第一次作业——结合三次小作业
作业一
(1)UniversitiesRanking实验
代码:
1 # wanglu031804127UniversitiesRanking.py 2 3 import requests 4 from bs4 import BeautifulSoup 5 6 7 def getHtmlText(url): 8 try: 9 r = requests.get(url, timeout=30) 10 r.raise_for_status() # 如果状态不是200,则引发HTTPError异常 11 r.encoding = r.apparent_encoding 12 return r.text 13 except: 14 print('响应失败') 15 return "" 16 17 18 def printUnivList(html): 19 tqlt = "{0:^10}\t{1:{5}^10}\t{2:^10}\t{3:^10}\t{4:^10}" 20 soup = BeautifulSoup(html, 'html.parser') 21 print(tqlt.format("排名", "学校", "省市", "类型", "总分", chr(12288))) # 采用中文字符的空格填充chr(12288) 22 for tr in soup.find('tbody').children: 23 tds = tr.find_all('td') # tds为tr标签的列表 24 # strip()方法用于去除字符串首尾的空白字符 25 print(tqlt.format(tds[0].text.strip(), tds[1].text.strip(), tds[2].text.strip(), tds[3].text.strip(), 26 tds[4].text.strip(), chr(12288))) 27 28 29 uinfo = [] 30 url = 'http://www.shanghairanking.cn/rankings/bcur/2020.html' 31 html = getHtmlText(url) 32 printUnivList(html)
结果图片:
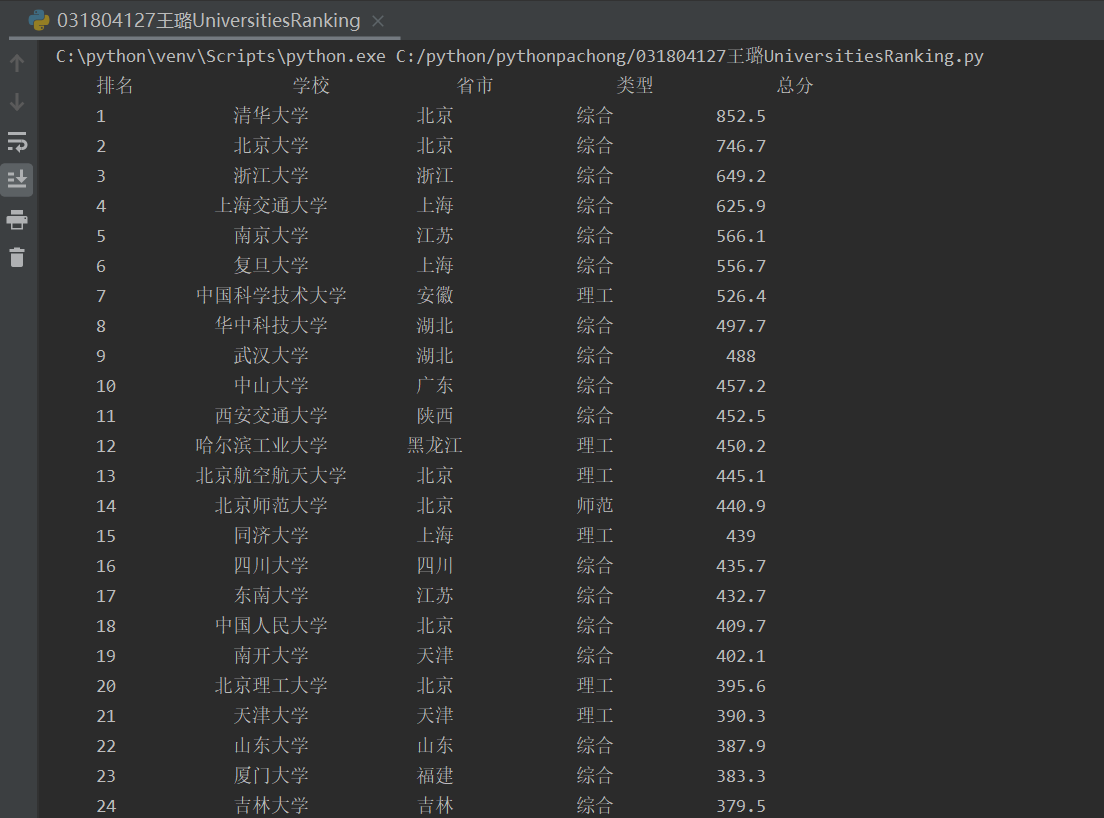
(2)心得体会
本次实验我动手实践爬取了大学排名。实验的第一步就是需要爬取网页的内容,用到了Requests库。这个爬取框架是我从网上搜索得来的,通过自己的查询和学习,理解了每一步的作用,比如r.status_code是HTTP请求的返回状态,200表示连接成功;r.encoding是从HTTP header中猜测的响应编码方式,而r.apparent_encoding是从内容中分析出的响应编码方式,因此,将r.apparent_encoding获得的内容赋给r.encoding可以正常看到网页中的内容。之后在编写输出函数的最后一步,输出内容的时候,我遇到了困难。我最开始是用tds[].string的方法输出的,但是最后结果总是报错,提示我有部分内容为NoneType,我在网上搜索了一下,发现一个Tag类型的对象返回一个NavigableString类型的对象,另一方面,.text获取所有的子字符串,并使用给定的分隔符返回连接. .text的返回类型是unicode对象.,因此改成用text.strip()方法输出,显示结果就正常了,这也让我意识到了细心的重要性,考虑问题要全面。
作业二
(1)GoodsPrice实验
代码:
1 # wanglu031804127 GoodsPrice.py 2 3 import requests 4 import re 5 from bs4 import BeautifulSoup 6 7 8 def getHTMLText(url): 9 try: 10 kv = {'user-agent': 'Mozilla/5.0'} 11 r = requests.get(url, headers=kv) # 加上头部,伪装成浏览器访问,以防爬虫被限制 12 r.raise_for_status() 13 r.encoding = r.apparent_encoding 14 return r.text 15 except: 16 return "" 17 18 19 def parsePage(html): 20 try: 21 soup = BeautifulSoup(html, "html.parser") 22 bag = soup.select("div[class='p-name p-name-type-2'] em") # 爬取商品名信息 23 price = soup.select("div[class='p-price'] i") # 爬取商品价格信息 24 for i in range(len(bag)): 25 GoodsName.append(bag[i].text.replace("\n", "").replace(" ", "").replace("\t", "")) # 去掉空白符 26 GoodsPrice.append(price[i].text.replace(" ", "")) 27 except: 28 print("") 29 30 31 def printGoodsList(GoodsName, GoodsPrice): 32 tplt = "{:4}\t{:16}\t{:8}" # 规范输出格式 33 print(tplt.format("序号", "商品名", "价格")) 34 for i in range(len(GoodsName)): 35 print(tplt.format(i, GoodsName[i], GoodsPrice[i])) 36 37 38 GoodsName = [] 39 GoodsPrice = [] 40 cate = '书包' # 指定商品种类 41 depth = 2 # 爬取前两页的商品信息 42 url = 'https://search.jd.com/Search?keyword=' + cate # 指定商品种类网址 43 # 爬取前两页 44 for i in range(depth): 45 try: 46 url = url + '&page=' + str(1 + i * 2) # 指定页面 47 html = getHTMLText(url) 48 parsePage(html) 49 except: 50 continue 51 printGoodsList(GoodsName, GoodsPrice
结果图片:

(2)心得体会
这次实验和上次实验内容差不多,都是爬取网页内容并输出。但是需要注意的问题有两个。一个是因为京东网站具有反爬虫的机制,所以用上次实验的网页爬取框架可能造成爬虫失败,因此在这次的网页爬取函数中,我自己定义了并添加了一个头部信息,将自己的个人电脑伪装成浏览器去爬取信息,就能成功了;第二个就是商品关键词和爬取页数的问题。老师要求我们爬取两页关于书包的商品和价格信息,因此网页的url是会改变的,我观察了一下在搜索书包关键词下,不同页面url的改变,第一页:https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&qrst=1&wq=%E4%B9%A6%E5%8C%85&stock=1&page=1&s=1&click=0;第二页:https://search.jd.com/Search?keyword=%E4%B9%A6%E5%8C%85&qrst=1&wq=%E4%B9%A6%E5%8C%85&stock=1&page=3&s=51&click=0,可以看出页码不同体现在page上,因此使用一个for循环就能实现对前两页信息的爬取。
作业三
(1)JPGFileDownload实验
代码:
1 # 031804127王璐JPGFileDownload.py 2 3 from wsgiref import headers 4 from bs4 import BeautifulSoup 5 from bs4 import UnicodeDammit 6 import urllib.request 7 8 9 def imageSpider(start_url): 10 try: 11 urls = [] 12 req = urllib.request.Request(start_url, headers=headers) 13 data = urllib.request.urlopen(req) 14 data = data.read() 15 dammit = UnicodeDammit(data, ["utf-8", "gbk"]) 16 data = dammit.unicode_markup 17 soup = BeautifulSoup(data, 'lxml') 18 images = soup.select("img") # 爬取所有图片 19 for image in images: 20 try: 21 # 获取图片的url 22 src = image["src"] 23 url = urllib.request.urljoin(start_url, src) 24 if url not in urls: 25 urls.append(url) # 没有被爬取过的图片就添加 26 print(url) 27 download(url) # 下载图片 28 except Exception as err: 29 print(err) 30 except Exception as err: 31 print(err) 32 33 34 def download(url): 35 global count # 声明全局变量count 36 try: 37 count = count + 1 38 if (url[len(url) - 4] == "."): # 图片格式后缀为三位,格式后缀前面的字符为"." 39 ext = url[len(url) - 4:] # 获取图片格式 40 else: 41 ext = "" 42 # 获取图片文件 43 req = urllib.request.Request(url, headers=headers) 44 data = urllib.request.urlopen(req, timeout=100) 45 data = data.read() 46 # 存储图片到指定位置并命名 47 fobj = open("D:\\images\\" + str(count) + ext, "wb") # 以二进制形式打开文件 48 fobj.write(data) 49 fobj.close() 50 print("downloaded" + str(count) + ext) 51 except Exception as err: 52 print(err) 53 54 55 start_url = "http://jwch.fzu.edu.cn/" 56 headers = {"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"} 57 count = 0 # 用于记录爬取图片的个数 58 imageSpider(start_url)
结果图片:
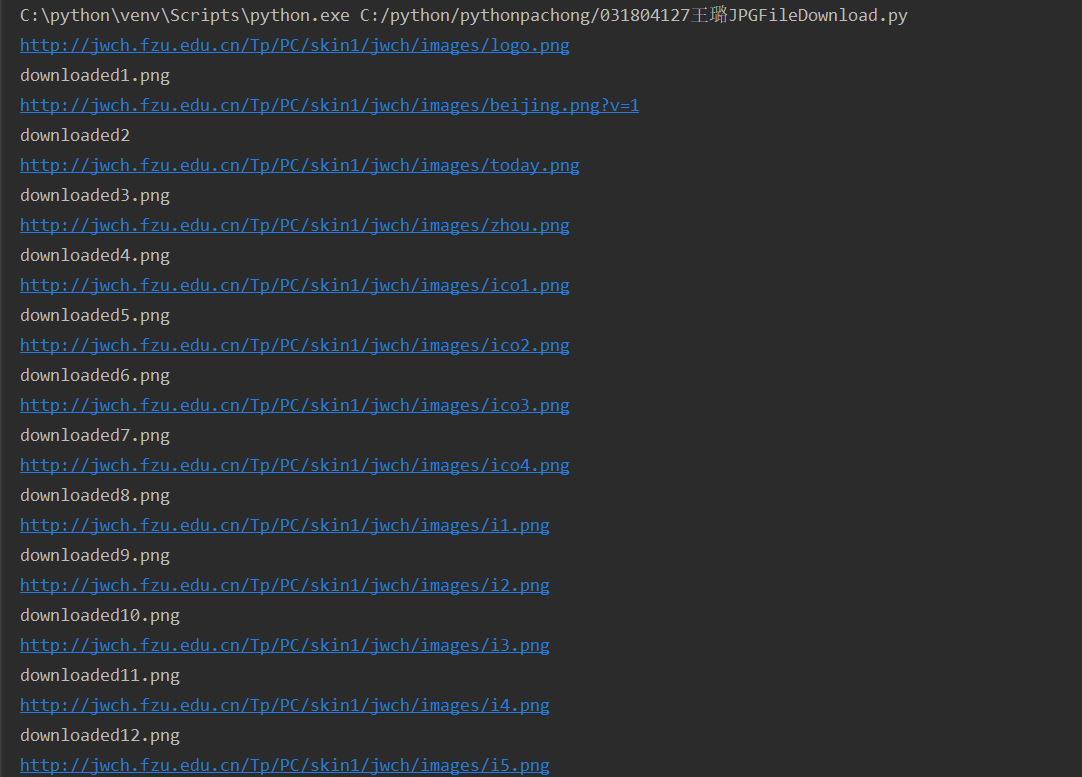
(2)实验心得
这次实验我是直接参考了书本3.5节,实践项目爬取网站图像文件的代码。由于还没有学习多线程,所以我参考的是单线程爬取图像的程序。下面就来总结一下在本次实验学到了哪些东西:首先就是对图片url的获取,由于教务处网站图片的HTML都是<img src="/Tp/PC/skin1/jwch/images/zhou.png" alt="">的格式,因此要获取图片的url,就要用教务处网站的网址加上“src=”后面的url内容,这就要使用urljoin()方法,将两段网址连接起来,得到图片的url;然后就是图片文件写入的问题,由于图片是以二进制形式存储的,因此要用‘wb’打开文件并写入,才能正确存储图片;最后一点,单线程程序会因为网站某个图像下载过程缓慢而效率低下,因此效率远远没有多线程高,所以在学习掌握了多线程爬取之后,我会改进我的代码,使之更高效。
