Flink
1.WordCount入门程序
创建一个maven项目,依赖如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>Flink</artifactId>
<groupId>com.oasisgames</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<encoding>UTF-8</encoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.13.6</flink.version>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<modelVersion>4.0.0</modelVersion>
<dependencies>
<!--Flink-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<!-- <version>1.10.1</version>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--Flink-clients-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--filesystem-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_${scala.binary.version}</artifactId>
<version>1.11.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/cn.hutool/hutool-all -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.0.5</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.parquet/parquet-avro -->
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.11.2</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.78</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.projectlombok/lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.16.6</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/com.drewnoakes/metadata-extractor -->
<dependency>
<groupId>com.drewnoakes</groupId>
<artifactId>metadata-extractor</artifactId>
<version>2.16.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-files -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Table API 和 Flink SQL -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
</dependency>
<!--动态代理 的包-->
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.1</version>
</dependency>
<dependency>
<groupId>com.google.collections</groupId>
<artifactId>google-collections</artifactId>
<version>1.0</version>
</dependency>
<!--json扁平化-->
<dependency>
<groupId>com.github.wnameless.json</groupId>
<artifactId>json-flattener</artifactId>
<version>0.8.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-jdbc -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_2.11</artifactId>
<version>1.13.6</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.16</version>
</dependency>
</dependencies>
<artifactId>FlinkTutorial</artifactId>
</project>
批处理WordCount
package com.wl;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/25 下午5:14
* @qq 2315290571
* @Description 批处理统计单词出现的次数
*/
public class WordCount {
public static void main(String[] args) throws Exception {
//创建批处理执行环境
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 读取文件
DataSource<String> input = environment.readTextFile("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/word.txt");
// 分组并求和
DataSet<Tuple2<String, Integer>> result = input.flatMap(new MyFlatMapper()).groupBy(0).sum(1);
result.print();
}
public static class MyFlatMapper implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// 按空格分组
String[] words = value.split(" ");
for (String word : words) {
// 将数据进行整合
out.collect(new Tuple2<>(word, 1));
}
}
}
}
word.txt
hello kotlin
hello java
hello spark
hello hadoop
hello flink
hello python
who are you
流式文件处理(配合kafka)
package com.wl;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/25 下午5:58
* @qq 2315290571
* @Description 流式处理文件
*/
public class WordCountStream {
public static void main(String[] args) throws Exception {
// 创建流处理运行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取流
Properties properties = new Properties();
properties.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.160.2:9092");
properties.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-topic");
DataStream<String> dataStream = environment.addSource(new FlinkKafkaConsumer<String>("test-topic", new SimpleStringSchema(), properties));
// 打散成单词并分组求和
DataStream<Tuple2<String, Integer>> result = dataStream.flatMap(new WordCount.MyFlatMapper())
.keyBy(0)
.sum(1);
// 打印
result.print();
environment.execute("com.wl.WorldCount");
}
}
再启动kafka,发送消息
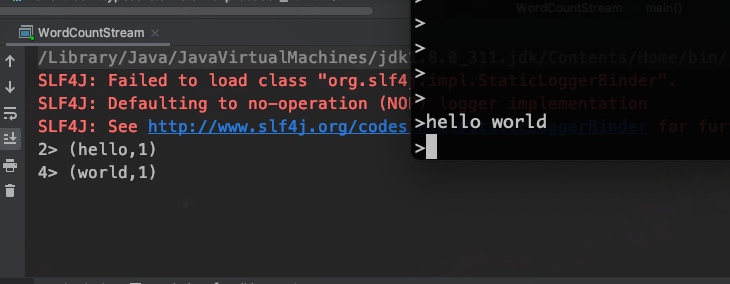
2.Flink安装和部署
StandaLone模式
安装启动
下载Flink
wget https://archive.apache.org/dist/flink/flink-1.10.1/flink-1.10.1-bin-scala_2.11.tgz
下载flink-hadoop插件
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.7.5-10.0/flink-shaded-hadoop-2-uber-2.7.5-10.0.jar
conf文件说明:
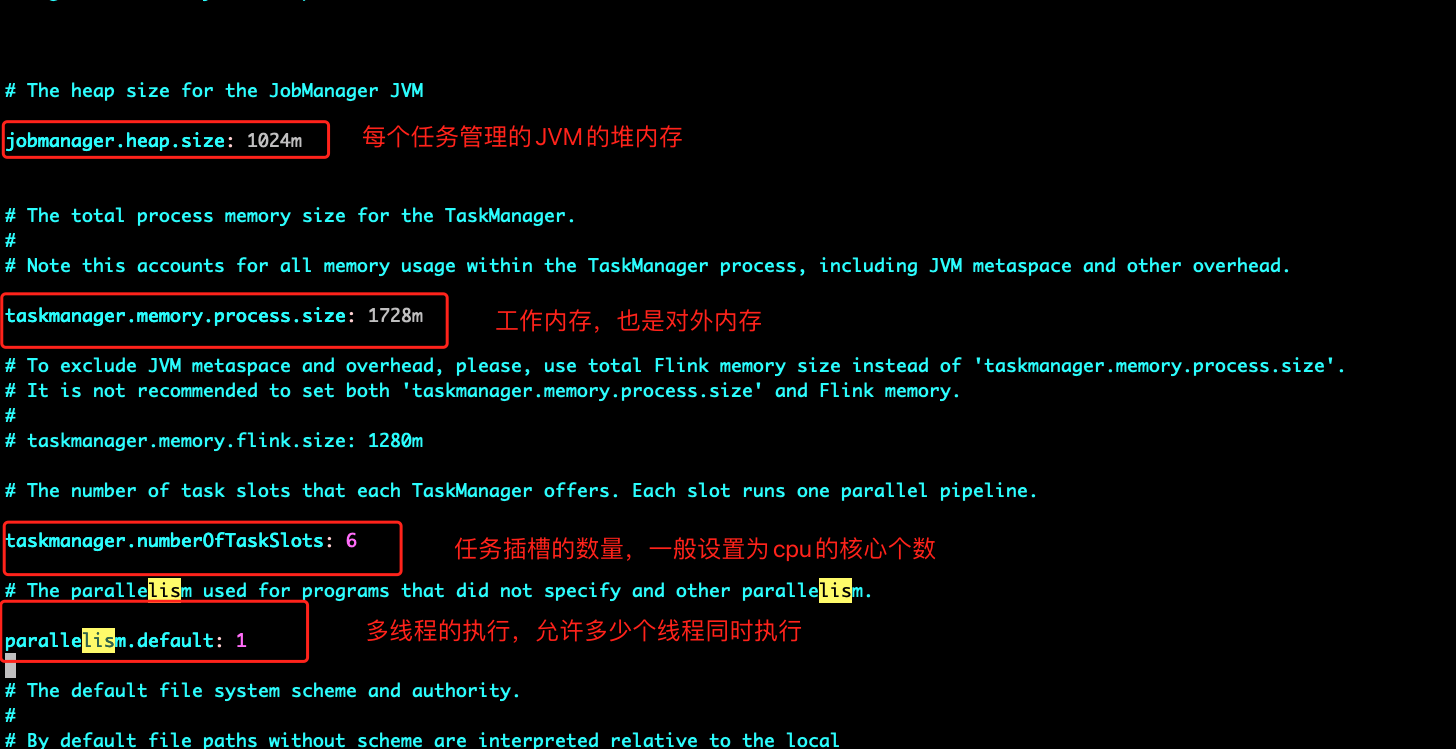
启动Flink
bin/start-cluster.sh
可以看到flink的默认web端口是8081
访问 8081端口得到web界面
将写的java程序打成jar包在 Submit New Job 按钮中添加
然后点击jar包,输入以下内容
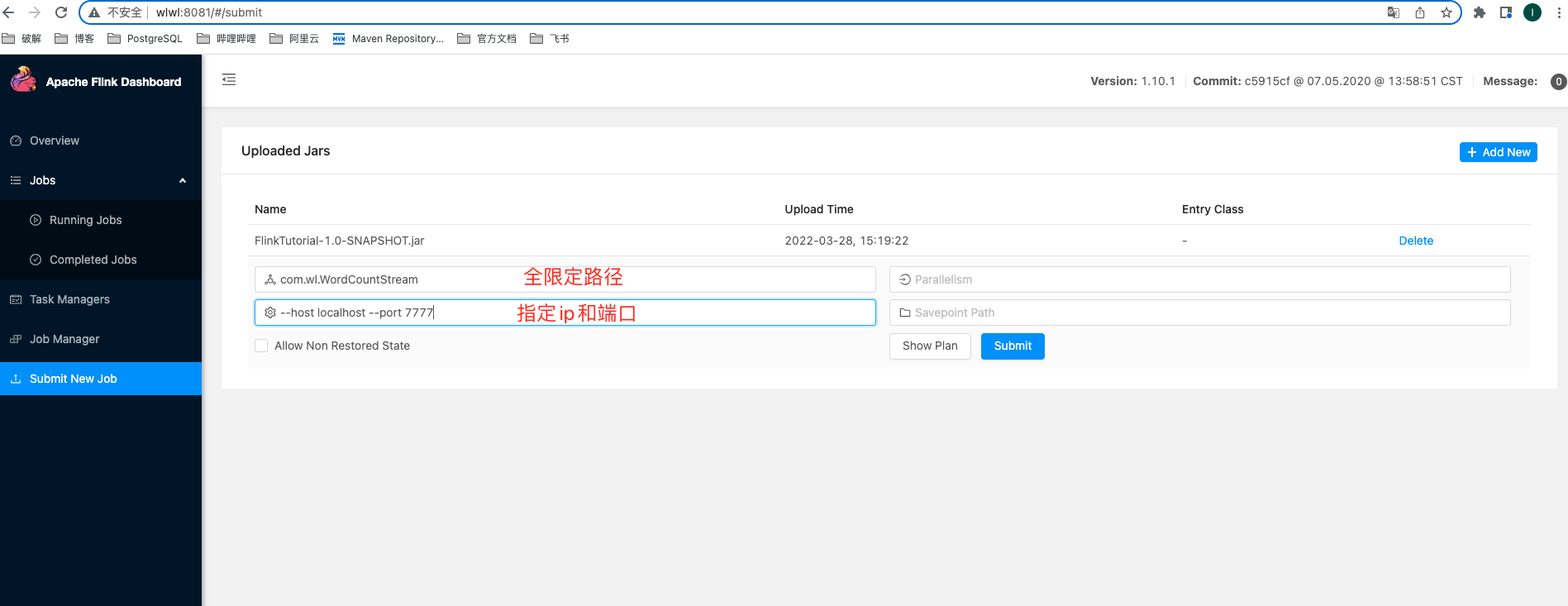
再点击Submit
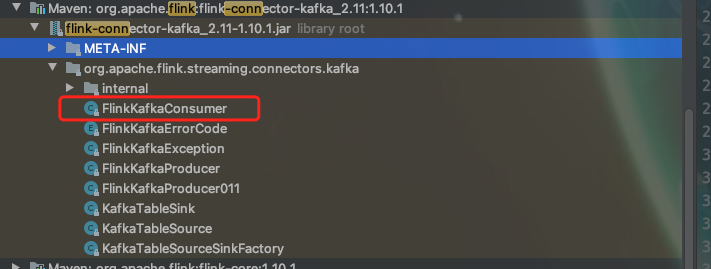
如果出现以下错误:
Caused by: java.lang.ClassNotFoundException:
org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
在 服务器上lib 目录下添加 FlinkKafkaConsumer所对应的jar包

然后运行Flink集群,出现了新的错误
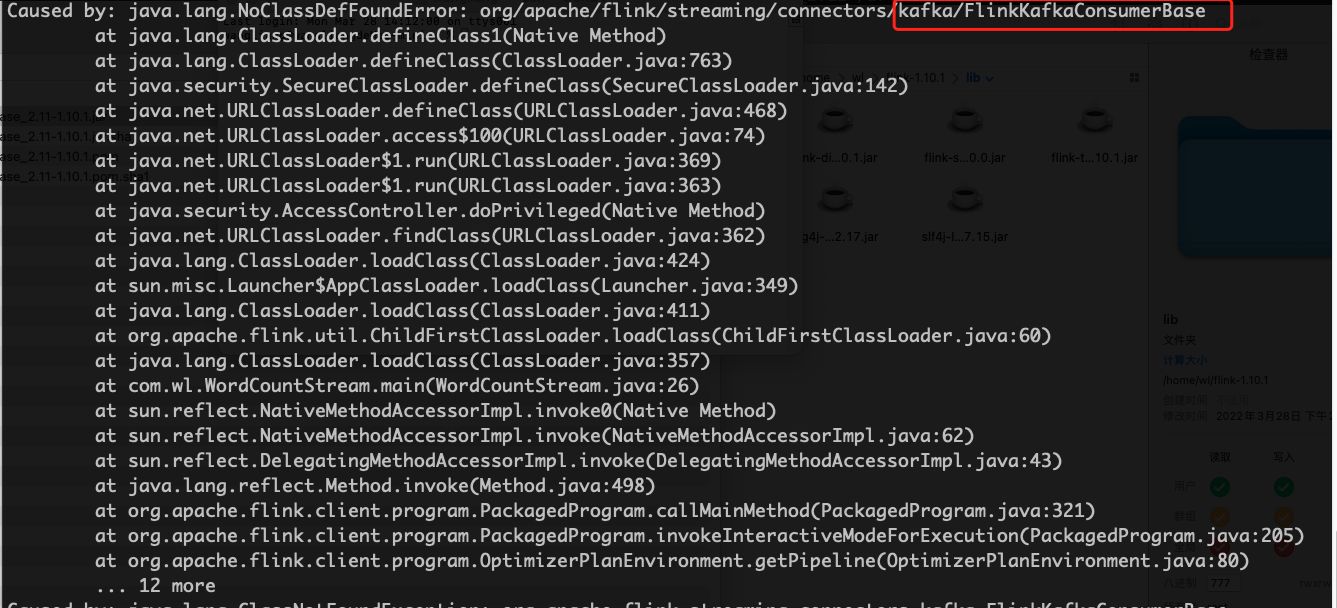
解决方法就是 将kafka-base的jar包上传到服务器上

再运行又报了个新错误 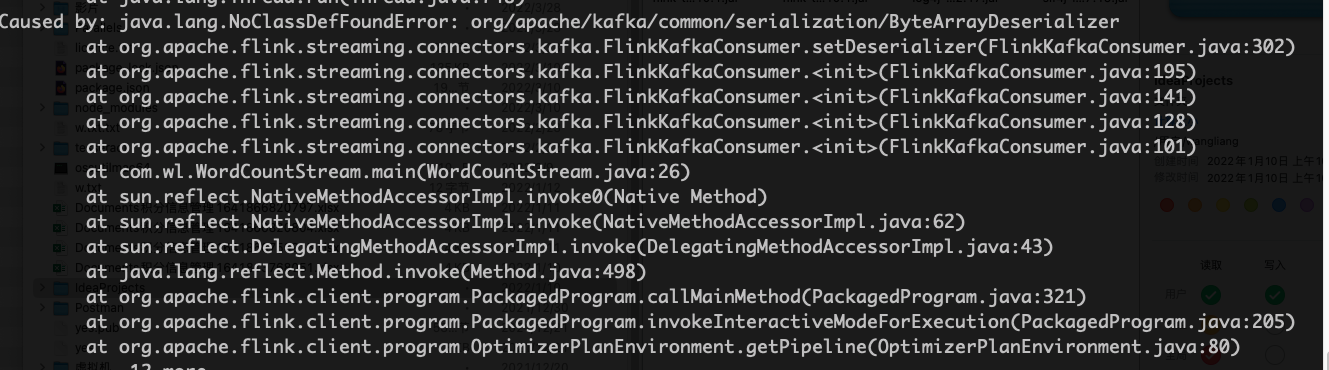
解决方法就是将 kafka-clients的jar加入到服务器的Flink的lib目录下


web页面提交任务
Submit New Job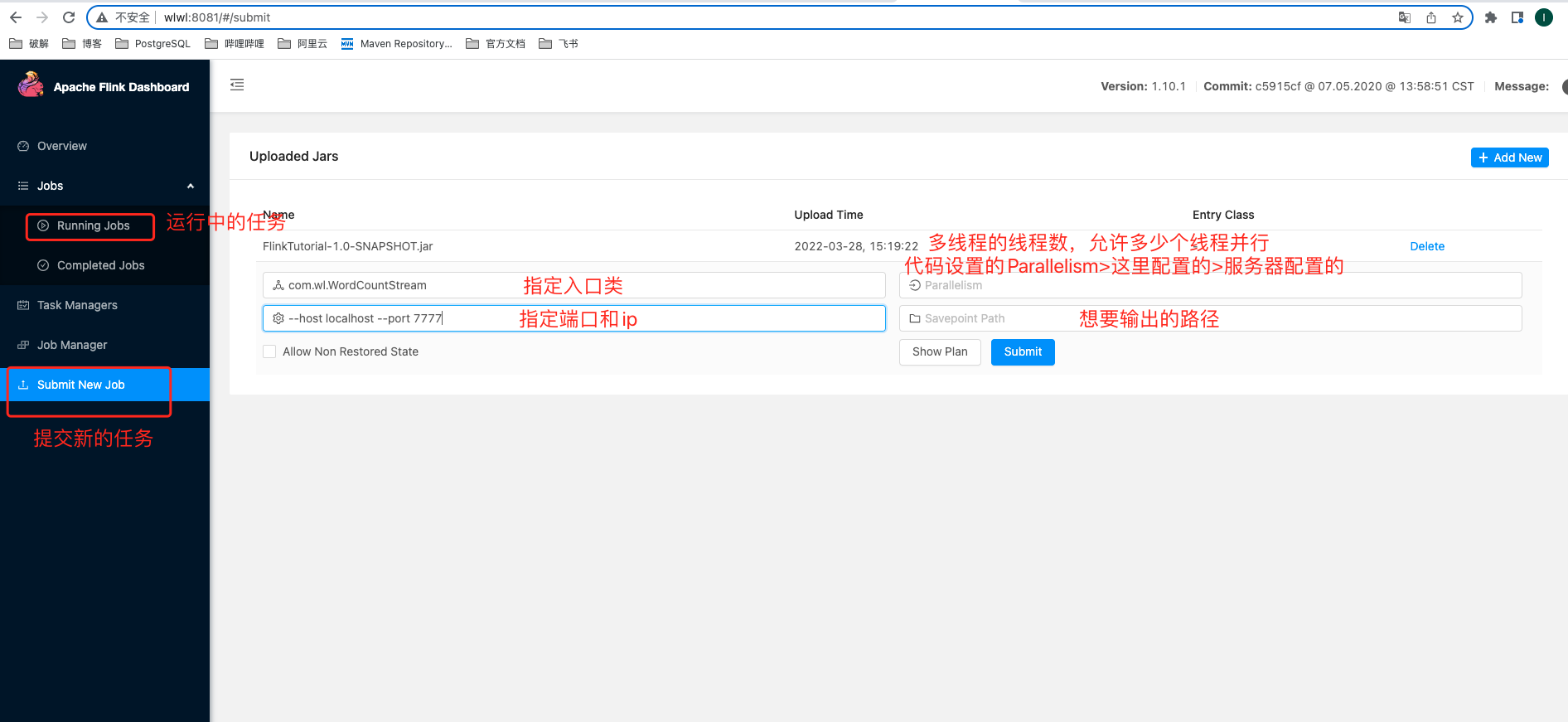
Job Manager
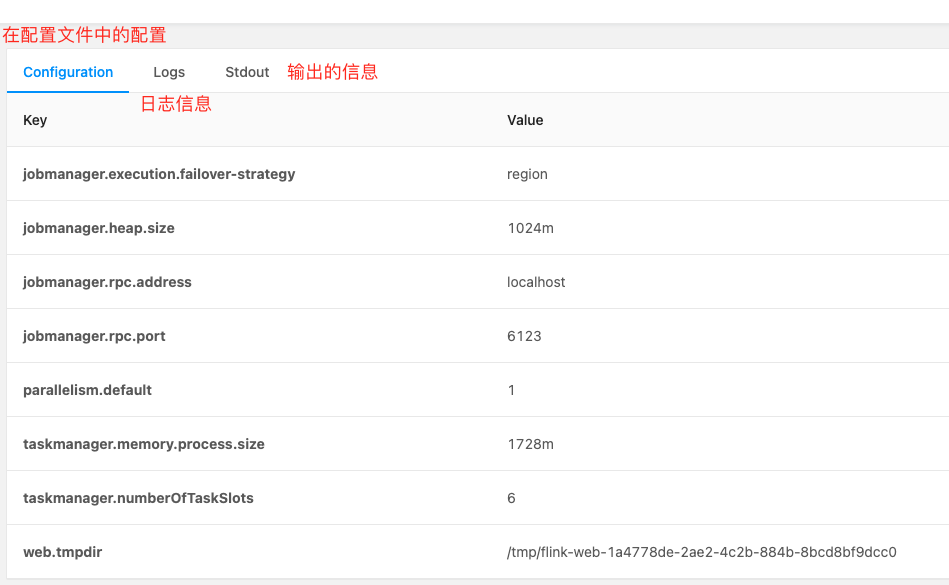
Task Managers
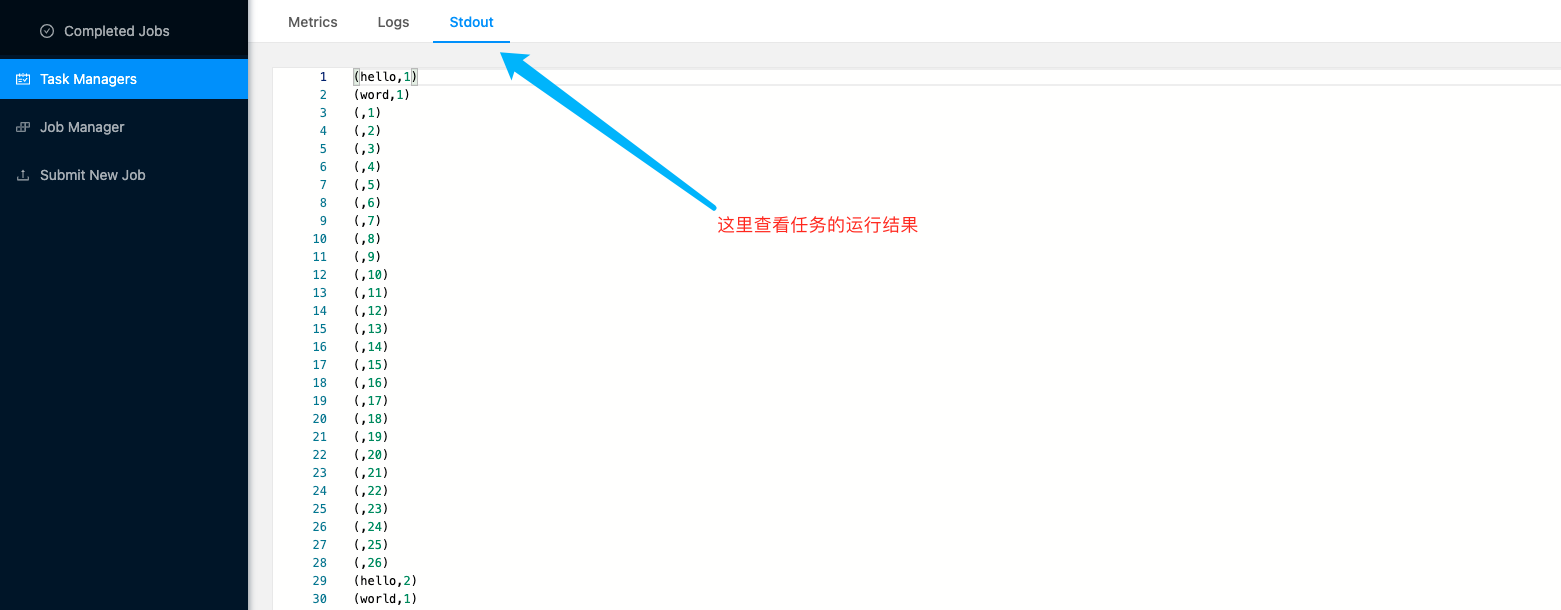
Shell命令提交任务
查看已经提交的任务
bin/flink list

运行提交任务
bin/flink run -c com.wl.WordCountStream /tmp/flink-web-1a4778de-2ae2-4c2b-884b-8bcd8bf9dcc0/flink-web-upload/8089cfe8-9410-4033-a940-c170a252f90c_FlinkTutorial-1.0-SNAPSHOT.jar --host localhost --port 7777
- -c 指定入口类
- -p 指定并行度 Parallelism
- jar包路径
- 启动参数
取消job
bin/flink cancel 4e0c7a93c3b4bec8ddc9d17451c6016f
Yarn模式
Session Cluster模式
Session-Cluster 模式需要先启动集群,然后再提交作业,接着会向 yarn 申请一块空间后,资源永远保持不变。适合规模小执行时间短的作业
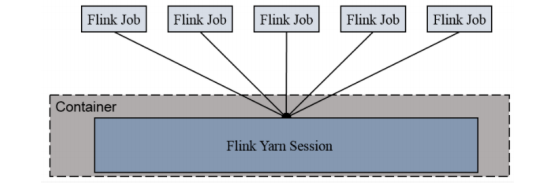
启动yarn-session
bin/yarn-session.sh -n 3 -s 3 -nm wl -d
-n(--container):TaskManager的数量-s(--slots):每个TaskManager的slot数量,默认一个slot一个core-jm:JobManager的内存(单位MB)。-tm:每个taskmanager的内存(单位MB)。-nm:yarn 的appName(现在yarn的webUi上的名字)。-d:后台执行。
关闭yarn-session
yarn application --kill application_1648521328084_0002
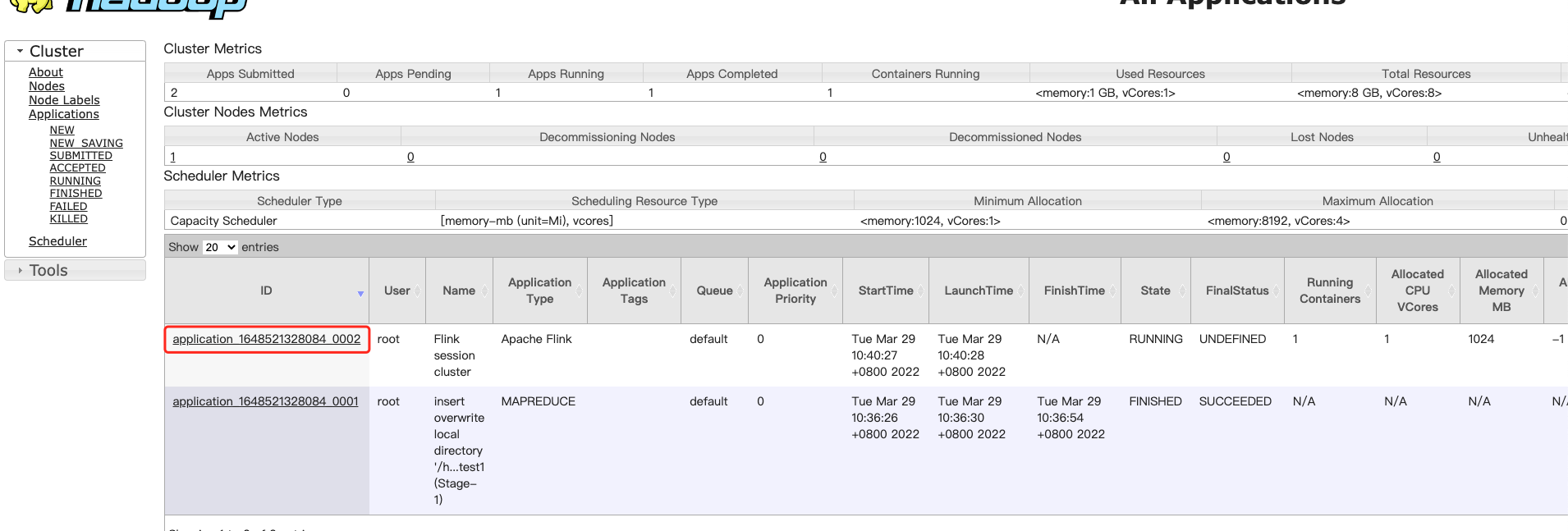
3.运行时架构
运行时的组件
JobManager(作业管理器)
主要的作用是控制一个应用程序的主进程,每个应用程序都会被一个不同的JobManager所控制执行。
应用程序会包括以下内容:
- JobGraph(作业图)
- logical dataflow graph(逻辑数据流图)
- jar包和类
JobManager会向ResourceManager(资源管理器)请求执行任务所必须的资源(插槽slot),一旦获取到了足够的资源,就会将JobGraph(作业图)转换为ExecutionGrap(执行图)分发给TaskManager去执行。
ResourceManager(资源管理器)
主要负责管理插槽,插槽是Flink中定义的处理资源单元。
JobManager申请插槽资源时,ResourceManager会将有空闲插槽的TaskManager分配给JobManager
TaskManger(任务管理器)
执行工作的进程。每个JobManager都包含一个或多个TaskManager运行,,每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。
TaskManager会向资源管理器注册自己的插槽,收到资源管理器的指令后,TaskManager就会将一个或者多个插槽提供给JobManager调用。JobManager就可以向插槽分配任务来执行了
在执行过程中,一个TaskManager可以跟其它运行同一应用程序的TaskManager交换数据
Dispatcher(分发器)
当一个应用被提交执行时,分发器就会启动并将应用移交给一个JobManager
Dispatcher也会启动一个Web UI,用来方便地展示和监控作业执行的信息。
任务提交流程
当一个应用提交时,Flink的组件是如何交互协作的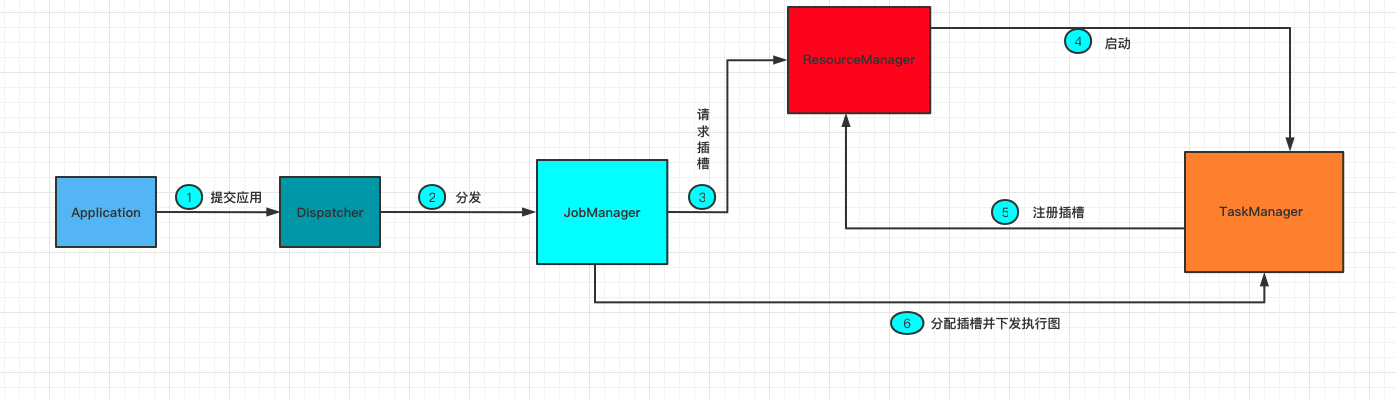
当部署在yarn上,流程如下
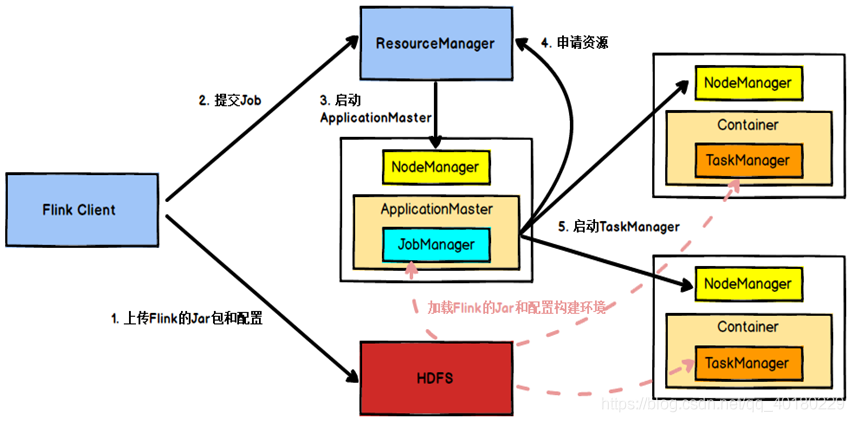
1.Flink任务提交后,Client向HDFS上传Flink的Jar包和配置
2.之后客户端向Yarn ResourceManager提交任务,ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster
3.ApplicationMaster启动后加载Flink的Jar包和配置构建环境,去启动JobManager,之后JobManager向Flink自身的RM进行申请资源,自身的RM向Yarn 的ResourceManager申请资源(因为是yarn模式,所有资源归yarn RM管理)启动TaskManager
4.Yarn ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager
5.NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager,TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
任务调度原理
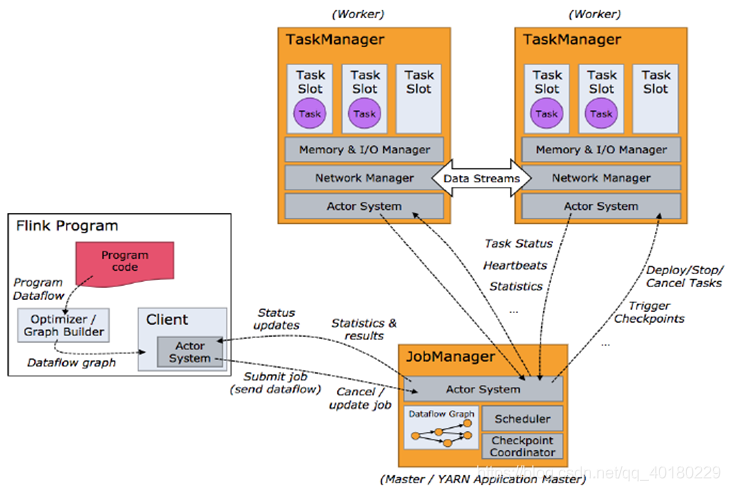
1.客户端不是运行时和程序执行的一部分,但它用于准备并发送dataflow(JobGraph)给Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。而Job Manager会产生一个执行图(Dataflow Graph)
2.当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
3.Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
4.JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
5.TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
5.Flink流处理API
从集合中读取数据
package com.wl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/30 下午5:19
* @qq 2315290571
* @Description 从集合中读取数据
*/
public class ReadFromCollection {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Student> dataStream= env.fromCollection(
Arrays.asList(
new Student("1001", "小明", 12),
new Student("1002", "小张", 13),
new Student("1003", "小李", 14),
new Student("1004", "小小", 15)
)
);
dataStream.print();
env.execute("collection job");
}
}
@AllArgsConstructor
@NoArgsConstructor
@Data
class Student{
private String stuNo;
private String name;
private Integer age;
}
从文件中获取数据
见1.WordCount实例
从Kafka中读取数据
见10.Flink读取Kafka投递文件到HDFS
基本转换算子(map/flatMap/filter)
java代码如下
package com.wl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/30 下午5:58
* @qq 2315290571
* @Description 基础转换算子
*/
public class TransformDemo {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从集合中读取数据
DataStream<Cat> dataStream = env.fromCollection(Arrays.asList(
new Cat(5, "cat1", "吃鱼"),
new Cat(4, "cat2", "抓老鼠"),
new Cat(3, "cat3", "睡觉"),
new Cat(2, "cat4", "睡觉")
));
// map映射 将对象转换为字符串输出
DataStream<String> mapStream = dataStream.map(cat -> {
return cat.toString();
});
// flatMap 拆分
DataStream<Character> flatMapStream = dataStream.flatMap(
new FlatMapFunction<Cat, Character>() {
@Override
public void flatMap(Cat value, Collector<Character> out) throws Exception {
char[] ch = value.toString().toCharArray();
for (char c : ch) {
out.collect(c);
}
}
}
);
// filter 过滤
DataStream<Cat> filterDataStream = dataStream.filter(cat -> {
return cat.getAge() > 3;
});
mapStream.print("map");
flatMapStream.print("flatMap");
filterDataStream.print("filter");
env.execute("Transform");
}
}
@AllArgsConstructor
@NoArgsConstructor
@Data
class Cat {
private Integer age;
private String name;
private String action;
}
聚合操作算子
DataStream里没有reduce和sum这类聚合操作的方法,因为Flink设计中,所有数据必须先分组才能做聚合操作。
KeyBy
这些算子可以针对KeyedStream的每一个支流做聚合。
-
sum()
-
min()
-
max()
-
minBy()
-
maxBy()
maxBy()
package com.wl;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/30 下午6:35
* @qq 2315290571
* @Description 分组聚合
*/
public class KeyByTransform {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取数据源
DataStream<String> dataStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/Cat.txt");
// 进行map整合操作
DataStream<Dog> stream = dataStream
.map(str -> {
String[] value = str.split(",");
return new Dog(Integer.parseInt(value[0]), value[1], value[2]);
})
// 按照 姓名分组
.keyBy(Dog::getName)
// 年龄最小的
.maxBy("age");
stream.print("result");
env.execute();
}
}
@AllArgsConstructor
@NoArgsConstructor
@Data
class Dog {
private Integer age;
private String name;
private String action;
}
启动
出现这个异常,我们在resources 目录下建一个文件 log4j.properties
可以更详细的看到报错信息
# 可以设置级别: debug>info>error
#debug :显示 debug 、 info 、 error
#info :显示 info 、 error
#error :只 error
# 也就是说只显示比大于等于当前级别的信息
log4j.rootLogger=info,appender1
#log4j.rootLogger=info,appender1
#log4j.rootLogger=error,appender1
# 输出到控制台
log4j.appender.appender1=org.apache.log4j.ConsoleAppender
# 样式为 TTCCLayout
log4j.appender.appender1.layout=org.apache.log4j.TTCCLayout
再次启动

发现了一个重要的信息, Dog类不是一个public,flink不认为是一个标准的POJO类型
所以需要加上修饰符public,不放在一个类中了
package com.wl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@AllArgsConstructor
@NoArgsConstructor
@Data
public class Dog{
private Integer age;
private String name;
private String action;
}
Cat.txt
5,catA,eat mouse
10,catF,run
9,catA,sleep
7,catD,jump
8,catH,catch mouse
9,catF,sleep
6,catH,sleep
运行结果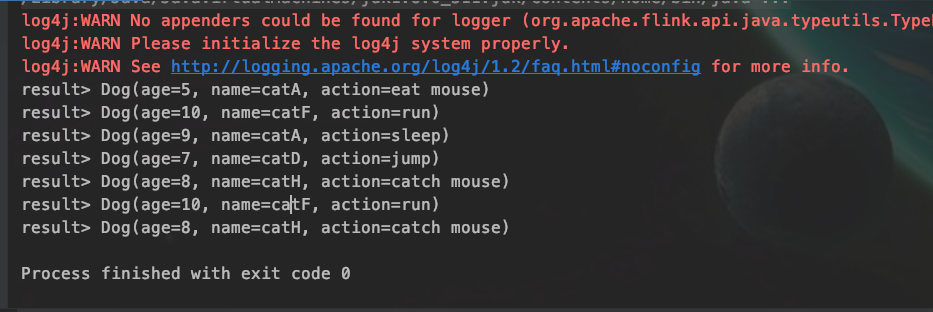
结果的解释说明:
首先keyBy进行name分组,然后分别求每组的最大值,第一条数据进来,只有他自己,所以是最大的,然后第二条,接着继续滚动
多流转换算子
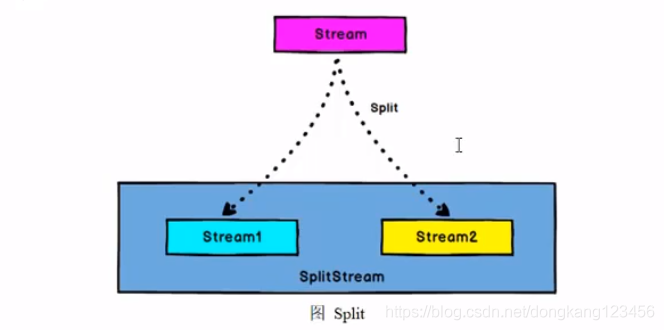
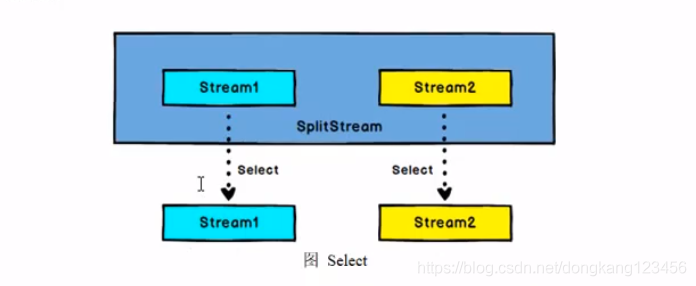
Split和Select
split将一个Stream 拆分成 一个SplitStream,他的里面包含多个stream
select是从SplitStream中获取stream
package com.wl;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Collections;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/31 上午11:19
* @qq 2315290571
* @Description Connect 和 map
*/
public class ConnectStreamDemo {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 转换成实体类
DataStream<Dog> mapStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/Cat.txt").map(value -> {
String[] str = value.split(",");
return new Dog(Integer.parseInt(str[0]), str[1], str[2]);
});
// 分流 按年龄分为两条流
SplitStream<Dog> splitStream = mapStream.split(value -> {
return (value.getAge() > 6) ? Collections.singletonList("old") : Collections.singletonList("young");
});
// 获取流
DataStream<Dog> oldStream = splitStream.select("old");
DataStream<Dog> youngStream = splitStream.select("young");
DataStream<Dog> allStream = splitStream.select("young", "old");
// 打印
oldStream.print("old");
youngStream.print("young");
// allStream.print("all");
// 执行
env.execute("split and select");
}
}
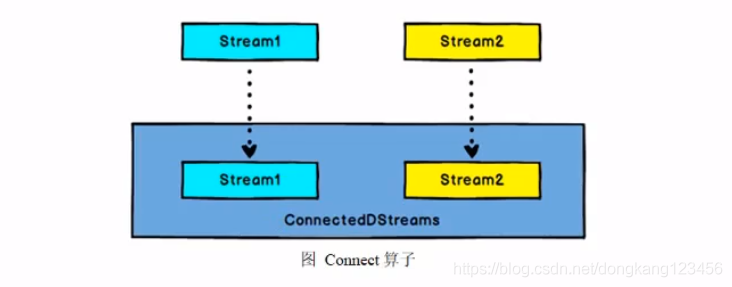
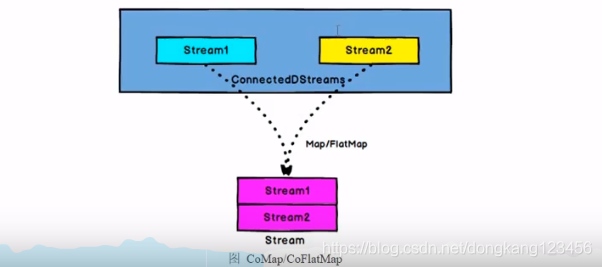
Connect和CoMap
Connect 连接两个保持他们类型的数据流,两个数据流被Connect 之后,只是被放在了一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立
package com.wl;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import scala.Tuple2;
import scala.Tuple3;
import java.util.Collections;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/31 上午11:19
* @qq 2315290571
* @Description Connect 和 map
*/
public class ConnectStreamDemo {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 转换成实体类
DataStream<Dog> mapStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/Cat.txt").map(value -> {
String[] str = value.split(",");
return new Dog(Integer.parseInt(str[0]), str[1], str[2]);
});
// 分流 按年龄分为两条流
SplitStream<Dog> splitStream = mapStream.split(value -> {
return (value.getAge() > 6) ? Collections.singletonList("old") : Collections.singletonList("young");
});
// 获取流
DataStream<Dog> oldStream = splitStream.select("old");
DataStream<Dog> youngStream = splitStream.select("young");
DataStream<Dog> allStream = splitStream.select("young", "old");
// 将 oldStream 转换成二元组类型
DataStream<Tuple2<String,Integer>> tuple2DataStream= oldStream.map(new MapFunction<Dog, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(Dog value) throws Exception {
return new Tuple2<>(value.getName(),value.getAge());
}
});
// 使用Connect 保持他们类型的数据流
ConnectedStreams<Tuple2<String, Integer>, Dog> connectedStreams = tuple2DataStream.connect(youngStream);
// 使用CoMap进行分别操作
DataStream<Object> resultStream = connectedStreams.map(new CoMapFunction<Tuple2<String, Integer>, Dog, Object>() {
@Override
public Object map1(Tuple2<String, Integer> value) throws Exception {
return new Tuple3<>(value._1, value._2, "old");
}
@Override
public Object map2(Dog dog) throws Exception {
return new Tuple2(dog.getAge(), "normal");
}
});
// 打印
resultStream.print();
// 执行
env.execute("Connect CosMap");
}
}
Union
合并两个及两个以上的流,产生一个新的流
对比Connect
- Connect的数据类型可以不同,Connect只能合并两个流
- Union可以合并多条流,Union的数据结构必须是一样的
代码演示 省略
7.WindowApi
要统计在一段时间内的数据,或者计数达到某个值的时候需要用到窗口。窗口就是在将无限流转换为有限块进行处理
窗口类型:
-
时间窗口(Time Window)
- 滚动时间窗口(Tumbling window)
- 滑动时间窗口 (Sliding window)
- 会话窗口(Session window)
-
计数窗口(Count Window)
- 滚动计数窗口
- 滑动计数窗口
开窗代码的实现
package com.wl.window;
import com.wl.Student;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.WindowAssigner;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.Arrays;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/5/16 下午2:52
* @qq 2315290571
* @Description 创建窗口
*/
public class CreateWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Student> dataStream = env.fromCollection(
Arrays.asList(
new Student("1001", "小明", 12),
new Student("1002", "小张", 13),
new Student("1003", "小李", 14),
new Student("1004", "小小", 15)
)
);
// 必须要在keyBy=以后才能开窗口 或者 创建全局窗口 windowAll(不推荐,因为会将并行度都为1)
/**
* 方法一:
* 开窗 window方法里面需要 传一个 {@link WindowAssigner} 类型的值 , WindowAssigner有一些实现类对应不同的窗口
* 例如 如果要创建 {@link TumblingProcessingTimeWindows} 滑动和滚动时间窗口 则需要调用它本身的 of方法,因为构造方法被 protected保护了 不能直接new
*方法二:
* 直接调用 timeWindow方法 和
*/
dataStream.keyBy("stuNo")
// 滚动时间窗口 和简写方式
// .window(TumblingProcessingTimeWindows.of(Time.seconds(15)))
// .timeWindow(Time.seconds(15))
// 滑动时间窗口 和简写方式
// .window(SlidingProcessingTimeWindows.of(Time.seconds(15),Time.seconds(20)))
// .timeWindow(Time.seconds(15),Time.seconds(20))
// 会话时间窗口 (无简写形式)
// .window(EventTimeSessionWindows.withGap(Time.minutes(1)))
// 滚动计数窗口
// .countWindow(5)
// 滑动计数窗口
.countWindow(5, 10);
dataStream.print();
env.execute("collection job");
}
}
窗口函数
开窗以后做的聚合运算 称之为窗口函数,分为两类:
- 增量聚合函数(来一条数据处理一条 ReduceFunction AggregateFunction)
- 全窗口聚合函数(批处理数据 ProcessWindowFunction WindowFunction)
增量聚合函数案例代码实现
根据对应的id进行累加计算
package com.wl.window;
import com.wl.Order;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/5/16 下午4:06
* @qq 2315290571
* @Description 增量聚合函数
*/
public class AccumulatorFunction {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(2000L);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.160.2:9092");//kafka
properties.setProperty("group.id", "flink-test"); //group.id
DataStream<Order> dataStream = env.addSource(new FlinkKafkaConsumer<String>("flink-test", new SimpleStringSchema(), properties))
.map(value -> {
String[] values = value.split(",");
System.out.println(Arrays.toString(values));
return new Order(Integer.parseInt(values[0]), values[1], Double.parseDouble(values[2]));
});
// 开窗处理
DataStream<Integer> countStream = dataStream.keyBy("orderId")
.timeWindow(Time.seconds(15))
// 增量聚合函数
.aggregate(new MyAggregateFunction());
countStream.print();
env.execute();
}
}
class MyAggregateFunction implements AggregateFunction<Order, Integer, Integer> {
@Override
public Integer createAccumulator() {
// 返回值是累加器初始值
return 0;
}
@Override
public Integer add(Order order, Integer accumulator) {
// 具体怎么累加 这里是来一个累加一次计算
return accumulator + 1;
}
@Override
public Integer getResult(Integer accumulator) {
// 返回结果 累加器的值
return accumulator;
}
@Override
public Integer merge(Integer integer, Integer acc1) {
return null;
}
}
实体类
package com.wl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/1 上午11:43
* @qq 2315290571
* @Description 学生实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Order {
private Integer orderId;
private String orderName;
private Double orderPrice;
}
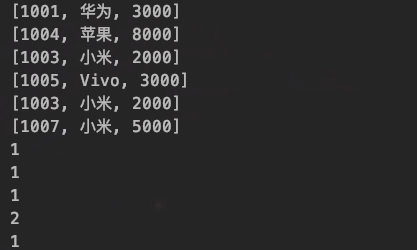
运行结果如下
全窗口聚合函数
根据不同的id输出对应的时间窗口
package com.wl.window;
import com.wl.Order;
import org.apache.commons.collections.IteratorUtils;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/5/17 上午11:08
* @qq 2315290571
* @Description 全窗口聚合函数
*/
public class WindowFunctionTest {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置kafka环境
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.160.2:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-test");
// 读取kafka内容
DataStream<Order> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink-test", new SimpleStringSchema(), pro))
.map(value->{
String[] values = value.split(",");
System.out.println(Arrays.toString(values));
return new Order(Integer.parseInt(values[0].trim()), values[1].trim(), Double.parseDouble(values[2].trim()));
// return new Order();
})
;
// 全窗口聚合函数 开窗操作 累加计数
DataStream<Tuple3<Integer, Long, Integer>> windowStream = sourceStream.keyBy("orderId")
// 窗口滚动15秒
.timeWindow(Time.seconds(15))
// 开窗函数
.apply(new WindowFunction<Order, Tuple3<Integer, Long, Integer>, Tuple, TimeWindow>() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Order> input, Collector<Tuple3<Integer, Long, Integer>> out) throws Exception {
// 获取订单id
Integer orderId = tuple.getField(0);
// 迭代累加
Integer count = IteratorUtils.toList(input.iterator()).size();
// 获取窗口的时间毫秒值
long endTime = window.getEnd();
out.collect(new Tuple3(orderId,endTime,count));
}
});
windowStream.print();
env.execute();
}
}
class MyWindowFunction implements WindowFunction<Order, Tuple3<String, Long, Integer>, Tuple, TimeWindow> {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable<Order> input, Collector<Tuple3<String, Long, Integer>> out) {
// 获取订单id
String orderId = tuple.getField(0);
// 迭代累加
Integer count = IteratorUtils.toList(input.iterator()).size();
// 获取窗口的时间毫秒值
long endTime = window.getEnd();
out.collect(new Tuple3(orderId,endTime,count));
}
}
运行结果
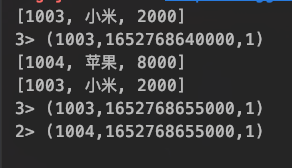
因为设置的滚动窗口是15秒滚动,所以根据输入的内容时间来进行批处理
滑动计数增量窗口
求平均值
package com.wl.window;
import com.wl.Order;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/5/17 下午2:45
* @qq 2315290571
* @Description 计数滑动窗口
*/
public class SlidingCountWindow {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置kafka环境
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.160.2:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-test");
// 读取kafka内容
DataStream<Order> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink-test", new SimpleStringSchema(), pro))
.map(value->{
String[] values = value.split(",");
System.out.println(Arrays.toString(values));
return new Order(Integer.parseInt(values[0].trim()), values[1].trim(), Double.parseDouble(values[2].trim()));
});
// 计数滑动窗口 使用增量函数窗口计算平均值
DataStream<Double> avgStream = sourceStream.keyBy("orderId")
.countWindow(10, 2)
.aggregate(new AggregateCountWindow());
avgStream.print();
env.execute();
}
}
class AggregateCountWindow implements AggregateFunction<Order, Tuple2<Double,Integer>,Double>{
@Override
public Tuple2<Double, Integer> createAccumulator() {
return new Tuple2(0.0,0);
}
@Override
public Tuple2<Double, Integer> add(Order order, Tuple2<Double, Integer> tuple2) {
return new Tuple2(order.getOrderPrice()+tuple2.f0,tuple2.f1+1);
}
@Override
public Double getResult(Tuple2<Double, Integer> tuple2) {
return tuple2.f0/tuple2.f1;
}
@Override
public Tuple2<Double, Integer> merge(Tuple2<Double, Integer> t1, Tuple2<Double, Integer> t2 ) {
return new Tuple2(t1.f0+ t2.f0,t2.f1+t2.f0);
}
}
运行结果
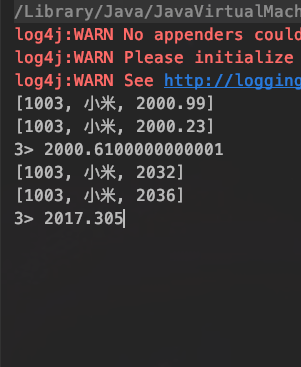
运行结果中发现 ,当输入两个数的时候,就已经开始计算平均值了,但是代码中要求的是10个数开始计算平均值,跟我们预期的不一样。
那是因为我们设置的滑动窗口是达到十个数,就往后滑两步,能往后面滑动,那也可以往前面滑动,所以从后面计算十个数,就往前滑两步进行计算。当达到10时,就会开启新的窗口
其他函数
trigger:触发器,定义window关闭的时间,触发并计算输出结果
evictor:移除器,定义移除某些数据的逻辑
allowedlateness:允许迟到的数据
sideOutputLateData:将迟到的数据放入侧输出流
getSideOutput:获取侧输出流
测试代码:
package com.wl.window;
import com.wl.Order;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/5/17 下午3:45
* @qq 2315290571
* @Description 其他APi
*/
public class OtherFunction {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 配置kafka环境
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.160.2:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink-test");
// 读取kafka内容
DataStream<Order> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink-test", new SimpleStringSchema(), pro))
.map(value->{
String[] values = value.split(",");
System.out.println(Arrays.toString(values));
return new Order(Integer.parseInt(values[0].trim()), values[1].trim(), Double.parseDouble(values[2].trim()));
});
// 开窗操作
SingleOutputStreamOperator<Order> priceSumStream = sourceStream.keyBy("orderId")
.timeWindow(Time.seconds(20))
// 允许等待迟到的数据的时长
.allowedLateness(Time.seconds(10))
// 聚合操作
.sum("orderPrice");
// priceSumStream.getSideOutput(outputTag).print("late");
priceSumStream.print("normal");
env.execute();
}
}
8. 时间语义和WaterMark
时间语义
在windowApi中提到了迟到的数据,数据是相对于什么时间而言算是迟到的呢,flink里面有三种时间语义:
-
EventTime:时间创建的时间
-
Ingestion Time:数据进入Flink的时间
-
Processing Time:执行操作算子的本地系统时间,与机器相关
一般情况下我们更关心EventTime,举如图所示的例子
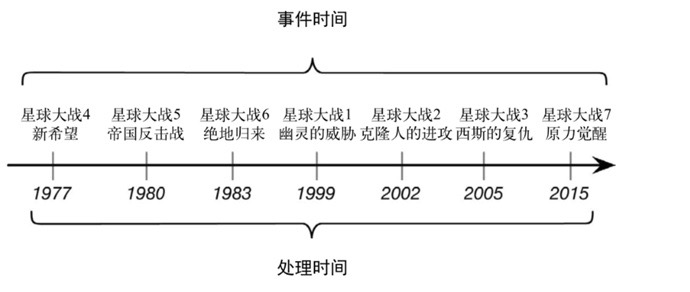
如果我们想去看星球大战,应该是从第一部开始看,更关心的是事件故事发展的顺序,而不是什么时间上映的。
在代码中使用EventTime
系统默认使用的是ProcessingTime,所以需要手动修改时间语义。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
WaterMark
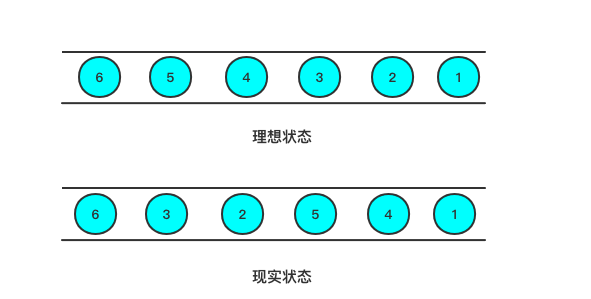
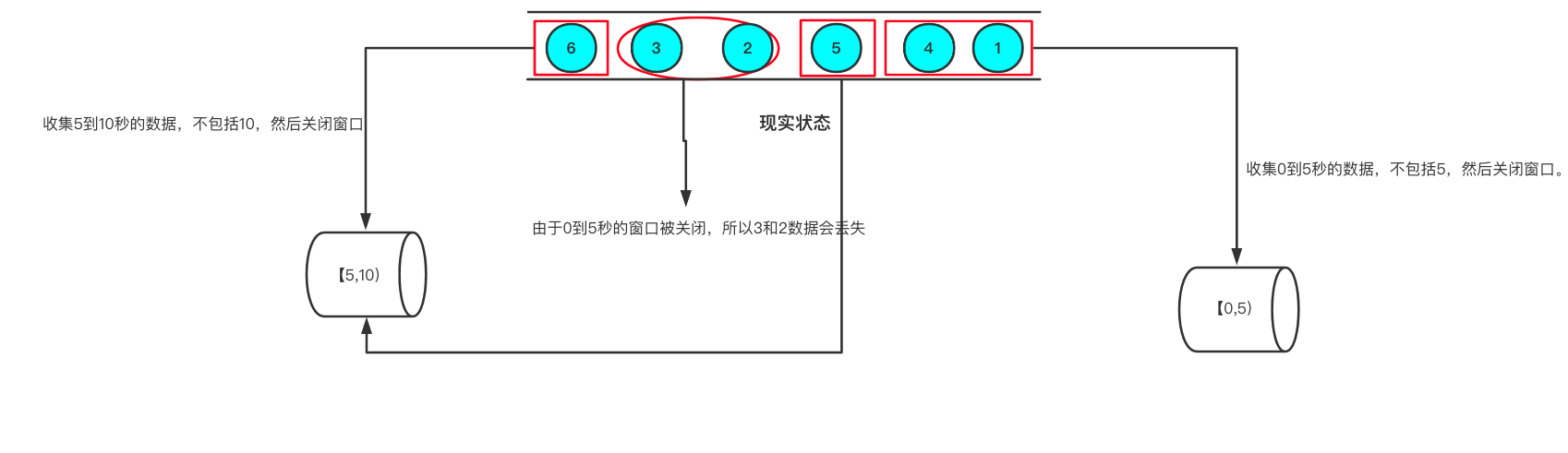
流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是可能网络、分布式等原因导致Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
当事件的先后顺序不是严格按照事件的Event Time顺序排列的时候,则会出现以下的情况,flink在收到第三个数据时间戳为5s的时候,会认为已经到5s的时间戳了,于是关闭0到5的窗口开启5到10的窗口,导致 2和3数据丢失。
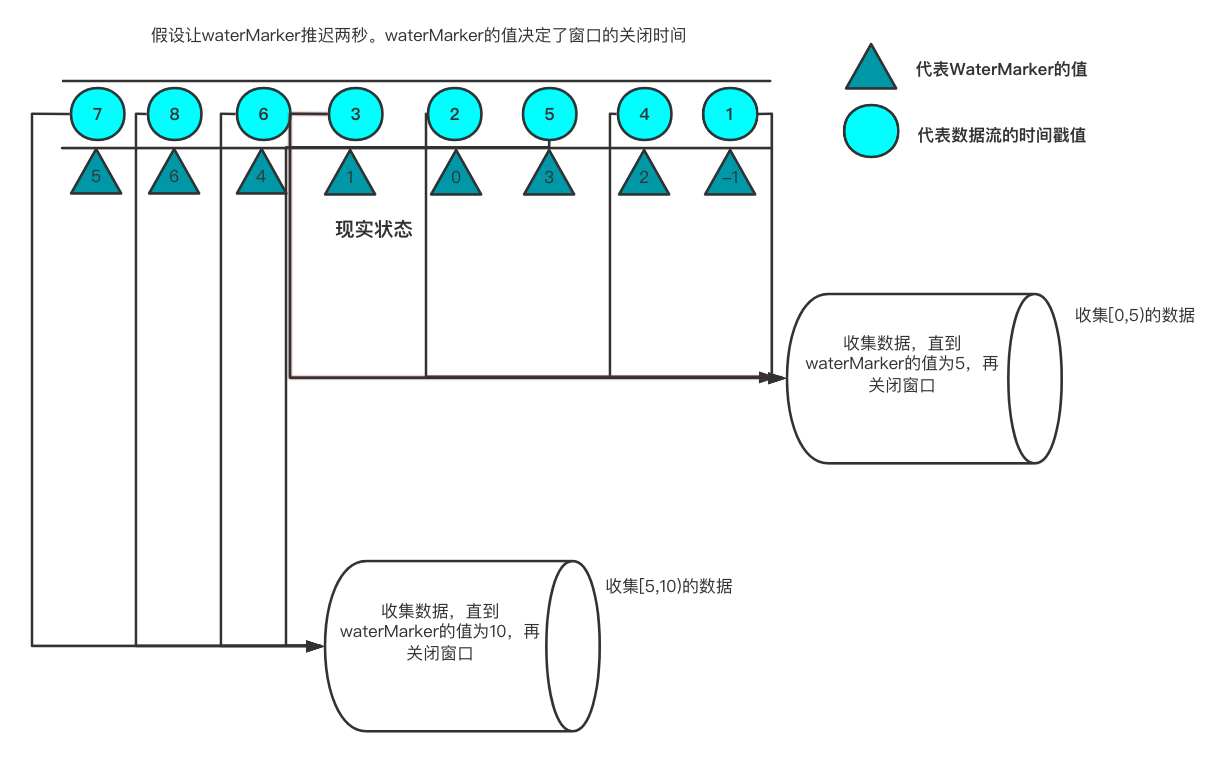
然后flink就提出了水位线(waterMark)的理念,水位线的值来决定窗口什么时间关闭。一般设置水位线的值是最大的迟到时间差值。通俗来说,水位线的概念就好像一个大巴车在8:00等学生上车,但是有些学生迟到了,需要8:02才能来,于是大巴车将钟表时间调成7:58,等到8点如果再不来就发车了。
9.状态后端
在实际开发中,数据一般都是以流的形式出现,当我们想对一个流式数据做一些标记性处理,例如累加计数,需要用到状态。Flink为我们提供了两种状态管理:
-
算子状态(Operator State) 作用范围是算子任务之内
-
键控状态(Keyed State) 按照key来操作,作为范围是key分组以后
算子状态
flink提供了三种数据结构来存储算子状态:
-
列表状态(List State) 状态用List集合来存储
-
联合列表状态(Union List State) 将数据用List集合存储
-
广播状态(Broadcast State) 算子有多项任务,状态相同,用广播
不常用不举例。。。
键控状态(Keyed State)
flink提供了四种数据结构来存储键控状态:
-
值状态(Value State) 存储单个状态
-
列表状态 (List State) 用list集合来存储状态
-
映射状态(Map State) 用key-value来存储状态
-
聚合状态(Reducing State&Aggergating State) 将状态表示为聚合操作的列表
Value State
package com.wl.state;
import com.wl.Order;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/1 上午11:32
* @qq 2315290571
* @Description 键控(Keyed State)状态管理
*/
public class StateManage {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取kafka
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.160.3:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"test-topic");
DataStream<Order> orderStream = env.addSource(new FlinkKafkaConsumer<String>("test-topic", new SimpleStringSchema(), pro))
.map(value -> {
String[] order = value.split(",");
return new Order(Integer.parseInt(order[0]),order[1],Double.parseDouble(order[2]));
})
;
// orderStream.print();
// 键控处理
DataStream<Integer> keyStream = orderStream.keyBy("orderId")
.map(new OrderCountMapFunction());
keyStream.print("keyState");
// 运行
env.execute("stateTest");
}
}
class OrderCountMapFunction extends RichMapFunction<Order, Integer> {
// 定义键的数据类型
private ValueState<Integer> countValue;
// 定义赋值初始值
@Override
public void open(Configuration parameters) throws Exception {
// 因为要获取上下文 所以不能直接在外面直接定义
countValue=getRuntimeContext().getState(new ValueStateDescriptor<Integer>("count",Integer.class,0));
}
@Override
public Integer map(Order value) throws Exception {
Integer count = countValue.value();
count++;
countValue.update(count);
return count;
}
}
运行结果
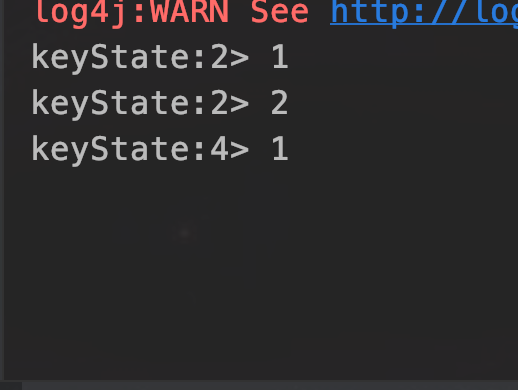
List State
package com.wl.state;
import com.wl.Order;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.ArrayList;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/1 上午11:32
* @qq 2315290571
* @Description 键控(Keyed State)状态管理
*/
public class StateManage {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取kafka
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.160.3:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-topic");
DataStream<Order> orderStream = env.addSource(new FlinkKafkaConsumer<String>("test-topic", new SimpleStringSchema(), pro))
.map(value -> {
String[] order = value.split(",");
return new Order(Integer.parseInt(order[0]), order[1], Double.parseDouble(order[2]));
});
// orderStream.print();
// 键控处理
DataStream<Tuple2<Integer, Double>> keyStream = orderStream.keyBy("orderId")
.map(new OrderCountMapFunction());
keyStream.print("keyState");
// 运行
env.execute("stateTest");
}
}
class OrderCountMapFunction extends RichMapFunction<Order, Tuple2<Integer, Double>> {
// 定义键的数据类型
private ListState<Object> countValue;
// 定义赋值初始值
@Override
public void open(Configuration parameters) throws Exception {
// 因为要获取上下文 所以不能直接在外面直接定义
countValue = getRuntimeContext().getListState(new ListStateDescriptor<Object>("count", Object.class));
}
@Override
public Tuple2<Integer, Double> map(Order value) throws Exception {
Integer id=0;
Double price=0.00;
for (Object o : countValue.get()) {
if (o instanceof Integer){
id=(int)o;
}else if (o instanceof Double){
price=(double)o;
}
}
ArrayList<Object> list = new ArrayList<>();
list.add(id+value.getOrderId() + 1);
list.add(price+value.getOrderPrice() + 5);
countValue.update(list);
return new Tuple2<>(id+value.getOrderId() + 1,price+value.getOrderPrice() + 5);
}
}
MapState
package com.wl.state;
import com.wl.Order;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/1 上午11:32
* @qq 2315290571
* @Description 键控(Keyed State)状态管理
*/
public class StateManage {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取kafka
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.160.3:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test-topic");
DataStream<Order> orderStream = env.addSource(new FlinkKafkaConsumer<String>("test-topic", new SimpleStringSchema(), pro))
.map(value -> {
String[] order = value.split(",");
return new Order(Integer.parseInt(order[0]), order[1], Double.parseDouble(order[2]));
});
// orderStream.print();
// 键控处理
DataStream<Tuple2<String, Double>> keyStream = orderStream.keyBy("orderId")
.map(new OrderCountMapFunction());
keyStream.print("keyState");
// 运行
env.execute("stateTest");
}
}
class OrderCountMapFunction extends RichMapFunction<Order, Tuple2<String, Double>> {
// 定义键的数据类型
private MapState<String,Double> countValue;
// 定义赋值初始值
@Override
public void open(Configuration parameters) throws Exception {
// 因为要获取上下文 所以不能直接在外面直接定义
countValue = getRuntimeContext().getMapState(new MapStateDescriptor<String, Double>("count", String.class,Double.class));
}
@Override
public Tuple2<String, Double> map(Order value) throws Exception {
if (countValue.get(value.getOrderId().toString())==null){
countValue.put(value.getOrderId().toString(),value.getOrderPrice());
}else {
Double price=countValue.get(value.getOrderId().toString())+value.getOrderPrice();
countValue.put(value.getOrderId().toString(),price);
}
return new Tuple2<>(value.getOrderId().toString(),countValue.get(value.getOrderId().toString()));
}
}
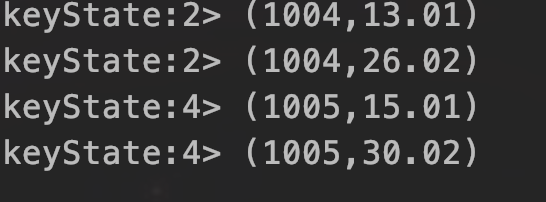
输入的值以及运行结果
1004,梨子,13.01
1004,梨子,13.01
1005,香蕉,15.01
1005,香蕉,15.01
前面几种状态数据结构不能访问事件的时间戳信息和watermark信息,在一些场景下需要访问 处理的时间戳信息时,就要使用到Flink提供的底层API ProcessFunction。
下面举例一个温度持续上升报警的案例
package com.wl.state;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/8 上午10:31
* @qq 2315290571
* @Description 温度监控
*/
public class temperatureMonitor {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取kafka
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wl:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
DataStream<Temperature> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro))
.map(value -> {
String[] tempStr = value.split(",");
return new Temperature(Integer.parseInt(tempStr[0]), Double.parseDouble(tempStr[1]));
});
sourceStream.print();
// 执行KeyedByProcession
sourceStream.keyBy(Temperature::getTemp_id)
.process(new TempWarning(Time.seconds(10).toMilliseconds())).print();
// 执行
env.execute("temperature monitor");
}
}
class TempWarning extends KeyedProcessFunction<Integer, Temperature, String> {
// 定义时间间隔
private Long interval;
// 定义上一个温度值
private ValueState<Double> lastTemperature;
// 最后一次定时器的触发时间
private ValueState<Long> recentTimerTimeStamp;
public TempWarning(Long interval) {
this.interval = interval;
}
// 初始化
@Override
public void open(Configuration parameters) throws Exception {
// 定义生命周期
lastTemperature = getRuntimeContext().getState(new ValueStateDescriptor<Double>("lastTemp", Double.class));
recentTimerTimeStamp = getRuntimeContext().getState(new ValueStateDescriptor<Long>("recentTemp", Long.class));
}
@Override
public void processElement(Temperature temperature, Context context, Collector<String> collector) throws Exception {
// 当前温度值
Double curTemp = temperature.getTemp_num();
// 上一次温度
Double lastTemp = lastTemperature.value() != null ? lastTemperature.value() : curTemp;
// 计时器状态的时间戳
Long timerStamp = recentTimerTimeStamp.value();
if (curTemp > lastTemp && timerStamp == null) {
long warningTimeStamp = context.timerService().currentProcessingTime() + interval;
// 触发定时器
context.timerService().registerProcessingTimeTimer(warningTimeStamp);
recentTimerTimeStamp.update(warningTimeStamp);
} else if (curTemp < lastTemp && timerStamp != null) {
context.timerService().deleteProcessingTimeTimer(timerStamp);
recentTimerTimeStamp.clear();
}
// 更新保存的温度值
lastTemperature.update(curTemp);
}
// 关闭
@Override
public void close() throws Exception {
lastTemperature.clear();
}
// 定时器
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("定时器触发 " + timestamp);
// 触发报警并且清除 定时器状态的值
out.collect("传感器id" + ctx.getCurrentKey() + "温度持续" + interval + "ms" + "上升");
recentTimerTimeStamp.clear();
}
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class Temperature {
private Integer temp_id;
private Double temp_num;
}
状态后端存储
为了确保flink 的检查点状态持久化存储,flink提供了三种状态后端:
-
MemoryStateBackend 将检查点状态存储在JVM的堆内存上(速度快,低延迟,但是不稳定,可能会丢失数据)
-
FsStateBackend 将检查点状态存储到文件系统(有本地文件系统和远程文件系统,容错率高)
-
RocksDBStateBackend 将所有状态序列化后,存入RocksDB中存储
状态后端可以有两种修改方式
配置文件修改-全局修改
代码修改-可以每个任务修改
// filesystem
env.setStateBackend(newFsStateBackend("hdfs://192.168.160.3:8020/data/stateBackend"));
10.容错机制
一致性检查点
flink故障恢复的核心就是应用状态的一致性检查点,在某个时间点,所有任务都进行一份自身快照。
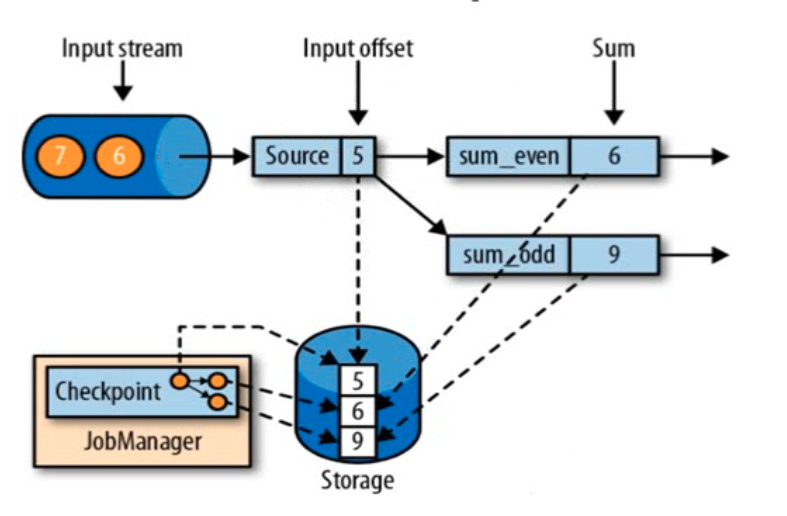
如图,假设从kafka中读取到源数据5,此时数据进入了奇数求和(1+3+5),那么做快照的时候,偶数流也要快照,因为同一个相同的数据 ,只是没有被处理。
从检查点恢复状态
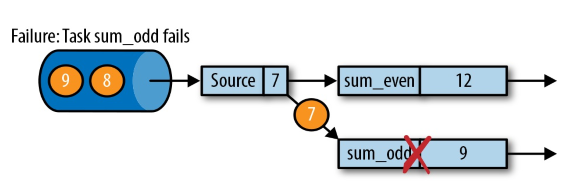
如图在处理到奇数流的时候宕机了,数据传输发生中断。
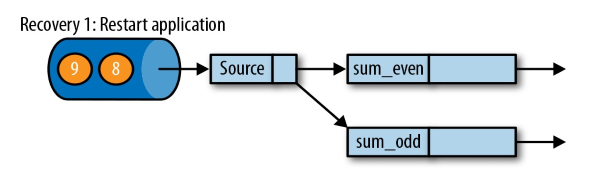
遇到故障之后,第一步就是重启应用
(重启后,起初流都是空的)
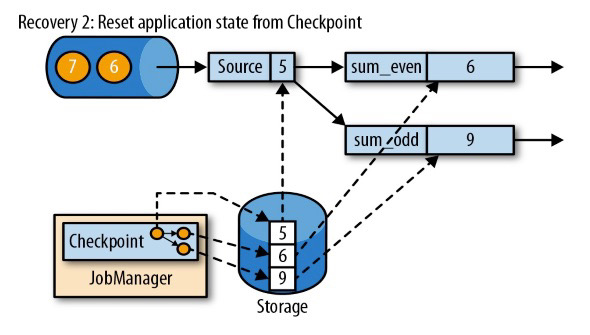
第二步是从 checkpoint 中读取状态,将状态重置
(读取在远程仓库(Storage,这里的仓库指状态后端保存数据指定的三种方式之一)保存的状态)
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同
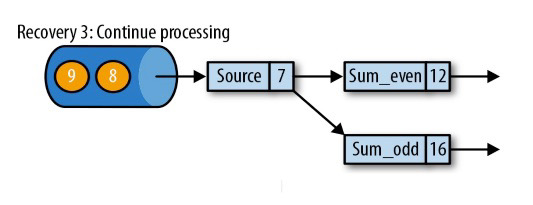
第三步:开始消费并处理检查点到发生故障之间的所有数据
这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置
检查点和重启策略配置
重启策略配置 可以在配置文件也可以在代码中配置,为了方便一般都在代码中配置
用一个计数的实例来说明程序中断,状态如何恢复:
已经配置了检查点策略的代码
package com.wl.state;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/8 下午3:23
* @qq 2315290571
* @Description 配置检查点
*/
public class CheckPointConfig {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置并行度
env.setParallelism(1);
// 开启检查点
env.enableCheckpointing(1000);
// 设置语义 精确一次
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// CheckPoint的处理超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 最大允许同时处理几个CheckPoint
env.getCheckpointConfig().setMaxConcurrentCheckpoints(2);
// 重启策略配置
// 固定延迟重启(最多尝试3次,每次间隔10s)
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000L));
// 失败率重启(在10分钟内最多尝试3次,每次至少间com.wl.state.CheckPointConfig隔1分钟)
env.setRestartStrategy(RestartStrategies.failureRateRestart(3, Time.minutes(10), Time.minutes(1)));
// 检查点存储
env.getCheckpointConfig().setCheckpointStorage("hdfs://192.168.160.2:8020/data/flink");
// 检查点默认不保留 当程序被取消时会被删除,使用以下配置可以在程序被取消或任务失败时,检查点不会被自动清理
env.getCheckpointConfig().setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 读取消息队列
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wlwl:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
DataStream<Temperature> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro))
.map(value -> {
String[] strValue = value.split(",");
return new Temperature(Integer.parseInt(strValue[0]), Double.parseDouble(strValue[1]));
});
sourceStream.print();
// 记录状态
DataStream<Integer> KeyCount = sourceStream.keyBy(Temperature::getTemp_id)
.map(new KeyCountMapper());
KeyCount.print();
// 执行
env.execute("execute CheckPoint");
}
private static class KeyCountMapper extends RichMapFunction<Temperature, Integer> {
private ValueState<Integer> countState;
@Override
public void open(Configuration parameters) throws Exception {
countState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("keyCount", Integer.class, 0));
}
@Override
public Integer map(Temperature temperature) throws Exception {
countState.update(countState.value() == null ? 0 : countState.value() + 1);
return countState.value();
}
}
}
然后服务器上打开flink并启动集群,将任务打成jar包运行,在运行过程中中断进程。
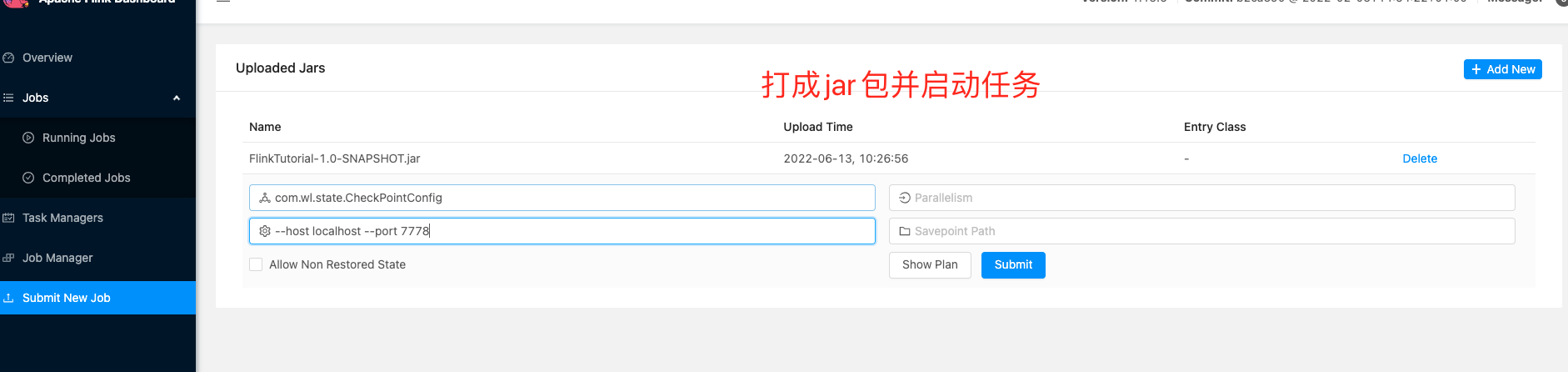


或者命令行手动停止
#找到任务的id
../bin/flink list
#找到对应的 任务id取消
bin/flink cancel 4e0c7a93c3b4bec8ddc9d17451c6016f
然后命令行恢复
# -s 检查点保存路径 -c 指定启动类 指定jar包 --host 指定ip --port 指定端口
bin/flink run -s hdfs://192.168.160.2:8020/data/flink/bfeb9c9fa7cee5a408a4210291f750f4/chk-1408/_metadata -c com.wl.state.CheckPointConfig /tmp/flink-web-c06e4543-b3f8-4746-966c-36e2a303d6f4/flink-web-upload/74c2d0ad-c66c-4ac0-ae77-7c3ec568545f_FlinkTutorial-1.0-SNAPSHOT.jar --host localhost --port 7778

11.TableAPI的使用
加入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.10.1</version>
</dependency>
dog.txt
12,dogA,sleep
23,dogB,watchDoor
14,dogC,eat
13,dogD,run
12,dogM,lie
13,dogW,shout
TableApi的简单使用
package com.wl;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/21 下午6:59
* @qq 2315290571
* @Description tableApi的使用
*/
public class TableDemoTest {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 转换成实体类
DataStream<Dog> mapStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/dog.txt").map(value -> {
String[] str = value.split(",");
return new Dog(Integer.parseInt(str[0]), str[1], str[2]);
});
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 使用tableApi创建虚拟表表并查询
Table dogTable = tableEnv.fromDataStream(mapStream);
Table tableApiResult = dogTable.select("name");
tableEnv.createTemporaryView("dog", dogTable);
// Using SQL DDL
Table ddlResult = tableEnv.sqlQuery("select name,action from dog");
tableEnv.toAppendStream(tableApiResult, Row.class).print("tableApiResult");
tableEnv.toAppendStream(ddlResult, Row.class).print("ddlResult");
env.execute("testTableApi");
}
}
TableApi批处理和流处理的创建
package com.wl.table;
import com.wl.Dog;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.java.BatchTableEnvironment;
import org.apache.flink.table.api.java.StreamTableEnvironment;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/22 下午3:09
* @qq 2315290571
* @Description 基础程序结构
*/
public class BasicTable {
public static void main(String[] args) {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 清洗数据转换为POJO类
DataStream<Dog> dogStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/dog.txt").map(
value -> {
String[] catValue = value.split(",");
return new Dog(Integer.parseInt(catValue[0]), catValue[1], catValue[2]);
}
);
// 创建表读取数据
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// planner流处理
EnvironmentSettings OldPlannerSettings = EnvironmentSettings.newInstance()
.useOldPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment plannerStreamTableEnv = StreamTableEnvironment.create(env, OldPlannerSettings);
// planner批处理
ExecutionEnvironment plannerBatchEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment plannerBatchTableEnv = BatchTableEnvironment.create(plannerBatchEnv);
// Blink批处理
EnvironmentSettings blinkStreamSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inStreamingMode()
.build();
StreamTableEnvironment blinkStreamTableEnv = StreamTableEnvironment.create(env, blinkStreamSettings);
// Blink的批处理
EnvironmentSettings blinkBatchSettings = EnvironmentSettings.newInstance()
.useBlinkPlanner()
.inBatchMode()
.build();
TableEnvironment blinkBatchTableEnv = TableEnvironment.create(blinkBatchSettings);
}
}
创建TableEnvironment 读取数据
package com.wl.table;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.Schema;
import org.apache.flink.types.Row;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/22 下午3:43
* @qq 2315290571
* @Description 从文件中读取数据创建表
*/
public class CommonApi {
public static void main(String[] args) throws Exception {
// 创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取表的运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取文件
String filePath = "/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/dog.txt";
tableEnv.connect(new FileSystem().path(filePath))// 从文件中获取数据
.withFormat(new Csv())// 格式化为csv文件
.withSchema(new Schema().field("age", DataTypes.INT()).field("name", DataTypes.STRING()).field("action", DataTypes.STRING())) // 定义表的结构
.createTemporaryTable("dogTable"); // 创建临时表
// 从文件中拿取数据
Table table = tableEnv.from("dogTable");
// 打印表的结构
table.printSchema();
// 1.Table 查询
// 1.1过滤
Table filterAgeTable = table.select("age,name,action").filter("age>12");
// 1.2分组统计
Table groupByAgeTable = table.groupBy("age").select("age,count(name)");
// 2.Sql查询sqlQueryTable
Table sqlQueryTable = tableEnv.sqlQuery("select count(action) as totalAge,avg(age) as avgAge from dogTable group by age");
tableEnv.toAppendStream(table, Row.class).print("data");
tableEnv.toAppendStream(filterAgeTable, Row.class).print("filterAgeTable");
tableEnv.toRetractStream(groupByAgeTable, Row.class).print("groupByAgeTable");
tableEnv.toRetractStream(sqlQueryTable, Row.class).print("sqlQueryTable");
env.execute();
}
}
运行结果
root
|-- age: INT
|-- name: STRING
|-- action: STRING
data> 12,dogA,sleep
filterAgeTable> 23,dogB,watchDoor
data> 23,dogB,watchDoor
filterAgeTable> 14,dogC,eat
data> 14,dogC,eat
filterAgeTable> 13,dogD,run
data> 13,dogD,run
filterAgeTable> 13,dogW,shout
groupByAgeTable> (true,12,1)
data> 12,dogM,lie
groupByAgeTable> (true,23,1)
data> 13,dogW,shout
groupByAgeTable> (true,14,1)
groupByAgeTable> (true,13,1)
groupByAgeTable> (false,12,1)
groupByAgeTable> (true,12,2)
groupByAgeTable> (false,13,1)
sqlQueryTable> (true,1,12)
groupByAgeTable> (true,13,2)
sqlQueryTable> (true,1,23)
sqlQueryTable> (true,1,14)
sqlQueryTable> (true,1,13)
sqlQueryTable> (false,1,12)
sqlQueryTable> (true,2,12)
sqlQueryTable> (false,1,13)
sqlQueryTable> (true,2,13)
false表示上一条保存的记录被删除,true则是新加入的数据所以Flink的Table API在更新数据时,实际是先删除原本的数据,再添加新数据
创建TableEnvironment 写数据
package com.wl.table;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.Schema;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/24 上午11:49
* @qq 2315290571
* @Description 写出数据到文件
*/
public class FileOutPut {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 获取TableApi的运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//根据文件创建表
String filePath = "/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/dog.txt";
tableEnv.connect(new FileSystem().path(filePath))
.withFormat(new Csv())
.withSchema(new Schema().field("age", DataTypes.INT()).field("name", DataTypes.STRING()).field("action", DataTypes.STRING()))
.createTemporaryTable("dog");
// 从文件中获取数据
Table table = tableEnv.from("dog");
// 分组统计
Table filterAgeTable = table.select("age,name,action").filter("age>12");
String outPath = "/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/out.txt";
tableEnv.connect(new FileSystem().path(outPath))
.withFormat(new Csv())
.withSchema(new Schema().field("age", DataTypes.INT()).field("name", DataTypes.STRING()).field("action", DataTypes.STRING()))
.createTemporaryTable("outTable");
filterAgeTable.insertInto("outTable");
tableEnv.execute("");
}
}
运行结果
23,dogB,watchDoor
14,dogC,eat
13,dogD,run
13,dogW,shout
这种方式写入文件有局限性,只能是批处理,再次运行代码会报错。
读写Kafka
新版Flink和新版kafka连接器,version指定"universal"
package com.wl.table;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.Kafka;
import org.apache.flink.table.descriptors.Schema;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/24 下午2:36
* @qq 2315290571
* @Description 读写Kafka
*/
public class KafkaReadAndWrite {
public static void main(String[] args) throws Exception {
//获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(1);
// 获取TableApi的运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取kafka
tableEnv.connect(new Kafka()
.topic("test-topic")
.version("universal")
.property("bootstrap.servers", "192.168.160.2:9092")
)
.withFormat(new Csv())
.withSchema(new Schema().field("id", DataTypes.INT()).field("name", DataTypes.STRING()).field("address", DataTypes.STRING()))
.createTemporaryTable("student");
// 从student表中获取数据
Table table = tableEnv.from("student");
Table resultTable = table.select("id,name,address");
// 将kafka数据写入txt文件
tableEnv.connect(new FileSystem().path("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/kafkaOut.txt"))
.withFormat(new Csv())
.withSchema(new Schema().field("id", DataTypes.INT()).field("name", DataTypes.STRING()).field("address", DataTypes.STRING()))
.createTemporaryTable("outTable");
resultTable.insertInto("outTable");
//将kafka数据写入kafka
tableEnv.connect(new Kafka()
.topic("flink-test")
.version("universal")
.property("bootstrap.servers", "192.168.160.2:9092")
)
.withFormat(new Csv())
.withSchema(new Schema().field("id", DataTypes.INT()).field("name", DataTypes.STRING()).field("address", DataTypes.STRING()))
.createTemporaryTable("toKafka");
resultTable.insertInto("toKafka");
tableEnv.execute("");
}
}
写入到mysql
package com.wl.table;
import com.wl.Order;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.Kafka;
import org.apache.flink.table.descriptors.Schema;
import org.apache.flink.types.Row;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/13 下午2:32
* @qq 2315290571
* @Description table Api 写入到mysql
*/
public class FlinkMysql {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(1);
// 设置table api的运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取kafka
// Properties pro = new Properties();
// pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wlwl:9092");
// pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
//
// DataStream<Order> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro))
// .map(value -> {
// String[] orderInfo = value.split(",");
// return new Order(Integer.parseInt(orderInfo[0]), orderInfo[1], Double.parseDouble(orderInfo[2]));
// });
tableEnv.connect(new Kafka()
.topic("flink")
.version("universal")
.property("bootstrap.servers", "192.168.160.2:9092")
)
.withFormat(new Csv())
.withSchema(new Schema().field("orderId", DataTypes.INT()).field("orderName", DataTypes.STRING()).field("orderPrice", DataTypes.DOUBLE()))
.createTemporaryTable("order_test");
// 将流的数据转换为动态表
Table selectResult = tableEnv.sqlQuery("select * from order_test ");
tableEnv.toRetractStream(selectResult, Row.class).print("sqlQueryTable");
// 执行DDL
String sinkDDL = "create table flink_test (" +
" order_id INT," +
" order_name STRING," +
" order_price DOUBLE" +
") WITH (" +
" 'connector' = 'jdbc', " +
" 'url' = 'jdbc:mysql://localhost:3306/flink', " +
" 'table-name' = 'order_test', " +
" 'username' = 'root', " +
" 'password' = 'wl990922' " +
")";
// 输入输出
tableEnv.executeSql(sinkDDL);
selectResult.executeInsert("flink_test");
// tableEnv.execute("test");
env.execute();
}
}
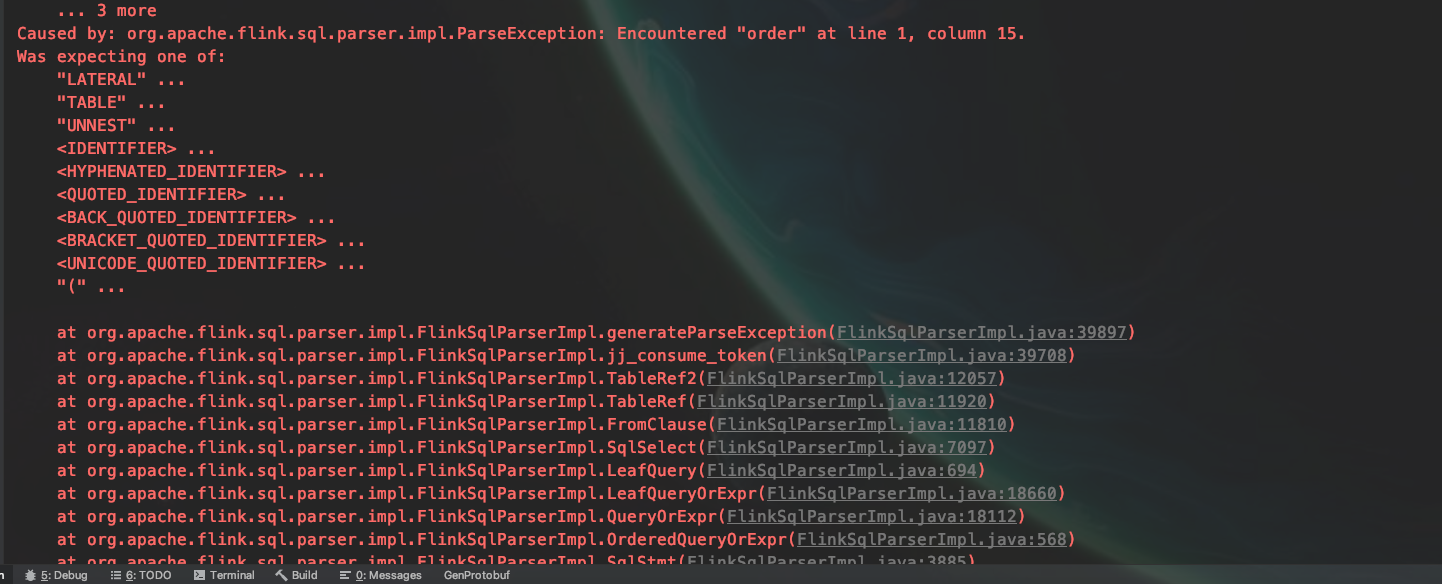
注意:表的名称不能包含关键字,否则会报以下异常
时间特性
Table 可以提供一个逻辑上的时间字段,用于在表处理程序中,指示时间和访问相应的时间戳
定义处理时间(Processing Time)
由DataStream转换成表时指定
package com.wl.window_sql;
import com.wl.Order;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.GroupWindow;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/14 下午3:03
* @qq 2315290571
* @Description 时间特性
*/
public class WindowTest {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取kafka
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wlwl:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
DataStream<Order> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro))
.map(value -> {
String[] orderInfo = value.split(",");
return new Order(Integer.parseInt(orderInfo[0]), orderInfo[1], Double.parseDouble(orderInfo[2]));
});
// 流转表
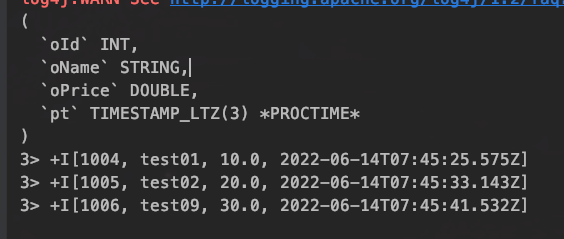
Table table = tableEnv.fromDataStream(sourceStream,"orderId as oId,orderName as oName,orderPrice as oPrice,pt.proctime");
table.printSchema();
tableEnv.toAppendStream(table, Row.class).print();
env.execute();
}
}
运行结果
定义TableSchema时指定
tableEnv.connect(new FileSystem().path("src/main/resources/order.txt"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("orderId", DataTypes.INT())
.field("orderName",DataTypes.STRING())
.field("orderPrice",DataTypes.DOUBLE())
.field("pt",DataTypes.TIMESTAMP(3)).proctime()
)
.createTemporaryTable("order_test");
DDL定义
String sinkDDL = "create table flink_test (" +
" order_id INT," +
" order_name STRING," +
" order_price DOUBLE" +
"pt AS PROCTIME() "+
") WITH (" +
" 'connector' = 'jdbc', " +
" 'url' = 'jdbc:mysql://localhost:3306/flink', " +
" 'table-name' = 'order_test', " +
" 'username' = 'root', " +
" 'password' = '111111' " +
")";
tableEnv.executeSql(sinkDDL);
定义时间事件(Event Time)
从流中获取定义
package com.wl.window_sql;
import com.wl.Order;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.*;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.descriptors.Csv;
import org.apache.flink.table.descriptors.FileSystem;
import org.apache.flink.table.descriptors.Rowtime;
import org.apache.flink.table.descriptors.Schema;
import org.apache.flink.table.types.DataType;
import org.apache.flink.types.Row;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/14 下午3:03
* @qq 2315290571
* @Description 时间特性
*/
public class WindowTest {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取kafka
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wlwl:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
DataStream<Order> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro))
.map(value -> {
String[] orderInfo = value.split(",");
return new Order(Integer.parseInt(orderInfo[0]), orderInfo[1], Double.parseDouble(orderInfo[2]),Long.parseLong(orderInfo[3]));
// return new Order();
});
// 流转表
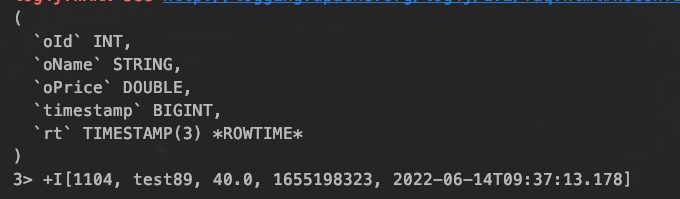
Table table = tableEnv.fromDataStream(sourceStream,"orderId as oId,orderName as oName,orderPrice as oPrice,timestamp,rt.rowtime");
table.printSchema();
tableEnv.toAppendStream(table, Row.class).print();
env.execute();
}
}
Schema定义
tableEnv.connect(new FileSystem().path("/Users/wangliang/Documents/ideaProject/Flink/FlinkTutorial/src/main/resources/order.txt"))
.withFormat(new Csv())
.withSchema(new Schema()
.field("orderId", DataTypes.INT())
.field("orderName",DataTypes.STRING())
.field("orderPrice",DataTypes.DOUBLE())
.field("timestamp",DataTypes.BIGINT())
.rowtime(new Rowtime().timestampsFromField("timestamp") // 从字段中提取时间戳
.watermarksPeriodicBounded(1000) // watermark延迟一秒
)
)
.createTemporaryTable("order_test");
DDL语言定义
String sinkDDL = "create table flink_test (" +
" order_id INT," +
" order_name STRING," +
" order_price DOUBLE," +
" rt AS TO_TIMESTAMP( FROM_UNIXTIME(ts) ),"+
") WITH (" +
" 'connector' = 'jdbc', " +
" 'url' = 'jdbc:mysql://localhost:3306/flink', " +
" 'table-name' = 'order_test', " +
" 'username' = 'root', " +
" 'password' = '111111' " +
")";
tableEnv.executeSql(sinkDDL);
Group Windows
类似于sql中的 group by,处理时间要定义事件时间语义
package com.wl.window_sql;
import com.wl.Temperature;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.util.Arrays;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/15 上午11:14
* @qq 2315290571
* @Description GroupWindow开窗
*/
public class GroupWindowTest {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 设置并行度
env.setParallelism(1);
// 读取kafka
// Properties pro = new Properties();
// pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wlwl:9092");
// pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
//
// DataStream<Temperature> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro))
// .map(value -> {
// String[] strValue = value.split(",");
// return new Temperature(Integer.parseInt(strValue[0]), Double.parseDouble(strValue[1]),Long.parseLong(strValue[2]));
// });
// sourceStream.print();
DataStream<Temperature> sourceStream= env.fromCollection(
Arrays.asList(
new Temperature(1004,20.12,1655198310L),
new Temperature(1004,30.12,1655198312L),
new Temperature(1005,50.12,1655398310L),
new Temperature(1005,60.12,1655398314L),
new Temperature(1005,70.12,1655178310L)
)
).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Temperature>(Time.seconds(2)) {
@Override
public long extractTimestamp(Temperature temperature) {
return temperature.getTemp_time()*1000L;
}
})
;
// 流转表 事件时间处理
Table table = tableEnv.fromDataStream(sourceStream,"temp_id as tId,temp_num as tNum,rt.rowtime");
tableEnv.createTemporaryView("temperature",table);
// table api 查询
Table resultTable = table.window(Tumble.over("10.seconds").on("rt").as("tw"))
.groupBy("tId,tw")
.select("tId,tId.count,tNum.avg,tw.end");
Table resultSqlTable = tableEnv.sqlQuery("select tId,count(tId) as ct,avg(tNum) as avgTemp,tumble_end(rt,interval '10' second) " +
" from temperature group by tId,tumble(rt,interval '10' second)");
tableEnv.toAppendStream(resultTable, Row.class).print("resultTable");
tableEnv.toAppendStream(resultSqlTable, Row.class).print("resultSqlTable");
env.execute();
}
}
运行结果
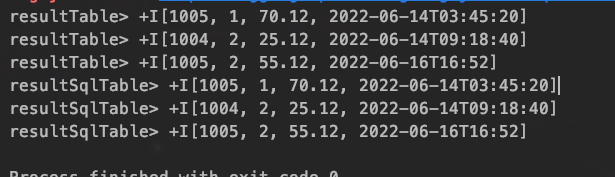
Overwindows
overWindow分为有界流和无界流
-
无界流可以在事件时间或处理时间,以及指定为时间间隔、或行计数的范围内,定义 Over windows
// 无界的事件时间over window (时间字段 "rowtime") .window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_RANGE).as("w")) //无界的处理时间over window (时间字段"proctime") .window(Over.partitionBy("a").orderBy("proctime").preceding(UNBOUNDED_RANGE).as("w")) // 无界的事件时间Row-count over window (时间字段 "rowtime") .window(Over.partitionBy("a").orderBy("rowtime").preceding(UNBOUNDED_ROW).as("w")) //无界的处理时间Row-count over window (时间字段 "proctime") .window(Over.partitionBy("a").orderBy("proctime").preceding(UNBOUNDED_ROW).as("w")) -
有界的over window是用间隔的大小指定的
// 有界的事件时间over window (时间字段 "rowtime",之前1分钟) .window(Over.partitionBy("a").orderBy("rowtime").preceding("1.minutes").as("w")) // 有界的处理时间over window (时间字段 "porctime",之前1分钟) .window(Over.partitionBy("a").orderBy("porctime").preceding("1.minutes").as("w")) // 有界的事件时间Row-count over window (时间字段 "rowtime",之前10行) .window(Over.partitionBy("a").orderBy("rowtime").preceding("10.rows").as("w")) // 有界的处理时间Row-count over window (时间字段 "proctime",之前10行) .window(Over.partitionBy("a").orderBy("proctime").preceding("10.rows").as("w"))
测试代码
package com.wl.window_sql;
import com.wl.Temperature;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.util.Arrays;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/15 下午2:48
* @qq 2315290571
* @Description over window
*/
public class OverWindowTest {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 数据源
DataStream<Temperature> sourceStream =env.fromCollection(Arrays.asList(
new Temperature(1004,40.01,1655198310L),
new Temperature(1004,30.01,1655198320L),
new Temperature(1004,40.01,1655198310L),
new Temperature(1004,40.01,1655198310L),
new Temperature(1005,40.01,1655198310L),
new Temperature(1005,20.01,1655198310L),
new Temperature(1005,20.01,1655198310L),
new Temperature(1005,40.01,1655198310L),
new Temperature(1005,30.01,1655198310L)
)).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Temperature>(Time.seconds(2)) {
@Override
public long extractTimestamp(Temperature temperature) {
return temperature.getTemp_time()*1000L;
}
});
// 流转表
Table dataTable = tableEnv.fromDataStream(sourceStream,"temp_id as tId,temp_num as tNum,temp_time as tTime,rt.rowtime");
// 创建临时表
tableEnv.createTemporaryView("temperature",dataTable);
// 按照 id进行分区 事件时间进行分组 当前和 前三行 总是取 当前行和前三行进行计算
Table overResult = dataTable.window(Over.partitionBy("tId").orderBy("rt").preceding("3.rows").as("tw"))
.select("tId,rt,tTime,tId.count over tw, tNum.avg over tw");
// sql语法
//Table overSqlResult = tableEnv.sqlQuery("select tId,rt,tTime,count(tId) over tw,avg(tNum) over tw" +
// " from temperature" +
// " window tw as (partition by tId order by rt rows between 3 preceding and //current row)");
// tableEnv.toAppendStream(overSqlResult, Row.class).print("overSqlResult");
tableEnv.toAppendStream(overResult, Row.class).print("overResult");
env.execute();
}
}
运行结果
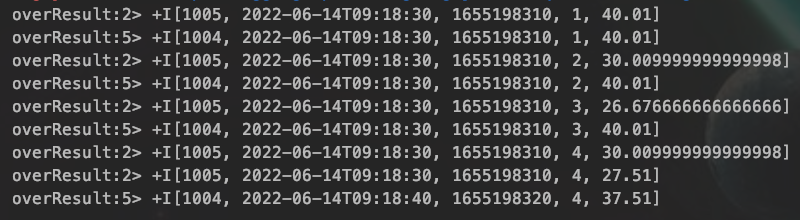
用户自定义函数
flink 的tableApi 提供看了一些内置的函数,但是当我们有自己的特定需求时需要用到自定义函数
自定义函数主要分三个步骤:
- 自定义函数 继承Scalar Funcion,写eval方法,类和方法必须都是 public
- 在代码中注册 registerFunction方法注册
- tableApi 或 sql中调用
package com.wl.udf;
import com.wl.Temperature;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.functions.ScalarFunction;
import org.apache.flink.types.Row;
import java.util.Arrays;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/15 下午5:38
* @qq 2315290571
* @Description 用户自定义函数 执行温度值的四舍五入
*/
public class User_Function {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取table 运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 获取流数据
DataStream<Temperature> sourceStream = env.fromCollection(
Arrays.asList(
new Temperature(1004, 40.9, 1655198310L),
new Temperature(1004, 30.8, 1655198320L),
new Temperature(1004, 40.1, 1655198310L),
new Temperature(1004, 40.15, 1655198310L),
new Temperature(1005, 40.24, 1655198310L),
new Temperature(1005, 20.55, 1655198310L),
new Temperature(1005, 20.11, 1655198310L),
new Temperature(1005, 40.66, 1655198310L),
new Temperature(1005, 30.22, 1655198310L)
)
);
// 流转表
Table dataTable = tableEnv.fromDataStream(sourceStream, "temp_id as tId,temp_num as tNum,temp_time as tTime");
// 注册临时表
tableEnv.createTemporaryView("temp",dataTable);
// 注册udf自定义函数
tableEnv.registerFunction("round",new Round());
// table api 查询
Table resultTable = dataTable.select("tId,tTime,round(tNum)");
// sql查询
Table resultSqlTable = tableEnv.sqlQuery("select tId,tTime,round(tNum) from temp ");
tableEnv.toAppendStream(resultTable, Row.class).print("resultTable");
tableEnv.toAppendStream(resultSqlTable, Row.class).print("resultSqlTable");
env.execute();
}
// 这个类必须是公共的
public static class Round extends ScalarFunction{
// 方法必须是public 方法名是eval
public Long eval(double tNum){
return Math.round(tNum);
}
}
}
运行结果
12.Flink读取Kafka投递文件到HDFS
java代码如下
package com.wl;
import org.apache.flink.api.common.serialization.SimpleStringEncoder;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.OnCheckpointRollingPolicy;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/29 下午5:03
* @qq 2315290571
* @Description aa
*/
public class HdfsTest {
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(10000L);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.160.2:9092");//kafka
properties.setProperty("group.id", "test-topic"); //group.id
DataStream<String> dataStream = env.addSource(new FlinkKafkaConsumer<String>("test-topic", new SimpleStringSchema(), properties));
dataStream.print();
final StreamingFileSink<String> sink = StreamingFileSink
.forRowFormat(new Path("hdfs://"+"192.168.160.2:8020/data/flink"), new SimpleStringEncoder<String>("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withRolloverInterval(TimeUnit.MINUTES.toMillis(30)) //15s空闲,就滚动写入新的文件
.withInactivityInterval(TimeUnit.MINUTES.toMillis(30)) // 不论是否空闲,超过30秒就写入新文件,默认60s。这里设置为30S
.withMaxPartSize(1024 * 1024 * 1024)
.build())
// 文件分为 In-progress Pending 和 Finished 三种状态
// 根据checkpoint的时间来将文件状态进行更改至已完成
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withBucketAssigner(new DateTimeBucketAssigner<>())
.build();
// parquet投递
StreamingFileSink<Order> parquetFileSink =
StreamingFileSink.forBulkFormat(new Path("hdfs://" + "192.168.160.2:8020/data/flink"),
ParquetAvroWriters.forReflectRecord(Order.class))
.withBucketAssigner(new DateTimeBucketAssigner<>("'date='yyyy-MM-dd'/hour='HH"))
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.build();
dataStream.addSink(sink);
env.execute("test");
}
}
启动,发现报错
Exception in thread "main" java.util.concurrent.ExecutionException: org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357)
at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1640)
at org.apache.flink.streaming.api.environment.LocalStreamEnvironment.execute(LocalStreamEnvironment.java:74)
at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1620)
at com.wl.HdfsTest.main(HdfsTest.java:48)
Caused by: org.apache.flink.runtime.client.JobExecutionException: Job execution failed.
at org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147)
at org.apache.flink.client.program.PerJobMiniClusterFactory$PerJobMiniClusterJobClient.lambda$getJobExecutionResult$2(PerJobMiniClusterFactory.java:175)
at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616)
at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591)
at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488)
at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975)
at org.apache.flink.runtime.concurrent.FutureUtils$1.onComplete(FutureUtils.java:874)
at akka.dispatch.OnComplete.internal(Future.scala:264)
at akka.dispatch.OnComplete.internal(Future.scala:261)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:191)
at akka.dispatch.japi$CallbackBridge.apply(Future.scala:188)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:60)
at org.apache.flink.runtime.concurrent.Executors$DirectExecutionContext.execute(Executors.java:74)
at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:68)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1(Promise.scala:284)
at scala.concurrent.impl.Promise$DefaultPromise.$anonfun$tryComplete$1$adapted(Promise.scala:284)
at scala.concurrent.impl.Promise$DefaultPromise.tryComplete(Promise.scala:284)
at akka.pattern.PromiseActorRef.$bang(AskSupport.scala:573)
at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:22)
at akka.pattern.PipeToSupport$PipeableFuture$$anonfun$pipeTo$1.applyOrElse(PipeToSupport.scala:21)
at scala.concurrent.Future.$anonfun$andThen$1(Future.scala:532)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:29)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:29)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:60)
at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
at akka.dispatch.BatchingExecutor$BlockableBatch.$anonfun$run$1(BatchingExecutor.scala:91)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:12)
at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:81)
at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:91)
at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:40)
at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(ForkJoinExecutorConfigurator.scala:44)
at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:110)
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:76)
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:192)
at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:186)
at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:180)
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:496)
at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:380)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:284)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:199)
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74)
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26)
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21)
at scala.PartialFunction.applyOrElse(PartialFunction.scala:123)
at scala.PartialFunction.applyOrElse$(PartialFunction.scala:122)
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:172)
at akka.actor.Actor.aroundReceive(Actor.scala:517)
at akka.actor.Actor.aroundReceive$(Actor.scala:515)
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592)
at akka.actor.ActorCell.invoke(ActorCell.scala:561)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258)
at akka.dispatch.Mailbox.run(Mailbox.scala:225)
at akka.dispatch.Mailbox.exec(Mailbox.scala:235)
... 4 more
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 'hdfs'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded.
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:450)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:362)
at org.apache.flink.streaming.api.functions.sink.filesystem.Buckets.<init>(Buckets.java:117)
at org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink$RowFormatBuilder.createBuckets(StreamingFileSink.java:288)
at org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink.initializeState(StreamingFileSink.java:427)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.tryRestoreFunction(StreamingFunctionUtils.java:178)
at org.apache.flink.streaming.util.functions.StreamingFunctionUtils.restoreFunctionState(StreamingFunctionUtils.java:160)
at org.apache.flink.streaming.api.operators.AbstractUdfStreamOperator.initializeState(AbstractUdfStreamOperator.java:96)
at org.apache.flink.streaming.api.operators.AbstractStreamOperator.initializeState(AbstractStreamOperator.java:284)
at org.apache.flink.streaming.runtime.tasks.StreamTask.initializeStateAndOpen(StreamTask.java:989)
at org.apache.flink.streaming.runtime.tasks.StreamTask.lambda$beforeInvoke$0(StreamTask.java:453)
at org.apache.flink.streaming.runtime.tasks.StreamTaskActionExecutor$SynchronizedStreamTaskActionExecutor.runThrowing(StreamTaskActionExecutor.java:94)
at org.apache.flink.streaming.runtime.tasks.StreamTask.beforeInvoke(StreamTask.java:448)
at org.apache.flink.streaming.runtime.tasks.StreamTask.invoke(StreamTask.java:460)
at org.apache.flink.runtime.taskmanager.Task.doRun(Task.java:708)
at org.apache.flink.runtime.taskmanager.Task.run(Task.java:533)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Hadoop is not in the classpath/dependencies.
at org.apache.flink.core.fs.UnsupportedSchemeFactory.create(UnsupportedSchemeFactory.java:58)
at org.apache.flink.core.fs.FileSystem.getUnguardedFileSystem(FileSystem.java:446)
... 16 more
Process finished with exit code 1
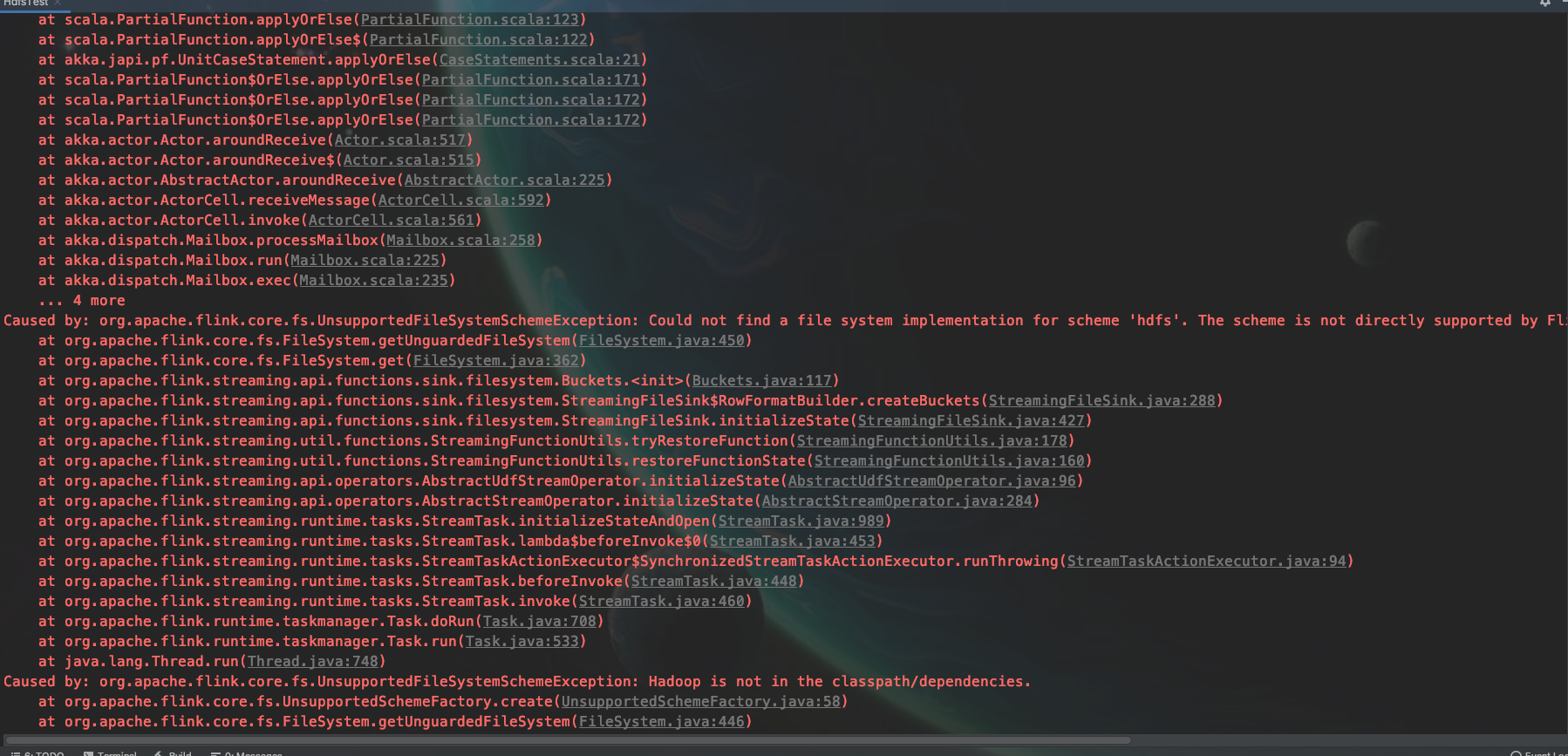
这是因为少加了个依赖,在maven中添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
加入依赖,报了新错误,再加log4j的依赖
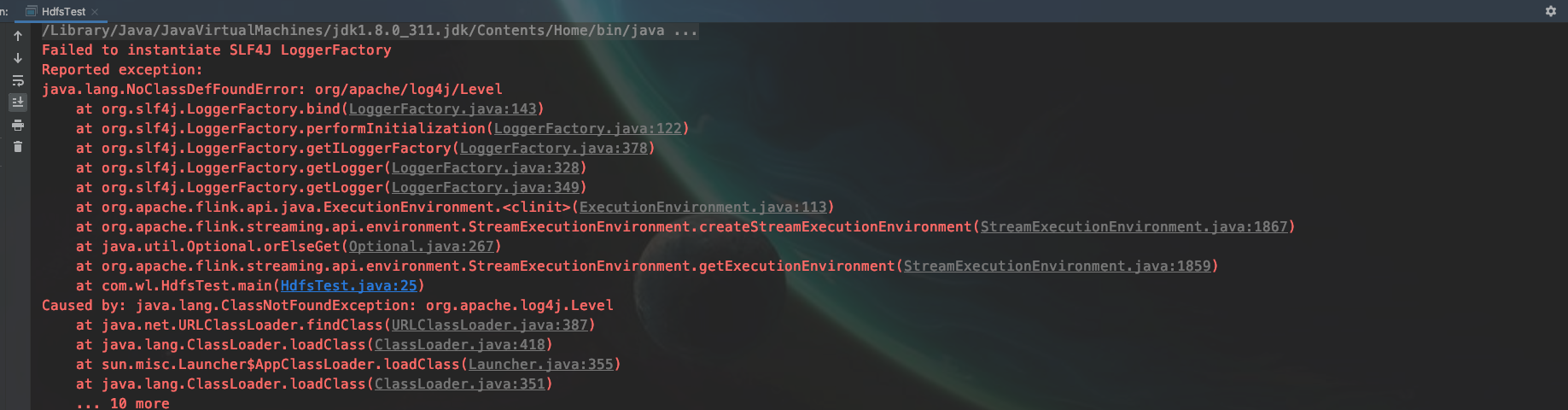
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
再次启动,发现报错 权限问题
解决办法是将用户加入supergroup
vim /etc/sudoers
或者将 hdfs目录权限给用户
hadoop fs -chown -R wangliang:supergroup /data
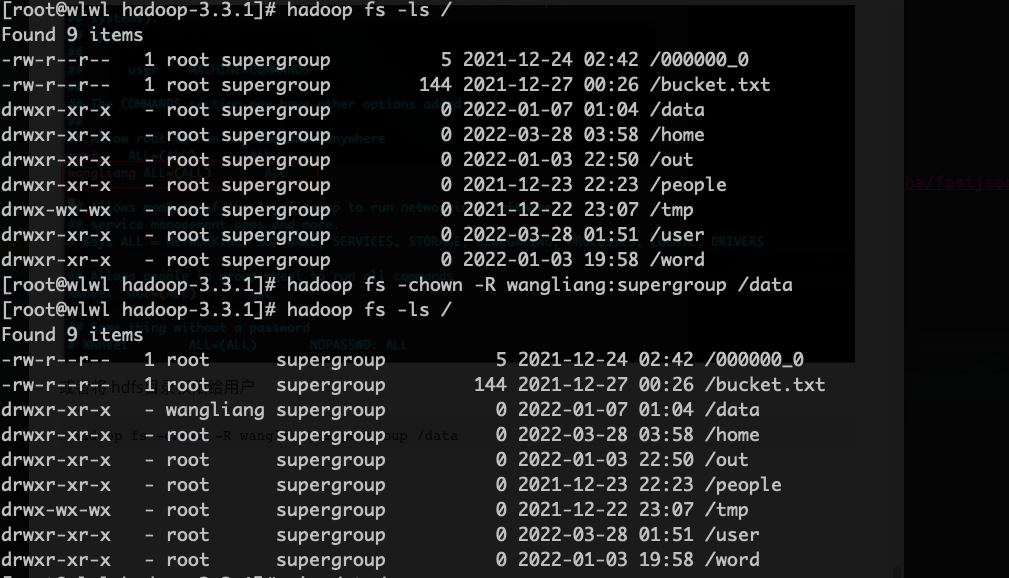
13.Flink投递parquet文件到HDFS,presto读取
POJO类
package com.wl.putrecord;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/4/27 上午10:19
* @qq 2315290571
* @Description
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User {
private Integer id;
private String username;
private String dateTime;
private String event_username;
private String event_password;
}
投递类
package com.wl.putrecord;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.wl.putrecord.MyBucketAssigner;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.core.fs.Path;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.OnCheckpointRollingPolicy;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.lang.reflect.Field;
import java.util.Map;
import java.util.Properties;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/29 下午5:03
* @qq 2315290571
* @Description aa
*/
public class HdfsDynamic {
public static void main(String[] args) throws Exception {
// set up the streaming execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.enableCheckpointing(2000L);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "192.168.160.2:9092");//kafka
properties.setProperty("group.id", "flink-test"); //group.id
DataStream<User> dataStream = env.addSource(new FlinkKafkaConsumer<String>("flink-test", new SimpleStringSchema(), properties))
.map(value -> {
return combinePojoData(value);
});
dataStream.print();
StreamingFileSink<User> parquetFileSink =
StreamingFileSink.forBulkFormat(new Path("hdfs://" + "192.168.160.2:8020/data/flink"),
ParquetAvroWriters.forReflectRecord(User.class))
.withBucketAssigner(new MyBucketAssigner())
.withRollingPolicy(OnCheckpointRollingPolicy.build())
.withOutputFileConfig(OutputFileConfig.builder().withPartSuffix(".parquet").build())
.build();
dataStream.addSink(parquetFileSink);
env.execute("test");
}
private static User combinePojoData(String value) {
JSONObject paramMap = JSON.parseObject(value);
try {
if (!paramMap.isEmpty()) {
// 封装额外参数
Integer id = paramMap.getInteger("id");
String username = paramMap.getString("username");
String dateTime = paramMap.getString("dateTime");
JSONObject m = paramMap.getJSONObject("event");
String m_username = m.getString("username");
String m_password = m.getString("password");
return new User(id,username,dateTime,m_username,m_password);
}
} catch (Exception e) {
throw new IllegalArgumentException("参数格式不正确");
}
return null;
}
private static User combineData(String value) {
Map<String, Object> paramMap = JSON.parseObject(value, Map.class);
try {
if (!paramMap.isEmpty()) {
// 封装额外参数
User newInstance = User.class.getDeclaredConstructor().newInstance();
for (Field field : User.class.getDeclaredFields()) {
if (paramMap.containsKey(field.getName())) {
field.setAccessible(true);
if (field.getName().equals("map")){
field.set(newInstance,(Map<String,Object>)paramMap.get(field.getName()));
}else {
field.set(newInstance, paramMap.get(field.getName()));
}
paramMap.remove(field.getName());
}
}
return newInstance;
}
} catch (Exception e) {
throw new IllegalArgumentException("参数格式不正确");
}
return null;
}
}
分区规则类
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.flink.core.io.SimpleVersionedSerializer;
import org.apache.flink.streaming.api.functions.sink.filesystem.BucketAssigner;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.SimpleVersionedStringSerializer;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/3/30 下午2:36
* @qq 2315290571
* @Description 自定义分区策略
*/
public class MyBucketAssigner implements BucketAssigner{
@Override
public Object getBucketId(Object o, Context context) {
// System.out.println(o.toString());
// JSONObject jsonObject = JSON.parseObject(o.toString());
User use=(User) o;
return use.getDateTime();
}
@Override
public SimpleVersionedSerializer<String> getSerializer() {
return SimpleVersionedStringSerializer.INSTANCE;
}
}
kafka数据
{"id":1006,"username":"小张","dateTime":"2022-02-03","event":{"username":"dreamJava","password":"123456"}}
{"id":1005,"username":"小童","dateTime":"2022-03-03","event":{"username":"dreamJava","password":"123456"}}
hive中的表创建以及导入
#创建对应的表
create table user_info(id int,username string,dateTime string,event_username string,event_password string) stored as parquet;
#加载hdfs parquet文件
load data inpath '/data/flink/2022-02-03/part-0-2.parquet' into table default.user_info;
load data inpath '/data/flink/2022-03-03/part-0-1.parquet' into table default.user_info;
启动presto查询hive
select * from hive.default.user_info;
14.Flink项目实战
1.热门商品热度实时统计
根据用户行为 pv 点击率,1小时的数据进行热度排序,每五分钟更新一次
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wl</groupId>
<artifactId>UserBehaviorAnalysis</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>HotShop</module>
</modules>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<encoding>UTF-8</encoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<flink.version>1.13.6</flink.version>
<kafka.version>2.7.0</kafka.version>
<lombok.verion>1.16.6</lombok.verion>
<scala.binary.version>2.11</scala.binary.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.verion}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
</project>
UserBehaviorTest.csv
POJO实体类
用户行为实体类
package com.wl.hot_shop_top.entitites;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午2:39
* @qq 2315290571
* @Description 用户行为实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class UserBehavior {
// 用户id
private Long userId;
// 商品id
private Long itemId;
// 商品类别ID
private Integer categoryId;
// 用户行为 pv、buy等
private String behavior;
// 发生的时间戳
private Long timestamp;
}
计数实体类
package com.wl.hot_shop_top.entitites;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午2:43
* @qq 2315290571
* @Description 统计实体类
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
public class ItemViewCount {
// 商品id
private Long itemId;
// 窗口的结束时间
private Long windowEnd;
// 统计数量
private Long count;
}
计算主类
package com.wl.hot_shop_top.main;
import com.wl.hot_shop_top.entitites.ItemViewCount;
import com.wl.hot_shop_top.entitites.UserBehavior;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.runtime.operators.util.AssignerWithPeriodicWatermarksAdapter;
import java.util.concurrent.TimeUnit;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午2:50
* @qq 2315290571
* @Description 计算商品的topN
*/
public class CalculateTopN {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(1);
// 从csv文件中获取数据
DataStream<String> sourceStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/UserBehaviorAnalysis/HotShop/src/main/resources/UserBehavior.csv");
// 映射成pojo并设置watermark
DataStream<UserBehavior> userBehaviorDataStream = sourceStream.map(
value -> {
String[] sourceData = value.split(",");
return new UserBehavior(Long.parseLong(sourceData[0]), Long.parseLong(sourceData[1]), Integer.parseInt(sourceData[2]), sourceData[3], Long.parseLong(sourceData[4]));
}
).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksAdapter.Strategy<>(
new BoundedOutOfOrdernessTimestampExtractor<UserBehavior>(Time.of(200, TimeUnit.MICROSECONDS)) {
@Override
public long extractTimestamp(UserBehavior userBehavior) {
return userBehavior.getTimestamp() * 1000L;
}
}
));
// 分组开窗聚合 得到每个商品的count值
DataStream<ItemViewCount> windowAggStream = userBehaviorDataStream
.filter(ub -> "pv".equals(ub.getBehavior())) // 过滤pv行为
.keyBy(UserBehavior::getItemId) // 按商品id分组
.timeWindow(Time.hours(1), Time.minutes(5))
// 聚合增量
.aggregate(new ItemCountAgg(), new WindowItemCountResult());
// 按窗口时间来输出topN
DataStream<String> resultStream = windowAggStream
.keyBy(ItemViewCount::getWindowEnd)
.process(new TOPNItem(10));
// 打印输出
resultStream.print();
// 运行
env.execute("ShopTopN");
}
}
增量类
package com.wl.hot_shop_top.main;
import com.wl.hot_shop_top.entitites.UserBehavior;
import org.apache.flink.api.common.functions.AggregateFunction;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午3:14
* @qq 2315290571
* @Description 商品增量聚合
*/
public class ItemCountAgg implements AggregateFunction<UserBehavior,Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(UserBehavior userBehavior, Long accumulator) {
return accumulator+1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return a+b;
}
}
计数类
package com.wl.hot_shop_top.main;
import com.wl.hot_shop_top.entitites.ItemViewCount;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午3:19
* @qq 2315290571
* @Description 窗口计数
*/
public class WindowItemCountResult implements WindowFunction<Long, ItemViewCount, Long, TimeWindow> {
@Override
public void apply(Long itemId, TimeWindow timeWindow, Iterable<Long> iterable, Collector<ItemViewCount> collector) throws Exception {
// 窗口结束时间
long windowEnd = timeWindow.getEnd();
// 计数
Long count = iterable.iterator().next();
collector.collect(new ItemViewCount(itemId,windowEnd,count));
}
}
状态定时器类
package com.wl.hot_shop_top.main;
import com.wl.hot_shop_top.entitites.ItemViewCount;
import org.apache.commons.compress.utils.Lists;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.sql.Timestamp;
import java.util.ArrayList;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午3:39
* @qq 2315290571
* @Description 商品topN处理
*/
public class TOPNItem extends KeyedProcessFunction<Long, ItemViewCount, String> {
// 定义 topN
private int topN;
// 定义状态
private ListState<ItemViewCount> itemViewCountListState;
public TOPNItem(int topN) {
this.topN = topN;
}
// 定义生命周期
@Override
public void open(Configuration parameters) throws Exception {
itemViewCountListState=getRuntimeContext().getListState(new ListStateDescriptor<ItemViewCount>("view-state",ItemViewCount.class));
}
@Override
public void processElement(ItemViewCount value, Context context, Collector<String> collector) throws Exception {
// 存入状态
itemViewCountListState.add(value);
// 注册定时器 等待100ms
context.timerService().registerEventTimeTimer(value.getWindowEnd()+100);
}
// 定时器
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// 定时器触发,当前收集到已有的数据,排序输出
ArrayList<ItemViewCount> itemList = Lists.newArrayList(itemViewCountListState.get().iterator());
// 排序
itemList.sort((a,b)->Long.compare(b.getCount(),a.getCount()));
// 控制台打印
StringBuilder sb = new StringBuilder();
sb.append("===============================\r\n");
sb.append("窗口结束时间").append(new Timestamp(timestamp-100)+"\r\n");
// 遍历输出
for (int i = 0; i <Math.min(topN,itemList.size()) ; i++) {
sb.append("No"+(i+1)+":\r\n")
.append("商品ID:"+itemList.get(i).getItemId()+"\r\n")
.append("热度:"+itemList.get(i).getCount()+"\r\n");
}
out.collect(sb.toString());
}
}
运行结果
===============================
窗口结束时间2017-11-26 09:05:00.0
No1:
商品ID:5051027
热度:3
No2:
商品ID:3493253
热度:3
No3:
商品ID:4261030
热度:3
No4:
商品ID:4894670
热度:2
No5:
商品ID:3781391
热度:2
No6:
商品ID:1591432
热度:2
No7:
商品ID:3114069
热度:2
No8:
商品ID:1932424
热度:2
No9:
商品ID:2288408
热度:2
No10:
商品ID:404802
热度:2
===============================
窗口结束时间2017-11-26 09:10:00.0
No1:
商品ID:812879
热度:5
No2:
商品ID:2600165
热度:4
No3:
商品ID:2828948
热度:4
No4:
商品ID:2338453
热度:4
No5:
商品ID:4261030
热度:4
No6:
商品ID:3624285
热度:4
No7:
商品ID:2563440
热度:4
No8:
商品ID:5128095
热度:3
No9:
商品ID:3990741
热度:3
No10:
商品ID:5142562
热度:3
===============================
窗口结束时间2017-11-26 09:15:00.0
No1:
商品ID:812879
热度:7
No2:
商品ID:138964
热度:5
No3:
商品ID:4568476
热度:5
No4:
商品ID:2338453
热度:5
No5:
商品ID:3624285
热度:5
No6:
商品ID:2563440
热度:5
No7:
商品ID:2600165
热度:4
No8:
商品ID:2331370
热度:4
No9:
商品ID:1591432
热度:4
No10:
商品ID:3845720
热度:4
===============================
窗口结束时间2017-11-26 09:20:00.0
No1:
商品ID:812879
热度:8
No2:
商品ID:2338453
热度:8
No3:
商品ID:2563440
热度:7
No4:
商品ID:138964
热度:6
No5:
商品ID:3624285
热度:6
No6:
商品ID:4568476
热度:5
No7:
商品ID:3783464
热度:5
No8:
商品ID:3845720
热度:5
No9:
商品ID:2828948
热度:5
No10:
商品ID:4261030
热度:5
.................
table api的实现方式
package com.wl.hot_shop_top.main.table;
import com.wl.hot_shop_top.entitites.UserBehavior;
import javafx.scene.control.Slider;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.runtime.operators.util.AssignerWithPeriodicWatermarksAdapter;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
import java.util.concurrent.TimeUnit;
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.lit;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 上午9:49
* @qq 2315290571
* @Description table Api 流式处理
*/
public class CalculateTopN_Table {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 设置表的运行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取并转换为 pojo实体类
DataStream<UserBehavior> sourceStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/UserBehaviorAnalysis/HotShop/src/main/resources/UserBehavior.csv")
.map(value -> {
String[] sourceData = value.split(",");
return new UserBehavior(Long.parseLong(sourceData[0]), Long.parseLong(sourceData[1]), Integer.parseInt(sourceData[2]), sourceData[3], Long.parseLong(sourceData[4]));
}).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksAdapter.Strategy<>(
new BoundedOutOfOrdernessTimestampExtractor<UserBehavior>(Time.of(200, TimeUnit.MICROSECONDS)) {
@Override
public long extractTimestamp(UserBehavior userBehavior) {
return userBehavior.getTimestamp() * 1000L;
}
}
));
// 将流数据转换成表
Table dataTable = tableEnv.fromDataStream(sourceStream, $("itemId"), $("behavior"), $("timestamp").rowtime().as("ts"));
// 分组开窗
Table windowAggTable = dataTable.filter($("behavior").isEqual("pv"))
.window(Slide.over(lit(1).hours()).every(lit(5).minutes()).on($("ts")).as("w"))
.groupBy($("itemId"), $("w"))
.select($("itemId"), $("w").end().as("windowEnd"), $("itemId").count().as("cnt"));
// 创建临时表
DataStream<Row> aggStream = tableEnv.toAppendStream(windowAggTable, Row.class);
tableEnv.createTemporaryView("agg", aggStream, $("itemId"), $("windowEnd"), $("cnt"));
// sql查询
Table resultTable = tableEnv.sqlQuery("select * from " +
" (select *,row_number() over (partition by windowEnd order by cnt desc) as row_num from agg)" +
"where row_num<=5"
);
// 纯sql实现
// 创建临时表
tableEnv.createTemporaryView("dataTable", sourceStream, $("itemId"), $("behavior"), $("timestamp").rowtime().as("ts"));
Table resultSqlTable = tableEnv.sqlQuery("select * from " +
"(select *,row_number() over (partition by windEnd order by cnt desc) as row_num " +
"from (" +
"select itemId,count(itemId) as cnt,HOP_END(ts,interval '5' minute ,interval '1' hour ) as windEnd " +
"from dataTable where behavior = 'pv' group by itemId,HOP(ts,interval '5' minute ,interval '1' hour )" +
")" +
") where row_num<=5"
);
// 打印结果
// tableEnv.toRetractStream(resultTable, Row.class).print();
tableEnv.toRetractStream(resultSqlTable, Row.class).print();
// 执行
env.execute("tableApi execute");
}
}
2.热门页面统计
在10分钟内统计用户访问最多的页面,五秒钟更新一次,从日志中提取
数据源-apache.log(见1 已经下载的文件)
POJO类
日志事件类
package com.wl.entitites;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午2:35
* @qq 2315290571
* @Description 日志实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class LogEvent {
// ip地址
private String ip;
// 用户id
private String userId;
// 事件时间戳
private Long timestamp;
// 请求方法
private String method;
// 请求路径
private String url;
}
页面统计类
package com.wl.entitites;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午2:43
* @qq 2315290571
* @Description 视图实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PageViewCount {
// 请求路径
private String url;
// 计数
private Long count;
// 窗口结束时间
private Long windowEnd;
}
计算主类
增量聚合类
package com.wl.main;
import com.wl.entitites.LogEvent;
import org.apache.flink.api.common.functions.AggregateFunction;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午3:09
* @qq 2315290571
* @Description 增量页面
*/
public class AggPageCount implements AggregateFunction<LogEvent,Long,Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(LogEvent logEvent, Long accumulator) {
return accumulator+1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return a+b;
}
}
统计topN类
package com.wl.main;
import com.wl.entitites.PageViewCount;
import org.apache.commons.compress.utils.Lists;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午3:26
* @qq 2315290571
* @Description 热门页面计算
*/
public class HotPageTopN extends KeyedProcessFunction<Long, PageViewCount, String> {
// 定义topN
private int topN;
// 定义状态
private ListState<PageViewCount> listState;
public HotPageTopN(int topN) {
this.topN = topN;
}
// 定义生命周期
@Override
public void open(Configuration parameters) throws Exception {
listState = getRuntimeContext().getListState(new ListStateDescriptor<PageViewCount>("pageCount", PageViewCount.class));
}
@Override
public void processElement(PageViewCount pageViewCount, Context context, Collector<String> collect) throws Exception {
listState.add(pageViewCount);
// 注册定时器
context.timerService().registerEventTimeTimer(pageViewCount.getWindowEnd() + 600);
}
// 定时器执行
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// 获取list
ArrayList<PageViewCount> pageCountList = Lists.newArrayList(listState.get().iterator());
// 按照count排序
pageCountList.sort((a, b) -> Long.compare(b.getCount(), a.getCount()));
StringBuffer sb = new StringBuffer();
sb.append("===========================\r\n")
.append("窗口结束时间:" + (timestamp - 600) + "\r\n")
.append("===========================\r\n");
// 格式化输出
for (int i = 0; i < Math.min(topN, pageCountList.size()); i++) {
sb.append("热门页面URL:"+pageCountList.get(i).getUrl()+"\r\n")
.append("热度:"+pageCountList.get(i).getCount()+"\r\n");
}
// 睡眠一秒 控制台打印的结果不会乱
Thread.sleep(1000);
out.collect(sb.toString());
}
}
页面统计计数类
package com.wl.main;
import com.wl.entitites.PageViewCount;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午3:10
* @qq 2315290571
* @Description 统计页面
*/
public class PageCountWindow implements WindowFunction<Long, PageViewCount, String, TimeWindow> {
@Override
public void apply(String url, TimeWindow timeWindow, Iterable<Long> iterable, Collector<PageViewCount> collect) throws Exception {
// 计数
Long count = iterable.iterator().next();
// 窗口结束时间
Long windowEnd = timeWindow.getEnd();
collect.collect(new PageViewCount(url, count, windowEnd));
}
}
计算统计主类
package com.wl.main;
import com.wl.entitites.LogEvent;
import com.wl.entitites.PageViewCount;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.runtime.operators.util.AssignerWithPeriodicWatermarksAdapter;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.text.SimpleDateFormat;
import java.util.concurrent.TimeUnit;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午2:48
* @qq 2315290571
* @Description 计算热门页面
*/
public class CalculateHotPage {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(1);
SimpleDateFormat sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");
// 获取数据源
DataStream<String> sourceStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/UserBehaviorAnalysis/HotPage/src/main/resources/apache.log");
// 转换成POJO 并注册时间戳
DataStream<LogEvent> logEventStream = sourceStream.map(
value -> {
String[] logEventStr = value.split(" ");
return new LogEvent(logEventStr[0], logEventStr[1], (sdf.parse(logEventStr[3])).getTime(), logEventStr[5], logEventStr[6]);
}
).assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarksAdapter.Strategy<>(
new BoundedOutOfOrdernessTimestampExtractor<LogEvent>(Time.of(1, TimeUnit.MINUTES)) {
@Override
public long extractTimestamp(LogEvent logEvent) {
return logEvent.getTimestamp();
}
}
)
);
// 分组开窗
DataStream<PageViewCount> pageCountStream=logEventStream.filter(logEvent -> "GET".equals(logEvent.getMethod()))
.keyBy(LogEvent::getUrl)
.window(SlidingEventTimeWindows.of(Time.minutes(10),Time.seconds(6)))
.aggregate(new AggPageCount(),new PageCountWindow());
// 计算统计
pageCountStream.keyBy(PageViewCount::getWindowEnd)
.process(new HotPageTopN(5)).print();
env.execute("hotPage");
}
}
运行结果
===========================
窗口结束时间:1431828306000
===========================
热门页面URL:/reset.css
热度:2
热门页面URL:/presentations/logstash-monitorama-2013/images/kibana-search.png
热度:1
热门页面URL:/presentations/logstash-monitorama-2013/images/redis.png
热度:1
热门页面URL:/blog/tags/puppet?flav=rss20
热度:1
热门页面URL:/style2.css
热度:1
===========================
窗口结束时间:1431828312000
===========================
热门页面URL:/reset.css
热度:3
热门页面URL:/blog/tags/puppet?flav=rss20
热度:2
热门页面URL:/style2.css
热度:2
热门页面URL:/presentations/logstash-monitorama-2013/images/kibana-dashboard2.png
热度:1
热门页面URL:/presentations/logstash-monitorama-2013/images/redis.png
热度:1
===========================
窗口结束时间:1431828318000
===========================
热门页面URL:/reset.css
热度:3
热门页面URL:/blog/tags/puppet?flav=rss20
热度:2
热门页面URL:/style2.css
热度:2
热门页面URL:/test.xml
热度:1
热门页面URL:/presentations/logstash-monitorama-2013/images/kibana-dashboard2.png
热度:1
===========================
窗口结束时间:1431828324000
===========================
热门页面URL:/reset.css
热度:3
热门页面URL:/favicon.ico
热度:2
热门页面URL:/images/web/2009/banner.png
热度:2
热门页面URL:/blog/tags/puppet?flav=rss20
热度:2
热门页面URL:/style2.css
热度:2
===========================
窗口结束时间:1431828330000
===========================
热门页面URL:/reset.css
热度:3
热门页面URL:/favicon.ico
热度:2
热门页面URL:/images/jordan-80.png
热度:2
热门页面URL:/images/web/2009/banner.png
热度:2
热门页面URL:/blog/tags/puppet?flav=rss20
热度:2
...............
代码升级
在实际开发中,水位线的时间不能设置太长,如果水位线时间太长就会出现延迟刷新结果。我们可以使用flink的三种处理延迟数据。首先将水位线的时间设置为1s,然后在增量聚合的时候进行迟到数据的处理。还要对计算topN的类进行修改,定义一个清除以往状态的定时器,并且修改状态存储的数据类型为MapState。
计算主类
package com.wl.improvement;
import com.wl.entitites.LogEvent;
import com.wl.entitites.PageViewCount;
import com.wl.main.AggPageCount;
import com.wl.main.HotPageTopN;
import com.wl.main.PageCountWindow;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming.runtime.operators.util.AssignerWithPeriodicWatermarksAdapter;
import org.apache.flink.util.OutputTag;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.text.SimpleDateFormat;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
import java.util.regex.Pattern;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午4:46
* @qq 2315290571
* @Description 统计热门页面
*/
public class HotPageCalculate {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置并行度
env.setParallelism(1);
SimpleDateFormat sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss");
// 获取数据源
Properties pro = new Properties();
pro.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "wl:9092");
pro.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "flink");
// DataStream<String> sourceStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/UserBehaviorAnalysis/HotPage/src/main/resources/apache.log");
DataStream<String> sourceStream = env.addSource(new FlinkKafkaConsumer<String>("flink", new SimpleStringSchema(), pro));
// 转换成POJO 并注册时间戳
DataStream<LogEvent> logEventStream = sourceStream.map(
value -> {
String[] logEventStr = value.split(" ");
return new LogEvent(logEventStr[0], logEventStr[1], (sdf.parse(logEventStr[3])).getTime(), logEventStr[5], logEventStr[6]);
}
).assignTimestampsAndWatermarks(
new AssignerWithPeriodicWatermarksAdapter.Strategy<>(
// 乱序数据 允许最多迟到一秒钟
new BoundedOutOfOrdernessTimestampExtractor<LogEvent>(Time.of(1, TimeUnit.SECONDS)) {
@Override
public long extractTimestamp(LogEvent logEvent) {
return logEvent.getTimestamp();
}
}
)
);
logEventStream.print("data");
// 定义一个侧输出流
OutputTag<LogEvent> lateTag = new OutputTag<LogEvent>("lateData") {
};
// 分组开窗
SingleOutputStreamOperator<PageViewCount> pageCountStream = logEventStream.filter(logEvent -> "GET".equals(logEvent.getMethod()))
.filter(data -> {
String regex = "^((?!\\.(css|js|png|ico)$).)*$";
return Pattern. matches(regex, data.getUrl());
})
.keyBy(LogEvent::getUrl)
.window(SlidingEventTimeWindows.of(Time.minutes(10), Time.seconds(5)))
// 多等一分钟迟到数据 再关闭窗口
.allowedLateness(Time.minutes(1))
// 将迟到的数据存到侧输出流
.sideOutputLateData(lateTag)
.aggregate(new AggPageCount(), new PageCountWindow());
pageCountStream.print("agg");
// 打印迟到数据
pageCountStream.getSideOutput(lateTag).print("lateData");
// 计算统计
pageCountStream.keyBy(PageViewCount::getWindowEnd)
.process(new HotPageTopN(5)).print();
env.execute("hotPage");
}
}
topN的计算类
package com.wl.main;
import com.wl.entitites.PageViewCount;
import org.apache.commons.compress.utils.Lists;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.ArrayList;
import java.util.Map;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/21 下午3:26
* @qq 2315290571
* @Description 热门页面计算
*/
public class HotPageTopN extends KeyedProcessFunction<Long, PageViewCount, String> {
// 定义topN
private int topN;
// 定义状态
private MapState<String, Long> mapState;
public HotPageTopN(int topN) {
this.topN = topN;
}
// 定义生命周期
@Override
public void open(Configuration parameters) throws Exception {
mapState = getRuntimeContext().getMapState(new MapStateDescriptor<String, Long>("pageCount", String.class, Long.class));
}
@Override
public void processElement(PageViewCount pageViewCount, Context context, Collector<String> collect) throws Exception {
mapState.put(pageViewCount.getUrl(), pageViewCount.getCount());
// 注册定时器
context.timerService().registerEventTimeTimer(pageViewCount.getWindowEnd() + 1);
// 注册一个1分钟以后的定时器 清空状态
context.timerService().registerEventTimeTimer(pageViewCount.getWindowEnd() + 60*1000L);
}
// 定时器执行
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
// 判断是否到了窗口关闭清理的时间 如果是需要清空状态返回
if (timestamp==ctx.getCurrentKey()+60*1000L){
mapState.clear();
return;
}
// 获取list
ArrayList<Map.Entry<String, Long>> pageCountList = Lists.newArrayList(mapState.entries().iterator());
// 按照count排序
pageCountList.sort((a, b) -> Long.compare(b.getValue(), a.getValue()));
StringBuffer sb = new StringBuffer();
sb.append("===========================\r\n")
.append("窗口结束时间:" + (timestamp - 1) + "\r\n")
.append("===========================\r\n");
// 格式化输出
for (int i = 0; i < Math.min(topN, pageCountList.size()); i++) {
sb.append("热门页面URL:" + pageCountList.get(i).getKey() + "\r\n")
.append("热度:" + pageCountList.get(i).getValue() + "\r\n");
}
Thread.sleep(100);
out.collect(sb.toString());
}
}
3.实时流量统计
pv统计
看每小时用户的点击率,因为无需考虑用户的影响,不需要keyBy,但是如果不分组使用windowALL方法就会把任务都放在一个分区,并行度为就1了。因为分组是按照哈希算法来进行分区的,我们可以按照随机数生成来进行分区,然后增量聚合并开窗整合,最后汇总数据。
POJO类
页面统计类
package com.wl.pv.entitites;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/22 上午10:59
* @qq 2315290571
* @Description pv实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class PageViewCount {
// 请求路径
private String url;
// 计数
private Long count;
// 窗口结束时间
private Long windowEnd;
}
用户行为类
package com.wl.pv.entitites;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.ToString;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/17 下午2:39
* @qq 2315290571
* @Description 用户行为实体类
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class UserBehavior {
// 用户id
private Long userId;
// 商品id
private Long itemId;
// 商品类别ID
private Integer categoryId;
// 用户行为 pv、buy等
private String behavior;
// 发生的时间戳
private Long timestamp;
}
计算主类
增量聚合类
package com.wl.pv.main;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/22 上午11:52
* @qq 2315290571
* @Description 增量聚合pv
*/
public class AggPvCount implements AggregateFunction<Tuple2<Integer,Long>,Long,Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Tuple2<Integer, Long> integerLongTuple2, Long accumulator) {
return accumulator+1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return a+b;
}
}
pv计数窗口类
package com.wl.pv.main;
import com.wl.pv.entitites.PageViewCount;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/22 上午11:52
* @qq 2315290571
* @Description pv计数
*/
public class PvCountWindow implements WindowFunction<Long, PageViewCount,Integer, TimeWindow> {
@Override
public void apply(Integer integer, TimeWindow timeWindow, Iterable<Long> iterable, Collector<PageViewCount> collect) throws Exception {
collect.collect(new PageViewCount(integer.toString(),iterable.iterator().next(),timeWindow.getEnd()));
}
}
汇总类
package com.wl.pv.main;
import com.wl.pv.entitites.PageViewCount;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/22 上午11:53
* @qq 2315290571
* @Description 汇总聚合
*/
public class TotalPvCount extends KeyedProcessFunction<Long, PageViewCount, PageViewCount> {
private ValueState<Long> valueState;
@Override
public void open(Configuration parameters) throws Exception {
valueState = getRuntimeContext().getState(new ValueStateDescriptor<Long>("countPv", Long.class));
}
@Override
public void processElement(PageViewCount pageViewCount, Context context, Collector<PageViewCount> collect) throws Exception {
// Long totalCount = valueState.value();
// if (null == totalCount) {
// totalCount = 0L;
// valueState.update(totalCount);
// }
valueState.update(pageViewCount.getCount()+(valueState.value() == null ? 0L : valueState.value()));
context.timerService().registerEventTimeTimer(pageViewCount.getWindowEnd() + 1);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<PageViewCount> out) throws Exception {
out.collect(new PageViewCount("pv", valueState.value(), timestamp - 1));
valueState.clear();
}
}
计数pv主类
package com.wl.pv.main;
import com.wl.pv.entitites.PageViewCount;
import com.wl.pv.entitites.UserBehavior;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.runtime.operators.util.AssignerWithPeriodicWatermarksAdapter;
import java.util.Random;
import java.util.concurrent.TimeUnit;
/**
* @author 没有梦想的java菜鸟
* @Date 创建时间:2022/6/22 上午11:05
* @qq 2315290571
* @Description 计算pv
*/
public class CalculatePv {
public static void main(String[] args) throws Exception {
// 获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(4);
// 获取数据源的数据
DataStream<String> sourceStream = env.readTextFile("/Users/wangliang/Documents/ideaProject/UserBehaviorAnalysis/HotStream/src/main/resources/UserBehavior.csv");
// 映射pojo和注册水位线
DataStream<UserBehavior> userBehaviorStream = sourceStream.map(
value -> {
String[] sourceData = value.split(",");
return new UserBehavior(Long.parseLong(sourceData[0]), Long.parseLong(sourceData[1]), Integer.parseInt(sourceData[2]), sourceData[3], Long.parseLong(sourceData[4]));
}
).assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarksAdapter.Strategy<>(
new BoundedOutOfOrdernessTimestampExtractor<UserBehavior>(Time.of(200, TimeUnit.MICROSECONDS)) {
@Override
public long extractTimestamp(UserBehavior userBehavior) {
return userBehavior.getTimestamp() * 1000L;
}
}
));
// 计算pv
DataStream<PageViewCount> aggStream = userBehaviorStream.filter(userBehavior -> "pv".equals(userBehavior.getBehavior()))
.map(new MapFunction<UserBehavior, Tuple2<Integer, Long>>() {
@Override
public Tuple2<Integer, Long> map(UserBehavior userBehavior) throws Exception {
Random random = new Random();
return new Tuple2(random.nextInt(10), 1L);
}
})
.keyBy(data -> data.f0)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.aggregate(new AggPvCount(), new PvCountWindow());
// 汇总
aggStream.keyBy(PageViewCount::getWindowEnd)
.process(new TotalPvCount()).print();
env.execute("pv count");
}
}
运行结果
2> PageViewCount(url=pv, count=41890, windowEnd=1511661600000)
1> PageViewCount(url=pv, count=48649, windowEnd=1511676000000)
2> PageViewCount(url=pv, count=50838, windowEnd=1511679600000)
3> PageViewCount(url=pv, count=48022, windowEnd=1511665200000)
2> PageViewCount(url=pv, count=52552, windowEnd=1511686800000)
4> PageViewCount(url=pv, count=47298, windowEnd=1511668800000)
3> PageViewCount(url=pv, count=13, windowEnd=1511694000000)
4> PageViewCount(url=pv, count=44499, windowEnd=1511672400000)
2> PageViewCount(url=pv, count=48292, windowEnd=1511690400000)
4> PageViewCount(url=pv, count=52296, windowEnd=1511683200000)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号