ElatsicSearch
1.安装(es版本一定要一一对应)
1.1 es下载地址(默认访问端口9200)
https://www.elastic.co/cn/downloads/elasticsearch
1.2 es head插件下载地址(默认访问端口9100)
https://github.com/mobz/elasticsearch-head
启动命令
npm run start
1.3 安装es head插件在(windows)
npm install # 打开所在的目录 cmd 执行npm install
1.4 在es的yml中配置以下,解决跨域
http.cors.enabled: true
http.cors.allow-origin: "*"
1.5 下载kibana(kibana是用来收集数据,并且可以做日志打印分析.(默认访问端口5601))
https://www.elastic.co/cn/downloads/kibana
1.6 汉化(在yml文件中加上以下内容)
i18n.locale: "zh-CN"
1.7 下载ik分词器(下载完成后解压缩添加到es的plugins目录下,v后面是版本号)
https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v7.13.4
2.使用ik分词器
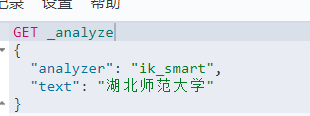
2.1 ik_smart(最少划分)

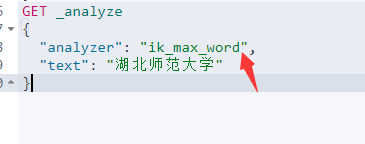
2.2 ik_max_word(最细致划分)
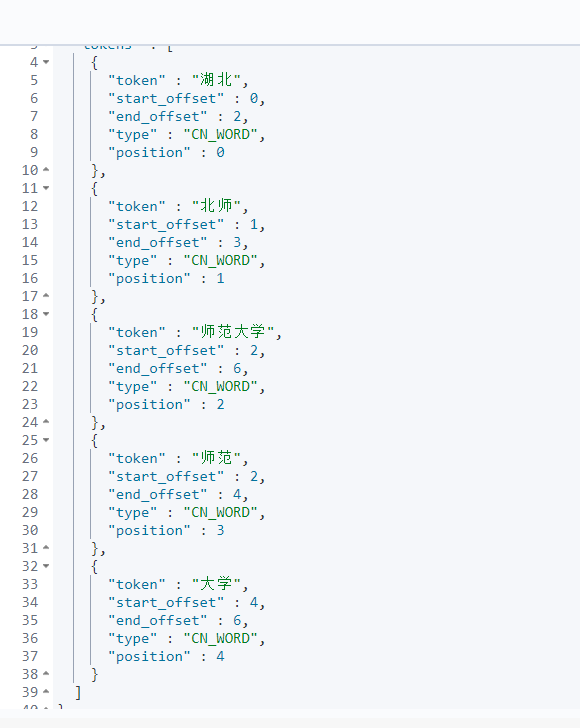
2.3 自定义词首先在ik分词中找到
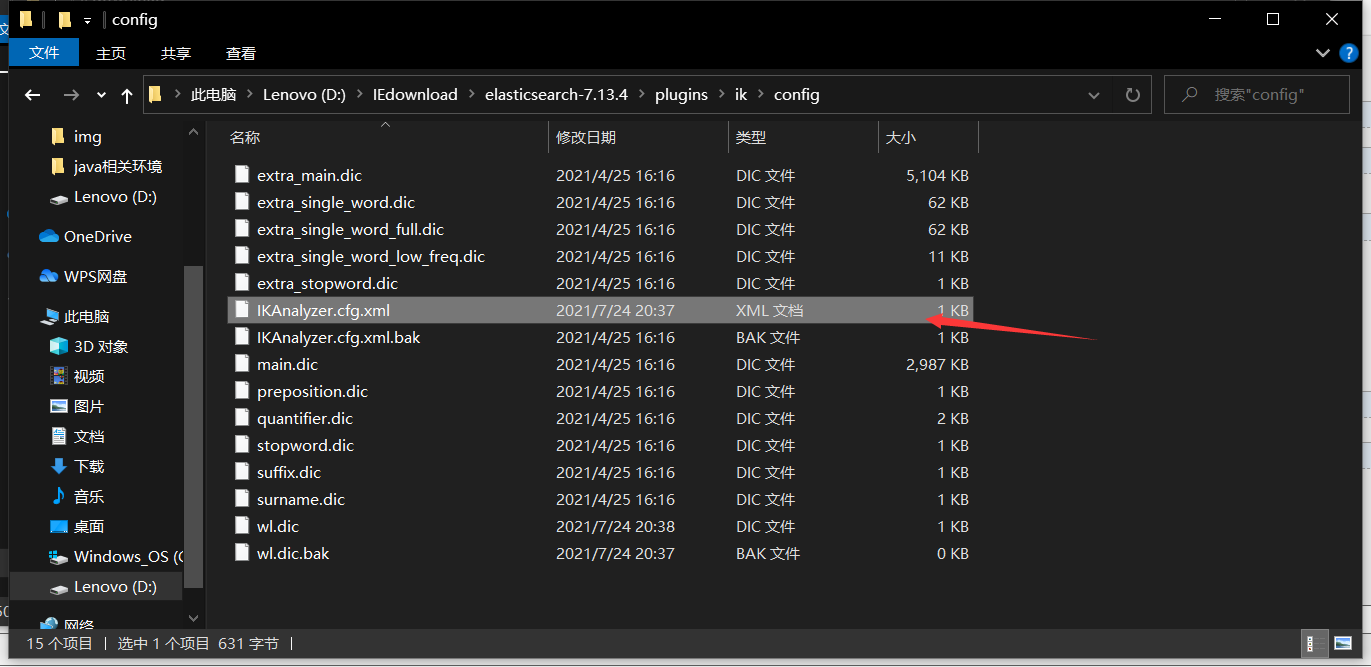
然后在下图位置添加
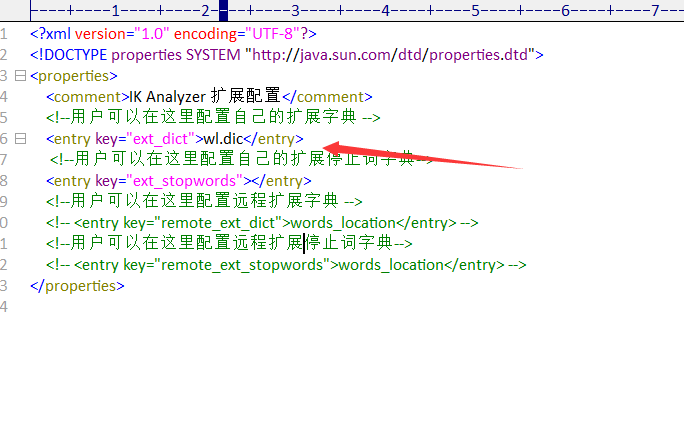
最后再创建一个自己的字典就行了
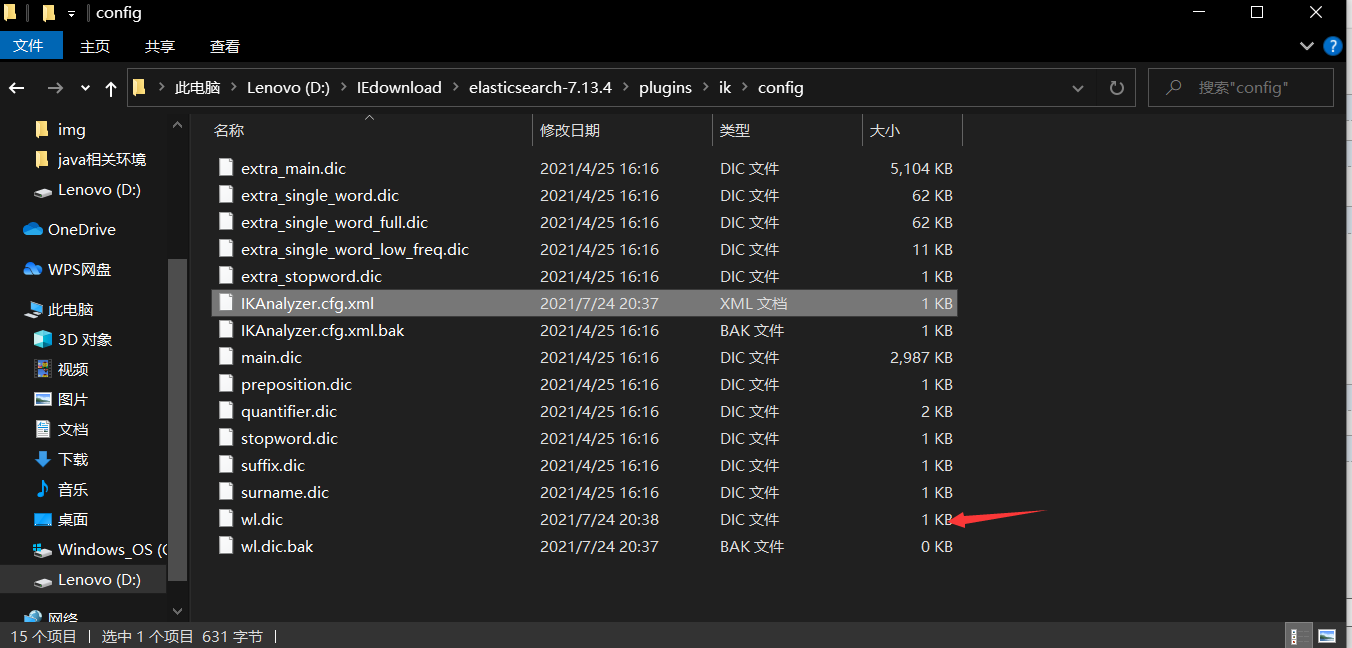
3.索引
3.1添加索引结构(类似于数据库中加一个表的时候给他设计字段的类型结构)
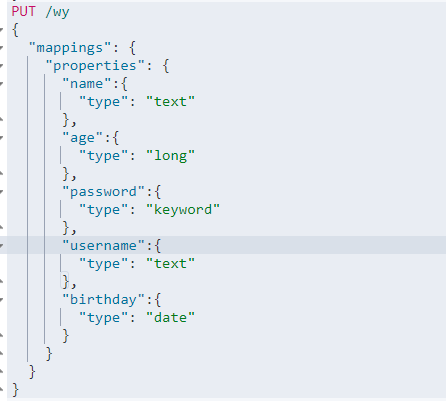
3.2 直接添加数据,es会默认帮我们自动创建字段的结构类型
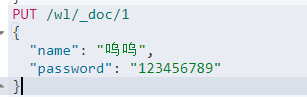
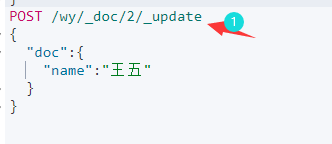
3.3 修改
3.4 删除
使用delete命令 加上你要删除对额
3.5 查询(模糊查询,只可单条件查询)

查询的结果如下

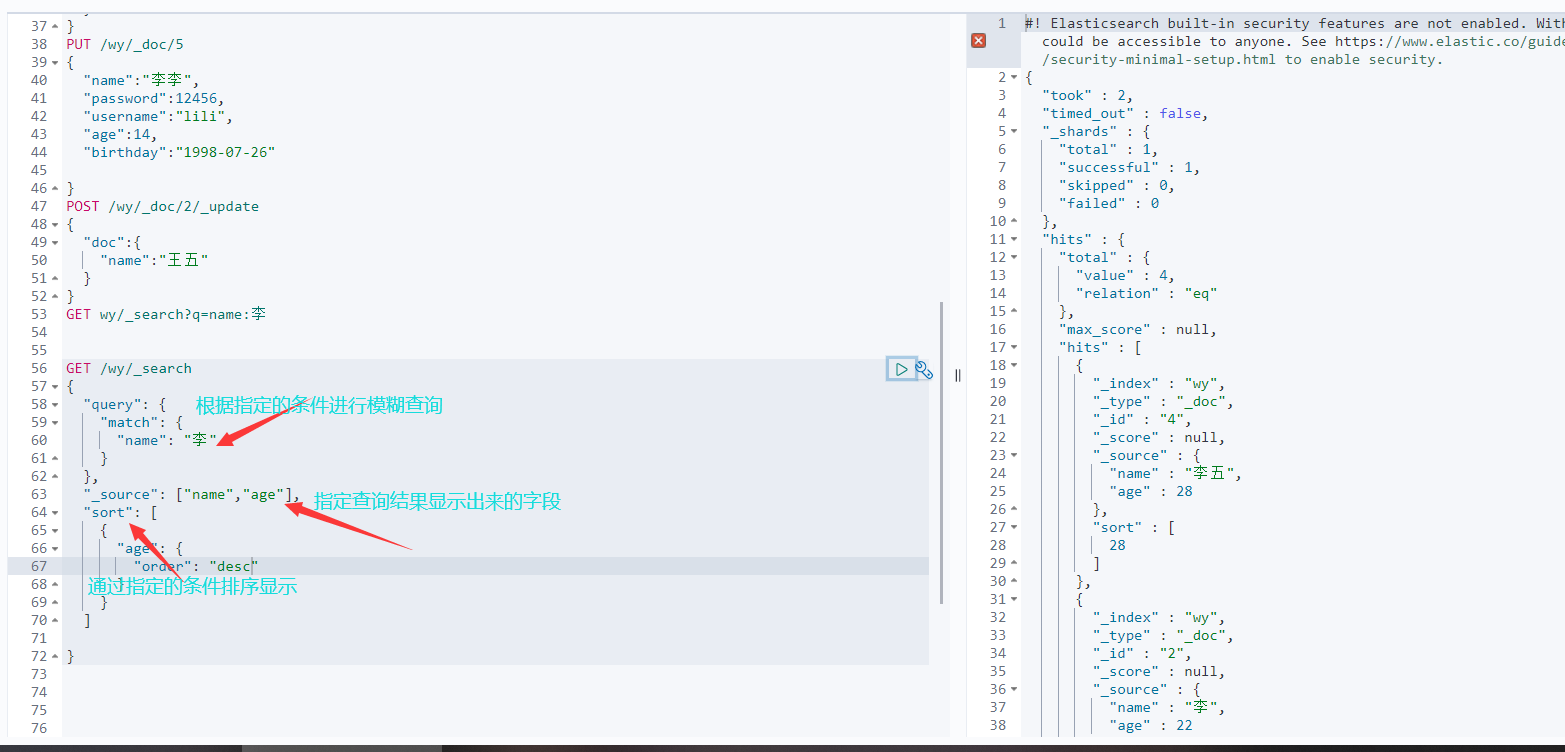
4.复杂查询
4.1
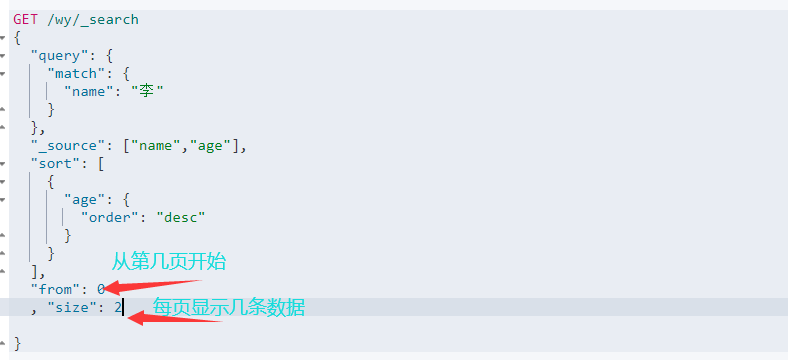
4.2 分页
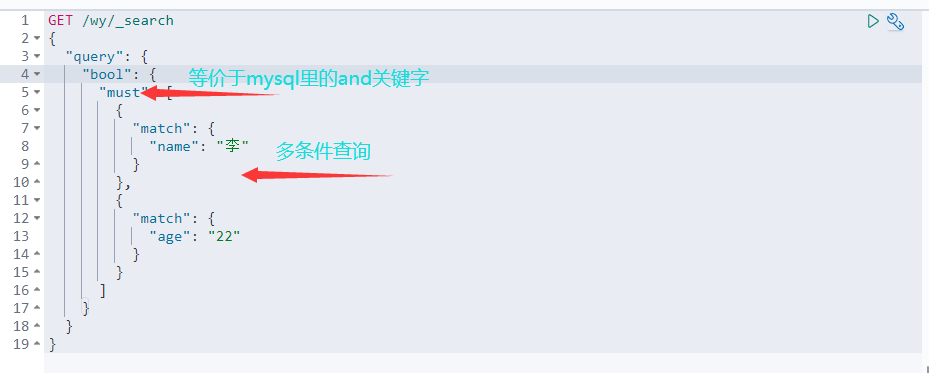
4.3 布尔值查询
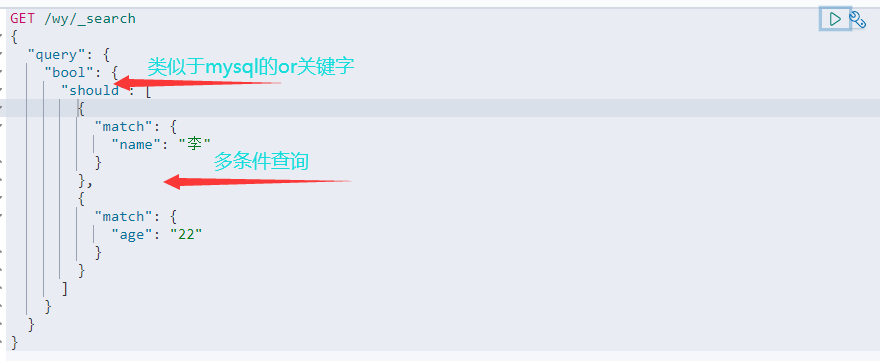
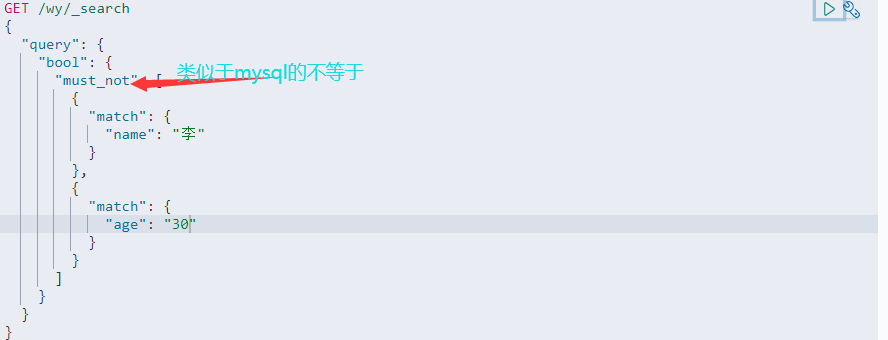

4.4 ES基本类型
(2)数字类型:long, integer, short, byte, double, float, half_float, scaled_float
(3)日期:date
(4)日期 纳秒:date_nanos
(5)布尔型:boolean
(6)Binary:binary
(7)Range: integer_range, float_range, long_range, double_range, date_range
(2)Geo-shape: geo_shape (for complex shapes like polygons)
(2)Completion类型:completion (to provide auto-complete suggestions)
(3)Token count:token_count (to count the number of tokens in a string)
(4)mapper-murmur3:murmur3(to compute hashes of values at index-time and store them in the index)
(5)mapper-annotated-text:annotated-text (to index text containing special markup (typically used for identifying named entities))
(6)Percolator:(Accepts queries from the query-dsl)
(7)Join:(Defines parent/child relation for documents within the same index)
(8)Alias:(Defines an alias to an existing field.)
(9)Rank feature:(Record numeric feature to boost hits at query time.)
(10)Rank features:(Record numeric features to boost hits at query time.)
(11)Dense vector:(Record dense vectors of float values.)
(12)Sparse vector:(Record sparse vectors of float values.)
(13)Search-as-you-type:(A text-like field optimized for queries to implement as-you-type completion)
4.5 SpringBoot 集成 es细节
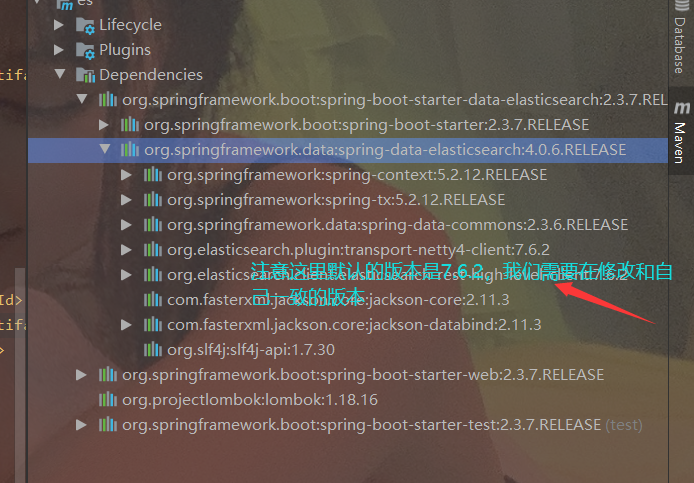
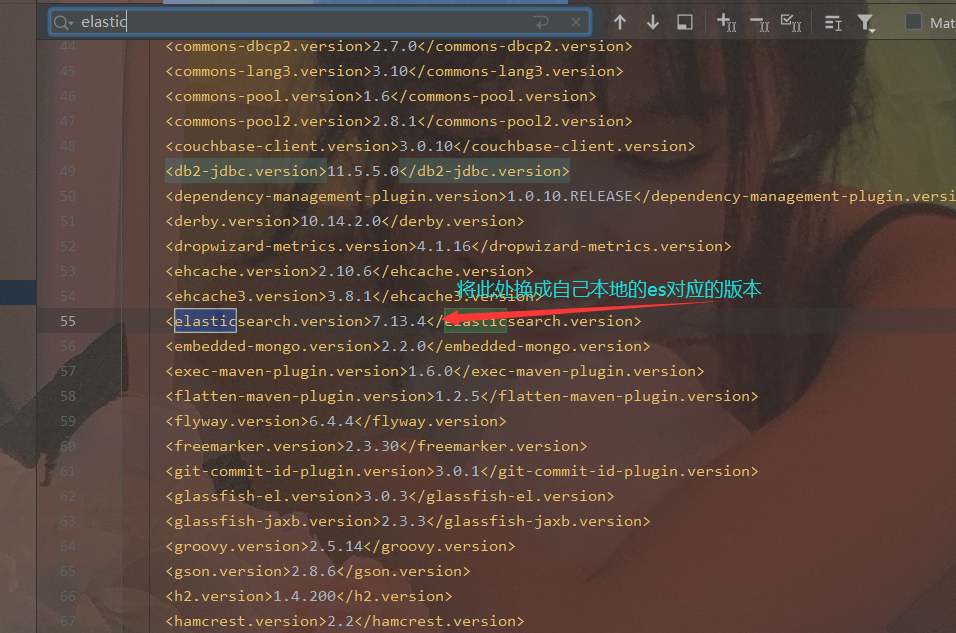
4.6 点进去找到es版本 修改即可
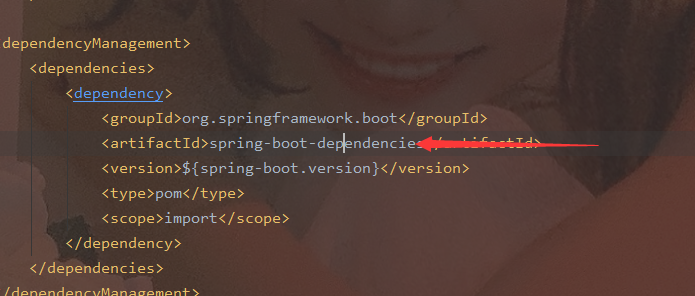
4.7文档
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
5.配置类代码
@Configuration
public class Myconfig {
@Bean
public RestHighLevelClient restHighLevelClient() {
return new RestHighLevelClient ( RestClient. builder ( new HttpHost( "localhost" , 9200 , "http" )));
}
}
6.基本的增删改
@Test
void contextLoads() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("test_wl");
CreateIndexResponse cr = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(cr);
}
@Test
// 测试添加文档
void addDoc() throws IOException {
IndexRequest indexRequest = new IndexRequest("test_wl");
// IndexRequest indexRequest = new IndexRequest ( "posts" ) 。id (“1” )。
// source ( "user" , "kimchy" , "postDate" , new Date (), "message" , "trying out Elasticsearch" );
// 创建对象
User user = new User(1003,"李四",34,"12aada3");
indexRequest.id("3").source(JSON.toJSONString(user), XContentType.JSON);
restHighLevelClient.index(indexRequest,RequestOptions.DEFAULT);
}
@Test
// 测试更新文档
void updateDoc() throws IOException {
// 创建更新请求
UpdateRequest updateRequest = new UpdateRequest("test_wl","1");
// 创建对象
User user = new User();
user.setName("胡图图");
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
// 执行更新操作
restHighLevelClient.update(updateRequest,RequestOptions.DEFAULT);
}
@Test
// 获取文档内容
void getDoc() throws IOException {
GetRequest gr = new GetRequest("test_wl","1");
GetResponse documentFields = restHighLevelClient.get(gr, RequestOptions.DEFAULT);
System.out.println(documentFields);
}
@Test
// 删除文档内容
void delDoc() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("test_wl","3");
restHighLevelClient.delete(deleteRequest,RequestOptions.DEFAULT);
}
@Test
// 批量插入
void bulkDoc() throws IOException {
BulkRequest bulkRequest = new BulkRequest();
List<User> userList = new ArrayList<>();
for (int i = 0; i <10; i++) {
userList.add(new User(1002+i,"吴"+i,3+i,"133ada"+i));
}
// 批处理请求
for (int i = 0; i <userList.size() ; i++) {
bulkRequest.add(new IndexRequest("test_wl").id(""+(i+1)).source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
}
@Test
// 查询
void queryDoc() throws IOException {
SearchRequest searchRequest = new SearchRequest("test_wl");
SearchSourceBuilder builder = new SearchSourceBuilder();
// 构建搜索条件
// bool 和 kibana 里面的一一对应
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "吴");
builder.query(termQueryBuilder);
searchRequest.source(builder);
// 执行查询操作
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(search);
}
7.jsoup爬取数据
public class JsoupUtils {
private JsoupUtils(){}
public static List<Content> getInformation(String keyword) throws Exception {
// 创建一个集合添加数据
List<Content> contentList = new ArrayList<>();
String url = "https://search.jd.com/Search?keyword="+keyword;
// 解析网页 返回的 Document就是js里面的dom对象
Document document = Jsoup.parse(new URL(url), 30000);
// 根据id获取dom操作
Element element = document.getElementById("J_goodsList");
// 获取所有的li标签
Elements li = document.getElementsByTag("li");
// 便利获取li中的数据信息
for (Element elements : li) {
if (elements.attr("class").equalsIgnoreCase("gl-item")){
String img = elements.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = elements.getElementsByClass("p-price").eq(0).text();
String title = elements.getElementsByClass("p-name").eq(0).text();
contentList.add(new Content(title,price,img));
}
}
return contentList;
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号