Hive的学习
1.Hive的安装
1.下载hive安装包
wget --no-check-certificate https://dlcdn.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz
2.解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz
3.配置环境变量
vim /etc/profile
添加以下内容
#hive
export HIVE_HOME=/home/wl/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin

让配置文件生效
source /etc/profile
4.初始化元数据库
来到安装目录 /home/wl/apache-hive-3.1.2-bin,输入以下指令初始化元数据库
bin/schematool -dbType derby -initSchema
2.安装mysql
1.查看当前系统是否安装过mysql
rpm -qa|grep mariadb
如过有,执行以下命令卸载
rpm -e --nodeps mariadb-libs

2.下载安装mysql
执行以下命令下载mysql安装包
wget https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.36-1.el7.x86_64.rpm-bundle.tar
下载完成后,解压
tar -xf mysql-5.7.36-1.el7.x86_64.rpm-bundle.tar

然后依次解压以下几个rpm包
rpm -ivh mysql-community-common-5.7.36-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.36-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.36-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.36-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.36-1.el7.x86_64.rpm
3.删除旧数据
如果/etc/my.cnf里面的datadir 指向的目录下的有内容就删掉
查看/etc/my.cnf里面的内容
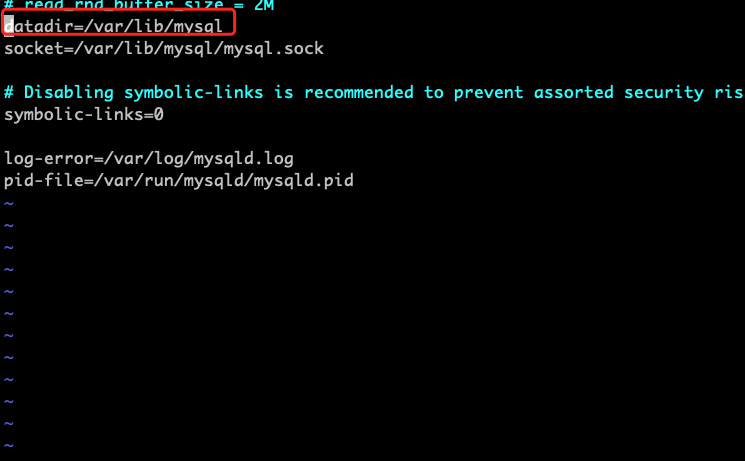
找到 /var/lib/mysql 目录,ls查看,如果有内容 就删除掉

4.初始化数据库
初始化数据库
sudo mysqld --initialize --user=mysql
查看临时生成的root用户的密码
cat /var/log/mysqld.log
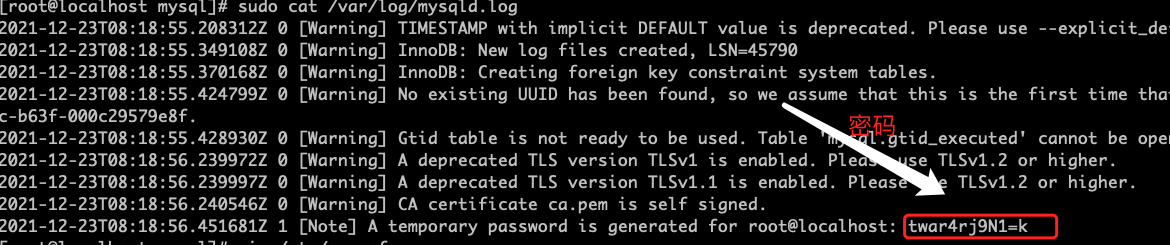
启动mysql
systemctl start mysqld
进入mysql中
mysql -u root -p
修改root用户的密码
mysql> set password = password("新密码");
修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
说明:这样做的好处就是,navicat这些可视化工具可以连接了
update mysql.user set host='%' where user='root';
flush privileges;
5.下载mysql连接驱动包
下载
wget https://cdn.mysql.com/archives/mysql-connector-java-5.1/mysql-connector-java-5.1.47.tar.gz
解压
tar -zxvf mysql-connector-java-5.1.47.tar.gz
进入到目录里面找到 mysql-connector-java-5.1.47.jar,将其移动到hive的lib目录下
mv mysql-connector-java-5.1.47.jar /home/wl/apache-hive-3.1.2-bin/lib/
3.配置Metastore到mysql
1.新增配置文件
在hive的conf目录下新建hive-site.xml,添加以下内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://wlwl:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>wl990922</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!--查询时展示表头-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.
</description>
</property>
<!--查询时展示当前数据库-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.
</description>
</property>
</configuration>
2.登录mysql并新建Hive元数据库并退出
mysql>create database metastore;
mysql>quit
3.初始化Hive元数据库
bin/schematool -initSchema -dbType mysql -verbose
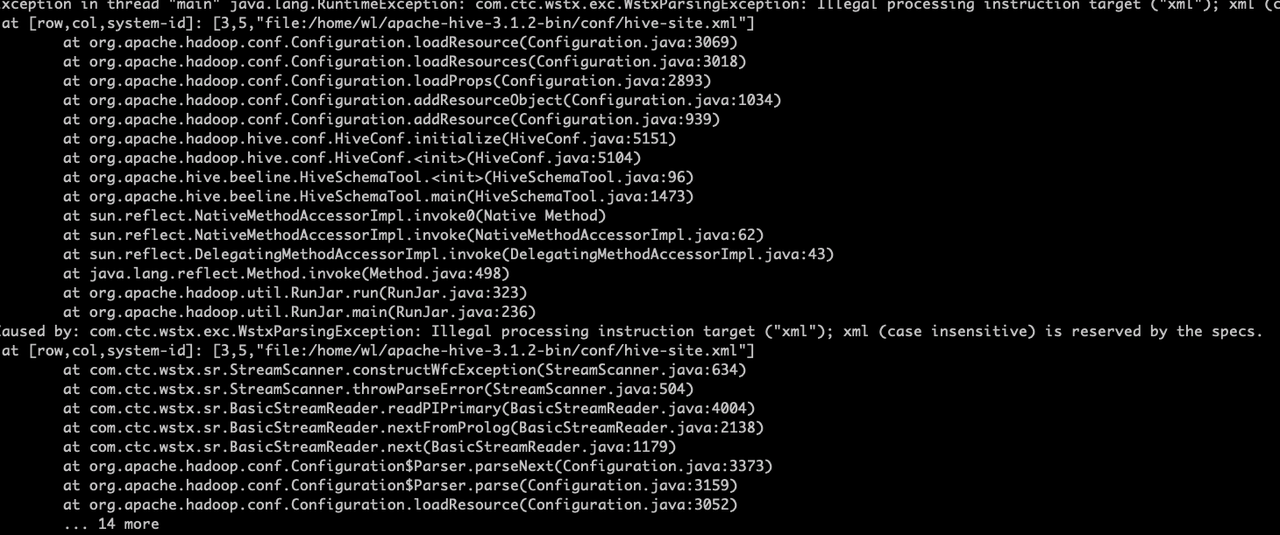
4.使用元数据服务的方式访问Hive
在hive-site.xml文件中添加以下配置
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property>
启动 metastore
bin/hive --service metastore
注意: 启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作
5.Hive的数据类型
基本数据类型和java相似
测试插入一条数据
往里面insert值得时候出现以下错误
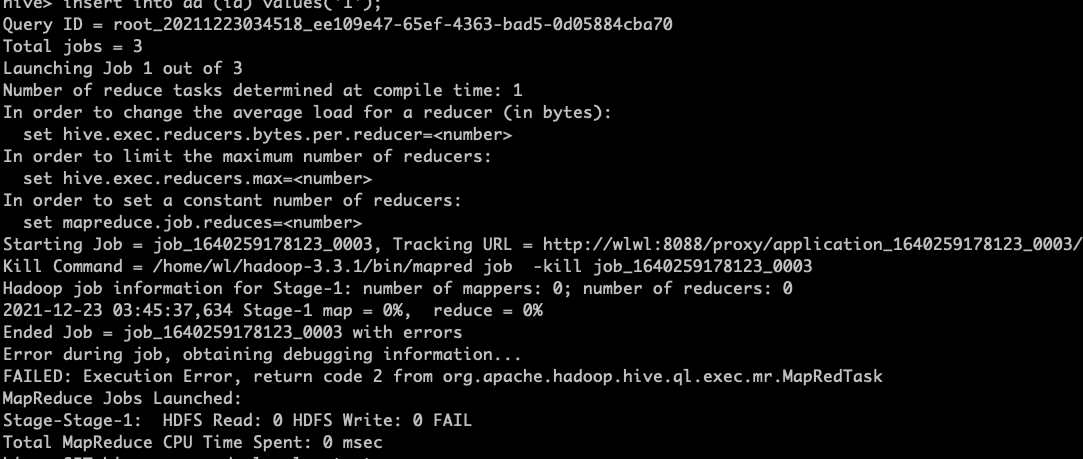
执行
SET hive.exec.mode.local.auto=true;就可以了
6.DDL数据定义
1.创建数据库
语法
CREATE DATABASE [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
说明:[]中的数据可有可无
-
[IF NOT EXISTS]:如果不存在就创建,避免创建时存在的错误 -
[COMMENT database_comment]:字段注释说明 -
[LOCATION hdfs_path]:指定数据库在HDFS上存放的位置
create database if not exists testbase ; #如果不存在此数据库则创建
2.查看数据库
查看数据库
show databases;
查看数据库信息
desc database test;
显示数据库详细信息
desc database extended test;
切换数据库
use test;
3.删除数据库
删除空数据库
drop database test;
如果数据库里面不为空,则使用 cascade关键字强制删除
drop database test cascade;
4.建表
建外部表,外部表的特征就是在删除表的时候,外部表只删除元数据,不删除HDFS上面的数据。
建表的时候使用以下语句,可以让存储的数据以 逗号分隔
row format delimited fields terminated by ',';
1.建一个外部表
create external table externalTest(id string,name string);
去mysql中查看TBLS这个表

删除外部表
drop table externalTest;
再次查看 mysql中的TBLS和HDFS上面的数据


发现只是删除了元数据,HDFS上面的数据还在
2.建一个管理表(内部表)
create table manage(id string);

删除管理表
drop table manage;
再次查看 mysql中的TBLS和HDFS上面的数据


发现元数据和HDFS上的数据都不在了
3. 管理表和外部表的互相转换
查询表的类型
des formatted aa;
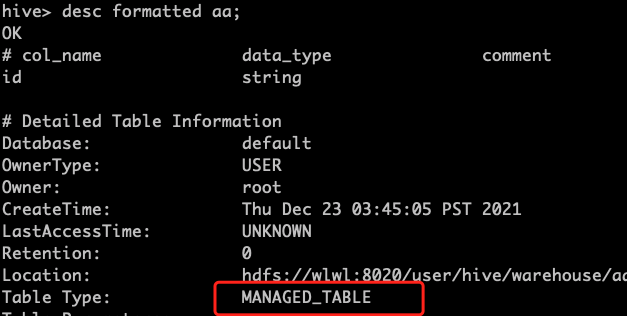
将其转换为外部表
alter table aa set tblproperties ('EXTERNAL'='TRUE');
在mysql中查看表的类型

4.修改表名
alter table aa rename to aa_test;
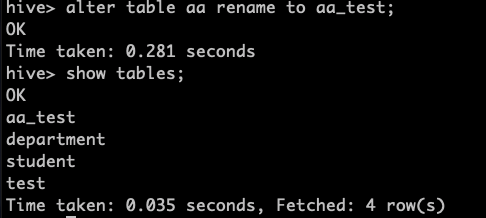
5.一些表的操作
添加列
alter table test add columns(name string);
查询表结构
desc test
更新列
alter table test change column id test_id string;
替换列
alter table test replace columns(test_id string,test_name string);
7.DML数据操作
1.数据导入
load data [local] inpath '数据的 path' [overwrite] into table test [partition (partcol1=val1,...)];
参数说明:
-
load data:表示加载数据 -
local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表 -
inpath:表示加载数据的路径 -
overwrite:表示覆盖表中已有数据,否则表示追加 -
into table:表示加载到哪张表 -
student:表示具体的表 -
partition:表示上传到指定分区
1.加载本地数据到hive中
load data local inpath '/home/wl/hadoop-3.3.1/load.txt' into table default.load_test;


2.加载HDFS文件到hive中
先上传本地文件到HDFS
dfs -put '/home/wl/hadoop-3.3.1/load2.txt' /;

从HDFS上加载数据到hive中
load data inpath '/load2.txt' into table default.load_test;
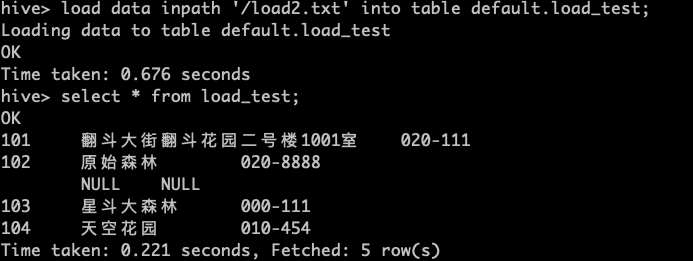
3.加载数据覆盖表中已有的数据
先上传本地文件到HDFS上
dfs -put '/home/wl/hadoop-3.3.1/load3.txt' /;
加载数据覆盖表中已有的数据
load data inpath '/load3.txt' overwrite into table default.load_test;
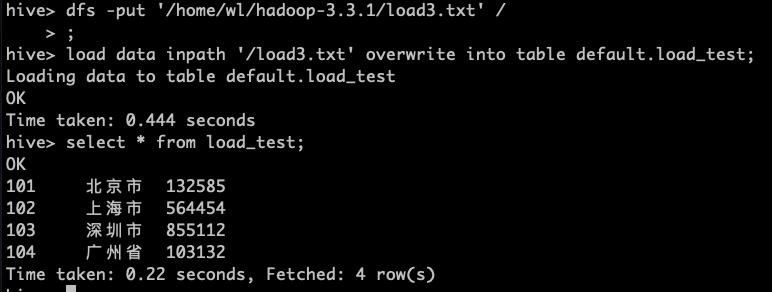
4.通过查询语句向表中插入数据
根据单张表中的数据,插入数据
insert into table test2 select id from test;
insert into:以追加数据的方式插入到表或分区,原有数据不会删除
insert overwrite:会覆盖表中已存在的数据
多表插入数据
> from test
> insert into table test3
> select id
> insert into table test2
> select id;
根据查询结果来创建表
create table if not exists student3 as select id, name from student;
Import 数据到指定 Hive 表中
import table student2 from '/user/hive/warehouse/export/student';
2.数据导出
1.insert导出
将查询的结果导出到本地
insert overwrite local directory '/home/wl/data/test' select * from test;
再去本地文件夹查看一下
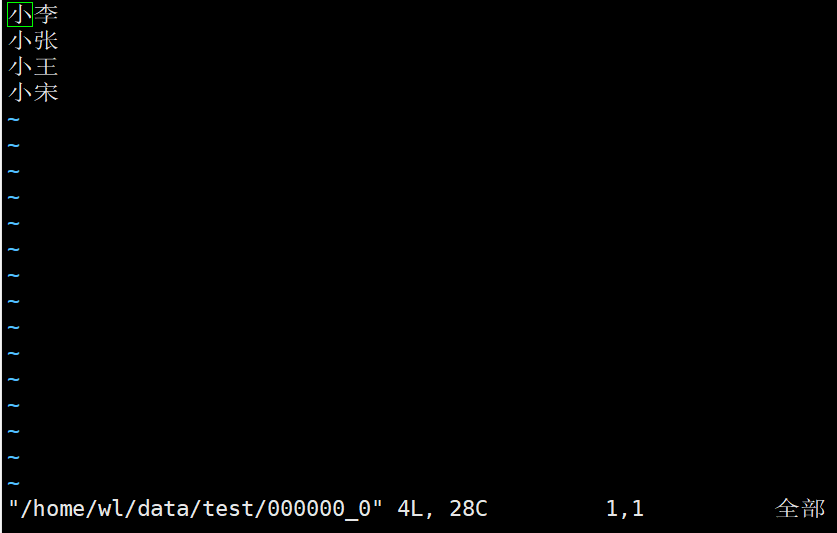
导出成功
将查询结果导出并格式化到本地
insert overwrite local directory '/home/wl/data/test2' row format delimited fields terminated by ',' select * from test4;
再去看看本地文件
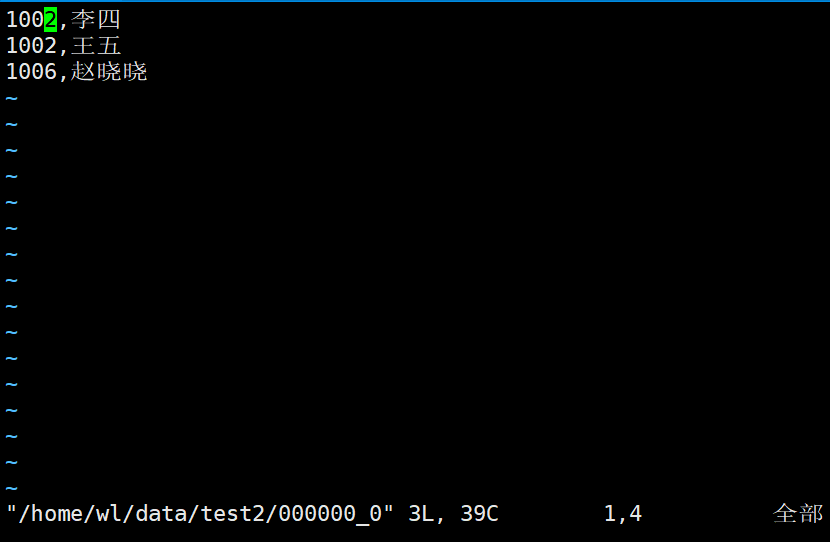
将查询结果格式化导出到HDFS上面
insert overwrite directory '/test4' row format delimited fields terminated by ',' select * from test4;
查看一下HDFS上是否有


2. export命令导出到本HDFS
export table test4 to '/tes4test4';

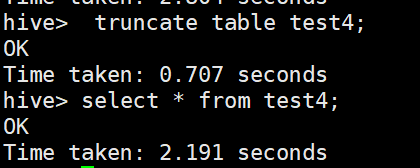
3. 清除表中数据(Truncate)
truncate table test4;
注意:Truncate 只能删除管理表,不能删除外部表中数据
8.分区表和分桶表
1.分区表
所谓分区表,就是在HDFS上进行分目录,分区表在一定程度上加快了查找效率,因为加入了分区,则不需要进行全表扫描了
下面来用案例解释一下分区表
应用场景: 假设一天的数据很大,需要按照时间段来存放,可以使用分区进行管理
1.创建一个分区表
>create table day01(id string,name string,address string)
> partitioned by (day string)
> row format delimited fields terminated by ',';
2.准备数据
在本地写三个文件的数据
day01.txt
1001,胡图图,翻斗花园1001
1002,胡英俊,翻斗花园1002
1003,牛爷爷,翻斗花园1003
day02.txt
1111,张三,北京市
2222,李四,北京市
3333,王五,北京市
day03.txt
0001,测试01,测试地址01
0002,测试02,测试地址02
0003,测试03,测试地址03
3.加载数据到分区表
load data local inpath '/home/wl/data/day01.txt' into table day01 partition(day='2021-12-27');
load data local inpath '/home/wl/data/day02.txt' into table day01 partition(day='2021-12-26');
load data local inpath '/home/wl/data/day03.txt' into table day01 partition(day='2021-12-25');
查看一下HDFS上面的目录结构,发现是按照我们分区规则进行存放的
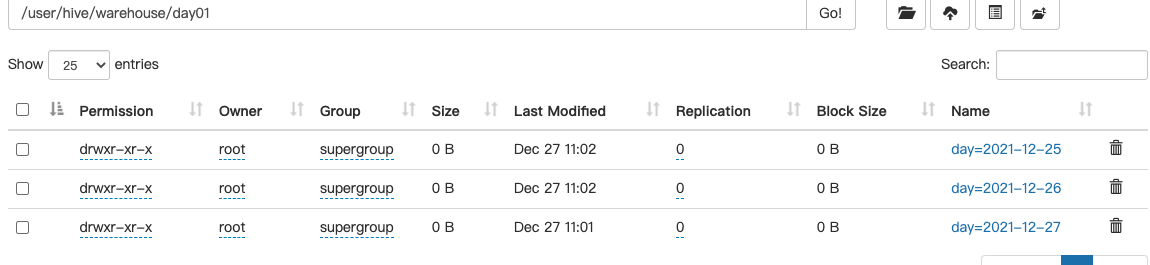

按分区查找一下数据
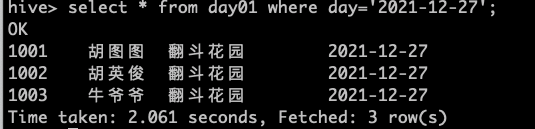
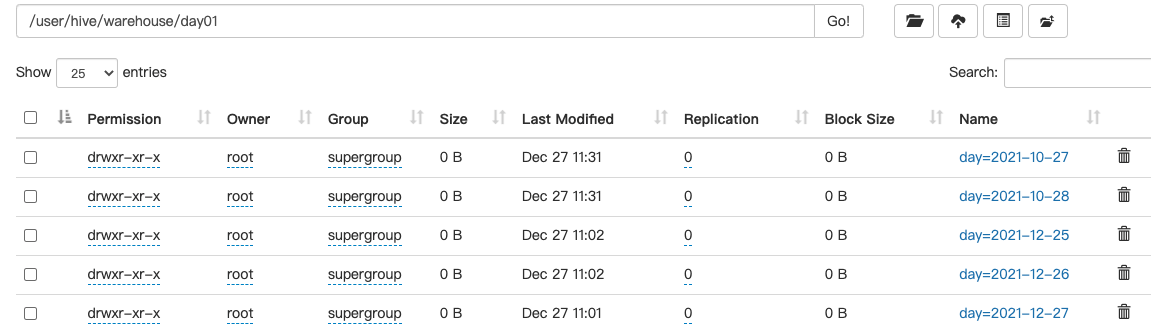
4.添加分区
alter table day01 add partition(day='2021-10-27') partition(day='2021-10-28');
注意:两个partition 之间 一定要用空格隔开!!!
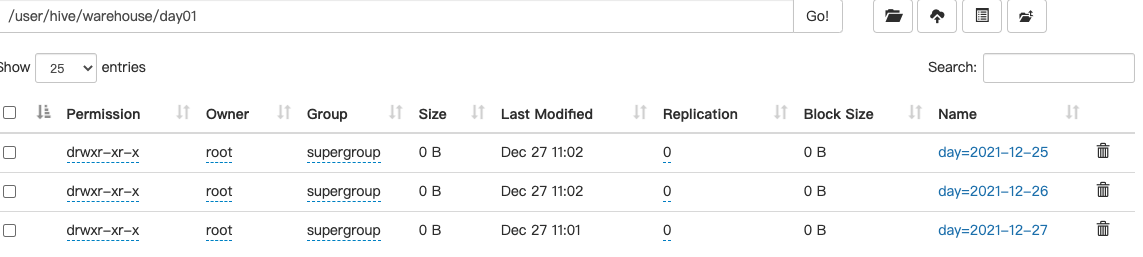
5.删除分区
alter table day01 drop partition(day='2021-10-27'),partition(day='2021-10-28');
注意:两个partition 之间 一定要用逗号隔开!!!

6.查看分区
查看有多少个分区
show partitions day01;
查看分区表的结构
desc formatted day01;
7.二级分区
当数据量特别大,希望按照小时来分区,这个时候就用到了二级分区
创建一个二级分区表
>create table day02(id string,name string,address string)
>partitioned by (day string,hours string)
>row format delimited fields terminated by ',';
加载数据进分区表
load data local inpath '/home/wl/data/day02.txt' into table day02 partition(day='2021-12-27',hours='10');
load data local inpath '/home/wl/data/day01.txt' into table day02 partition(day='2021-12-27',hours='18');
load data local inpath '/home/wl/data/day03.txt' into table day02 partition(day='2021-12-27',hours='13');
查看HDFS上的目录结构
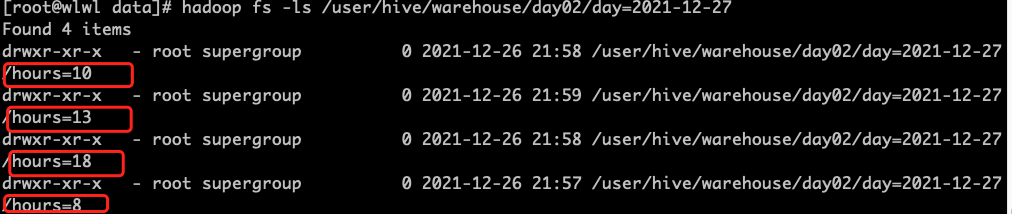
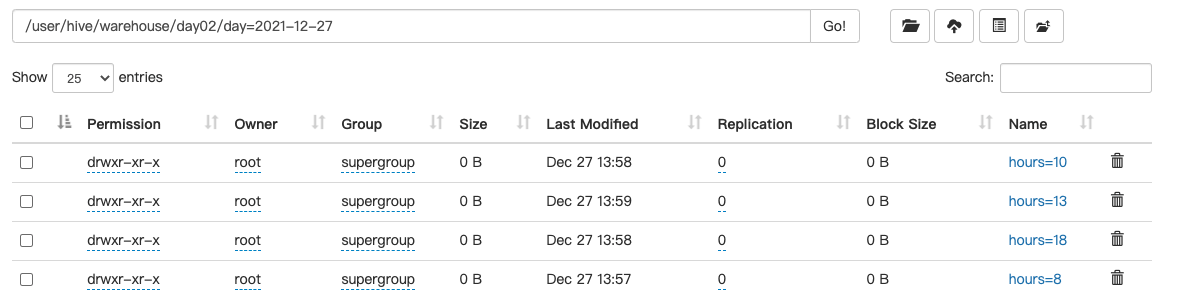
查看一个分区中的数据
select * from day02 where day='2021-12-27' and hours='13';

8.分区数据查询问题
首先在HDFS上建一个文件夹
hadoop fs -mkdir /user/hive/warehouse/day01/day=2021-12-28
然后往里面插入数据
hadoop fs -put /home/wl/data/day01.txt /user/hive/warehouse/day01/day=2021-12-28

我们发现里面是有数据的,那么再去看看day01表中是否有 day=2021-12-28 数据
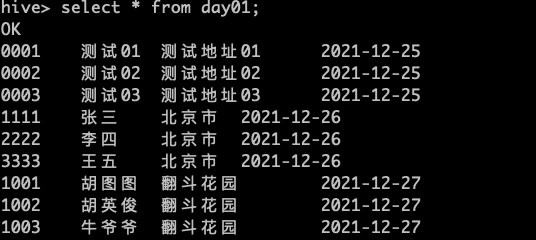
有以下三种解决方案:
1.修复命令
执行修复命令
msck repair table day01;
这个命令会去扫描HDFS上面的文件目录是否和mysql存储的元数据是否一致,如果不一致就会进行修复

再次查看表中的数据
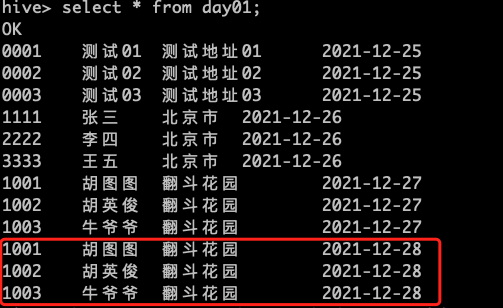
2.手动添加分区
alter table day01 add partition(day='2021-12-28')
3.创建文件夹后 load 数据到分区
将本地的数据load进表中
load data local inpath '/home/wl/data/day01.txt' into table default.day01 partition(day='2021-12-28');
9.动态分区
根据某个特定的字段进行分区,无需写死
创建一个分区表
>create table day03(id string ,name string)
>partitioned by (address string)
>row format delimited fields terminated by ',';
往分区中加载数据
动态分区的列必须在查询语句的最后
insert into table day03 partition(address) select id,name,address from day02;
这里报错是因为动态分区的模式,默认 strict,表示必须指定至少一个分区为 静态分区,nonstrict 模式表示允许所有的分区字段都可以使用动态分区。

我们发现,分区按照地址进行动态分区
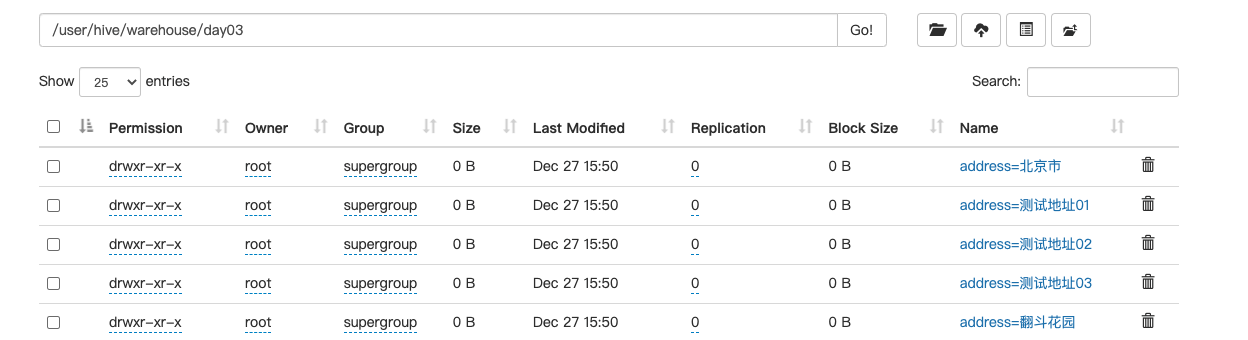
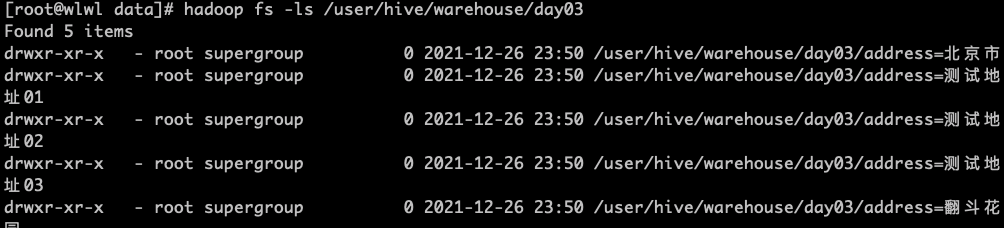
2.分桶表
将数据拆分成文件进桶里面存储
创建分桶表
>create table bucket(id int ,name string)
> clustered by(id)
> into 4 buckets
> row format delimited fields terminated by ',';
准备数据
1001,胡图图
1002,黑猫警长
1003,蝎子精
1004,大熊
1005,叮当猫
1006,柯南
1007,牛爷爷
1008,胡英俊
1009,穿山甲
1010,蛇精
加载数据
load data local inpath '/home/wl/data/bucket.txt' into table bucket;
注意:这里分桶需要有一个注意的点,因为默认reducer的个数为1,所以分桶的时候会出现以下错误
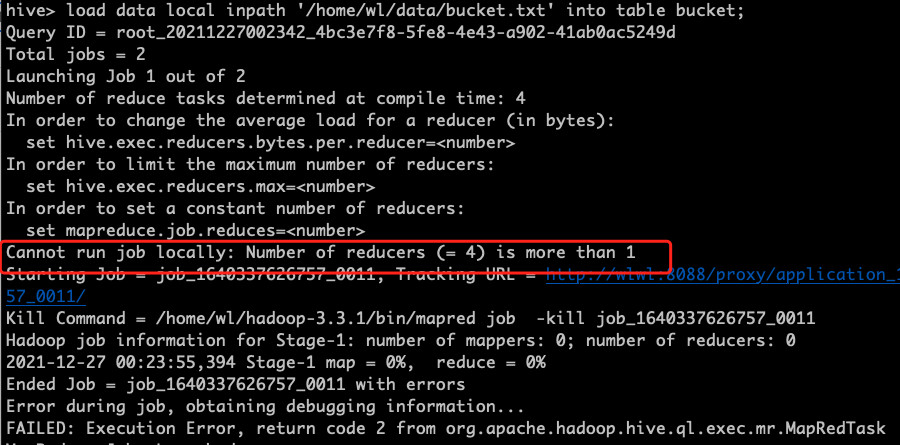
在hive中配置reducer的个数
set mapred.reduce.tasks = 5;
9.函数
1.系统内置函数
查看系统自带的函数
show functions;
显示自带的函数的用法
desc function when;
展示自带函数的详细用法
desc function extended when;
2.常用内置函数
1.NVL函数-空字段赋值

用法 :nvl(values,default_values):表示如果value的值不是空的则返回value,否则返回default_value
创建一个表
>create table nvlTest(id int,name string,depno string)
>row format delimited fields terminated by ',';
往表中加载数据
load data local inpath '/home/wl/data/nvlTest.txt' into table nvlTest;
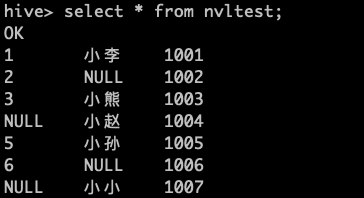
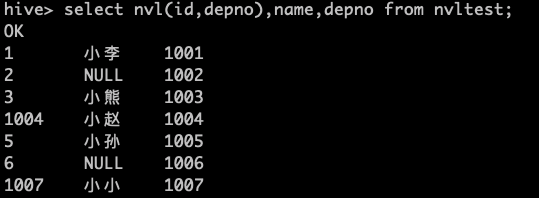
使用nvl函数进行处理
select nvl(id,depno),name,depno from nvltest;
2.CASE WHEN THEN ELSE END
建表
>create table emp(name string,dep_name string,sex string)
>row format delimited fields terminated by ',';
数据准备
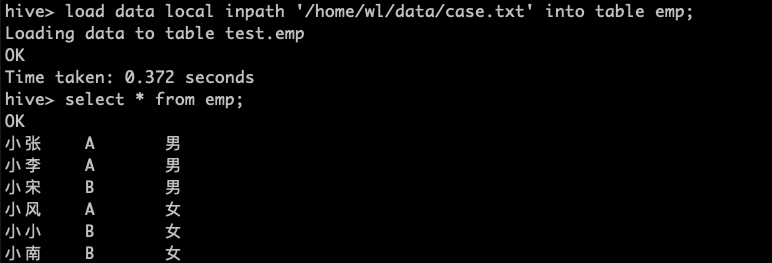
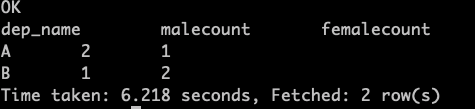
需求 :求出不同部门男女各多少人
> select
> dep_name,
> sum (case sex when '男' then 1 else 0 end) maleCount,
> sum(case sex when '女' then 1 else 0 end) femaleCount
> from emp
> group by dep_name;
3.行转列
拼接函数:
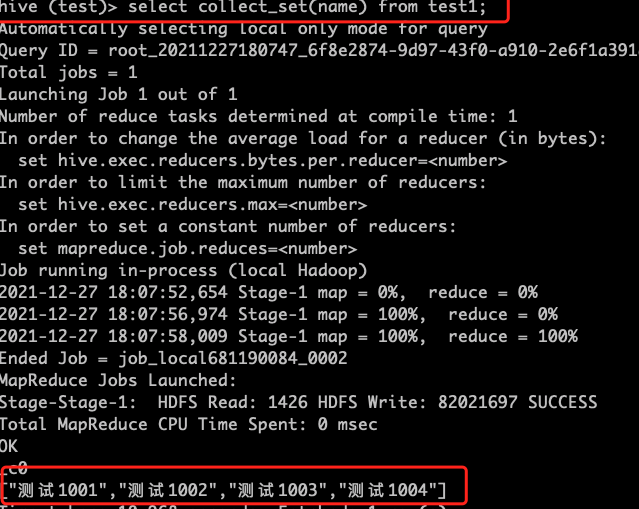
- COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重 汇总,产生 Array 类型字段。
- CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数剩余参
数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将 为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接 的字符串之间
COLLECT_SET的使用:
select collect_set(name) from test1;
CONCAT_WS的使用
select concat_ws('-','a','b','c','d');

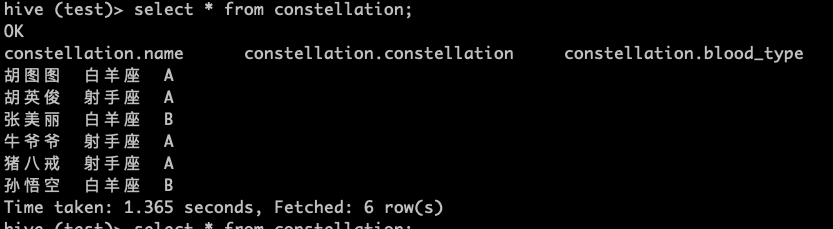
建表
>create table constellation(name string,constellation string,blood_type string)
>row format delimited fields terminated by ',';
数据准备
胡图图,白羊座,A
胡英俊,射手座,A
张美丽,白羊座,B
牛爷爷,射手座,A
猪八戒,射手座,A
孙悟空,白羊座,B
加载数据
load data local inpath '/home/wl/data/constellation.txt' into table constellation;
需求:把星座和血型一样的人归类到一起
射手座,A 胡英俊|牛爷爷|猪八戒
白羊座,A 胡图图
白羊座,B 张美丽|孙悟空
思路:
1.首先先把星座和血型拼接起来
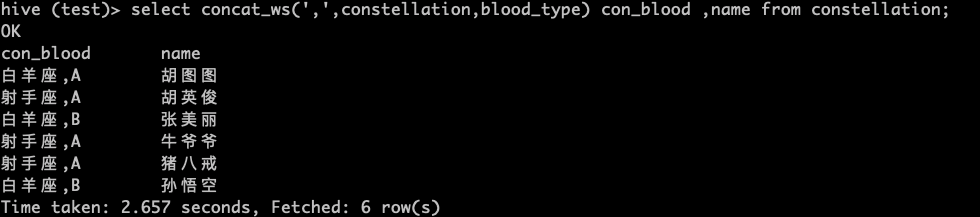
select concat_ws(',',constellation,blood_type) con_blood ,name from constellation;
2.聚合相同星座血型的人名
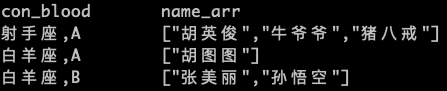
SELECT
con_blood,
collect_set ( NAME ) name_arr
FROM
(
SELECT
concat_ws( ',', constellation, blood_type ) con_blood,
NAME
FROM
constellation
) t1
GROUP BY
con_blood;
3.完成操作
SELECT
con_blood,
concat_ws( '|', name_arr )
FROM
(
SELECT
con_blood,
collect_set ( NAME ) name_arr
FROM
(
SELECT
concat_ws( ',', constellation, blood_type ) con_blood,
NAME
FROM
constellation
) t1
GROUP BY
con_blood) t2;

4.列转行
查看explode函数的使用

建表测试
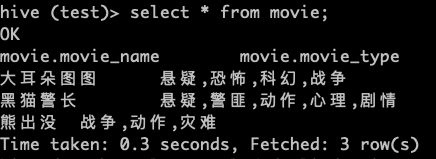
>create table movie(movie_name string,movie_type string)
>row format delimited fields terminated by '|';
数据准备
大耳朵图图|悬疑,恐怖,科幻,战争
黑猫警长|悬疑,警匪,动作,心理,剧情
熊出没|战争,动作,灾难
加载数据
load data local inpath '/home/wl/data/movie.txt' into table split_table;
使用explode函数
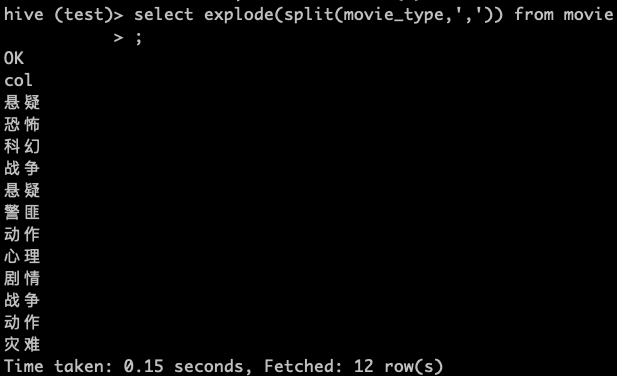
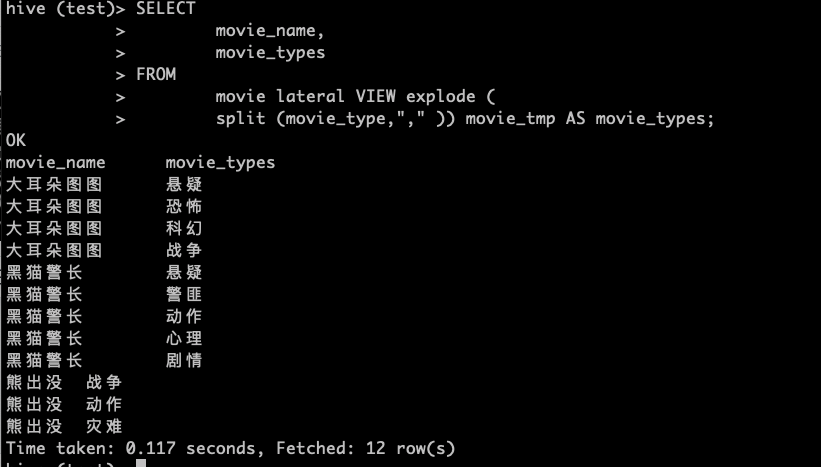
> SELECT
> movie_name,
> movie_types
> FROM
> movie lateral VIEW explode (
> split (movie_type,"," )) movie_tmp AS movie_types;
10.Kotlin连接Hive
1.启动元数据服务
bin/hive --service metastore
2.启动Hserver2服务
在Hive中conf目录下,在hive-site.xml里面添加以下内容
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>wlwl</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
启动h2服务
bin/hive --service hiveserver2
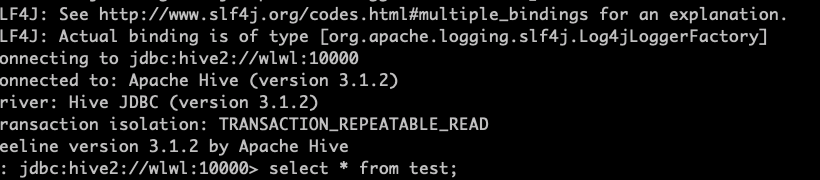
3.启动beeline 客户端
bin/beeline -u jdbc:hive2://wlwl:10000/default
发现出现了以下错误

解决方案:
在hadoop中的core-site.xml中添加以下内容
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
看到以下界面说明,连接成功
4.IDEA中创建Kotlin工程连接Hserver2
gradle内容如下
plugins {
id 'org.jetbrains.kotlin.jvm' version '1.4.32'
}
group 'org.example'
version '1.0-SNAPSHOT'
repositories {
mavenCentral()
}
dependencies {
implementation "org.jetbrains.kotlin:kotlin-stdlib"
implementation 'org.apache.hive:hive-jdbc:2.3.2'
implementation 'org.apache.hadoop:hadoop-common:3.1.1'
implementation 'org.apache.hadoop:hadoop-client:3.2.2'
implementation 'org.apache.hive:hive-metastore:2.3.8'
}
2.连接代码如下
fun main(){
var stmt:Statement?
var conn:Connection?
var rs:ResultSet?
// 定义路径
val url="jdbc:hive2://wlwl:10000/default"
// 反射注册Driver
Class.forName("org.apache.hive.jdbc.HiveDriver")
// 获取连接
conn=DriverManager.getConnection(url)
stmt=conn.createStatement()
// 执行sql
val sql="select * from test"
rs=stmt.executeQuery(sql)
// 获取值
while (rs.next()){
print(rs.getString("test_id")+"\t")
print(rs.getString("test_name"))
println()
}
}
查看hive中的test
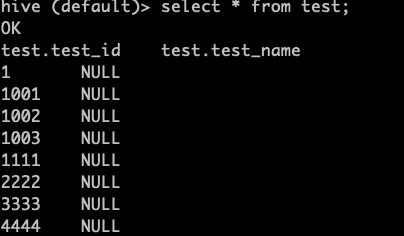
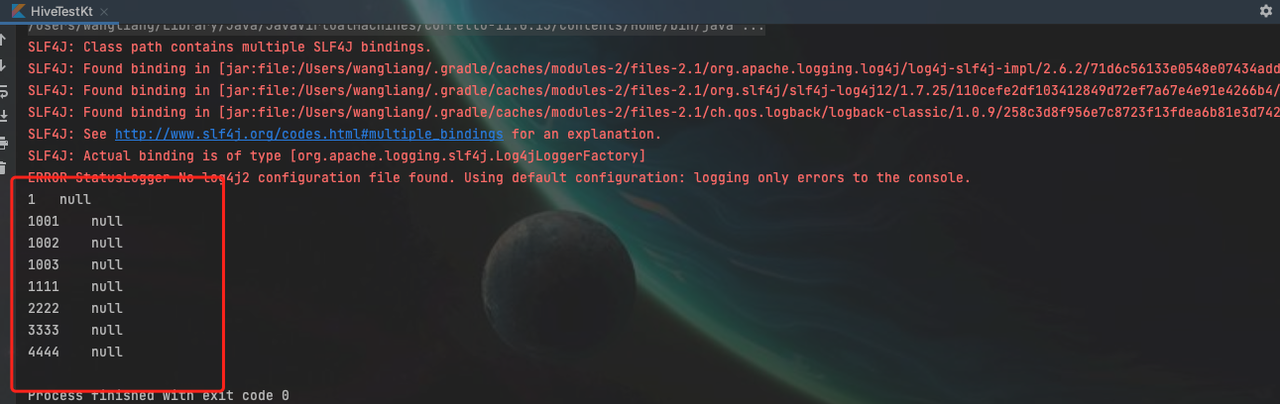
和kotlin执行的结果一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号