hudi
1.Hudi的介绍
2.Hudi环境的搭建
maven安装
在Centos系统上安装maven
wget https://dlcdn.apache.org/maven/maven-3/3.8.6/binaries/apache-maven-3.8.6-bin.tar.gz
配置maven的环境变量
# 解压缩
tar -zxvf apache-maven-3.8.6-bin.tar.gz
# 配置maven环境
vim /etc/profile
export MAVEN_HOME=/home/wl/apache-maven-3.8.6-bin
export PATH=$MAVEN_HOME/bin:$PATH
source /etc/profile
Hudi安装
下载hudi的源码包
wget https://dlcdn.apache.org/hudi/0.9.0/hudi-0.9.0.src.tgz
解压缩hudi源码包并编译hudi
mvn clean install -DskipTests -DskipITs -Dscala-2.12 -Dspark3
3.Hudi的使用
spark写入hudi
准备数据,resident.txt
{"username":"zhangsan","password":"123456","address":"翻斗家园1号街","ip":"192.182.11"}
{"username":"lisi","password":"www","address":"翻斗家园2号街","ip":"192.182.11"}
{"username":"wangwu","password":"23456","address":"翻斗家园3号街","ip":"192.182.11"}
{"username":"lili","password":"1333","address":"翻斗家园4号街","ip":"192.182.11"}
{"username":"xaiozhang","password":"5778","address":"翻斗家园1号街","ip":"192.182.11"}
启动spark-shell,指定环境
bin/spark-shell \
> --jars /home/wl/hudi-jar/hudi-spark3-bundle_2.12-0.9.0.jar,\
> /home/wl/hudi-jar/spark-avro_2.12-3.0.1.jar,/home/wl/hudi-jar/spark_unused-1.0.0.jar \
> --conf "spark.serializer=org.apache.spark.serializer.KryoSerializer"
resident.txt,写入hudi表
# 读取json文件转换成dataframe
val df=spark.read.json("/home/wl/data/resident.txt")
# 导入运行环境
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "resident"
val basePath = "hdfs://192.168.160.2:8020/spark"
# 打开粘贴模式防止换行出错
# 将数据写入hudi表 保存至hdfs
:paste
df.write.
format("hudi").
mode(Overwrite).
options(getQuickstartWriteConfigs).
option(PRECOMBINE_FIELD.key(),"username").
option(RECORDKEY_FIELD.key(),"password").
option(PARTITIONPATH_FIELD.key(), "ip").
option(TBL_NAME.key(), tableName).
save(basePath)
# control+d
参数解释:
-
Overwrite:写入覆盖
-
getQuickstartWriteConfigs:设置写入/更新数据至Hudi时,Shuffle时分区数目
-
PRECOMBINE_FIELD.key():数据合并时,依据主键字段
-
RECORDKEY_FIELD.key():每个记录的唯一id
-
PARTITIONPATH_FIELD.key():分区字段
-
TABLE_NAME:表名
-
basePath:保存的路径
查看hdfs
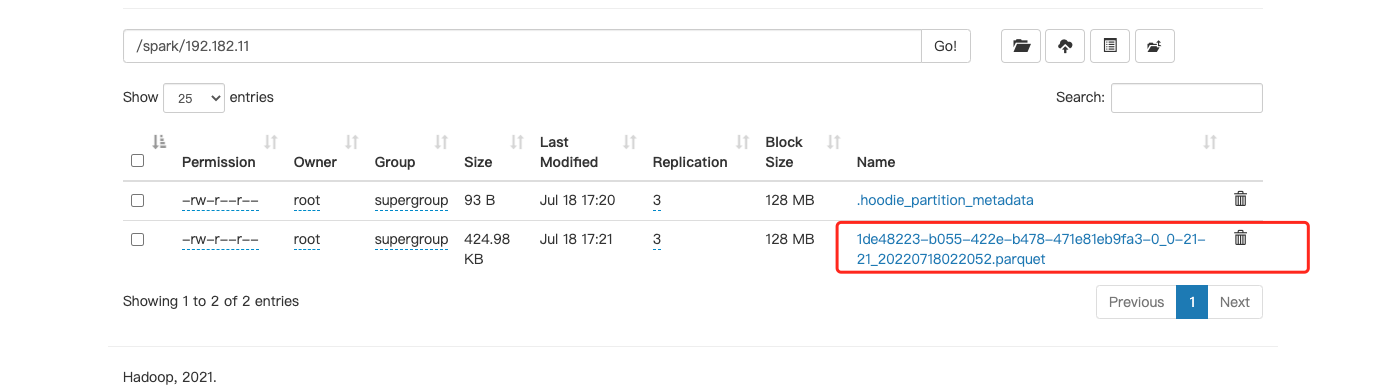
spark读取hudi数据
找到hudi分区目录,一级分区就使用 一个 /*
val df=spark.read.format("hudi").load(basePath+"/*")
打印Schema,会发现多了几个属性,这些字段属于Hudi管理数据时使用的相关字段
|-- _hoodie_commit_time: string (nullable = true)
|-- _hoodie_commit_seqno: string (nullable = true)
|-- _hoodie_record_key: string (nullable = true)
|-- _hoodie_partition_path: string (nullable = true)
|-- _hoodie_file_name: string (nullable = true)
|-- address: string (nullable = true)
|-- ip: string (nullable = true)
|-- password: string (nullable = true)
|-- username: string (nullable = true)
查询表中数据
df.show

idea中使用hudi-插入读取
环境准备
创建maven工程依赖如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hudi</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>hudi-core</module>
</modules>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<encoding>UTF-8</encoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hudi.version>0.9.0</hudi.version>
<spark.version>3.1.2</spark.version>
<hadoop.version>3.3.1</hadoop.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3-bundle_${scala.binary.version}</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- spark-hive依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
</project>
添加scala插件,并将hadoop的 core-site.xml和hdfs-site.xml配置文件放到resources目录下,并将spark的log4j.properties.template文件放到resources目录下改名log4j.properties
代码实现
读取本地的json文件,并写入hudi和读取
package com.wl.hudi
import org.apache.spark.sql.SparkSession
import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/19 上午11:39
* @qq 2315290571
* @Description ${description}
*/
object simpleExample {
def main(args: Array[String]): Unit = {
// 创建sparkSql运行环境
val spark = SparkSession.builder()
.appName("hudiExample")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 读取本地json文件转换成dataFrame
val df = spark.read.json("file:" + "/Users/wangliang/Documents/ideaProject/hudi/hudi-core/src/main/resources/resident.txt")
// 设置表名和存储路径
val tableName = "resident"
val basePath = "hdfs://192.168.160.2:8020/spark"
// 写入hudi
df.write.format("hudi")
.mode("overwrite")
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD.key(), "username")
.option(RECORDKEY_FIELD.key(), "password")
.option(PARTITIONPATH_FIELD.key(), "ip")
.option(TBL_NAME.key(), tableName)
.save(basePath)
// 读取hudi表
spark.read.format("hudi").load(basePath+"/*").show()
spark.stop()
}
}
运行结果

idea中使用hudi-更新增量删除
更新数据
准备数据resident1.txt
{"username":"zhangsan","password":"123456","address":"翻斗家园2号街","ip":"192.182.11"}
{"username":"lisi","password":"www","address":"翻斗家园3号街","ip":"192.182.11"}
{"username":"wangwu","password":"23456","address":"翻斗家园4号街","ip":"192.182.11"}
{"username":"lili","password":"1333","address":"翻斗家园5号街","ip":"192.182.11"}
{"username":"xaiozhang","password":"5778","address":"翻斗家园6号街","ip":"192.182.11"}
{"username":"xiaowang","password":"333333","address":"翻斗家园6号街","ip":"192.182.11"}
{"username":"hututu","password":"1111111","address":"翻斗家园10号街","ip":"192.182.11"}
更新数据 只需要改动 写入文件方式,hudi会帮我们 upsert
package com.wl.hudi
import org.apache.hudi.DataSourceWriteOptions.{PARTITIONPATH_FIELD, PRECOMBINE_FIELD, RECORDKEY_FIELD}
import org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs
import org.apache.hudi.config.HoodieWriteConfig.TBL_NAME
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/19 下午4:36
* @qq 2315290571
* @Description ${description}
*/
object updateExample {
def main(args: Array[String]): Unit = {
// 创建sparkSql运行环境
val spark = SparkSession.builder()
.appName("hudiExample")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 读取json文件转换成dataFrame
val df = spark.read.json("file:" + "/Users/wangliang/Documents/ideaProject/hudi/hudi-core/src/main/resources/resident1.txt")
// 设置表名和存储路径
val tableName = "resident"
val basePath = "hdfs://192.168.160.2:8020/spark"
// 更新数据
df.write.format("hudi")
.mode(SaveMode.Append)
.options(getQuickstartWriteConfigs)
.option(PRECOMBINE_FIELD.key(), "username")
.option(RECORDKEY_FIELD.key(), "password")
.option(PARTITIONPATH_FIELD.key(), "ip")
.option(TBL_NAME.key(), tableName)
.save(basePath)
// 查询更新后的数据
// 读取hudi表
spark.read.format("hudi").load(basePath+"/*").show()
}
}
运行结果

增量查询
当hudi表类型是COW时候,支持 快照查询(Snapshot Queries)和增量查询(Incremental Queries) ,默认情况下是快照查询。我们可以通过option 进行设置,最重要的两个参数如下图
设置查询类型

设置开始时间

package com.wl.hudi
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.hudi.DataSourceReadOptions._
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/19 下午5:29
* @qq 2315290571
* @Description ${description}
*/
object IncrementExample {
def main(args: Array[String]): Unit = {
// 创建sparkSql运行环境
val spark = SparkSession.builder()
.appName("hudiExample")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 设置表名和存储路径
val basePath = "hdfs://192.168.160.2:8020/spark"
import spark.implicits._
// 加载hudi数据 注册临时表 并 获取 hoodie_commit_time 当做 beginTime
spark.read
.format("hudi")
.load(basePath + "/*")
.createOrReplaceTempView("resident")
val rows: Array[String] = spark.sql(
"""
|select
| distinct(_hoodie_commit_time) as commitTime
|from
| resident
|order by
| commitTime DESC
|
|""".stripMargin).map(k => k.getString(0)).take(10)
// 因为我的时间都是同一天 所以需要转换一下
val beginTime = rows(rows.length - 1).replaceAll("20220719","20220718")
println(s"beginTime = ${beginTime}")
// 增量查询
val df = spark.read
.format("hudi")
// 设置查询数据模式为:incremental,增量读取
.option(QUERY_TYPE.key(), QUERY_TYPE_INCREMENTAL_OPT_VAL)
// 设置增量读取数据的开始时间 >beginTime
.option(BEGIN_INSTANTTIME.key(), beginTime)
.load(basePath)
// 注册临时表并查询结果
df.createOrReplaceTempView("resident_incremental")
spark.sql("select * from resident_incremental").show
}
}
运行结果
+-------------------+--------------------+------------------+----------------------+--------------------+--------------+----------+--------+---------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name| address| ip|password| username|
+-------------------+--------------------+------------------+----------------------+--------------------+--------------+----------+--------+---------+
| 20220719165757| 20220719165757_0_1| 1333| 192.182.11|a9aab30f-3263-4cc...| 翻斗家园5号街|192.182.11| 1333| lili|
| 20220719165757| 20220719165757_0_2| 23456| 192.182.11|a9aab30f-3263-4cc...| 翻斗家园4号街|192.182.11| 23456| wangwu|
| 20220719165757| 20220719165757_0_3| www| 192.182.11|a9aab30f-3263-4cc...| 翻斗家园3号街|192.182.11| www| lisi|
| 20220719165757| 20220719165757_0_4| 5778| 192.182.11|a9aab30f-3263-4cc...| 翻斗家园6号街|192.182.11| 5778|xaiozhang|
| 20220719165757| 20220719165757_0_5| 123456| 192.182.11|a9aab30f-3263-4cc...| 翻斗家园2号街|192.182.11| 123456| zhangsan|
| 20220719165757| 20220719165757_0_6| 1111111| 192.182.11|a9aab30f-3263-4cc...|翻斗家园10号街|192.182.11| 1111111| hututu|
| 20220719165757| 20220719165757_0_7| 333333| 192.182.11|a9aab30f-3263-4cc...| 翻斗家园6号街|192.182.11| 333333| xiaowang|
+-------------------+--------------------+------------------+----------------------+--------------------+--------------+----------+--------+---------+
删除数据
准备用于删除的json文件,resident2.txt
{"username":"zhangsan","password":"123456","address":"翻斗家园2号街","ip":"192.182.11"}
{"username":"lisi","password":"www","address":"翻斗家园3号街","ip":"192.182.11"}
代码
package com.wl.hudi
import org.apache.spark.sql.{SaveMode, SparkSession}
import org.apache.hudi.QuickstartUtils.getQuickstartWriteConfigs
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/19 下午6:55
* @qq 2315290571
* @Description ${description}
*/
object DeleteExample {
def main(args: Array[String]): Unit = {
// 创建sparkSql运行环境
val spark = SparkSession.builder()
.appName("hudiExample")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
// 设置表名和存储路径
val basePath = "hdfs://192.168.160.2:8020/spark"
val tableName = "resident"
// 读取删除的数据
val df = spark.read.json("file:" + "/Users/wangliang/Documents/ideaProject/hudi/hudi-core/src/main/resources/resident2.txt")
// 删除语句
df.write
.mode(SaveMode.Append)
.format("hudi")
.options(getQuickstartWriteConfigs())
// 指定写入 方式 是删除
.option(OPERATION.key(), "delete")
.option(PRECOMBINE_FIELD.key(), "username")
.option(RECORDKEY_FIELD.key(), "password")
.option(PARTITIONPATH_FIELD.key(), "ip")
.option(TBL_NAME.key(), tableName)
.save(basePath)
// 再查表看看是否减少了数据
spark.read.format("hudi").load(basePath+"/*").show
spark.stop()
}
}
查询结果


 浙公网安备 33010602011771号
浙公网安备 33010602011771号