Python爬虫学习总结-爬取某素材网图片
⭐Python爬虫学习总结-爬取某素材网图片
最近在学习python爬虫,完成了一个简单的爬取某素材网站的功能,记录操作实现的过程,增加对爬虫的使用和了解。
1️⃣ 前期准备
1.1 浏览器安装xpath插件(以chrome浏览器为例)
插件下载地址:https://wwa.lanzout.com/iUwy601einob
将插件手动拖拽到浏览器扩展中即可完成安装(安装完后需要重启浏览器)
启动插件快捷键Ctrl+shift+x
1.2 安转lxml依赖
安转lxml依赖前,需要安装有pip才能下载依赖
查看电脑是否安装pip指令:pip -V
安装lxml前需要先进入到python解释器的Scripts路径中
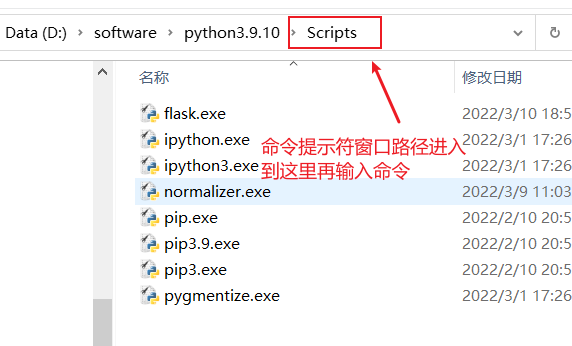
安装指令:pip install lxml ‐i https://pypi.douban.com/simple
1.3 学习xpath基本语法
xpath基本语法:
1.路径查询
//:查找所有子孙节点,不考虑层级关系
/ :找直接子节点
2.谓词查询
//div[@id]
//div[@id="maincontent"]
3.属性查询
//@class
4.模糊查询
//div[contains(@id, "he")]
//div[starts‐with(@id, "he")]
5.内容查询
//div/h1/text()
6.逻辑运算
//div[@id="head" and @class="s_down"]
//title | //price
2️⃣ 分析界面
以站长素材网站为例:https://sc.chinaz.com/
2.1查看图片页面的源码,分析页面链接规律
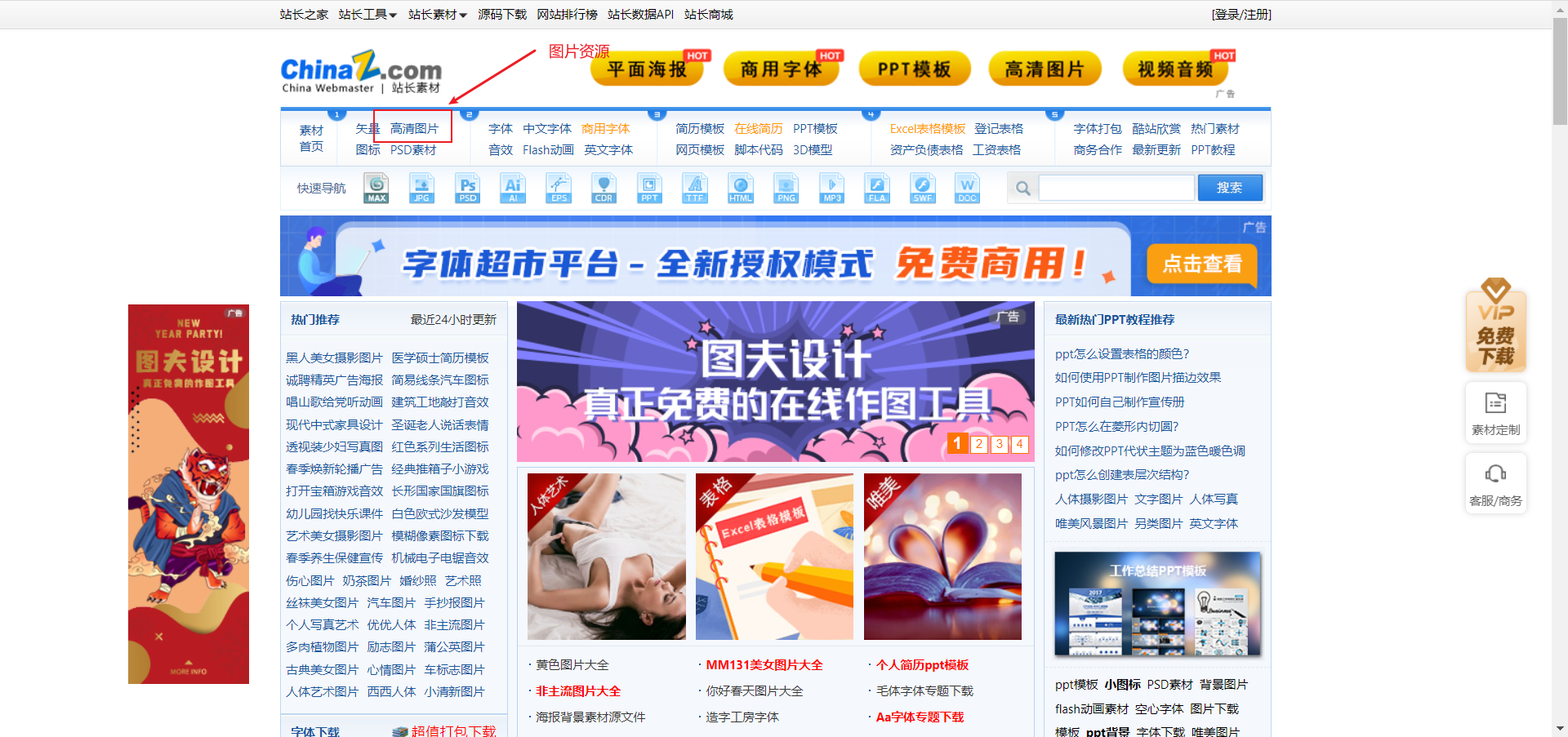
打开有侧边栏的风景图片(以风景图片为例,分析网页源码)
第一页图片的地址:https://sc.chinaz.com/tupian/fengjingtupian.html
第二页图片的地址:https://sc.chinaz.com/tupian/fengjingtupian_2.html
第三页图片的地址:https://sc.chinaz.com/tupian/fengjingtupian_3.html
第n页图片的地址:https://sc.chinaz.com/tupian/fengjingtupian_page.html page是代表当前的页数
⭐通过分析网址可以得到每页网址的规律,接下来分析图片地址如何获取到
2.2 分析如何获取图片下载地址
首先在第一页通过F12打开开发者工具,找到图片在源代码中位置
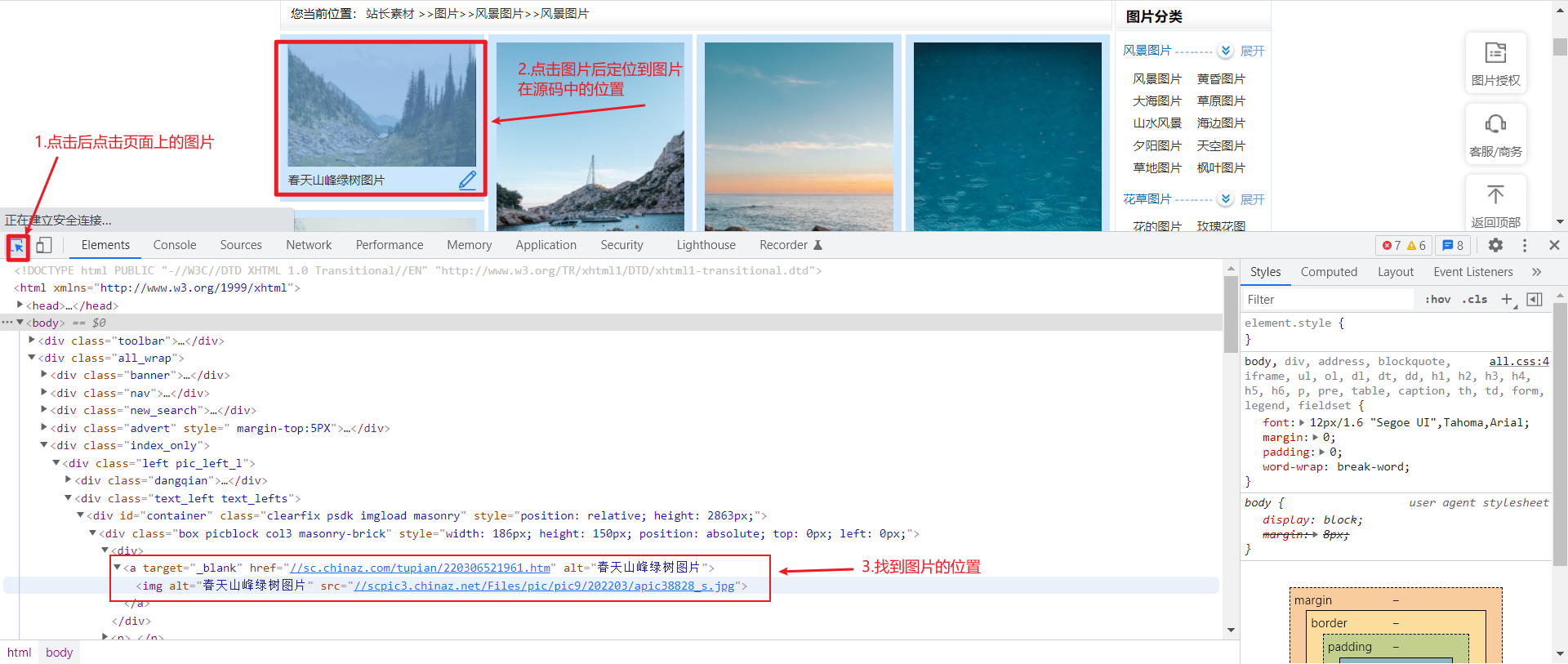
:⭐通过分析源码可以看到图片的下载地址和图片的名字,接下来通过xpath解析,获取到图片名字和图片地址
2.3 xpath解析获取图片地址和名字
调用xpath插件得到图片名字://div[@id="container"]//img/@alt
图片下载地址://div[@id="container"]//img/@src2
注意:由于该界面图片的加载方式是懒加载,一开始获取到的图片下载地址才是真正的下载地址也就是src2标签
⭐前面的工作准备好了,接下来就是书写代码
3️⃣代码实现
3.1 导入对应库
import urllib.request
from lxml import etree
3.2 函数书写
请求对象的定制
def create_request(page,url):
# 对不同页面采用不同策略
if (page==1):
url_end = url
else:
#切割字符串
url_temp = url[:-5]
url_end = url_temp+'_'+str(page)+'.html'
# 如果没有输入url就使用默认的url
if(url==''):
url_end = 'https://sc.chinaz.com/tupian/fengjingtupian.html'
# 请求伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
# 请求对象的定制
request = urllib.request.Request(url = url_end,headers=headers)
# 返回伪装后的请求头
return request
获取网页源码
def get_content(request):
# 发送请求获取响应数据
response = urllib.request.urlopen(request)
# 将响应数据保存到content
content = response.read().decode('utf8')
# 返回响应数据
return content
下载图片到本地
def down_load(content):
# 下载图片
#urllib.request.urlretrieve('图片名称','文件名字')
# 解析网页
tree = etree.HTML(content)
# 获取图片姓名 返回的是列表
img_name = tree.xpath('//div[@id="container"]//a/img/@alt')
img_add = tree.xpath('//div[@id="container"]//a/img/@src2')
# 循环下载图片
for i in range(len(img_name)):
# 挨个获取下载的图片名字和地址
name = img_name[i]
add = img_add[i]
# 对图片下载地址进行定制
url = 'https:'+add
# 下载到本地 下载图片到当前代码同一文件夹的imgs文件夹中 需要先在该代码文件夹下创建imgs文件夹
urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')
主函数
if __name__ == '__main__':
print('该程序为采集站长素材图片')
url = input("请输入站长素材图片第一页的地址(内置默认为风景图片)")
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
#请求对象的定制
request = create_request(page,url)
# 获取网页的源码
content = get_content(request)
# 下载
down_load(content)
💻完整代码
# 1.请求对象的定制
# 2.获取网页源码
# 3.下载
# 需求:下载前十页的图片
# 第一页:https://sc.chinaz.com/tupian/touxiangtupian.html
# 第二页:https://sc.chinaz.com/tupian/touxiangtupian_2.html
# 第三页:https://sc.chinaz.com/tupian/touxiangtupian_3.html
# 第n页:https://sc.chinaz.com/tupian/touxiangtupian_page.html
import urllib.request
from lxml import etree
# 站长素材图片爬取下载器
def create_request(page,url):
# 对不同页面采用不同策略
if (page==1):
url_end = url
else:
#切割字符串
url_temp = url[:-5]
url_end = url_temp+'_'+str(page)+'.html'
# 如果没有输入url就使用默认的url
if(url==''):
url_end = 'https://sc.chinaz.com/tupian/fengjingtupian.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39'
}
request = urllib.request.Request(url = url_end,headers=headers)
return request
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
return content
def down_load(content):
# 下载图片
#urllib.request.urlretrieve('图片名称','文件名字')
tree = etree.HTML(content)
# 获取图片姓名 返回的是列表
img_name = tree.xpath('//div[@id="container"]//a/img/@alt')
img_add = tree.xpath('//div[@id="container"]//a/img/@src2')
for i in range(len(img_name)):
name = img_name[i]
add = img_add[i]
# 对图片下载地址进行定制
url = 'https:'+add
# 下载到本地
urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')
if __name__ == '__main__':
print('该程序为采集站长素材图片')
url = input("请输入站长素材图片第一页的地址(内置默认为风景图片)")
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
#请求对象的定制
request = create_request(page,url)
# 获取网页的源码
content = get_content(request)
# 下载
down_load(content)
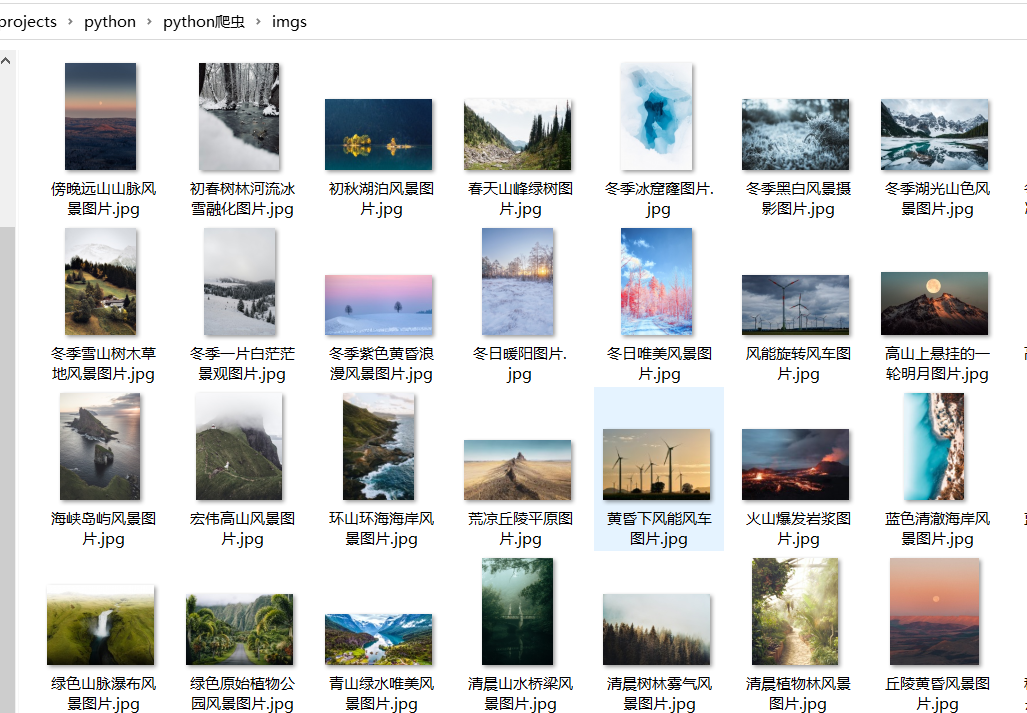
4️⃣运行结果

🚀总结
此次案例是基于尚硅谷的python视频学习后的总结,感兴趣的可以去看全套视频,尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)_哔哩哔哩_bilibili
人们总说兴趣是最好的老师,自从接触爬虫后我觉得python十分有趣,这也是我学习的动力,通过对一次案例的简单总结,回顾已经学习的知识,并不断学习新知识,是记录也是分享。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号