Spark
1.WordCount入门
安装scala插件
打开plugins,搜索scala下载插件
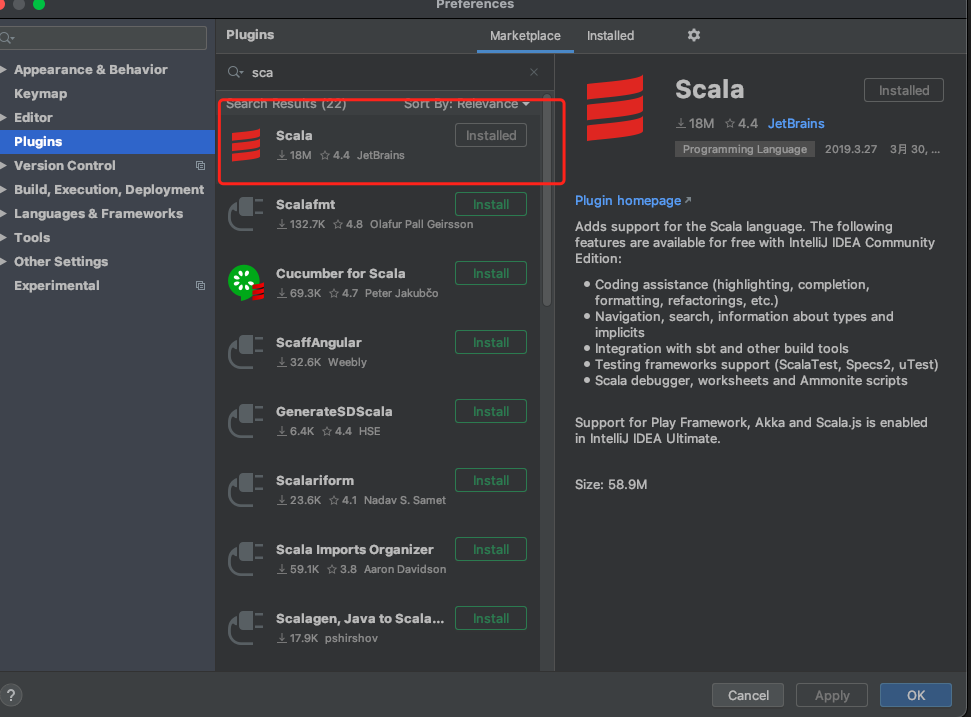
给项目添加scala环境
WordCount流程图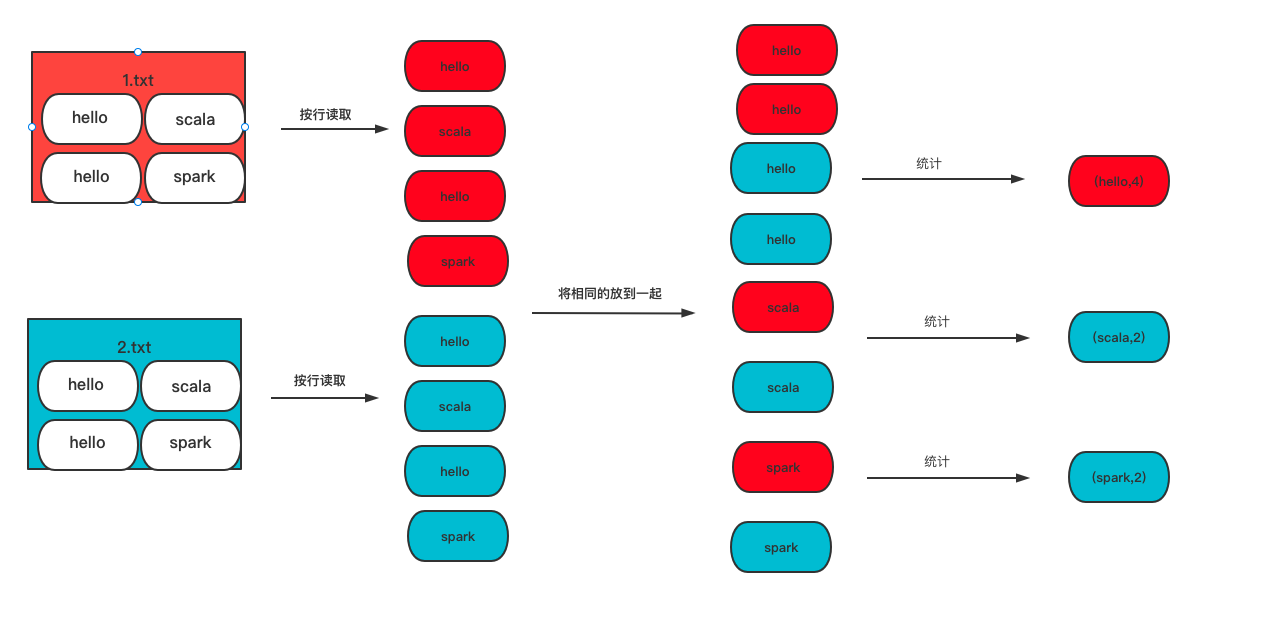
WordCount项目
maven依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<encoding>UTF-8</encoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<spark.version>3.1.2</spark.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
data下面的 word1.txt 和 word2.txt
word1.txt
hello spark
hello scala
word2.txt
hello spark
hello scala
主程序
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext, rdd}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/28 下午5:24
* @qq 2315290571
* @Description ${description}
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 配置环境
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
// 获取运行环境上下文
val sc = new SparkContext(sparkConf)
// 读取文件数据
val file: RDD[String] = sc.textFile("/Users/wangliang/Documents/ideaProject/Spark/data")
// 将文件中的数据进行分词
val word: RDD[String] = file.flatMap(_.split(" "))
// 分组聚合
val word2Rdd: RDD[(String, Iterable[String])] = word.groupBy(word => word)
// 映射
val wordCount = word2Rdd.map { case (word, list) => {
(word, list.size)
}
}
// 将数据聚合结果采集并打印
val tuple2: Array[(String, Int)] = wordCount.collect()
// 打印结果
tuple2.foreach(print)
sc.stop()
}
}
运行结果
(scala,2)(hello,4)(spark,2)
使用spark框架自带的方法
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext, rdd}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/28 下午5:24
* @qq 2315290571
* @Description ${description}
*/
object WordCount {
def main(args: Array[String]): Unit = {
// 配置环境
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
// 获取运行环境上下文
val sc = new SparkContext(sparkConf)
// 读取文件数据
val file: RDD[String] = sc.textFile("/Users/wangliang/Documents/ideaProject/Spark/data")
// 将文件中的数据进行分词
val word: RDD[String] = file.flatMap(_.split(" "))
// 转换数据结构
val word2Rdd: RDD[(String, Int)] = word.map((_, 1))
// 使用 spark自带的方法 分组聚合 reduceByKey 相同key 可以对value 进行reduce聚合
val wordCount = word2Rdd.reduceByKey((_+_))
// 将数据聚合结果采集并打印
val tuple2: Array[(String, Int)] = wordCount.collect()
// 打印结果
tuple2.foreach(print)
sc.stop()
}
}
关闭日志
在执行程序时,会出现很多日志,当我们只希望出现错误时才打印日志,可以在resource目录下创建 log4j.properties文件,内容如下:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd
HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
2.运行环境
spark提供了很多种运行环境
本地运行模式-mac
先去官网下载安装包
https://archive.apache.org/dist/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
解压缩
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz
修改conf下面的 spark-env.sh文件
#jdk 路径
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_311.jdk/Contents/Home
启动spark
./sbin/start-all.sh
启动 spark控制台
bin/spark-shell
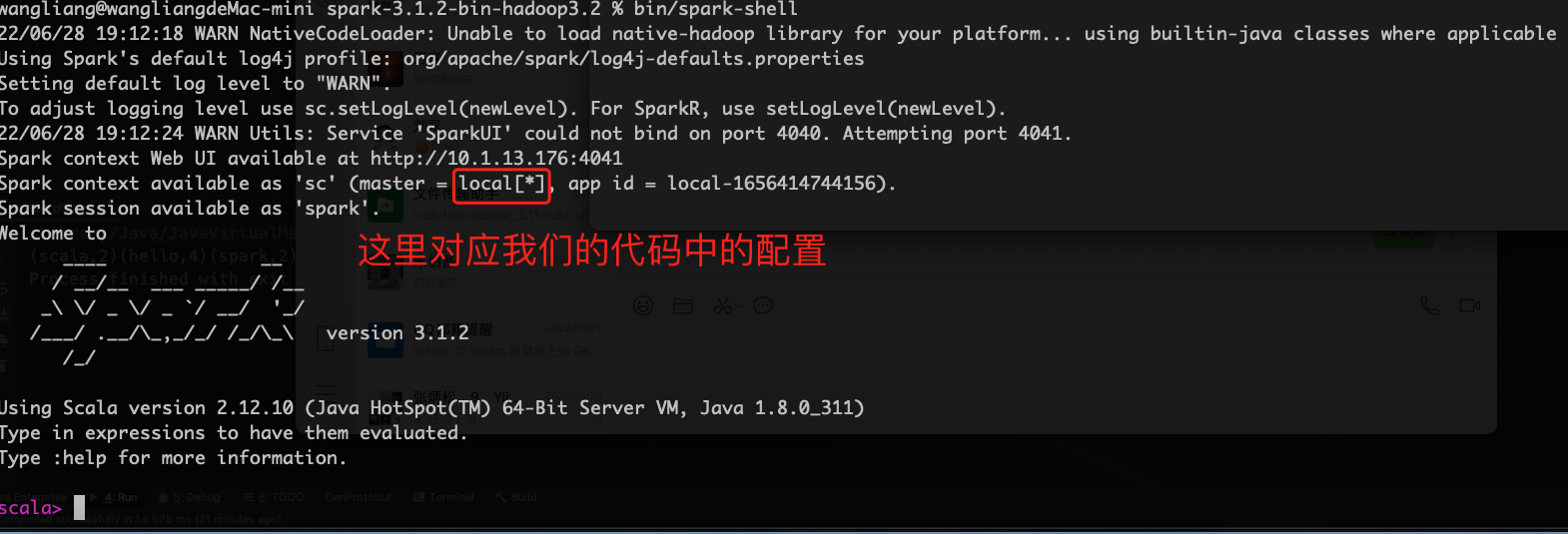
使用spark-shell完成WordCount
sc.textFile("/Users/wangliang/Documents/ideaProject/Spark/data").flatMap(_.split(" ")).map((_,1)).reduceByKey((_+_)).collect().foreach(print)

3.运行时架构
4.Spark核心编程
1.RDD是什么
RDD叫做弹性分布式数据集,是spark中最基本的数据处理模型。
主要具有以下特性:
-
弹性:
- 存储的弹性,内存与磁盘的自动切换
- 容错的弹性,数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:根据需要重新分片
-
分布式:数据存储在大数据集群不同节点上
-
数据集:RDD封装了计算逻辑,并不保存数据
-
数据抽象:RDD是一个抽象类,需要子类具体实现
-
不可变:RDD不可以改变,如果想改变只能生成新的RDD
-
可分区:并行计算
2.RDD执行原理
Spark在执行任务时,会先申请资源,将应用程序的数据逻辑分解成一个个的计算任务。然后将任务发到已经分配资源的计算节点上,按照指定的计算模型进行数据计算,最后得到结果。
RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给 Executor 节点执行计算。
3.创建RDD
在spark中创建RDD
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/30 下午3:51
* @qq 2315290571
* @Description ${description}
*/
object RDDTest {
def main(args: Array[String]): Unit = {
// 配置运行环境 localhost[*] *代表几核
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("fileTest")
// 创建运行环境
val sc = new SparkContext(sparkConf)
// 从内存中创建RDD
val seq = Seq[Int](1, 2, 3, 4)
val rdd: RDD[Int] = sc.makeRDD(seq)
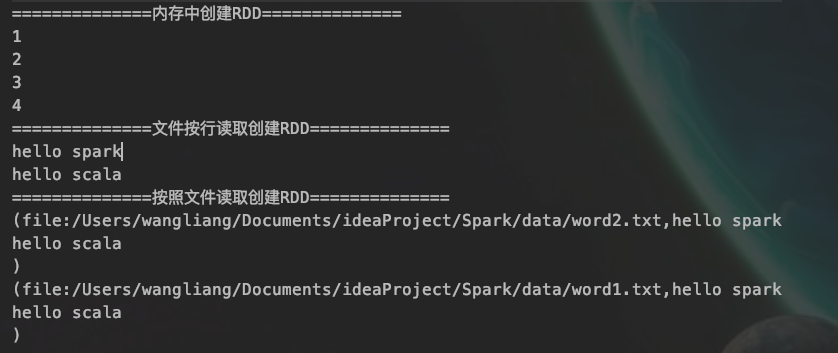
println("==============内存中创建RDD==============")
// 遍历输出
rdd.collect().foreach(println)
// 从文件中读取 按行读取
val fileRDD: RDD[String] = sc.textFile("data/word1.txt")
println("==============文件按行读取创建RDD==============")
fileRDD.collect().foreach(println)
// 从文件中读取 以文件作为单位 读取的结果是元组 可以识别文件的来源
val fileRDD2: RDD[(String, String)] = sc.wholeTextFiles("data")
println("==============按照文件读取创建RDD==============")
fileRDD2.collect().foreach(println)
sc.stop()
}
}
运行结果
4.分区的设定以及分区文件规则
内存中分区规则
在创建rdd的时候,我们使用的是makeRDD方法,这个方法有第二个参数,这个参数是设置分区数量
如果不传递则使用默认值 defaultParallelism 底层是任务运行的核数
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/30 下午4:56
* @qq 2315290571
* @Description ${description}
*/
object RDDPar {
def main(args: Array[String]): Unit = {
// 配置环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Par")
// 获取运行环境上下文
val sc = new SparkContext(sparkConf)
// 创建RDD
// makeRDD 第二个参数设置分区的数量 如果不传递则使用默认值 defaultParallelism 底层是任务运行的核数
// scheduler.conf.getInt("spark.default.parallelism", totalCores)
val rdd: RDD[Int] = sc.makeRDD(
List(1, 2, 3, 4, 5),3
)
// 将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
sc.stop()
}
}
分区中的文件中的内容是怎么分配的,我们可以通过源码进行分析。
首先点击 makeRDD方法,可以看到 parallelize(seq, numSlices) 方法
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
// 用来分隔分区文件的内容 seq 代表集合 numSlices代表分区数
parallelize(seq, numSlices)
}
再次点击 parallelize(seq, numSlices) 方法
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
// 执行分隔文件内容操作
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
点击 ParallelCollectionRDD 方法,找到 getPartitions,这个方法里面的 ParallelCollectionRDD.slice(data, numSlices).toArray 是进行 具体的拆分
override def getPartitions: Array[Partition] = {
// data 代表集合 numSlices 代表分区数
val slices = ParallelCollectionRDD.slice(data, numSlices).toArray
slices.indices.map(i => new ParallelCollectionPartition(id, i, slices(i))).toArray
}
点进方法 ParallelCollectionRDD.slice ,看到具体的处理逻辑
def slice[T: ClassTag](seq: Seq[T], numSlices: Int): Seq[Seq[T]] = {
// 如果分区长度小于1抛出异常
if (numSlices < 1) {
throw new IllegalArgumentException("Positive number of partitions required")
}
def positions(length: Long, numSlices: Int): Iterator[(Int, Int)] = {
(0 until numSlices).iterator.map { i =>
val start = ((i * length) / numSlices).toInt
val end = (((i + 1) * length) / numSlices).toInt
(start, end)
}
}
// 匹配数据的类型
seq match {
// 如果是范围类型
case r: Range =>
positions(r.length, numSlices).zipWithIndex.map { case ((start, end), index) =>
// If the range is inclusive, use inclusive range for the last slice
if (r.isInclusive && index == numSlices - 1) {
new Range.Inclusive(r.start + start * r.step, r.end, r.step)
} else {
new Range.Inclusive(r.start + start * r.step, r.start + (end - 1) * r.step, r.step)
}
}.toSeq.asInstanceOf[Seq[Seq[T]]]
// 如果是范围类型
case nr: NumericRange[T] =>
// For ranges of Long, Double, BigInteger, etc
val slices = new ArrayBuffer[Seq[T]](numSlices)
var r = nr
for ((start, end) <- positions(nr.length, numSlices)) {
val sliceSize = end - start
slices += r.take(sliceSize).asInstanceOf[Seq[T]]
r = r.drop(sliceSize)
}
slices.toSeq
// 其他类型
case _ =>
val array = seq.toArray // To prevent O(n^2) operations for List etc
positions(array.length, numSlices).map { case (start, end) =>
array.slice(start, end).toSeq
}.toSeq
}
}
大致流程图
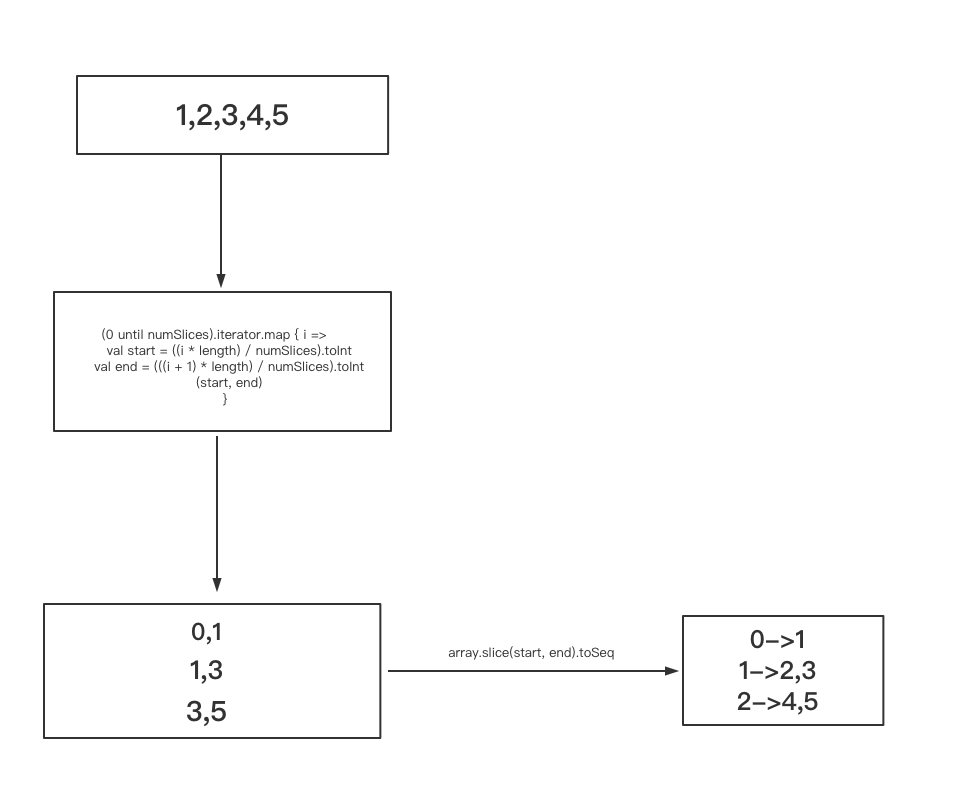
所以按照这个规则 分区1 存放的数据应该是 [1] ,分区2存放的数据应该是 [2,3],分区三存放的数据应该是[4,5]
文件分区规则
读取文件的时候也可以进行分区设定
文件内容
1
2
3
代码
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/30 下午4:56
* @qq 2315290571
* @Description ${description}
*/
object RDDPar {
def main(args: Array[String]): Unit = {
// 配置环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD_Par")
// 获取运行环境上下文
val sc = new SparkContext(sparkConf)
// 创建RDD
// 第二个参数是 最小分区数 源码中 走的是这个 math.min(defaultParallelism, 2) 方法 ,如果不写,则是在 defaultParallelism 和2 之间取最小值
// 分区规则走的时候hadoop的规则
// totalSize/goalSize totalSize代表的是 文件总字节数 goalSize 代表每个分区存放的字节 7/2=3
// 因为换行符占两个字节 那么应该是 7/3 =2...1 个分区 根据hadoop规则,余下的大小超过 百分之十 就需要开一个新的分区 最终会有三个分区
val rdd:RDD[String] = sc.textFile("data/1.txt",2)
// 将处理的数据保存成分区文件
rdd.saveAsTextFile("output")
sc.stop()
}
}
第二个参数是 最小分区数 源码中 走的是这个 math.min(defaultParallelism, 2) 方法 ,如果不写,则是在 defaultParallelism 和2 之间取最小值
分区规则走的时候hadoop的规则
totalSize/goalSize ,totalSize代表的是 文件总字节数 goalSize 代表每个分区存放的字节 7/2=3 因为换行符占两个字节 那么应该是 7/3 =2...1 个分区 根据hadoop规则,余下的大小超过 百分之十 就需要开一个新的分区 最终会有三个分区分区文件的内容规则如下
上面已经得出结论需要三个分区,那么对应的分区操作如下
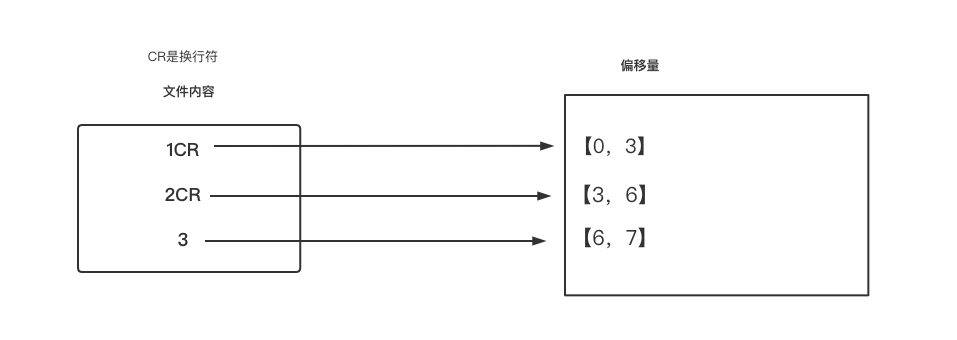
则第一个 分区放入 的应该是 【0,3】1CR2,也就是 1,2数据
第二个分区 放入的应该是【3,6】,因为hadoop不会重复读偏移量所以不会再从第三个读取了,直接读取 【6,7】了 也就是3
4.RDD转换算子
认知心理学认为解决问题其实是将问题的状态进行改变: 问题(初始)=》操作(opteraor)=》问题(审核中)=》操作=》问题(完成),所以称为RDD算子不是RDD方法。
RDD算子主要有两大类:转换算子(map,flatMap)和行动算子(collect)。
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/1 下午2:52
* @qq 2315290571
* @Description ${description}
*/
object OperatorTest {
def main(args: Array[String]): Unit = {
// 配置环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("operator")
// 配置运行环境
val sc = new SparkContext(sparkConf)
// 创建RDD
val rdd = sc.makeRDD(List(1, 2, 3, 4), 2)
// 使用mapPartitions 进行按分区进行 迭代操作
// mapPartitions 是将一个分区的数据都加载到内存
val rddValue = rdd.mapPartitions(
iter => {
println("-----------------")
iter.map(_ * 2)
}
)
rddValue.collect().foreach(println)
sc.stop()
}
}
glom
将同一个分区的数据直接转换为相同类型的内存数组进行处理,分区不变
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/4 上午10:25
* @qq 2315290571
* @Description ${description}
*/
object glomTest {
def main(args: Array[String]): Unit = {
// 创建spark 运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("glom")
val sc = new SparkContext(sparkConf)
// 使用 glom 计算所有分区最大值求和(分区内取最大值,分区间最大值求和)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4), 2)
val glomRDD: RDD[Array[Int]] = rdd.glom()
val resultRDD: RDD[Int] = glomRDD.map(
arr => {
arr.max
}
)
println(resultRDD.collect().sum)
}
}
groupBy
根据传入的key进行分组
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/4 下午3:50
* @qq 2315290571
* @Description ${description}
*/
object groupByTest {
def main(args: Array[String]): Unit = {
// 配置运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("groupBy")
// 获取运行环境
val sc = new SparkContext(sparkConf)
// 创建RDD
val sourceRDD: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
// 按照 自己的规则分组
val resultRDD: RDD[(Int, Iterable[Int])] = sourceRDD.groupBy(_ % 2)
// 打印查看
resultRDD.collect().foreach(println)
// 停止
sc.stop()
}
}
运行结果
(0,CompactBuffer(2, 4, 6))
(1,CompactBuffer(1, 3, 5))
coalesce
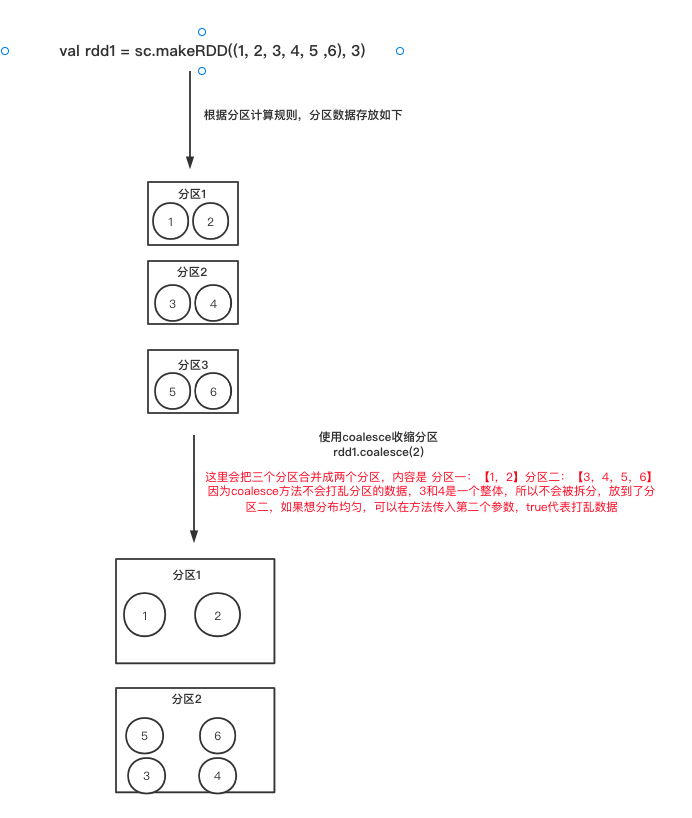
当 spark 程序中,存在过多的小任务的时候,可以通过 coalesce 方法,收缩合并分区,减少 分区的个数,减小任务调度成本
代码
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午4:07
* @qq 2315290571
* @Description ${description}
*/
object coalesceTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 3)
// 使用coalesce收缩分区
// 传入第二个参数 代表打乱数据再分区
rdd1.coalesce(2).saveAsTextFile("output")
sc.stop()
}
}
分区内容如下
part-00000:
1
2
part-00001:
3
4
5
6
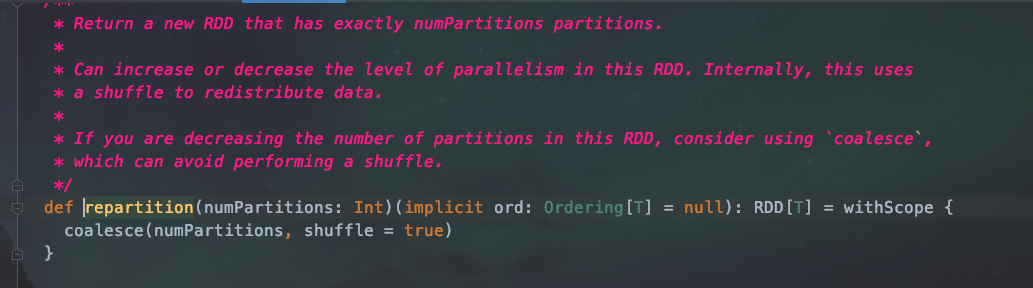
repartition
扩大分区使用repartition,其实底层调用了 coalesce方法
代码实现
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午4:52
* @qq 2315290571
* @Description ${description}
*/
object repartitionTest {
def main(args: Array[String]): Unit = {
// 创建运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("repartition")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
// 扩大分区
rdd.repartition(3).saveAsTextFile("output")
// 关闭
sc.stop()
}
}
分区内容如下(分区数据可能不一样,因为是被打乱的):
part-00000:
3
5
part-00001:
1
6
part-00002:
2
4
sample
sample 是用来抽样的一个算子
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午5:14
* @qq 2315290571
* @Description ${description}
*/
object sampleTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
// sample 是用来抽样的一个算子
// 参数一:抽取数据后是否将数据返回 true-放回 false-丢弃
// 参数二:数据源中每条数据被抽取的概率
// 参数三:种子 为1 则抽取的数固定,如果不传递 则使用的是当前系统时间
println(rdd1.sample(false, 0.4).collect().mkString(","))
}
}
distinct
将数据集中的数据去重
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午5:23
* @qq 2315290571
* @Description ${description}
*/
object distinctTest {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6, 1, 2, 3))
// 去重
// 底层采用了 map(x => (x, null)).reduceByKey((x, _) => x, numPartitions).map(_._1)
/*
(1,null)(2,null)(3,null)(4,null)(5,null)(6,null) (1,null)(2,null)(3,null)
||
|| reduceByKey
\ /
\/
(1,null) (1,null)=》 相同的value 做聚合(1,null)
*/
rdd1.distinct().collect().foreach(println)
}
}
sortBy
排序
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午5:05
* @qq 2315290571
* @Description ${description}
*/
object sortByTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(2, 1, 3, 4, 6, 5), 3)
// 注意:排序必须是同一种数据类型 默认升序,传入第二个参数就是降序
rdd1.sortBy(num => num).collect().foreach(println)
println("======================================")
// 关闭
sc.stop()
}
}
差集交集
intersection·:对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
union:取两个RDD的结果集
subtract:取差集
zip:键值对合并
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午6:16
* @qq 2315290571
* @Description ${description}
*/
object intersection {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6))
val rdd2 = sc.makeRDD(List(1, 5, 9, 8))
// intersection 算子 代表取交集 数据类型必须一致 否则编译不通过
println("intersection 算子:")
rdd1.intersection(rdd2).foreach(println)
// union 取联合结果
println("union 算子:")
rdd1.union(rdd2).foreach(println)
// subtract 算子 计算差集
println("subtract 算子:")
rdd1.subtract(rdd2).foreach(println)
// zip 算子 将rdd两个元素 以键值对形式进行合并 相同位置第一个rdd为key,第二个rdd为value
// 注: 两个rdd的数量 必须有相同 否则会报错 Can only zip RDDs with same number of elements in each partition
val rdd3 = sc.makeRDD(List(1, 2, 3, 4))
val rdd4 = sc.makeRDD(List(3, 4, 9, 8))
println("zip 算子:")
rdd3.zip(rdd4).foreach(println)
sc.stop()
}
}
运行结果
intersection 算子:
5
1
union 算子:
5
4
3
2
6
1
5
1
8
9
subtract 算子:
4
6
3
2
zip 算子:
(4,8)
(2,4)
(3,9)
(1,3)
partitionBy
重分区
package com.wl
import org.apache.spark.{HashPartitioner, SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午6:51
* @qq 2315290571
* @Description ${description}
*/
object partitionByTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(1, 2, 3, 4, 5, 6), 2)
// 映射
val mapRDD = rdd1.map((_, 1))
val newRDD = mapRDD.partitionBy(new HashPartitioner(2))
newRDD.saveAsTextFile("output")
sc.stop()
}
}
运行结果
part-00000:
(2,1)
(4,1)
(6,1)
part-00001:
(1,1)
(3,1)
(5,1)
reduceByKey
相同的key 做value的聚合
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/6 下午7:00
* @qq 2315290571
* @Description ${description}
*/
object reduceByKeyTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd = sc.makeRDD(List(("a",1),("b",2),("c",3),("a",4),("b",7)))
// 相同的key 做value的聚合
rdd.reduceByKey((x,y)=>x+y).collect().foreach(println)
// 停止
sc.stop()
}
}
groupByKey
根据key对value分组
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/7 上午10:06
* @qq 2315290571
* @Description ${description}
*/
object groupByKeyTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3), ("a", 2)))
rdd1.groupByKey().foreach(println)
// 停止
sc.stop()
}
}
运行结果
(b,CompactBuffer(2))
(a,CompactBuffer(1, 2))
(c,CompactBuffer(3))
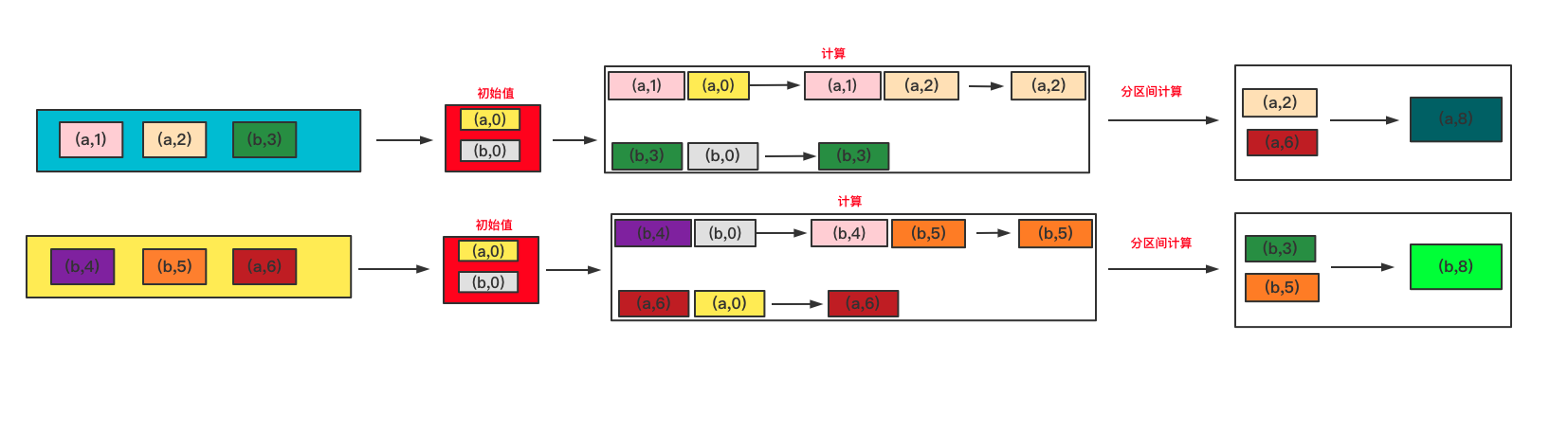
aggregateByKey
将数据根据不同的规则进行分区内计算和分区间计算
 代码如下
代码如下
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/7 下午2:29
* @qq 2315290571
* @Description ${description}
*/
object aggregateByKeyTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4 ),("b",5),("a",6)),2)
// 1.zeroValue 代表初始值
// 2.第二个参数列表:第一个参数代表分区内计算规则 第二个参数代表分区间计算规则
rdd1.aggregateByKey(0)(Math.max(_,_),_+_).foreach(println)
// 停止
sc.stop()
}
}
运行结果
(b,8)
(a,8)
foldByKey
当分区内计算规则和分区间计算规则相同时,aggregateByKey 就可以简化为 foldByKey
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/7 下午5:23
* @qq 2315290571
* @Description ${description}
*/
object foldByKeyTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(("a",1),("a",2),("b",3),("b",4 ),("b",5),("a",6)),2)
// 1.zeroValue 代表初始值
// 2.当计算规则相同
rdd1.foldByKey(0)(_+_).foreach(println)
// 停止
sc.stop()
}
}
运行结果
(b,12)
(a,9)
join
在类型为(K,V)和(K,W)的 RDD 上调用,返回一个相同 key 对应的所有元素连接在一起的
package com.wl
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/7 下午5:31
* @qq 2315290571
* @Description ${description}
*/
object joinTest {
def main(args: Array[String]): Unit = {
// 创建任务执行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("coalesce")
val sc = new SparkContext(sparkConf)
// 创建rdd
val rdd1 = sc.makeRDD(List(("a",1),("c",2),("b",3)))
val rdd2 = sc.makeRDD(List(("a",2),("c","c"),("b","b")))
rdd1.join(rdd2).collect().foreach(println)
// 关闭
sc.stop()
}
}
运行结果
(a,(1,2))
(b,(3,b))
(c,(2,c)
案例实操
统计出每一个省份每个广告被点击数量排行的 Top3
agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。
package com.wl
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/11 上午10:22
* @qq 2315290571
* @Description 需求:统计出每一个省份每个广告被点击数量排行的 Top3
*/
object SampleTest {
def main(args: Array[String]): Unit = {
// 获取运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("test")
val sc = new SparkContext(sparkConf)
// 获取原始数据 : 时间戳、省份、城市、用户、广告
val fileRDD = sc.textFile("/Users/wangliang/Documents/ideaProject/Spark/spark-core/src/main/resources/agent.log")
// map映射 =》((省份,广告),1)
val mapRDD = fileRDD.map(
data => {
val line = data.split(" ")
((line(1), line(4)), 1)
}
)
// 相同的key 做 value 相加聚合
val reduceRDD: RDD[((String, String), Int)] = mapRDD.reduceByKey(_ + _)
// 将聚合的结果 进行结构的转换 (省份,(广告,sum))
val newRDD = reduceRDD.map {
case ((prv, ad), sum) => {
(prv, (ad, sum))
}
}
// 根据省份进行分组
val groupByKeyRDD: RDD[(String, Iterable[(String, Int)])] = newRDD.groupByKey()
// 将分组后的数据组内排序(降序),取前三名
val sortRDD: RDD[(String, List[(String, Int)])] = groupByKeyRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(3)
}
)
// 采集数据
sortRDD.collect().foreach(println)
sc.stop()
}
}
运行结果
(4,List((12,25), (2,22), (16,22)))
(8,List((2,27), (20,23), (11,22)))
(6,List((16,23), (24,21), (22,20)))
(0,List((2,29), (24,25), (26,24)))
(2,List((6,24), (21,23), (29,20)))
(7,List((16,26), (26,25), (1,23)))
(5,List((14,26), (21,21), (12,21)))
(9,List((1,31), (28,21), (0,20)))
(3,List((14,28), (28,27), (22,25)))
(1,List((3,25), (6,23), (5,22)))
5.SparkSql
sparkSql主要依赖于两种数据结构 DataFrame和DataSet
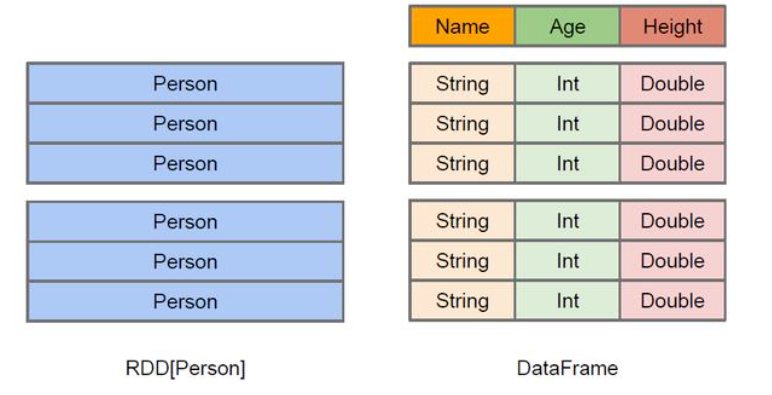
什么是DataFrame?
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中 的二维表格,DataFrame携带者二维表数据的名称和类型。
创建 DataFrame
在 Spark SQL 中 SparkSession 是创建 DataFrame 和执行 SQL 的入口,创建 DataFrame
有三种方式:通过 Spark 的数据源进行创建;从一个存在的 RDD 进行转换;还可以从 Hive Table 进行查询返回。
sql语法
查看支持的数据源格式
spark.read.

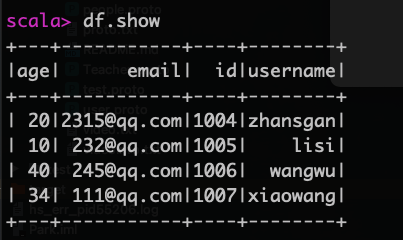
准备info.json文件
{"id":1004,"username":"zhansgan","email":"2315@qq.com","age":20}
{"id":1005,"username":"lisi","email":"232@qq.com","age":10}
{"id":1006,"username":"wangwu","email":"245@qq.com","age":40}
{"id":1007,"username":"xiaowang","email":"111@qq.com","age":34}
读取json文件
val df=spark.read.json("info.json")
展示结果
df.show
创建Session会话内的临时视图
df.createOrReplaceTempView("user")
使用sql查询结果
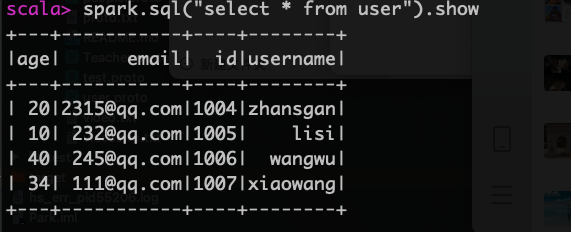
spark.sql("select * from user").show
创建全局视图
df.createOrReplaceGlobalTempView("user")
如果报jdbc的错误 将mysql连接驱动放入的 jars目录下
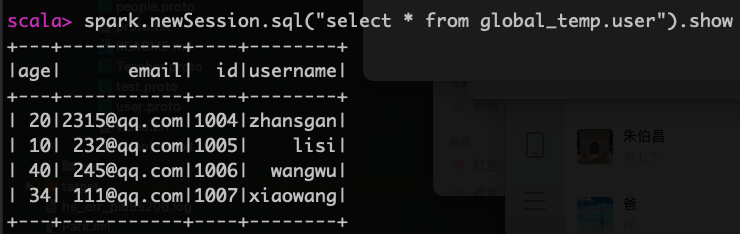
查询临时视图结果
spark.newSession.sql("select * from global_temp.user").show
dsl语法
使用dsl语法就不必去创建临时视图了
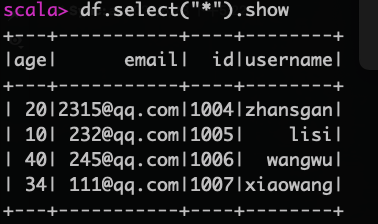
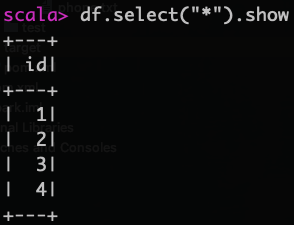
引用上面的df,然后查询
df.select("*").show
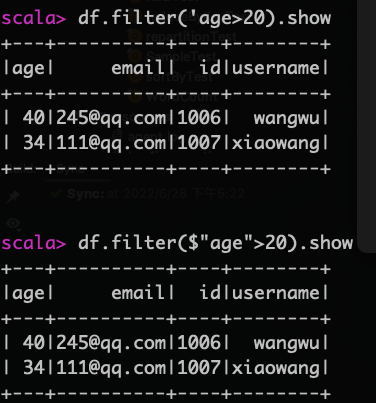
查询年龄大于20的用户信息,使用 '或者$符表示引用字段
df.filter('age>20).show
df.filter($"age">20).show
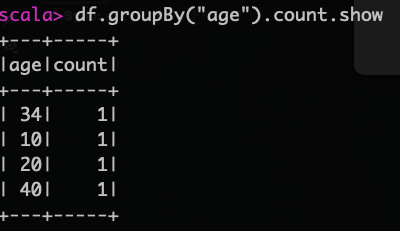
按年龄分组查看每组的记录数
df.groupBy("age").count.show
rdd转换为DataFrame
首先创建一个rdd
val rdd=sc.makeRDD(List(1,2,3,4))
使用toDF方法将rdd转换成DataFrame
val df=rdd.toDF("id")
查看df内容
df.select("*").show
DataFrame转换为rdd
使用rdd方法将其转换为 rdd
val r=df.rdd
r.collect()

什么是DataSet?
在jdbc中我们使用 ResultSet来获取查询内容,使用 其中的 getInt()和getString()来获取对应的列值,但是这种不太方便使用,DataSet是对其的改进,是一个批处理的数据集。DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
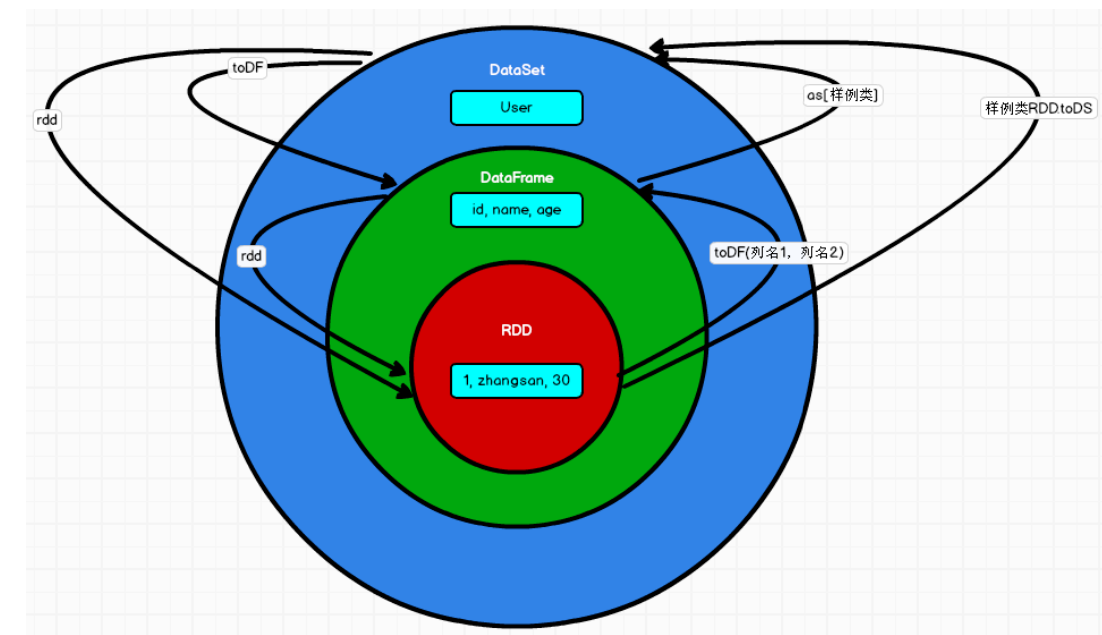
三者的关系
rdd转换成DataSet
创建一个样例类
case class student(id:Long,name:String)
创建样例类型的rdd
val rdd1=sc.makeRDD(List(student(1003,"张三"),student(1005,"李四")))
将rdd转换成DataSet
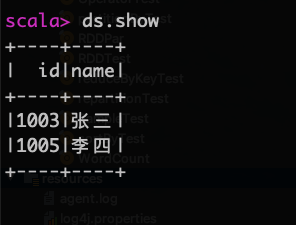
val ds=rdd1.toDS
查看查询结果
ds.show
DataSet转换成rdd
使用rdd方法将DataSet转换成rdd
val rdd4=ds.rdd

DataFrame转换成DataSet
创建样例类
case class User(id:Long,name:String)
创建DataFrame
val df = sc.makeRDD(List(User(1000,"小李"),User(2000120,"小张"))).toDF("id","name")
将DataFrame转换成DataSet
val ds =df.as[User]
DataSet转换成DataFrame
使用ds.toDF将DataSet转换成DataFrame
ds.toDF
idea中使用SparkSql
在maven中加入spark-sql的依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
student.txt
{"username":"qwer","password":"1232443"}
{"username":"rrta","password":"d123ddf"}
{"username":"rggu","password":"dhjrfdf"}
具体代码
package com.wl.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/12 上午10:36
* @qq 2315290571
* @Description SparkSql
*/
object SqlTest {
def main(args: Array[String]): Unit = {
// 创建运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSql")
// 创建SparkSession对象
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//RDD=>DataFrame=>DataSet 转换需要引入隐式转换规则,否则无法转换
//spark 不是包名,是上下文环境对象名
import spark.implicits._
// 读取json文件 创建df
val df = spark.read.json("/Users/wangliang/Documents/ideaProject/Spark/spark-sql/src/main/resources/student.txt")
// 查看内容
df.show
// sql风格查询
df.createOrReplaceTempView("user")
spark.sql("select username from user where password like '%12%' ").show
// dsl风格
df.select("username").filter('password like "%12%").show
spark.stop()
}
}
用户自定义函数
用户自定义函数
使用 spark.udf可以添加自定义函数
package com.wl.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/12 上午11:05
* @qq 2315290571
* @Description ${description}
*/
object UdfTest {
def main(args: Array[String]): Unit = {
// 创建运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSql")
// 创建SparkSession对象
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
//RDD=>DataFrame=>DataSet 转换需要引入隐式转换规则,否则无法转换
//spark 不是包名,是上下文环境对象名
import spark.implicits._
// 读取json文件 创建df
val df = spark.read.json("/Users/wangliang/Documents/ideaProject/Spark/spark-sql/src/main/resources/student.txt")
// 创建自定义函数
spark.udf.register("replaceStr",(x:String)=>x.replaceAll("1","*"))
// 创建临时表
df.createOrReplaceTempView("student")
// 应用自定义函数
spark.sql("select username,replaceStr(password) as password from student").show
spark.stop()
}
}
运行结果
+--------+--------+
|username|password|
+--------+--------+
| qwer| *232443|
| rrta| d*23ddf|
| rggu| dhjrfdf|
+--------+--------+
用户自定义聚合函数
使用Aggregator 累加器实现 求平均值
package com.wl.sparksql
import org.apache.spark.SparkConf
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import org.apache.spark.sql.expressions.Aggregator
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/12 下午1:54
* @qq 2315290571
* @Description ${description}
*/
object AvgSalaryTest_Aggregator {
def main(args: Array[String]): Unit = {
// 创建运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Aggregator")
val spark = SparkSession.builder().config(sparkConf).getOrCreate()
// 创建DataFrame
val df = spark.read.json("/Users/wangliang/Documents/ideaProject/Spark/spark-sql/src/main/resources/teacher.txt")
// 创建临时视图
df.createOrReplaceTempView("teacher")
// 注册自定义函数
spark.udf.register("ageAvg", functions.udaf(new MyAverageUDFA()))
// 查询
spark.sql("select ageAvg(age) as avgAge from teacher").show
// 关闭
spark.stop
}
}
case class Buff(var total: Long, var count: Long)
/**
* IN 代表输入值的类型
* BUF 代表缓冲区的类型
* OUT 代表输出值得类型
*/
class MyAverageUDFA extends Aggregator[Long, Buff, Long] {
// 初始值
override def zero: Buff = {
Buff(0L, 0L)
}
// 计算逻辑
override def reduce(buff: Buff, a: Long): Buff = {
buff.total = buff.total + a
buff.count = buff.count + 1
buff
}
// 合并缓冲区
override def merge(buff1: Buff, buff2: Buff): Buff = {
buff1.total = buff1.total + buff2.total
buff1.count = buff1.count + buff2.count
buff1
}
// 完成
override def finish(reduction: Buff): Long = {
reduction.total / reduction.count
}
// 缓冲区的编码操作
override def bufferEncoder: Encoder[Buff] = Encoders.product
// 输出的编码操作
override def outputEncoder: Encoder[Long] = Encoders.scalaLong
}
运行结果
+------+
|avgAge|
+------+
| 26|
+------+
数据的读取和保存
读取
使用spark.read.load默认读取是parquet文件
spark.read.load("/Users/wangliang/Documents/ideaProject/Flink/data/date=2022-07-12/hour=16/part-0-4.parquet").show
运行结果
+-------+---------+----------+---------+
|orderId|orderName|orderPrice|timestamp|
+-------+---------+----------+---------+
| 1008|payment03| 234.0|122132112|
| 1009|payment04| 1231.0|213234234|
| 1108|payment05| 45353.0| 56675757|
| 1923|payment06| 1344.0| 2353453|
| 1223|payment07| 143545.0| 668893|
+-------+---------+----------+---------+
也可以指定格式,比如csv
spark.read.format("csv").option("sep",",").option("inferSchema","true").option("header","false").load("LoginLog.csv")
或
spark.read.options(Map("delimiter"->";", "header"->"true")).csv(path)
- header 代表是否有表头
- sep代表分隔符
不用创建临时视图,可以直接在json文件中查询
spark.sql("select * from json.`info.json`")
读取mysql中的数据,需要加入mysql连接驱动
命令行的方式读取
spark.read.format("jdbc").option("url","jdbc:mysql://localhost:3306/test_mysql").option("driver","com.mysql.cj.jdbc.Driver").option("user","root").option("password","wl990922").option("dbtable", "device_info").load().show
代码读取
package com.wl
import java.util.Properties
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/13 上午11:27
* @qq 2315290571
* @Description ${description}
*/
object TestRead {
def main(args: Array[String]): Unit = {
// 创建运行环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("readTest")
val spark = SparkSession.builder().config(sparkConf).getOrCreate();
// 方式一:通过load的方式读取
spark.read.format("jdbc")
.option("url", "jdbc:mysql://localhost:3306/test_mysql")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "wl990922")
.option("dbtable", "device_info").load().show
// 方式二:通过load的另一种参数
spark.read.format("jdbc")
.options(Map("url"->"jdbc:mysql://localhost:3306/test_mysql?user=root&password=wl990922", "dbtable"->"device_info","driver"->"com.mysql.cj.jdbc.Driver"))
.load().show
// 方式三:通过jdbc方法读取
val pro = new Properties()
pro.setProperty("user","root")
pro.setProperty("password","wl990922")
spark.read.jdbc("jdbc:mysql://localhost:3306/test_mysql","device_info",pro).show
spark.stop()
}
}
读取Hive
操作hive分别是以下几个步骤
➢ Spark要接管Hive需要把hive-site.xml拷贝到conf/目录下
➢ 把Mysql的驱动copy到jars/目录下
➢ 如果访问不到hdfs,则需要把core-site.xml和hdfs-site.xml拷贝到conf/目录下
➢ 重启spark-shell
使用命令行查看hive表格
spark.sql("show tables").show
结果
+--------+----------+-----------+
|database| tableName|isTemporary|
+--------+----------+-----------+
| default| aa_test| false|
| default| bucket| false|
| default| day01| false|
| default| day02| false|
| default| day03| false|
| default| dep| false|
| default|department| false|
| default|load2_test| false|
| default|load3_test| false|
| default|load4_test| false|
| default| load_test| false|
| default| stu| false|
| default| stu2| false|
| default| student| false|
| default| test| false|
| default| user_info| false|
+--------+----------+-----------+
查询其中的一个表
spark.sql("select * from day01").show
结果
| id| name| address| day|
+----+------+----------+--------------------+
|1001|胡图图| 翻斗花园| 2021-12-30|
|1002|胡英俊| 翻斗花园| 2021-12-30|
|1003|牛爷爷| 翻斗花园| 2021-12-30|
|1001|胡图图| 翻斗花园| 2021-12-28|
|1002|胡英俊| 翻斗花园| 2021-12-28|
|1003|牛爷爷| 翻斗花园| 2021-12-28|
|1001|胡图图| 翻斗花园| 2021-12-27|
|1002|胡英俊| 翻斗花园| 2021-12-27|
|1003|牛爷爷| 翻斗花园| 2021-12-27|
|1001|胡图图| 翻斗花园|__HIVE_DEFAULT_PA...|
|1002|胡英俊| 翻斗花园|__HIVE_DEFAULT_PA...|
|1003|牛爷爷| 翻斗花园|__HIVE_DEFAULT_PA...|
|1111| 张三| 北京市| 2021-12-26|
|2222| 李四| 北京市| 2021-12-26|
|3333| 王五| 北京市| 2021-12-26|
|0001|测试01|测试地址01| 2021-12-25|
|0002|测试02|测试地址02| 2021-12-25|
|0003|测试03|测试地址03| 2021-12-25|
|1001|胡图图| 翻斗花园| 2021-12-29|
|1002|胡英俊| 翻斗花园| 2021-12-29|
+----+------+----------+--------------------+
only showing top 20 rows
补充:如果读取嵌套文件,需要在父级目录下 加上 * 模糊匹配
spark.read.json("data/*").show
如果不加会报以下错误
org.apache.spark.sql.AnalysisException: Unable to infer schema for JSON. It must be specified manually.
想要指定schema如下
// 创建 schema
val schema = (new StructType)
.add("address", StringType)
.add("ip", StringType)
// 读取
spark.read.schema(schema).json("/Users/wangliang/Documents/ideaProject/Testaa/data/*").show
写入数据
当加入了hive以后,都会默认找 hdfs上的文件,所以读取文件时候需要指定file,如下
val df = spark.read.json("file:/Users/info.json")
然后我们将数据写入本地,spark有四种写入规则:
➢ mode("eroor"):如果文件已经存在则抛出异常(spark默认使用这个)
➢ mode("append"):如果文件已经存在则追加
➢ mode("overwrite"):如果文件已经存在则覆盖
➢ mode("ignore"):如果文件已经存在则忽略
➢ coalesce(2):写出几个分区
oas.coalesce(2).write.mode("append").csv("/Users/wangliang/Desktop/test")
hive的写入,代码操作
加入依赖
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
将 hive-site.xml文件拷贝到项目的resources目录中
注意:在开发工具中创建数据库默认是在本地仓库,通过参数修改数据库仓库的地址: config("spark.sql.warehouse.dir", "hdfs://linux1:8020/user/hive/warehouse")
package com.wl.sparksql
import org.apache.spark.sql.SparkSession
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/13 下午4:13
* @qq 2315290571
* @Description ${description}
*/
object HiveTest {
def main(args: Array[String]): Unit = {
// 创建运行环境
val spark = SparkSession.builder().enableHiveSupport().master("local[*]").appName("hiveTest").getOrCreate()
spark.sql("show tables").show
spark.sql("select * from dep").show
spark.sql("insert into dep values(1004,'科技公司','北京市')")
spark.sql("select * from dep").show
spark.stop()
}
}
案例操作
首先往 hive表中创建以下三个表并导入数据
CREATE TABLE `user_visit_action`(
`date` string,
`user_id` bigint,
`session_id` string,
`page_id` bigint, `action_time` string, `search_keyword` string, `click_category_id` bigint, `click_product_id` bigint, `order_category_ids` string, `order_product_ids` string, `pay_category_ids` string, `pay_product_ids` string, `city_id` bigint)
row format delimited fields terminated by '\t';
load data local inpath '/home/wl/data/user_visit_action.txt' into table user_visit_action;
CREATE TABLE `product_info`(
`product_id` bigint,
`product_name` string,
`extend_info` string)
row format delimited fields terminated by '\t';
load data local inpath '/home/wl/data/product_info.txt' into table product_info;
CREATE TABLE `city_info`(
`city_id` bigint,
`city_name` string,
`area` string)
row format delimited fields terminated by '\t';
load data local inpath '/home/wl/data/city_info.txt' into table city_info;
需求:计算各个区域前三大热门商品,并备注上每 个商品在主要城市中的分布比例,超过两个城市用其他显示。
sql分析:
- 1.首先三表关联查询,查询出 是点击事件的 商品名称、地区、城市
- 2.然后查询 地区、商品名称、点击数 并分组
- 3.排序取前三条数据
SELECT
*
FROM
(
SELECT
*,
rank() over ( PARTITION BY area ORDER BY clikCount DESC ) AS rank
FROM
(
SELECT
area,
product_name,
count(*) AS clikCount,
cityRemark(city_name) as city_remark
FROM
(
SELECT
a.*,
b.product_name,
c.area,
c.city_name
FROM
user_visit_action a
LEFT JOIN product_info b ON a.click_product_id = b.product_id
LEFT JOIN city_info c ON a.city_id = c.city_id
WHERE
a.click_product_id > 1
) t1
GROUP BY
area,
product_name
) t2
) t3
WHERE
rank <=3
代码具体实现
package com.wl.sparksql
import org.apache.spark.sql.expressions.Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession, functions}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/7/13 下午6:51
* @qq 2315290571
* @Description sparkSqlTest
*/
object SparkSqlTest {
def main(args: Array[String]): Unit = {
// 创建spark运行环境
val spark = SparkSession.builder().enableHiveSupport().master("local[*]").appName("sparkSqlTest").getOrCreate()
spark.udf.register("cityRemark", functions.udaf(new CityRemark()))
// 运行sql
spark.sql(
"""
|SELECT
| *
|FROM
| (
| SELECT
| *,
| rank() over ( PARTITION BY area ORDER BY clikCount DESC ) AS rank
| FROM
| (
| SELECT
| area,
| product_name,
| count(*) AS clikCount,
| cityRemark(city_name) as city_remark
| FROM
| (
| SELECT
| a.*,
| b.product_name,
| c.area,
| c.city_name
| FROM
| user_visit_action a
| LEFT JOIN product_info b ON a.click_product_id = b.product_id
| LEFT JOIN city_info c ON a.city_id = c.city_id
| WHERE
| a.click_product_id > 1
| ) t1
| GROUP BY
| area,
| product_name
| ) t2
| ) t3
|WHERE
| rank <=3
|
|
|""".stripMargin).show
}
}
case class City(var total: Long, var cityMap: mutable.Map[String, Long])
class CityRemark extends Aggregator[String, City, String] {
// 初始值
override def zero: City = {
City(0, new mutable.HashMap[String,Long]())
}
// 计算逻辑
override def reduce(buff: City, cityName: String): City = {
buff.total += 1
var newCount = buff.cityMap.getOrElse(cityName, 0L) + 1
buff.cityMap.update(cityName, newCount)
buff
}
// 合并
override def merge(buff1: City, buff2: City): City = {
// 合并总数
buff1.total+=buff2.total
var map1 = buff1.cityMap
var map2 = buff2.cityMap
// 合并 cityMap
buff1.cityMap = map1.foldLeft(map2) {
case (map, (city, cnt)) => {
var newCount = map.getOrElse(city, 0L) + cnt
map.update(city, newCount)
map
}
}
buff1
}
override def finish(buff: City): String = {
val remarkList = ListBuffer[String]()
val totalCount = buff.total
val cityMap = buff.cityMap
// 排序 cityMap
val cityCntList = cityMap.toList.sortWith(
(left, right) => {
left._2 > right._2
}
).take(2)
val hasMore = cityMap.size > 2
var rsum = 0L
// 赋值
cityCntList.foreach {
case (city, cnt) => {
println(cnt)
val r = cnt * 100 / totalCount
remarkList.append(s"${city} ${r}%")
rsum += r
}
}
// 其他赋值
if (hasMore) {
remarkList.append(s"其他 ${100 - rsum}%")
}
remarkList.mkString(",")
}
override def bufferEncoder: Encoder[City] = Encoders.product
override def outputEncoder: Encoder[String] = Encoders.STRING
}
运行结果
+----+------------+---------+-------------------------+----+
|area|product_name|clikCount| city_remark|rank|
+----+------------+---------+-------------------------+----+
|华东| 商品_86| 371|上海 16%,杭州 15%,其...| 1|
|华东| 商品_47| 366|杭州 15%,青岛 15%,其...| 2|
|华东| 商品_75| 366|上海 17%,无锡 15%,其...| 2|
|西北| 商品_15| 116| 西安 54%,银川 45%| 1|
|西北| 商品_2| 114| 银川 53%,西安 46%| 2|
|西北| 商品_22| 113| 西安 54%,银川 45%| 3|
|华南| 商品_23| 224|厦门 29%,福州 24%,其...| 1|
|华南| 商品_65| 222|深圳 27%,厦门 26%,其...| 2|
|华南| 商品_50| 212|福州 27%,深圳 25%,其...| 3|
|华北| 商品_42| 264|郑州 25%,保定 25%,其...| 1|
|华北| 商品_99| 264|北京 24%,郑州 23%,其...| 1|
|华北| 商品_19| 260|郑州 23%,保定 20%,其...| 3|
|东北| 商品_41| 169|哈尔滨 35%,大连 34%,...| 1|
|东北| 商品_91| 165|哈尔滨 35%,大连 32%,...| 2|
|东北| 商品_58| 159|沈阳 37%,大连 32%,其...| 3|
|东北| 商品_93| 159|哈尔滨 38%,大连 37%,...| 3|
|华中| 商品_62| 117| 武汉 51%,长沙 48%| 1|
|华中| 商品_4| 113| 长沙 53%,武汉 46%| 2|
|华中| 商品_57| 111| 武汉 54%,长沙 45%| 3|
|华中| 商品_29| 111| 武汉 50%,长沙 49%| 3|
+----+------------+---------+-------------------------+----+

 浙公网安备 33010602011771号
浙公网安备 33010602011771号