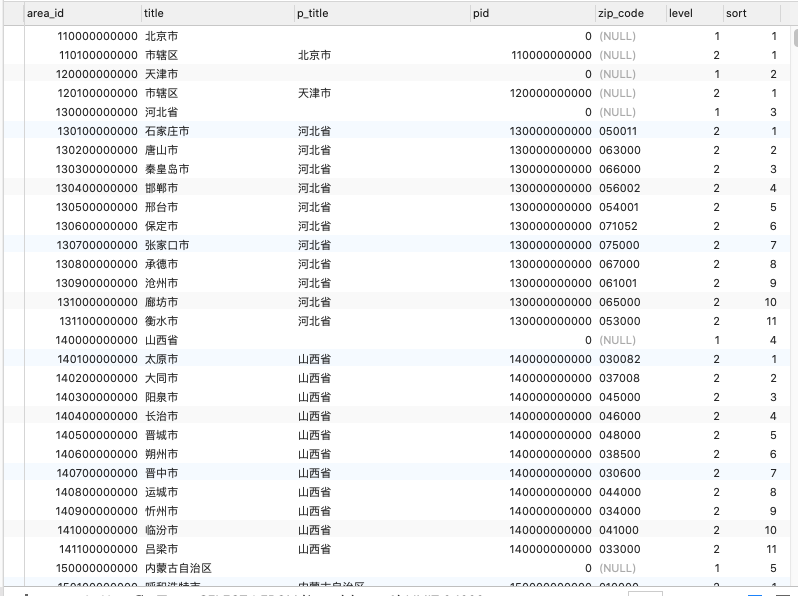
全国地区 4级 5级 mysql 数据
数据来源于
http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/
注意表结构和字段编码为 utf8mb4
CREATE TABLE `area_5` ( `area_id` bigint(13) NOT NULL AUTO_INCREMENT COMMENT '地区id', `title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '地区名称', `p_title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '父级地区名称', `pid` bigint(13) NOT NULL DEFAULT '0' COMMENT '父级地区ID', `zip_code` varchar(10) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT '邮编', `level` tinyint(2) NOT NULL DEFAULT '1' COMMENT '地区层级', `sort` smallint(6) NOT NULL DEFAULT '0' COMMENT '排序值', PRIMARY KEY (`area_id`) USING BTREE, KEY `pid` (`pid`) USING BTREE ) ENGINE=MyISAM AUTO_INCREMENT=820008000001 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT='区域表';
爬取代码


import scrapy class AreaSpider(scrapy.Spider): name = 'area' start_urls = ['http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/index.html'] def parse(self, response): print("开始运行") href_list = response.xpath("//tr[@class='provincetr']/td/a/@href").extract() area_list = response.xpath("//tr[@class='provincetr']/td/a/@href").extract() i=0 for href in href_list: url = response.urljoin(href) add_params = {} add_params['area_id'] = area_list[i] i=i+1 yield scrapy.Request(url=url, callback=self.parse_city,cb_kwargs=add_params) # 城市的数据,传入父级省份的id,解开注释的yield 就返回城市数据,下方其他地区同理 def parse_city(self, response,area_id): # for quote in response.css('tr.citytr'): # yield { # 'area_id': quote.css('td a::text').get(), # 'name': quote.xpath('./td[2]/a/text()').get(), # 'url':area_id # } href_list = response.xpath("//tr[@class='citytr']/td[1]/a/@href").extract() area_list = response.xpath("//tr[@class='citytr']/td[1]/a//text()").extract() i=0 for href in href_list: url = response.urljoin(href) add_params = {} add_params['area_id'] = area_list[i] i = i + 1 yield scrapy.Request(url=url, callback=self.parse_area, cb_kwargs=add_params) ##地区的数据 def parse_area(self, response,area_id): href_list = response.xpath("//tr[@class='countytr']/td[1]/a/@href").extract() area_list = response.xpath("//tr[@class='countytr']/td[1]/a//text()").extract() print(href_list) i = 0 for href in href_list: url = response.urljoin(href) add_params = {} add_params['area_id'] = area_list[i] i = i + 1 yield scrapy.Request(url=url, callback=self.parse_street, cb_kwargs=add_params) # for quote in response.css('tr.countytr'): # yield { # 'area_id': quote.xpath('./td[1]//text()').get(), # 'name': quote.xpath('./td[2]//text()').get(), # 'pid':area_id # } ##街道数据 def parse_street(self, response,area_id): href_list = response.xpath("//tr[@class='towntr']/td[1]/a/@href").extract() area_list = response.xpath("//tr[@class='towntr']/td[1]/a//text()").extract() print(href_list) i = 0 for href in href_list: url = response.urljoin(href) add_params = {} # time.sleep(1) # 休眠0.1秒 print(i) add_params['area_id'] = area_list[i] i = i + 1 yield scrapy.Request(url=url, callback=self.parse_cun, cb_kwargs=add_params) # for quote in response.css('tr.towntr'): # yield { # 'area_id': quote.xpath('./td[1]//text()').get(), # 'name': quote.xpath('./td[2]//text()').get(), # 'pid':area_id # } ##村\居委会数据 def parse_cun(self, response,area_id): ##没有下级了就直接返回了 for quote in response.css('tr.villagetr'): yield { 'area_id': quote.xpath('./td[1]//text()').get(), 'name': quote.xpath('./td[3]//text()').get(), 'type': quote.xpath('./td[2]//text()').get(), 'pid':area_id }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号