时间和
FGC:系统迄今为止老年代垃圾回收次数
FGCT:老年代垃圾回收总消耗时间和
GCT:所有gc消耗总时间 (YGCT+FGCT)
除了 jstat -gc PID 之外,还有一些其他命令可以看到详细信息了,不过单独这一个命令就已经够用了。
jstat -gccapacity 堆内存分析
jstat -gcnew 年轻代GC分析,TT和MTT表示年轻代对象最小年龄和最大年龄
jstat -gcnewcapacity 年轻代内存分析
jstat -gcold 老年代GC分析
jstat -gcoldcapacity 老年代内存分析
jstat -gcmetacapacity 元空间内存分析
新生代对象增长速率
jstat -gc PID time num ,这个命令就是每隔指定time时间监控一次jvm信息,一共统计num次。比如我们现在每隔1s统计一次,一共统计5次。
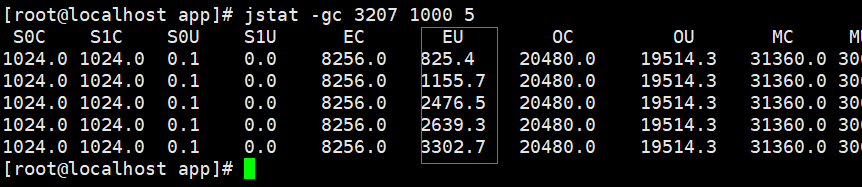
我们现在只需要看“EU”这一列,就可以看到eden区的使用情况了。如果第一次是200mb,第二次205mb,第三次209mb。那么我们可以估算出每秒eden区新增5mb对象。我们可以根据自己系统的情况设置成每分钟或者每十分钟监控一次,也可以看看系统高峰期和日常两种情况下对象的增长速率。
Young GC触发频率和耗时
我们知道eden区新增对象的速率后,就可以计算出young gc触发的频率和耗时了。比如eden区有800mb对象,每秒新增5m,那么160s就会把eden区装满、差不多3分钟的样子就会触发一次young gc。如果每秒新增0.5m对象,那就是30分钟一次young gc。gc耗时我们可以用 ygct/ygc 求出每次young gc的所用时长。

老年代对象增长速率
3分钟一次young gc,那我们就3分钟监控一次jvm信息,查看10次。jstat -gc PID 180000 10

此时可以看看young gc后 eden survivor 老年代 的对象变化。正常来讲,eden区每次放满对象再gc后,里面的对象会变得很少。然后survivor区会放入一些存活对象,老年代也会增长一些对象。
正常来讲,一般老年代对象不会增长的很快,因为我们的系统其实没那么多长期存活的对象。如果每次young gc后,老年代增长几十mb,说明young gc后存活的对象太多了需要调优下,一般新增 几百kb、几mb才是正常水准。我们通过这十次每次进入老年的的对象大小求出平均数,就知道老年代的增长速率啦。
Full GC触发频率和耗时
比如现在我们知道每3分钟一次young gc后有50mb进入老年代,那么48分钟就会把老年代装满触发一次full gc。比如现在一共进行了10次full gc共耗时20s,那么每次耗时就是2s。
jvm调优实战
案例代码
/** java -jar -Xmn100M -Xms200M -Xmx200M -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=20M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log demo-1.0.jar 新生代100m , 总堆200m , eden:from:to=8:1:1 , 超过15岁进入老年代 , 大对象阈值20m , parnew+cms回收 */ public class Demo1 { public static void main(String[] args) throws Exception{ // 系统先休眠30s,给我们足够的时间找到pid来监测进程情况。 Thread.sleep(30000); while (true){ loadData(); } } private static void loadData()throws Exception{ byte[] data = null; // 每次生成40mb垃圾对象 for(int i=0;i<4;i++){ data = new byte[10 * 1024 * 1024]; } data = null; // data1 data2 被引用不会成为垃圾 byte[] data1 = new byte[10 * 1024 *1024]; byte[] data2 = new byte[10 * 1024 *1024]; byte[] data3 = new byte[10 * 1024 *1024]; // data3指向新对象,之前的成为垃圾 data3 = new byte[10 * 1024 *1024]; // 阻塞1s,来模拟每个请求执行完需要1s Thread.sleep(1000); } }
gc分析
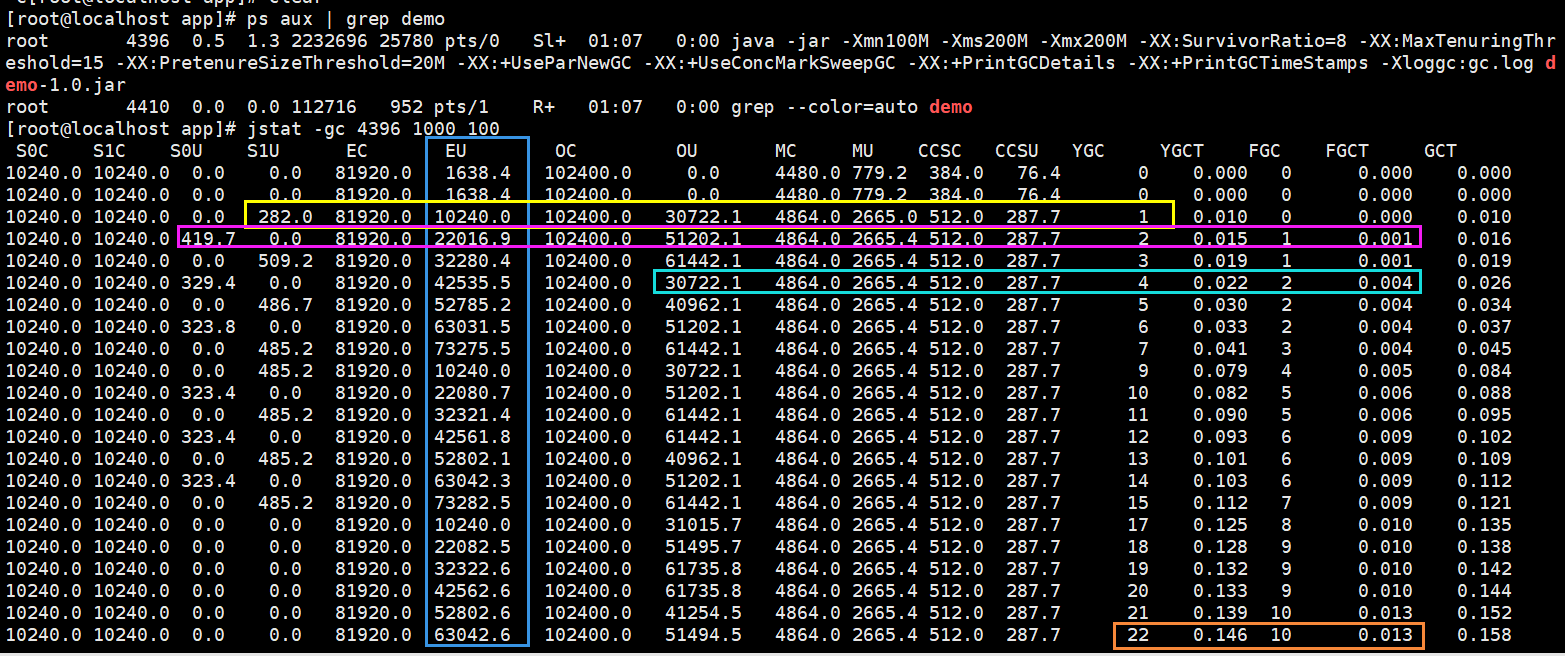
1. 最开始eden区一直只有1638kb,说明线程还在30s的阻塞中没开始创建对象
2. 下一秒可以看到已经触发了young gc了。eden区只有80m,我们创建了80m对象再加上一些系统自己占用的内存,所以eden就放不下了。回收了282k在survivor区中(一些系统未知对象),data1 data2 data3 一共30mb放入了老年代。
3. 每次young gc都会存活很多对象,而survivor放不下,都会直接进入老年代
4. 老年代从30m、50m、60m又变成了30m,说明老年代放不下了对60m进行了fgc回收,装了新的30m
通过对比可以看到每秒执行一次ygc,每2秒左右执行一次fgc。每次ygc差不多22/0.146=0.0067秒,每次fgc差不多0.013/10=0.0013秒。ygc执行时间是fgc5倍。所以不难发现,我们的ygc不是由于老年代自己空间不足发生的,而是新生代ygc的时候survivor放不下,触发了老年代的空间担保机制和动态年龄判断造成的。ygc每次都要等fgc将老年代清出空余位置后才把对象放入老年代。所以才会出现ygc比fgc时间要长的情况。
性能调优
鉴于上一步的分析,我们可以看出由于新生代的内存不足,导致每次ygc都会将对象放入老年代,频繁触发fgc。所以我们要加大新生代内存空间,最好survivor区可以放下每次ygc的对象。
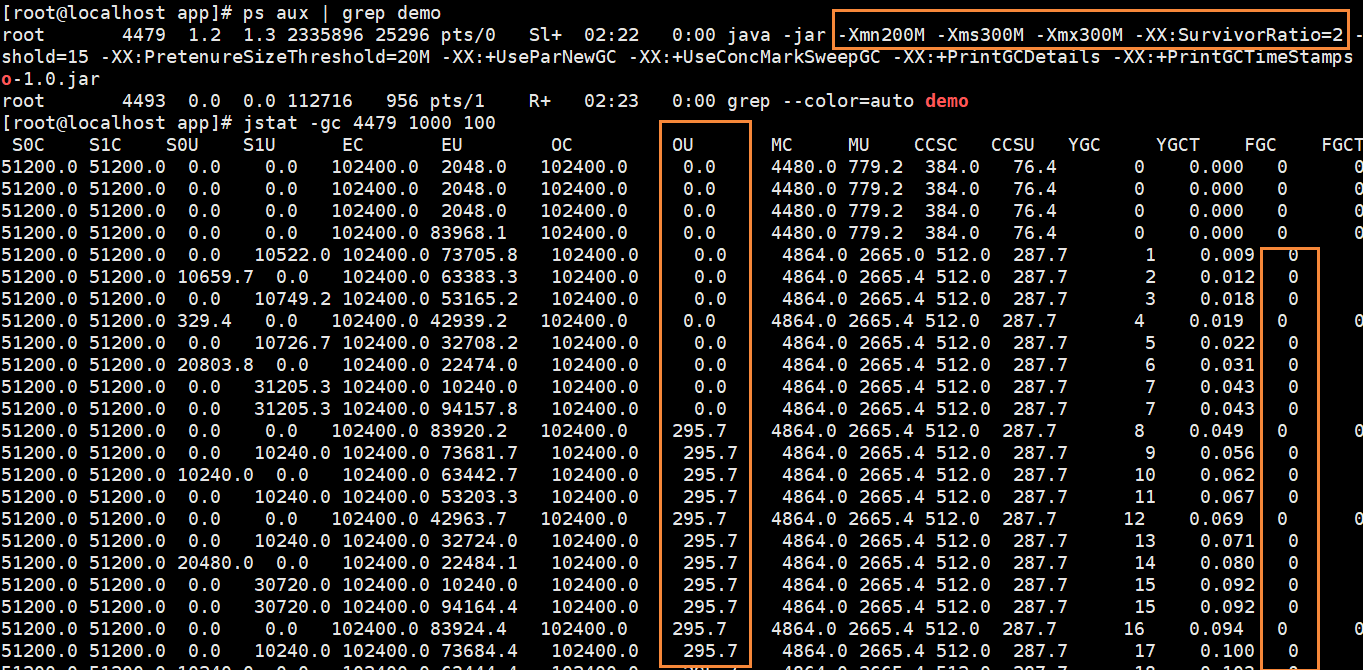
java -jar -Xmn200M -Xms300M -Xmx300M -XX:SurvivorRatio=2 -XX:MaxTenuringThreshold=15 -XX:PretenureSizeThreshold=20M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log demo-1.0.jar 新生代200m,总堆300m,eden:s0:s1=2:1:1 此时查看jvm可以看到没有触发fgc了,只有少量对象进入老年代中。一般的系统young gc几分钟或几十分钟一次,每次不超过几十毫秒是正常的;full gc几十分钟或几小时一次,几百毫秒之内是正常的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号